1.查看当前值
show variables like '%join_buffer_size%'
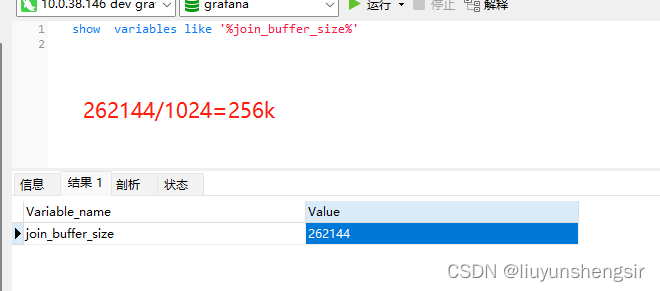
mysql默认该设置为128 或 256 或512k,各个版本有所出入
2.作用范围
在mysql中表和表进行join时候,无论是两个表之间还是多个表之间,join的情况大致分为下面几种情况
-
join key 有索引 或者是主键
-
join key 有索引,但是属于二级索引
-
join可以没有索引
join-buffe_size 真正起作用的是前面提到的 第 2 和3中情况,即表之间关联需要进行表扫描操作,而如果关联的
key使用有索引 或主键的是不需要用到join_buffer_size的,因为本身走索引效果更好
3.如何起作用
在mysql中两个表之间关联的关联算法只有 迭代循环这个算法,而join_buffer_size就是在迭代循环没有索引的情况下,减少过多的表扫描而设计的,关于表关联算法大概有下面几种
-
Nested-loop join
-
merge join
-
Hash join
正如前面说的mysql现在是只有nested-loop,后续会有新的算法,8.0已经引入了hash,而针对迭代算法,如果在有索引的情况下肯定是非常快的(前提是两表都不大,或至少有一个小表),一般会将数据量小的表称为驱动表或外表,从小表中取数据在大表中进行匹配,大概意思我们看下面的图
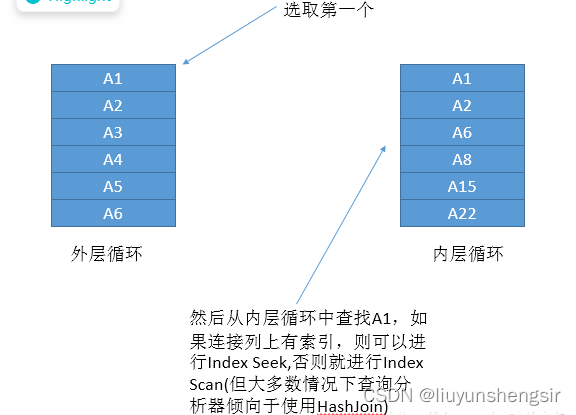
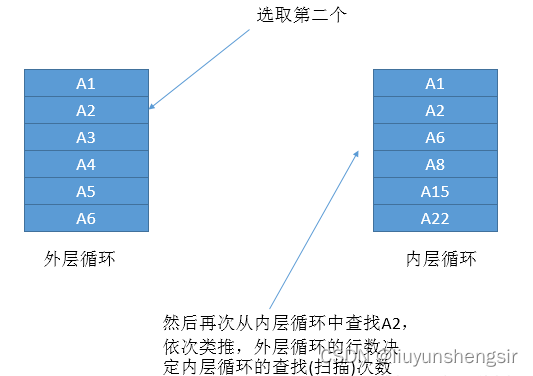
我们假设 a 表 1000条记录 b表100000条记录,那么针对下面的sql(关联key没有索引或主键)
select * from a
inner join b on a.id=b.id
我们需要依次从a表中取1000次记录,并将这些记录在b表中遍历1000次,假设b表的数据是上千万,
那么我们需要对b表进行1000次的scan,效率会差的要命。
Block Nested-Loop Join
块嵌套循环,简称 BNLJ,这个看起来比普通的Nested-loop 多了一个block,没错就是块,通俗来讲就是每次别一条条的去内表遍历了,每次整个1000条去遍历多好,我们如果每次是1000条那么上面的的sql语句的遍历次数就会从1000次直接降低到1次,理论上性能提高了将近1000倍,但是决定你去内表迭代的条数可不是随心所欲的,肯定有个地方要进行限制,毕竟一条和1千条使用的内存是不同的,ok这里就是join_buffer_size该起作用的时候了,我们通过设置该值大小来控制能有多少条记录统一一次去进行遍历操作,而不是每次一条。
4.使用建议
不建议在系统级别对该值设置过大,一般可以设置512K以内,因为最终解决方案还是要依靠索引来解决,当然不排除
有时候两个表关联的确是没有索引可用的,那我们可以在session级别来调大该值,以便能快速获得我们所需数据
比如设置session 中该值为512M,语句如下
set session join_buffer_size =10241024512;
当然这些在sql server 或orale 中都是优化过的了,不用我们过多关注,比如sql server直接将小表加入到内存中去