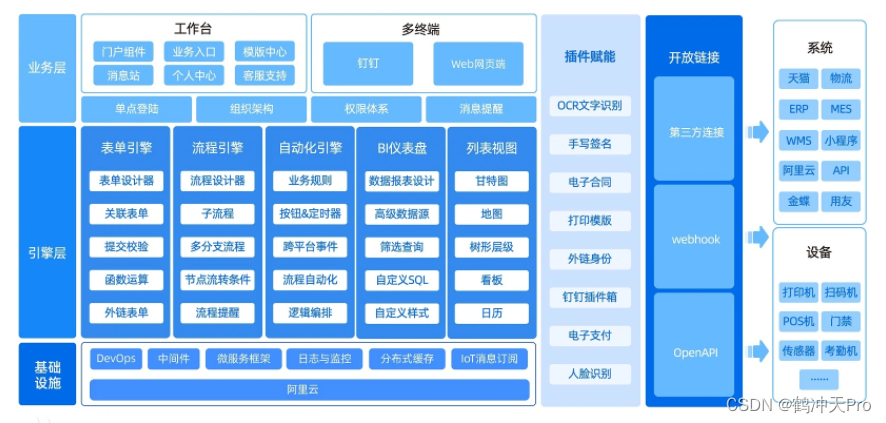
目录
- The Basic Usage of CNN
- Padding(填充)
- Weights(权重)
- Pooling
The Basic Usage of CNN
What are Convolutional Neural Networks?
They’re basically just neural networks that use Convolutional layers(卷积层), Conv layers, which are based on the mathematical operation of convolution(内积). Conv layers consist of a set of filters(卷积核), which you can think of as just 2d matrices of numbers. Here’s an example 3x3 filter:
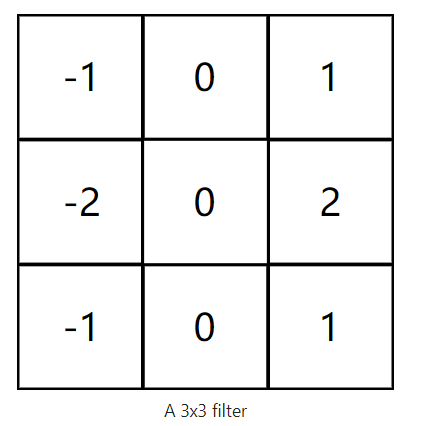
We can use an input image and a filter to produce an output image by convolving the filter with the input image. This consists of

Consider this tiny 4x4 grayscale image and this 3x3 filter:
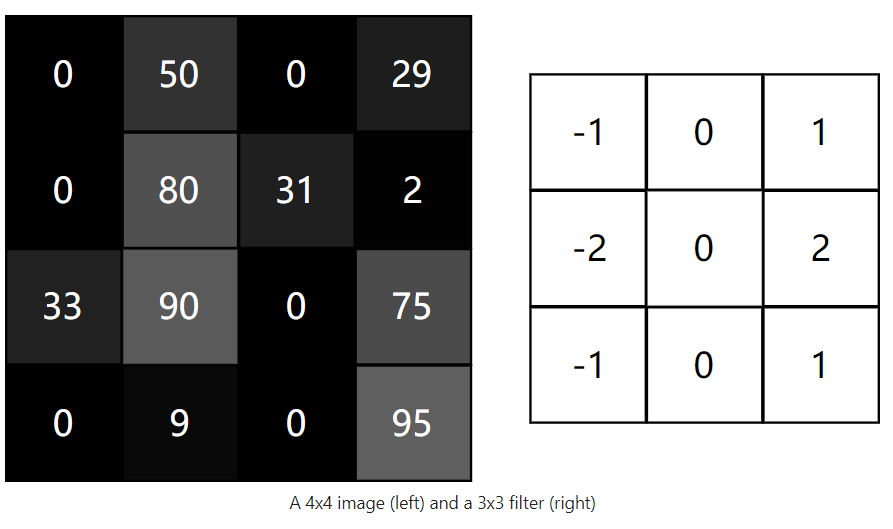
The numbers in the image represent pixel intensities, where 0 is black and 255 is white. We’ll convolve the input image and the filter to produce a 2x2 output image:

