一、基本概念
1、页:struct page ,如下图所示,x86架构下一般为4K为大小
2、分区:struct zone ,如下图所示,x86架构下分为三个区ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM
3、ZONE_DMA,一般由于内存碎片,有可能申请不到连续的一片物理内存,而DMA需要连续的物理内存,所以在X86下给DMA大概会留一块连续的16M的物理内存。
4、内存节点:struct node。对于一个简单的嵌入式系统只有一个node,对于大型服务器而言,有成千上万个CPU,这样肯定有成千上万个node,每个cpu都可以访问自己的内存,同时也可以通过总线访问其他内存。

二、内存管理
1、zone通过buddy系统进行管理,buddy system由Harry Markowitz在1963年提出。buddy用来管理内存的使用情况:一个页被申请了,别人就不能申请了。通过/proc/buddyinfo可以查看buddy的内存余量。buddy是zone里面的一个成员,每个zone都有自己的buddy系统来管理自己的内存(buddy管理是物理内存)。
2、buddy的问题就是容易碎掉,基于buddy,slab(或slub/slob)对内存进行了二次管理,使系统可以申请小块内存。Slab先从buddy拿到数个页的内存,然后切成固定的小块(称为object),再分配出去。从/proc/slabinfo中可以看到系统内有很多slab,每个slab管理着数个页的内存,它们可分为两种:模块专用的、通用。专用slab主要用于内核各模块的一些数据结构,这些内存是模块启动时就通过kmem_cache_alloc分配好占为己有,一些模块自己单独申请一块kmem_cache可以确保有可用内存。而通用slab则用于给内核中的kmalloc等函数分配内存。slabtop命令可以查看当前系统中slab内存的消耗情况。
三、各种内存申请和内存管理之间的关系
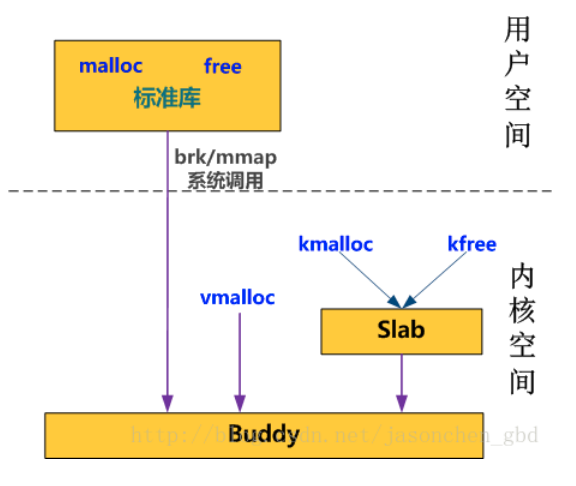
1、vmalloc:vmalloc是直接向buddy要内存,申请内存的最小单位是一页,可以从高端和低端拿内存
2、kmalloc:kmalloc通过slab拿内存,slab只从lowmem申请内存
3、malloc:用户态的malloc通过brk/mmap系统调用每次向内核申请一页,然后在标准库里再做进一步管理供用户程序使用
四、内存相关问题
1、户态申请内存时的”lazy allocation”
用户态申请内存时,库函数并不会立即从内核里去拿,而是COW(copy on write)的,要不然用户态细细碎碎的申请释放都要跟内核打交道,那频繁系统调用的代价太大,并且内核每次都是一页一页的分配给用户态,小内存让内核很头疼的。
但是库函数会欺骗用户程序,你申请10MB,就让你以为已经拥有了10MB内存,但是只有你真的要用的时候,C库才会一点一点的从内核申请,直到10MB都拿到,这就是用户态申请内存的lazy模式。有时用户程序为了立即拿到这10MB内存,在申请完之后,会立即把内存写一遍(例如memset为0),让C库将内存都真正申请到。Linux会欺骗用户程序,但不欺骗内核,内核中的kmalloc/vmalloc就真的是要一个字节内存就没了一个字节。
因此malloc在刚申请(brk或mmap)的时候,10MB所有页面在页表中全都映射到同一个零化页面(ZERO_PAGE,全局共享的页,页的内容总是0,用于zero-mapped memory areas等用途),内容全是0,且页表上标记这10MB是只读的,在写的时候发生page fault,才去一页一页的分配内存和修改页表。所以brk和mmap只是扩展了你的虚拟地址空间,而不是去拿内存。在你实际去写内存的时候,内核会先把这个只读0页面拷贝到给你新分配的页面,然后执行你的写操作。
进程栈的内存分配也是lazy的,因为进程栈对应的VMA的vma->vm_flags带有VM_GROWSDOWN标记,这样,在page fault处理的时候kernel就知道落在了stack区域,就会通过expand_stack(vma, address)将栈扩展(vma区域的vm_start降低),这时如果扩展超过RLIMIT_STACK或RLIMIT_AS的限制,就会返回-ENOMEM。
2、OOM(Out Of Memory)
OOM即是内存不够用了,在内核中会选择杀掉某个进程来释放内存,内核会给所有进程打分,分最高的则被杀掉,打分的依据主要是看谁占的内存多(当然是杀掉占内存的多的进程才能释放更多内存)。每个进程的/proc/pid/oom_score就是当前得分,OOM的时候就会选择分数最高的那个杀掉。被干掉之后,OOM的打印中也会打印出这个进程的score。
评分标准(mm/oom_kill.c中的badness()给每个进程一个oom score)有:
根据resident内存、page table和swap的使用情况,采用百分比乘以10,因此最高1000分,最低0分。
root用户进程减30分。
oom_score_adj: oom_score会加上这个值。可以在/proc/pid/oom_score_adj中修改(可以是负数),这样来人为地调整score结果。
oom_adj: -16~15的系数调整。修改/proc/pid/oom_adj里面的值,是一个系数,因此会在原score上乘上系数。数值越大,score结果就会变得越大,数值为负数时,score就会变得比原值小。
修改了3、4之后,/proc/pid/oom_score中的值就会随之改变。这样的话,就可以人为地干预OOM杀掉的进程。
参考:
Linux内存管理 —— 内核态和用户态的内存分配方式 - kissrule - 博客园
linux内存管理 -- Slab_linux slab_嘭噗的博客-CSDN博客