- df.head()/tail() 查看头/尾5条数据;
- df.info 查看表格简明概要;
- df.dtypes 查看字段数据类型;
- df.index 查看表格索引;
- df.columns 查看表格列名;
- df.values 以array形式返回指定数据的取值;
- list(dt.groupby("字段A")) groupby会把数据框按指定的字段分成几个小块,转化成列表,即可输出各部分的模块展示;
- groupby的聚合函数:
函数名 说明 count 分组中非NA值的数量 sum 非NA值的和 mean 非NA值的平均值 median 非NA值的算术中位数 std、var 无偏(分母为n-1)标准差和方差 min、max 非NA值的最小值和最大值 prod 非NA值的积 first、last 第一个或最后一个非NA值 - groupby的参数:
by:mapping, function, str, or iterable。 用于确定groupby的组。如果by是一个函数,那么会调用对象索引的每个值。如果传递了一个dict或Series,则将使用Series或dict的值来确定组。一个str或者一个strs列表可以通过自己的列传递给group。 axis:轴,int值,默认为0 level:如果axis是一个MultiIndex(分层),则按特定的级别分组。int值,默认为None as_index:对于聚合输出,返回带有组标签的对象作为索引。as_index=False实际上是“SQL风格”分组输出,boolean值,默认为True。 sort:排序。关闭此功能以获得更好的性能。boolean值,默认True。 group_keys:当调用apply时,添加group key来索引来识别片断。boolean值,默认True。 squeeze:尽可能减少返回类型的维度,否则返回一致的类型。boolean值,默认False。 -
dt.groupby(['版本','级别level','星期','时段'],as_index=False)['供应量'].count(),则可以显示excel数据透视表的功效
- dt.columns=['','','']统一赋值重命名,或者使用rename对指定列进行修改
dt.rename(columns={'供需指数':'SDI均值'},inplace=True) - 删除满足条件的行:drop删除一行的时候比较方便
fx1.drop(fx1[fx1['版本']=='进阶版LTO试听课'].index,inplace=True)
fx1=fx1.loc[(fx1['版本']!='进阶版LTO试听课'),:]
&表示并集,|表示或集,~表示与列出的条件相反,:表示希望保留所有列
- 删除满足条件的行后,重置索引:drop删除原索引,inplace替换原文件
fx1.reset_index(drop=True,inplace=True)
- 色阶配置:
import seaborn as sns # cmp=sns.light_palette('pink',as_cmap=True) # cmp=sns.color_palette('Pastel1_r',as_cmap=True) # cmp=sns.color_palette('Pastel2',as_cmap=True) cmp=sns.color_palette('Spectral',as_cmap=True) therm=df.iloc[:,:].style.background_gradient(cmap=cmp)为excel表格配置色阶,可以用iloc选择对哪些区域生效,用pd.ExcelWriter进行保存即可
- 条件格式常用:

pandas基本操作
news2026/2/11 9:45:04
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/349974.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

vue2 使用 cesium 篇
vue2 使用 cesium 篇 今天好好写一篇哈,之前写的半死不活的。首先说明:这篇博文是我边做边写的,小白也是,实现效果会同时发布截图,如果没有实现也会说明,仅仅作为技术积累,选择性分享࿰…

远程管理时代,还得是智能化PDU才靠得住!
在如今这个信息技术高速发展的时代,数据中心IDC机房服务器数量与日俱增,提供DNS域名服务、主机托管服务、虚拟主机服务等服务的服务器是IDC最基本的功能之一。服务器需要7*24小时不间断持续工作,但当服务器数量很大,服务器工作、重…
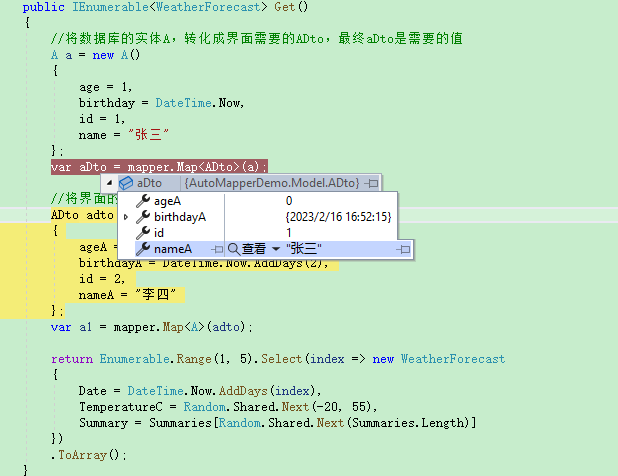
.net6API使用AutoMapper和DTO
AutoMapper,是一个转换工具,说到AutoMapper时,就不得不先说DTO,它叫做数据传输对象(Data Transfer Object)。 通俗的来说,DTO就是前端界面需要用的数据结构和类型,而我们经常使用的数据实体,是数…
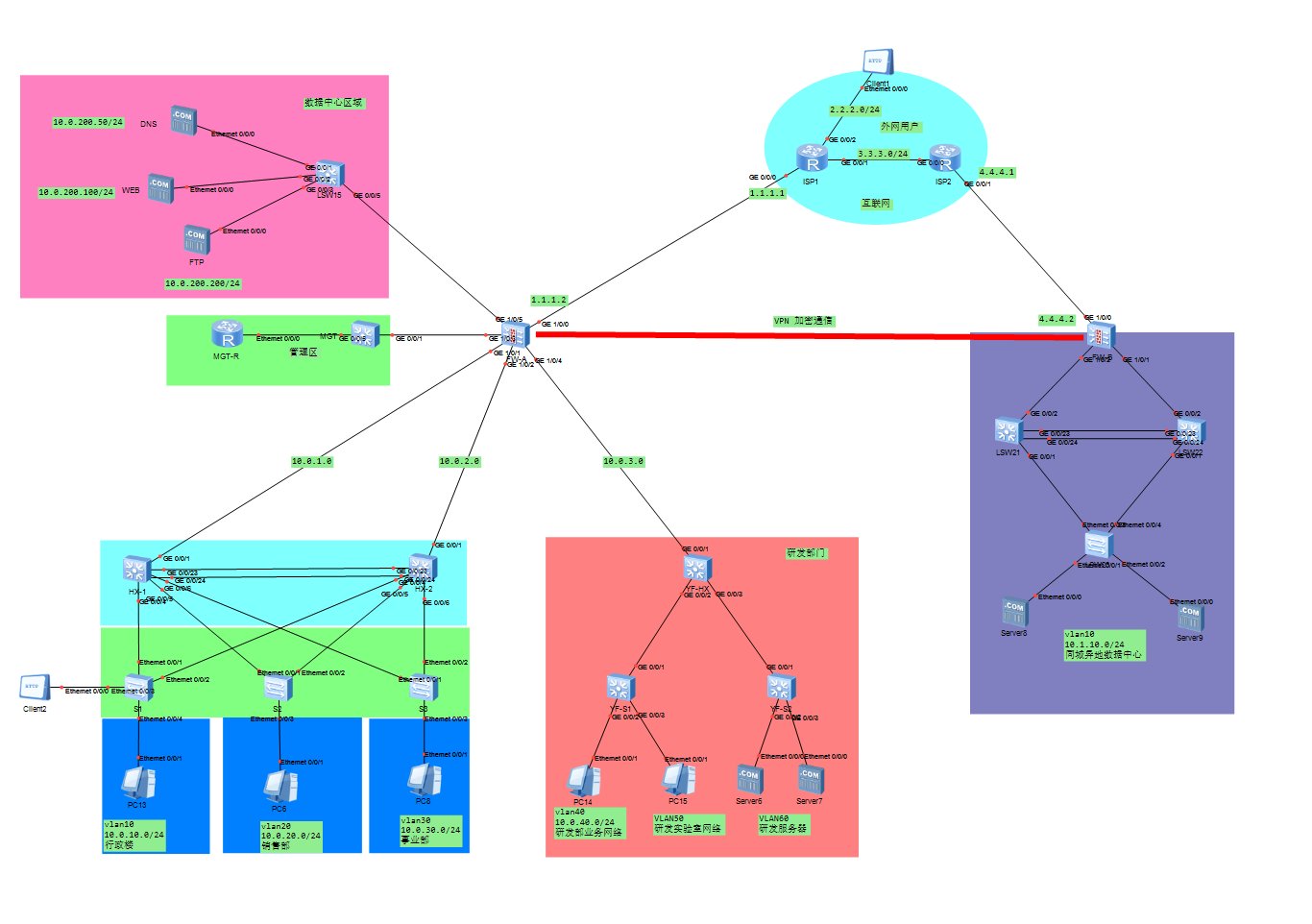
华为ensp模拟校园网/企业网实例(同城灾备及异地备份中心保证网络安全)
文章简介:本文用华为ensp对企业网络进行了规划和模拟,也同样适用于校园、医院等场景。如有需要可联系作者,可以根据定制化需求做修改。作者简介:网络工程师,希望能认识更多的小伙伴一起交流,私信必回。一、…

多元回归分析 | CNN-LSTM卷积长短期记忆神经网络多输入单输出预测(Matlab完整程序)
多元回归分析 | CNN-LSTM卷积长短期记忆神经网络多输入单输出预测(Matlab完整程序) 目录 多元回归分析 | CNN-LSTM卷积长短期记忆神经网络多输入单输出预测(Matlab完整程序)预测结果评价指标基本介绍程序设计参考资料预测结果 评价指标 训练集平均绝对误差MAE:0.69559 训练…
宝塔搭建实战php源码人才求职管理系统后台端thinkphp源码(一)
大家好啊,我是测评君,欢迎来到web测评。 在开源社区里看到了这一套系统,骑士人才系统SE版,搭建测试了,感觉很不错。能够帮助一些想做招聘平台的朋友降低开发成本,就是要注意,想商业使用的话&…
QT+OpenGL光照2
QTOpenGL材质
本篇完整工程见gitee:QtOpenGL 对应点的tag,由turbolove提供技术支持,您可以关注博主或者私信博主
材质
在现实世界中,每个物体会对光照产生不同的反应 在OpenGL中模拟多种类型的物体,必须为每种物体分别定义一个…
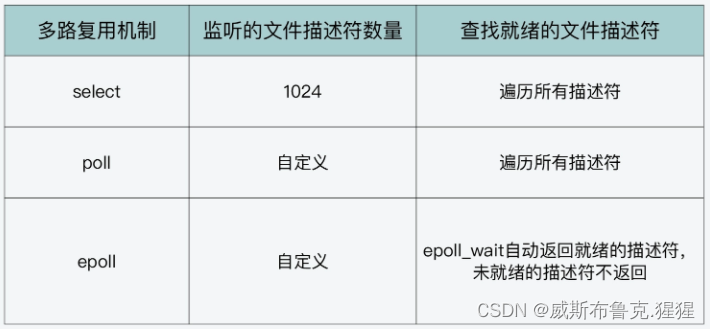
IO模型--从BIO、NIO、AIO到内核select、poll、epoll剖析
IO基本概述
IO的分类 IO以不同的维度划分,可以被分为多种类型;从工作层面划分成磁盘IO(本地IO)和网络IO; 也从工作模式上划分:BIO、NIO、AIO;从工作性质上分为阻塞式IO与非阻塞式IO;…
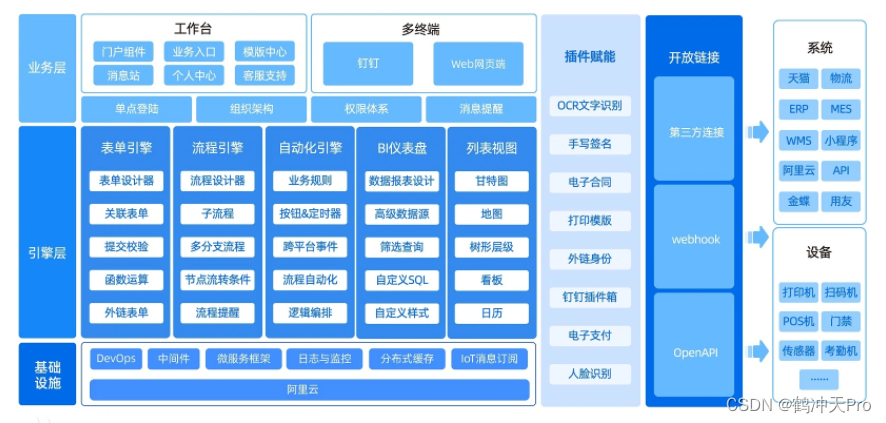
低代码/零代码的快速开发框架
目前国内主流的低代码开发平台有:宜搭、简道云、明道云、云程、氚云、伙伴云、道一云、JEPaaS、华炎魔方、搭搭云、JeecgBoot 、RuoYi等。这些平台各有优劣势,定位也不同,用户可以根据自己需求选择。
一、阿里云宜搭 宜搭是阿里巴巴集团在20…

分布式文件存储Minio学习入门
文章目录一、分布式文件系统应用场景1. Minio介绍Minio优点2. MinIO的基础概念、3. 纠删码ES(Erasure Code)4. 存储形式5. 存储方案二、Docker部署单机Minio三、minio纠删码模式部署四、分布式集群部署分布式存储可靠性常用方法冗余校验分布式Minio优势运行分布式minio使用dock…
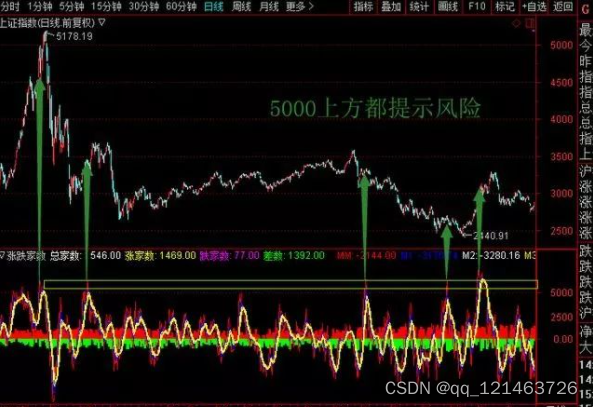
如何设置股票接口版交易软件的指标涨跌家数?
如何设置股票接口版交易软件指标涨跌家数?今天小编就以通达信为例给大家介绍一下,很多人其实不知道通达信里面有个很厉害的股票情绪的指标,叫做通达信涨跌家数,打开在通达信软件k线界面,然后输入880005就可以找到了。下…

如何解决 Python 中 TypeError: unhashable type: ‘dict‘ 错误
Python “TypeError: unhashable type: ‘dict’ ” 发生在我们将字典用作另一个字典中的键或用作集合中的元素时。
要解决该错误,需要改用 frozenset,或者在将字典用作键之前将其转换为 JSON 字符串。
当我们将字典用作另一个字典中的键时,…

AnlogicFPGA-IO引脚约束设置
(https://www.eefocus.com/article/472120.html此链接是一篇关于XillinxFPGA的IO的状态分析,希望自己也要能了解到AnLogic的IO状态并有对此问题的分析能力)
1、DriveStrength: 驱动强度,即最大能驱动的电流大小(见带负…

Project Caliper:目标是打造最佳VR手柄
一提到Valve Index,人们很快联想到它的五指追踪VR手柄,这款支持手势追踪和体感反馈的高端VR手柄,是市面上最强大的C端VR手柄之一。尽管如此,它依然存在许多缺陷,比如配备的小型摇杆质量不佳、集成式设计不利于维修、人…
算法问题——排序算法问题
摘要
查找和排序算法是算法的入门知识,其经典思想可以用于很多算法当中。因为其实现代码较短,应用较常见。所以在面试中经常会问到排序算法及其相关的问题。但万变不离其宗,只要熟悉了思想,灵活运用也不是难事。一般在面试中最常…
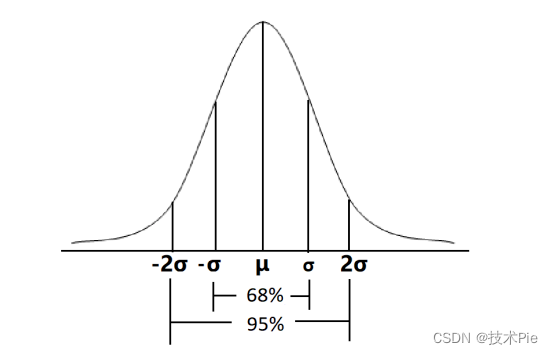
布林线(BOLL)计算公式详解,开口收口代表什么
布林带,英文名称BOLL,是John Bollinger在上世纪八十年代创建的,由中轨、上轨、下轨三条线组成。 一、布林线计算公式详解
布林线中轨是简单移动平均线,一般软件上自带的布林带中轨是20日均线,上轨是中轨加上2个标准差…
Spring 系列之FrameWork
Spring 系列文章 文章目录Spring 系列文章前言一、Spring 介绍二、Spring 架构特征三、Spring 优势四、Spring 体系结构五、IOC 控制反转1. 概念引入2. 原理分析六、Bean 管理1. 介绍2. 管理的内容3. Bean 管理方式1. XML实现DI 赋值2. Bean生命周期1. 测试生命周期2. 后置处理…

RuoYi-Vue搭建(若依)
项目简介 RuoYi-Vue基于SpringBootVue前后端分离的Java快速开发框架1.前端采用Vue、Element UI2.后端采用Spring Boot、Spring Security、Redis & Jwt3.权限认证使用Jwt,支持多终端认证系统4.支持加载动态权限菜单,多方式轻松权限控制5.高效率开发&a…

27岁想转行IT,还来得及吗?
来不来得及不还是看你自身的意愿和条件,这个问题要问你自己吧! 每个人的能力、看法都不同。面对类似的问题,很多人会把侧重点放在IT上,或者27岁上面。那么我们试着换一个方式来问呢:什么时候适合转行,有哪些…
1.PostgreSQL
文章目录LIMITWITH 和RECURSIVEPostgreSQL 约束PostgreSQL AUTO INCREMENT(自动增长)PostgreSQL PRIVILEGES(权限)GRANT语法LIMIT
SELECT * FROM COMPANY LIMIT 3 OFFSET 2;WITH 和RECURSIVE WITH RECURSIVE t(a,b) AS (VALUES (…