YOLOv3
-
预测部分
-
Darknet-53
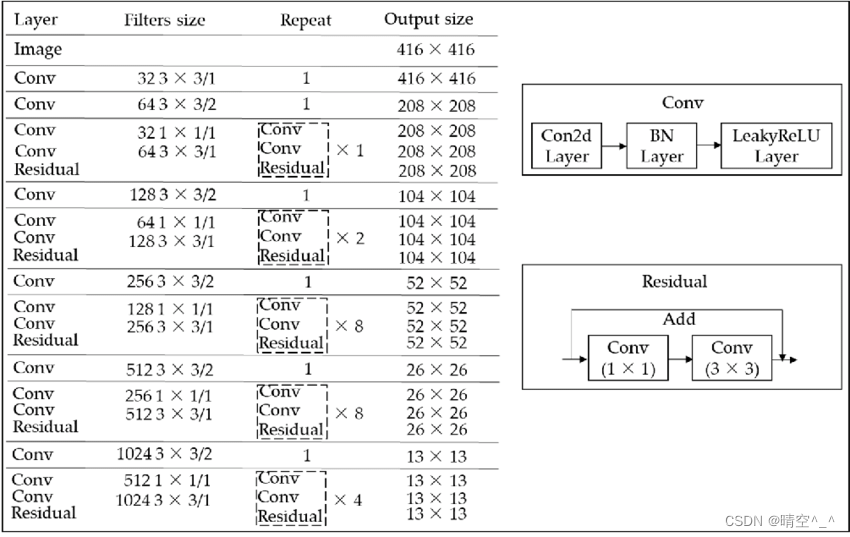
YOLOv3的主干提取网络为Darknet-53,相比于YOLOv2时期的Darknet-19,其加深了网络层数且引入了Residual残差结构。其通过不断的1X1卷积和3X3卷积以及残差边的叠加,大幅度的加深了网络。残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。
如图,一个Conv层包含一个二维卷积层,一个BatchNormalization层和一个LeakyReLU激活函数层。
BN层:
BN层解决的问题:随着神经网络深度的增加,训练越来越困难,收敛越来越慢。BN就是通过一定的规范化手段,把每层神经网络的神经元的输入值的分布强行拉回到均值为0方差为1的标准正态分布。简单理解就是把越来越偏的分布强制拉回比较标准的分布,这样神经元的输出就不会很大,并且使得激活函数的输入落在比较敏感的区域,可以得到比较大的梯度,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
从形式上来说,用 x ∈ B \mathbf{x} \in \mathcal{B} x∈B表示一个来自小批量 B \mathcal{B} B的输入,批量规范化 B N \mathrm{BN} BN根据以下表达式转换 x \mathbf{x} x:
B N ( x ) = γ ⊙ x − μ ^ B σ ^ B + β . \mathrm{BN}(\mathbf{x}) = \boldsymbol{\gamma} \odot \frac{\mathbf{x} - \hat{\boldsymbol{\mu}}_\mathcal{B}}{\hat{\boldsymbol{\sigma}}_\mathcal{B}} + \boldsymbol{\beta}. BN(x)=γ⊙σ^Bx−μ^B+β.
其中: μ ^ B \hat{\boldsymbol{\mu}}_\mathcal{B} μ^B是小批量 B \mathcal{B} B的样本均值, σ ^ B \hat{\boldsymbol{\sigma}}_\mathcal{B} σ^B是小批量 B \mathcal{B} B的样本标准差。由于单位方差是一个主观的选择,因此通常包含拉伸参数(scale) γ \boldsymbol{\gamma} γ和偏移参数(shift) β \boldsymbol{\beta} β,它们的形状与 x \mathbf{x} x相同。请注意, γ \boldsymbol{\gamma} γ和 β \boldsymbol{\beta} β是需要与其他模型参数一起学习的参数。 μ ^ B \hat{\boldsymbol{\mu}}_\mathcal{B} μ^B和 σ ^ B {\hat{\boldsymbol{\sigma}}_\mathcal{B}} σ^B,如下所示:
μ ^ B = 1 ∣ B ∣ ∑ x ∈ B x , σ ^ B 2 = 1 ∣ B ∣ ∑ x ∈ B ( x − μ ^ B ) 2 + ϵ . \begin{aligned} \hat{\boldsymbol{\mu}}_\mathcal{B} &= \frac{1}{|\mathcal{B}|} \sum_{\mathbf{x} \in \mathcal{B}} \mathbf{x},\\ \hat{\boldsymbol{\sigma}}_\mathcal{B}^2 &= \frac{1}{|\mathcal{B}|} \sum_{\mathbf{x} \in \mathcal{B}} (\mathbf{x} - \hat{\boldsymbol{\mu}}_{\mathcal{B}})^2 + \epsilon.\end{aligned} μ^Bσ^B2=∣B∣1x∈B∑x,=∣B∣1x∈B∑(x−μ^B)2+ϵ.
在方差估计值中添加一个小的常量 ϵ > 0 \epsilon > 0 ϵ>0,以确保永远不会除以零,即使在经验方差估计值可能消失的情况下也是如此。估计值 μ ^ B \hat{\boldsymbol{\mu}}_\mathcal{B} μ^B和 σ ^ B {\hat{\boldsymbol{\sigma}}_\mathcal{B}} σ^B通过使用平均值和方差的噪声(noise)估计来抵消缩放问题。LeakyReLU:
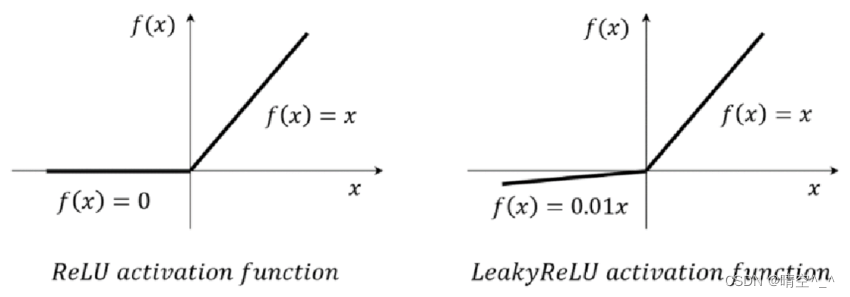
LeakyReLU与ReLU类似,区别是ReLU在值小于零为0而LeakyReLU在值为负时仍有较小的梯度。
-
FPN:
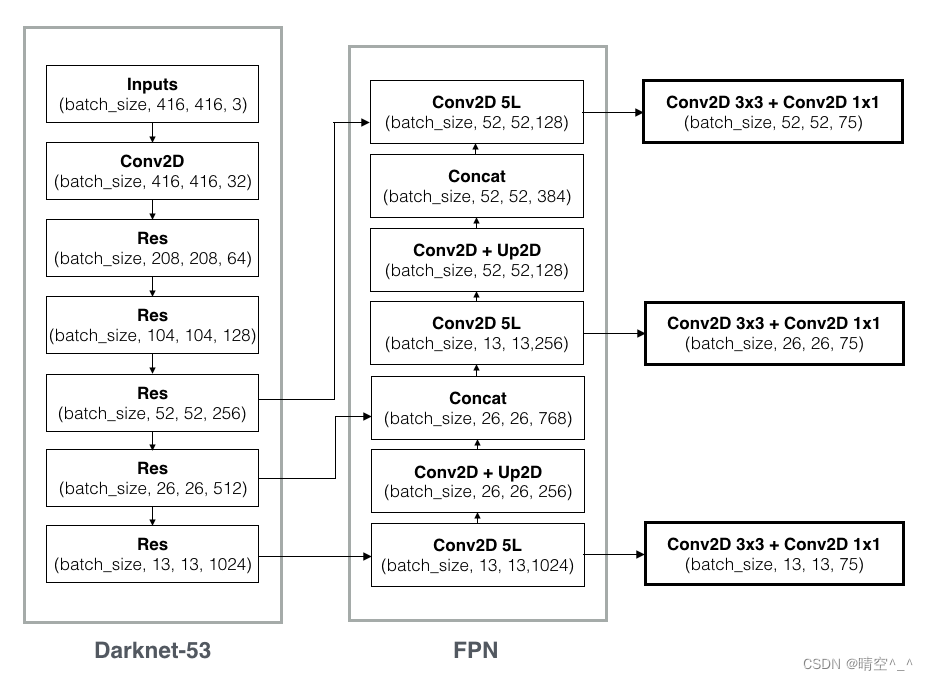
YOLOv3使用FPN特征金字塔进行特征提取,在此可以获得三个尺寸的加强特征。分别为 ( 13 , 13 , 1024 ) (13, 13, 1024) (13,13,1024)、 ( 26 , 26 , 256 ) (26, 26, 256) (26,26,256), ( 52 , 52 , 128 ) (52, 52, 128) (52,52,128)。其中第一个特征图下采样8倍,第二个特征图下采样16倍,第三个特征图下采样32倍。之后将这三个加强特征传入YOLO Head中获得预测结果。
Up2D即上采样层,作用是将小尺寸的特征图通过插值等方法生成大尺寸的特征图来进行特征融合。
concat操作来源于DenseNet网络的设计思路,其直接将特征图按通道数进行拼接。如图,concat层的最后一维通道数是水平箭头左面和竖直箭头下面最后一维通道数的和,与而加和操作 y = f ( x ) + x y=f(x)+x y=f(x)+x是完全不同的。
FPN特征金字塔使用小尺寸特征图检测大物体,大尺寸特征图检测小物体(可以理解为尺寸越小,网络的深度越深,看到的图像的面积越大,检测的物体也就越大)。
特征金字塔可以将不同shape的特征层进行特征融合,有利于提取出更好的特征。
-
预测结果解码
YOLO head本质为一个 3 × 3 3 \times 3 3×3卷积与 1 × 1 1 \times 1 1×1卷积。前者进行特征提取,后者调整通道数为75。其中 75 = 3 × ( 1 + 4 + 20 ) 75=3 \times(1+4+20) 75=3×(1+4+20)。 3 3 3代表每个位置包含三个锚框, 1 1 1代表该锚框是否包含物体, 4 4 4代表锚框的调整参数, 20 20 20代表voc数据集的类别数。(假设YOLOv3的训练数据集为VOC数据集)
在经过YOLO Head后得到三个加强特征层的预测结果,如:
- ( b a t c h _ s i e , 13 , 13 , 75 ) (batch\_sie, 13, 13, 75) (batch_sie,13,13,75)
- ( b a t c h _ s i e , 26 , 26 , 75 ) (batch\_sie, 26, 26, 75) (batch_sie,26,26,75)
- ( b a t c h _ s i e , 52 , 52 , 75 ) (batch\_sie, 52, 52, 75) (batch_sie,52,52,75)
其中,每个特征层将预测图片分成与其大小对应的网格,如$ (13, 13, 75)$就是将原图片分为 13 × 13 13 \times 13 13×13的网格,然后从网格中建立3个锚框,这些框是网络预先设定好的框,网络的预测结果会判断这些框内是否包含物体,以及这个物体的种类。因此上述结果可以reshape为:
- ( b a t c h _ s i e , 13 , 13 , 3 , 25 ) (batch\_sie, 13, 13, 3, 25) (batch_sie,13,13,3,25)
- ( b a t c h _ s i e , 26 , 26 , 3 , 25 ) (batch\_sie, 26, 26, 3, 25) (batch_sie,26,26,3,25)
- ( b a t c h _ s i e , 52 , 52 , 3 , 25 ) (batch\_sie, 52, 52, 3, 25) (batch_sie,52,52,3,25)
其中,25分别代表x_offset、y_offset、h、w、置信度和20个分类结果。
但是这个预测值并不是最终的预测结果,还需要进行解码。
锚框解码:
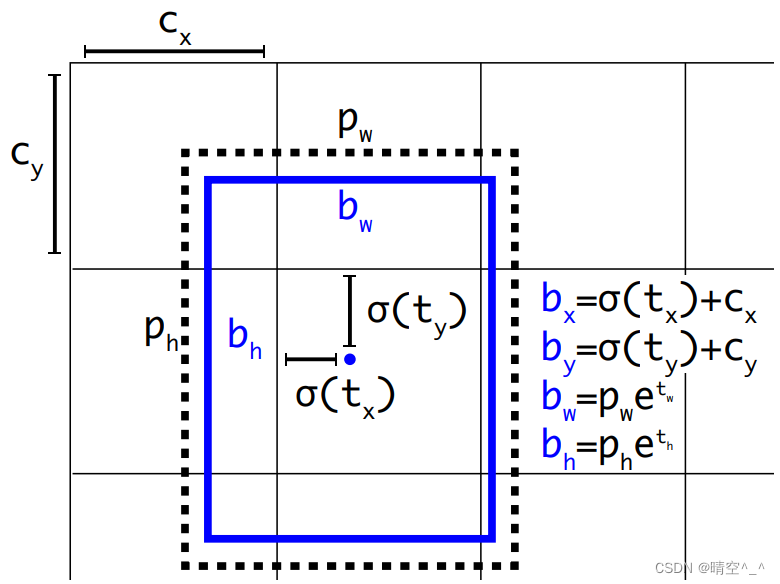
- 每个网格点加上其对应的x_offset和y_offset,结果就是预测框的中心。
- 之后利用锚框和h、w结合计算出预测框的宽高,这样就得到整个预测框的位置。
如图, σ ( t x ) \sigma(t_x) σ(tx)、 σ ( t y ) \sigma(t_y) σ(ty)是基于矩形框中心点左上角格点坐标的偏移量。 σ \sigma σ是sigmoid激活函数。 p w p_w pw、 p h p_h ph是锚框的宽和高。
置信度解码:
置信度25维中占固定一位,使用sigmoid进行映射,使结果在[0, 1]之间。
类别解码:
类别数在25维中占20维,每一维独立代表一个类别。
-
使用sigmoid替代softmax取消类别之间的互斥,使网络更加的灵活。
-
三个特征图一共可以解码出 8 × 8 × 3 + 16 × 16 × 3 + 32 × 32 × 3 = 4032 个box以及相应的类别、置信度。这4032个box,在训练和推理时,使用方法不一样:
-
训练时4032个box全部送入打标签函数,进行后一步的标签以及损失函数的计算。
-
预测时,选取一个置信度阈值,过滤掉低阈值box,再经过nms(非极大值抑制),就可以输出整个网络的预测结果了。
非极大抑制的简单理解就是:当有许多锚框时,可能会输出许多相似的具有明显重叠的预测边界框,都围绕着同一目标。为了简化输出,可以使用非极大值抑制(non-maximum suppression,NMS)合并属于同一目标的类似的预测边界框。
-
解码后就可以得到最终的预测框位置与类别并将其绘制在原图中。
-
-
训练部分
-
训练策略:
-
预测框一共分为三种情况:正例(positive)、负例(negative)和忽略样例(ignore)。
-
正例:任取一个ground truth(标签),与4032个框全部计算IOU,IOU最大的预测框,即为正例。并且一个预测框,只能分配给一个ground truth。例如第一个ground truth已经匹配了一个正例检测框,那么下一个ground truth,就在余下的4031个检测框中,寻找IOU最大的检测框作为正例。ground truth的先后顺序可忽略。正例产生置信度loss、检测框loss、类别loss。预测框为对应的ground truth box标签(需要反向编码,使用真实的x、y、w、h计算出 t x . t y , t w , t h t_x. t_y, t_w, t_h tx.ty,tw,th);类别标签对应类别为1,其余为0;置信度标签为1。
-
忽略样例:正例除外,与任意一个ground truth的IOU大于阈值(论文中使用0.5),则为忽略样例。忽略样例不产生loss。
作用:由于Yolov3使用了多尺度特征图,不同尺度的特征图之间会有重合检测部分。比如有一个真实物体,在训练时被分配到的检测框是特征图1的第三个box,IOU达0.98,此时恰好特征图2的第一个box与该ground truth的IOU达0.95,也检测到了该ground truth,如果此时给其置信度强行打0的标签,网络学习效果会不理想。
-
负例:正例除外(与ground truth计算后IOU最大的检测框,但是IOU小于阈值,仍为正例),与全部ground truth的IOU都小于阈值(0.5),则为负例。负例只有置信度产生loss,置信度标签为0。
-
-
Loss函数
最终损失由三个部分组成:
- 正例,编码后的长宽与x、y轴偏移量与预测框的差值。
- 正例,预测结果置信度的值与1的对比;负例,预测结果置信度的值与0对比。
- 实际存在的框,种类预测结果与实际结果的对比。
最终的Loss为以上三个Loss相加。
其中,x、y、w和h使用MSE(或smooth L1 Loss)作为损失函数;置信度、类别标签由于是0、1二分类使用交叉熵作为损失函数。
-