目录
缓存穿透-总结
出现场景:
解决方法:
方法1.缓存空对象:
方法2.加一个布隆过滤器:
总结:
缓存穿透-总结
出现场景:
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效。如果有恶
意用户构建并发线程一直故意请求缓存和数据库中都不存在的数据的话,那么这些请求一直都会打
到数据库,就会造成缓存穿透问题。
解决方法:
方法1.缓存空对象:
思路总结:
当我们查询Redis缓存没有查询到,并且查询数据库没有查询到对应数据时,我们在Redis缓存一个null。当出现上述的情况时,就会直接返回一个null。目的就是为了进行避免多次甚至更多次的恶意请求导致一直访问攻击数据库 ,导致缓存穿透。
优点:
实现简单,维护方便。
缺点:
(1) 额外的内存消耗
分析:
我们想要查询一个id对应在数据库中的数据,当我们查询Redis缓存中没有时,数据库中进行查询也没有对应请求想要查询的数据,此时就会返回一个null值给客户端。
我们可以在redis缓存中给对应id进行缓存一个对应的null(垃圾数据),当下一次再请求相同的id对应的数据时,直接返回缓存中对应存储的null值即可。
但是会产生额外的内存消耗,因为可能客户端恶意请求数据库中其它不存在的id,这样我们就需要缓存多个null在缓存中,多个null对应多个数据库中不存在的数据值。
因此我们可以进行设定TTL这个exprie方法对应的失效时间。我们尽可能的缩短这个TTL对应的时间,这样一段时间没有命中缓存中某一个null值后,该null值就会失效,减小一点额外内存的消耗。
(2) 可能造成短期的不一致
分析:
我们可以在redis缓存中给对应id进行缓存一个对应的null(垃圾数据),当下一次再请求相同的id对应的数据时,直接返回缓存中对应存储的null值即可。
但是在缓存一个null之后,我们对请求的这个数据 对应在数据库中进行了更新操作。意思就是可以在数据库查询到id对应到数据库的数据 ,但是我们是先访问redis缓存的,所以就直接返回null。
这可能会导致短期的不一致。因此我们可以尽可能的缩短缓存null的TTL 缓存销毁时间。
方法2.加一个布隆过滤器:
布隆过滤器原理:
(1) 布隆过滤器是一种占用内存少,时间复杂度低的数据结构,当需要存储并访问海量数据的时候,我们通常使用布隆过滤器来取代替哈希表。
哈希表查询复杂度为O(1)级别,为什么在存储并访问海量数据时采用布隆过滤器呢?
因为哈希表的空间利用率低,存储等量的数据,但是需要占用较大的内存。之所以哈希表需要大量的内存占用是为了降低哈希冲突。举个例子:可能整一个哈希表只存储两个元素,但是哈希数组的长度就可能达到20,甚至更多。
(2) 布隆过滤器的底层是一个二级制的数组,这个数组是二进制的就可以说明它十分节省内存。
(3) 布隆过滤器优缺点:
优点:空间内存利用效率和查询数据的效率都远远超过一般的算法
缺点:有一定的误判率
(4) 结合这个缓存穿透的案例进行说明:
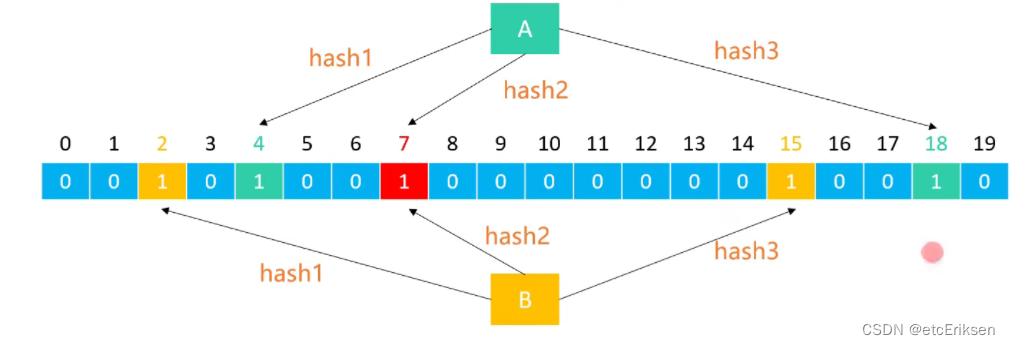
如下图:假设说布隆过滤器是由一个20位二进制,3个哈希函数组成的。
注释:A和B都是数据库中的数据值,这里只列出了A和B进行参考
步骤:
(1) 添加数据库中所有数据到布隆过滤器中:
数据库中的每一个数据元素经过这三个哈希函数处理运算后都能生成一个对应的索引位置。将每一个哈希函数生成的索引位置都设为1。
(2) 当客户端查询某一个数据,在访问缓存和数据库之前,都会优先去访问布隆过滤器:
如果客户端进行查询的某一个数据,它对应有一个哈希函数生成的索引位置处的二进制位的值不为1,就代表不存在。(100%正确)
分析:如果有一个索引位置对应的二进制值不为1,说明一定不存在。
如果客户端进行查询的某一个数据,它对应每一个哈希函数生成的索引位置处的二进制位的值都为1,就代表可能存在。
分析:为什么是可能存在?因为可能一个索引位置不止有一个数据元素进行指向引用,如图A和B就对7号位置进行了同时引用,即使A或B删除了一个,7号位置的值还是1。那么假设说数据库中有海量数据呢?这个同时引用的概率又大大的提升了。
(5) 添加,查询的时间复杂度都是:O(k),k是哈希函数的个数。空间复杂度是:O(m),m是二进制位的个数。
(6) 为什么布隆过滤器不适合删除元素?
因为哈希函数生成值具有随机性,可能一个二进制位置可能会有多个元素指向引用。(如:索引为7处的二进制位被元素A和B同时指向)。
那么当我们对元素B进行删除时,对于该元素的所有哈希指向的二进制位的值都需要改为0。但是元素A还是指向该二进制位置的,那么当我们判断A是否存在时就会产生误判,会判断出元素A是不存在的!
(7)布隆过滤器是不存储数据本身的,只是判断数据是否存在的性能比较优越。
思路总结:
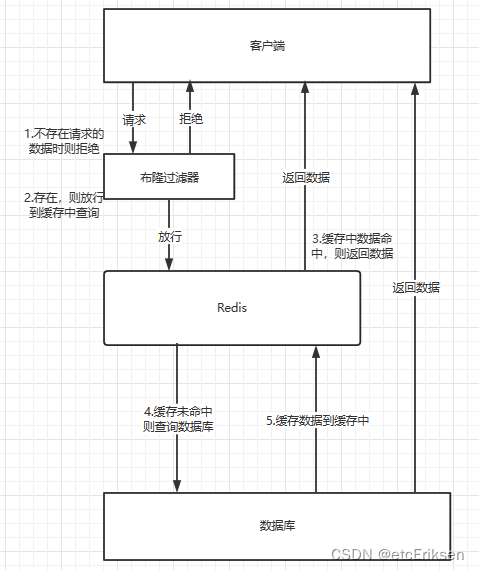
(1) 在客户端和Redis之间加一个布隆过滤器,该布隆过滤器会把数据库中的所有数据都进行记录【具体如何记录的,见上布隆过滤器原理(4)-添加元素的讲解】。
(2) 当客户端进行请求一个数据时,优先访问布隆过滤器,若布隆过滤器判断出该数据是不存在的,那么直接拒绝该请求。如果判断该数据存在,那么放行该请求。【布隆过滤器是不存储数据本身的,只是判断数据是否存在的性能比较优越并且布隆过滤器说该数据存在是具有一定误差的,所以不可以直接返回数据】
(3) 放行后,查询缓存,缓存命中,直接返回数据。缓存未命中,查询数据库。
(4) 查询数据库,查询到,缓存数据到缓存中,并且返回数据。数据库查询不到,结果还是造成了缓存穿透。
(5)由此可见,使用布隆过滤器是具有一定风险的。
优点:
占用内存较少
分析:它无需多余内存的消耗,只需要搞一个布隆过滤器,该布隆过滤器负责对数据库减压。
缺点:
同样会存在一些误差
分析:如果布隆过滤器判断出某个数据是不存在的,那么该数据一定是不存在的。但是要判断出某个数据是存在的,那么该数据可能是不存在的。
总结:
(1) 无论是方法1还是方法2,都是被动的解决方案,当缓存穿透的问题出现后进行被动的处理
对于这两种方法:方法2存在误判可能性,所以开发时使用方法1。
(2) 但是我们可以在出现缓存穿透这一问题之前,进行主动解决:
1.可以增加id的复杂度,这样可以避免恶意用户轻易的猜到id的规律
2.可以做好对数据的基础格式校验
3.加强用户权限的校验
4.做好热点参数的限流,对热数据进行限流,降低缓存穿透的概率
总结不易,期待三连。