To start, lets overlay our filter in the top left corner of the image:
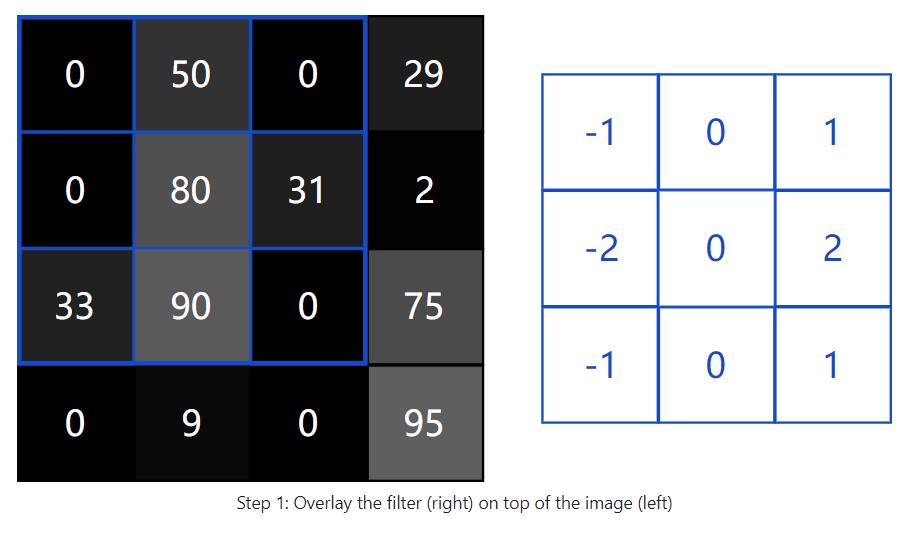
Next, we perform element-wise multiplication between the overlapping image values and filter values. Here are the results, starting from the top left corner and going right, then down:

Next, we sum up all the results. That’s easy enough:
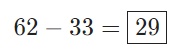
Finally, we place our result in the destination pixel of our output image. Since our filter is overlayed in the top left corner of the input image, our destination pixel is the top left pixel of the output image:
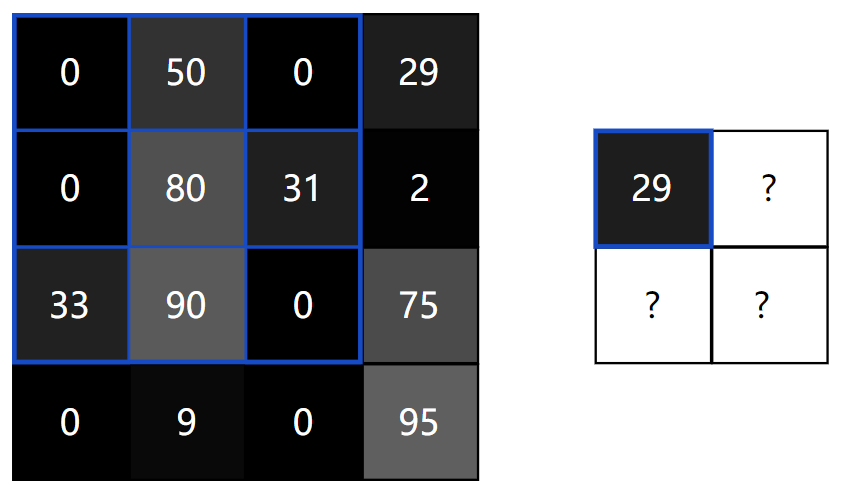
We do the same thing to generate the rest of the output image:

Padding(填充)
Remember convolving a 4x4 input image with a 3x3 filter earlier to produce a 2x2 output image? Often times, we’d prefer to have the output image be the same size as the input image. To do this, we add zeros around the image so we can overlay the filter in more places. A 3x3 filter requires 1 pixel of padding:
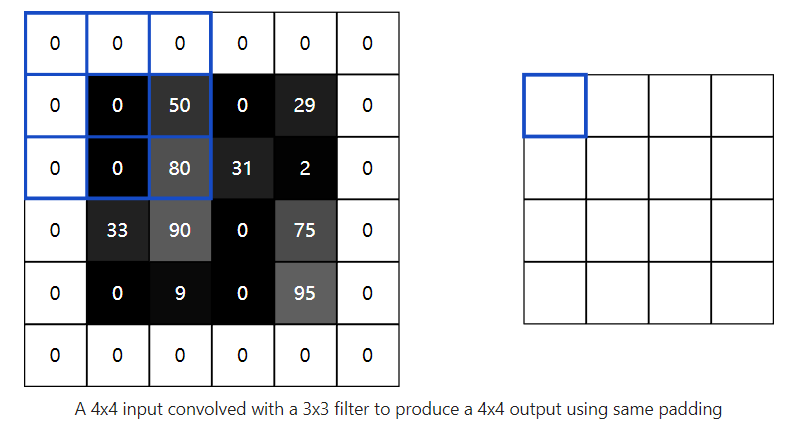
Weights(权重)
A conv layer’s primary parameter is the number of filters it has.
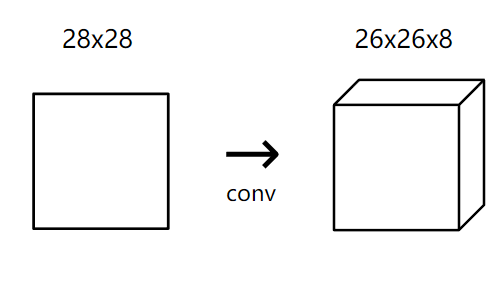
For our MNIST CNN, we’ll use a small conv layer with 8 filters as the initial layer in our network. This means it’ll turn the 28x28 input image into a 26x26x8 output volume:

Pooling
Neighboring pixels in images tend to have similar values, so conv layers will typically also produce similar values for neighboring pixels in outputs. As a result, much of the information contained in a conv layer’s output is redundant(冗余的).
Here’s an example of a Max Pooling layer with a pooling size of 2: