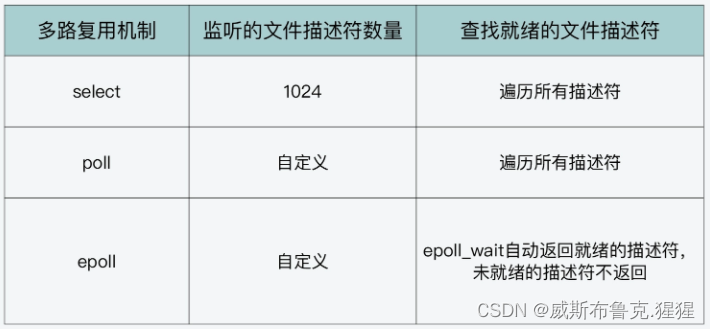
第五章.与学习相关技巧
5.3 Batch Normalization
- Batch Norm以进行学习时的mini_batch为单位,按mini_batch进行正则化,具体而言,就是进行使数据分布的均值为0,方差为1的正则化。
- Batch Norm是调整各层激活值的分布使其拥有适当的广度。
1.优点
- 可以使学习快速进行
- 不那么依赖初始值
- 抑制过拟合(降低Dropout等的必要性)
2.数学式
1).均值:

2).方差:
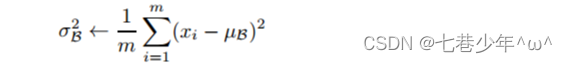
3).正则化:

- 参数说明:
①.ε:微小值(1e-7),防止出现除数为0的情况
4).缩放和平移
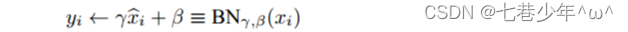
- 参数说明:
①.α,β:一开始α=1,β=0,然后通过学习调整到合适的值。
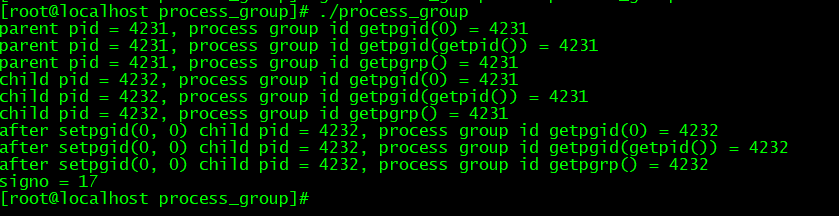
3.通过MNIST数据集来对比使用Batch Norm层与不使用Batch Norm层的差异。
1).不同权重初始值的标准差:
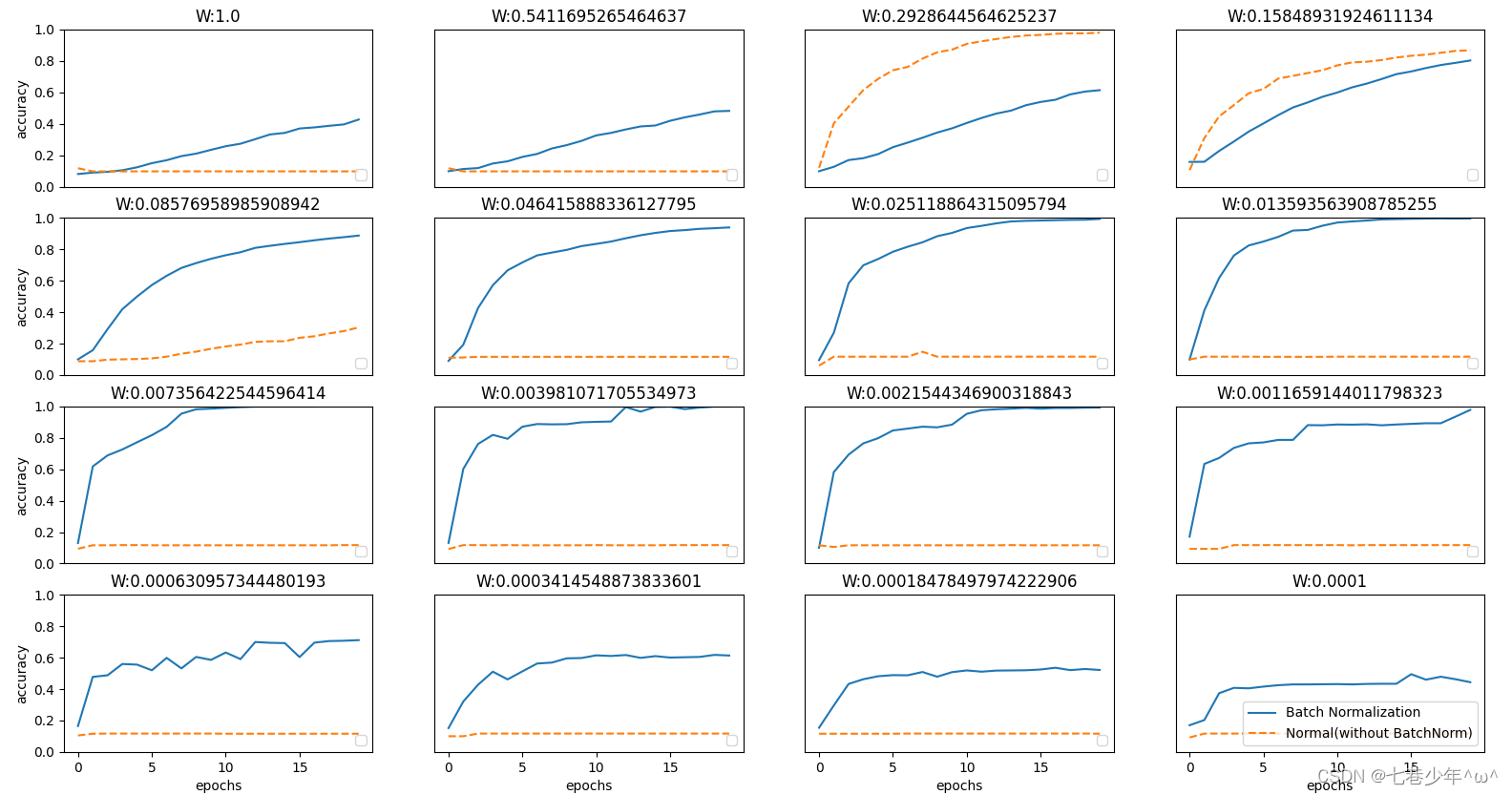
2).图像分析:
-
从图像可知,几乎所有的情况下都是使用Batch Norm时学习进行的更快,同时也可以发现,在不使用Batch Norm的情况下,如果不赋予一个尺度好的初始值,学习将完全无法进行。
-
综上,通过使用Batch Norm,可以推动学习的进行,并且对权重初始值变得健壮,不那么依赖初始值。
3).代码实现:
import sys, os
sys.path.append(os.pardir)
import numpy as np
import matplotlib.pyplot as plt
from dataset.mnist import load_mnist
from collections import OrderedDict
# 加载数据
def get_data():
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True)
return (x_train, t_train), (x_test, t_test)
def Sigmoid(x):
return 1 / (1 + np.exp(-x))
def Relu(x):
return np.maximum(x, 0)
def numerical_gradient(f, x):
h = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + h
fxh1 = f(x) # f(x+h)
x[idx] = tmp_val - h
fxh2 = f(x) # f(x-h)
grad[idx] = (fxh1 - fxh2) / (2 * h)
x[idx] = tmp_val # 还原值
it.iternext()
return grad
class SoftmaxWithLoss:
def __init__(self):
self.loss = None # 损失
self.y = None # softmax的输出
self.t = None # 监督数据(one_hot vector)
# 输出层函数:softmax
def softmax(self, x):
if x.ndim == 2:
x = x.T
x = x - np.max(x, axis=0)
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
x = x - np.max(x) # 溢出对策
return np.exp(x) / np.sum(np.exp(x))
# 交叉熵误差
def cross_entropy_error(self, y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 监督数据是one-hot-vector的情况下,转换为正确解标签的索引
if t.size == y.size:
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
# 正向传播
def forward(self, x, t):
self.t = t
self.y = self.softmax(x)
self.loss = self.cross_entropy_error(self.y, self.t)
return self.loss
# 反向传播
def backward(self, dout=1):
batch_size = self.t.shape[0]
if self.t.size == self.y.size: # 监督数据是one-hot-vector的情况
dx = (self.y - self.t) / batch_size
else:
dx = self.y.copy()
dx[np.arange(batch_size), self.t] -= 1
dx = dx / batch_size
return dx
class Affine:
def __init__(self, W, b):
self.W = W
self.b = b
self.x = None
self.original_x_shape = None
# 权重和偏置参数的导数
self.dW = None
self.db = None
# 正向传播
def forward(self, x):
# 对应张量
self.original_x_shape = x.shape
x = x.reshape(x.shape[0], -1)
self.x = x
out = np.dot(self.x, self.w) + self.b
return out
# 反向传播
def backward(self, dout):
dx = np.dot(dout, self.W.T)
self.dW = np.dot(self.x.T, dout)
self.db = np.sum(dout, axis=0)
# 还原输入数据的形状
dx = dx.reshape(*self.original_x_shape)
return dx
class SGD:
def __init__(self, lr):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]
# 调整各层的激活值分布使其拥有适当的广度
class BatchNormlization:
def __init__(self, gamma, beta, momentum, running_mean=None, running_var=None):
self.gamma = gamma
self.beta = beta
self.momentum = momentum
self.input_shape = None # Conv层的情况下为4维,全连接层的情况下为2维
# 测试时使用的平均值和方差
self.running_mean = running_mean
self.running_var = running_var
# backward时使用的中间数据
self.batch_size = None
self.xc = None
self.std = None
self.dgamma = None
self.dbeta = None
def __forward(self, x, train_flg):
if self.running_mean is None:
N, D = x.shape
self.running_mean = np.zeros(D)
self.running_var = np.zeros(D)
if train_flg:
mu = x.mean(axis=0)
xc = x - mu
var = np.mean(xc ** 2, axis=0)
std = np.sqrt(var + 1e-7)
xn = xc / std
self.batch_size = x.shape[0]
self.xc = xc
self.xn = xn
self.std = std
self.running_mean = self.momentum * self.running_mean + (1 - self.momentum) * mu
self.running_var = self.momentum * self.running_var + (1 - self.momentum) * var
else:
xc = x - self.running_mean
xn = xc / (np.sqrt(self.running_var + 1e-7))
return self.gamma * xn + self.beta
def forward(self, x, train_flg=True):
self.input_shape = x.shape
if x.ndim != 2:
N, C, H, W = x.shape
x = x.reshape(N, -1)
out = self.__forward(x, train_flg)
return out.reshape(*self.input_shape)
def __backward(self, dout):
dbeta = dout.sum(axis=0)
dgamma = np.sum(self.xn + dout, axis=0)
dxn = self.gamma * dout
dxc = dxn / self.std
dstd = -np.sum((dxn * self.xc) / (self.std * self.std), axis=0)
dvar = 0.5 * dstd / self.std
dxc += (2.0 / self.batch_size) * self.xc * dvar
dmu = np.sum(dxc, axis=0)
dx = dxc - dmu / self.batch_size
self.dgamma = dgamma
self.dbeta = dbeta
return dx
def backward(self, dout):
if dout.ndim != 2:
N, C, H, W = dout.shape
dout = dout.reshape(N, -1)
dx = self.__backward(dout)
dx = dx.reshape(*self.input_shape)
return dx
# 在学习过程中随机删除神经元的方法:dropout_ratio神经元的删除比
class Dropout:
def __int__(self, dropout_ratio=0.5):
self.dropout_ratio = dropout_ratio
self.mask = None
# 正向传播
def forward(self, x, train_flg=True):
if train_flg:
self.mask = np.random.rand(*x.shape) > self.dropout_ratio
return x * self.mask
else:
return x * (1 - self.dropout_ratio)
# 反向传播
def backward(self, dout):
return dout * self.mask
# 全连接的多层神经网络
class MultiLayerNet:
def __init__(self, input_size, hidden_size_list, output_size, activation='relu', weight_init_std='relu',
weight_decay_lambda=0, use_dropout=False, dropout_ratio=0.5, use_batchnorm=False):
self.input_size = input_size
self.hidden_size_list = hidden_size_list
self.output_size = output_size
self.hidden_layer_num = len(hidden_size_list)
self.use_dropout = use_dropout
self.use_batchnorm = use_batchnorm
self.weight_decay_lambda = weight_decay_lambda
self.params = {}
# 初始化权重
self.__init_weight(weight_init_std)
# 生成层
activation_layer = {'sigmoid': Sigmoid, 'relu': Relu}
self.layer = OrderedDict()
for idx in range(1, self.hidden_layer_num + 1):
self.layer['Affine' + str(idx)] = Affine(self.params['W' + str(idx)], self.params['b' + str(idx)])
if self.use_batchnorm:
self.params['gamma' + str(idx)] = np.ones(hidden_size_list[idx - 1])
self.params['beta' + str(idx)] = np.zeros(hidden_size_list[idx - 1])
self.layer['BatchNorm' + str(idx)] = BatchNormlization(self.params['gamma' + str(idx)],
self.params['beta' + str(idx)])
self.layer['Activation—_function' + str(idx)] = activation_layer[activation]
if self.use_dropout:
self.layer['Dropout' + str(idx)] = Dropout(dropout_ratio)
idx = self.hidden_layer_num + 1
self.layer['Affine' + str(idx)] = Affine(self.params['W' + str(idx)], self.params['b' + str(idx)])
self.last_layer = SoftmaxWithLoss()
def __init_weight(self, weight_init_std):
"""设定权重的初始值
Parameters
----------
weight_init_std : 指定权重的标准差(e.g. 0.01)
指定'relu'或'he'的情况下设定“He的初始值”
指定'sigmoid'或'xavier'的情况下设定“Xavier的初始值”
"""
all_size_list = [self.input_size] + self.hidden_size_list + [self.output_size]
for idx in range(1, len(all_size_list)):
scale = weight_init_std
if str(weight_init_std).lower() in ('relu', 'he'):
scale = np.sqrt(2.0 / all_size_list[idx - 1]) # 使用ReLU的情况下推荐的初始值
elif str(weight_init_std).lower() in ('sigmoid', 'xavier'):
scale = np.sqrt(1.0 / all_size_list[idx - 1]) # 使用sigmoid的情况下推荐的初始值
self.params['W' + str(idx)] = scale * np.random.randn(all_size_list[idx - 1], all_size_list[idx])
self.params['b' + str(idx)] = np.zeros(all_size_list[idx])
def predict(self, x, train_flg=False):
for key, layer in self.layers.items():
if "Dropout" in key or "BatchNorm" in key:
x = layer.forward(x, train_flg)
else:
x = layer.forward(x)
return x
def loss(self, x, t, train_flg=False):
"""求损失函数
参数x是输入数据,t是教师标签
"""
y = self.predict(x, train_flg)
weight_decay = 0
for idx in range(1, self.hidden_layer_num + 2):
W = self.params['W' + str(idx)]
weight_decay += 0.5 * self.weight_decay_lambda * np.sum(W ** 2)
return self.last_layer.forward(y, t) + weight_decay
def accuracy(self, X, T):
Y = self.predict(X, train_flg=False)
Y = np.argmax(Y, axis=1)
if T.ndim != 1: T = np.argmax(T, axis=1)
accuracy = np.sum(Y == T) / float(X.shape[0])
return accuracy
def numerical_gradient(self, X, T):
"""求梯度(数值微分)
Parameters
----------
X : 输入数据
T : 教师标签
Returns
-------
具有各层的梯度的字典变量
grads['W1']、grads['W2']、...是各层的权重
grads['b1']、grads['b2']、...是各层的偏置
"""
loss_W = lambda W: self.loss(X, T, train_flg=True)
grads = {}
for idx in range(1, self.hidden_layer_num + 2):
grads['W' + str(idx)] = numerical_gradient(loss_W, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_W, self.params['b' + str(idx)])
if self.use_batchnorm and idx != self.hidden_layer_num + 1:
grads['gamma' + str(idx)] = numerical_gradient(loss_W, self.params['gamma' + str(idx)])
grads['beta' + str(idx)] = numerical_gradient(loss_W, self.params['beta' + str(idx)])
return grads
def gradient(self, x, t):
# forward
self.loss(x, t, train_flg=True)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# 设定
grads = {}
for idx in range(1, self.hidden_layer_num + 2):
grads['W' + str(idx)] = self.layers['Affine' + str(idx)].dW + self.weight_decay_lambda * self.params[
'W' + str(idx)]
grads['b' + str(idx)] = self.layers['Affine' + str(idx)].db
if self.use_batchnorm and idx != self.hidden_layer_num + 1:
grads['gamma' + str(idx)] = self.layers['BatchNorm' + str(idx)].dgamma
grads['beta' + str(idx)] = self.layers['BatchNorm' + str(idx)].dbeta
return grads
# 加载数据
(x_train, t_train), (x_test, t_test) = get_data()
# 抽取训练数据
x_train = x_train[:1000]
t_train = t_train[:1000]
# 超参数
iter_num = 10000000
lr = 0.01
max_epochs = 201
train_size = x_train.shape[0]
batch_size = 100
def __train(weight_init_std):
bn_network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,
weight_init_std=weight_init_std, use_batchnorm=True)
network = MultiLayerNet(input_size=784, hidden_size_list=[100, 100, 100, 100, 100], output_size=10,
weight_init_std=weight_init_std)
optimizer = SGD(lr)
train_acc_list = []
bn_train_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
epoch_cnt = 0
for i in range(iter_num):
# 数据抽取
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
for _network in (bn_network, network):
grads = _network.gradient(x_batch, t_batch)
optimizer.update(_network.params, grads)
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
train_acc_list.append(train_acc)
bn_train_acc = _network.accuracy(x_train, t_train)
bn_train_acc_list.append(bn_train_acc)
print('train_acc,bn_train_acc|', str(train_acc) + str(bn_train_acc))
epoch_cnt += 1
if epoch_cnt >= max_epochs:
break
return train_acc_list, bn_train_acc_list
# 绘制图形
weight_scale_list = np.logspace(0, -4, num=16)
x = np.arange(max_epochs)
for i, w in enumerate(weight_scale_list):
print("============== " + str(i + 1) + "/16" + " ==============")
train_acc_list, bn_train_acc_list = __train(w)
plt.subplot(4, 4, i + 1)
plt.title("W:" + str(w))
if i == 15:
plt.plot(x, bn_train_acc_list, label='Batch Normalization', markevery=2)
plt.plot(x, train_acc_list, linestyle="--", label='Normal(without BatchNorm)', markevery=2)
else:
plt.plot(x, bn_train_acc_list, markevery=2)
plt.plot(x, train_acc_list, linestyle="--", markevery=2)
plt.ylim(0, 1.0)
if i % 4:
plt.yticks([])
else:
plt.ylabel("accuracy")
if i < 12:
plt.xticks([])
else:
plt.xlabel("epochs")
plt.legend(loc='lower right')
plt.show()