文章目录
- 为什么分库分表
- 一、垂直分片、水平分片
- 二、常用的数据分片策略
- 三、垂直分表、垂直分库、水平分库、水平分表
- 四、垂直切分、水平切分优缺点
- 五、数据分片规则
- 六、分库分表带来的问题
本文参考
博主「小Y是我的」的文章,原文链接:https://blog.csdn.net/m0_48383346/article/details/116999608
博主「勤天」的文章,原文链接:https://blog.csdn.net/demored/article/details/123371982
为什么分库分表
随着平台的业务发展,数据可能会越来越多,甚至达到亿级。以MySQL为例,单库数据量在5000万以内性能比较好,超过阈值后性能会随着数据量的增大而明显降低。单表的数据量超过1000w,性能也会下降严重。这就会导致查询一次所花的时间变长,并发操作达到一定量时可能会卡死,甚至把系统给拖垮
我们是否可以通过提升服务器硬件能力来提高数据处理能力?能,但是这种方案很贵,并且提高硬件是有上限的。那我们能不能把数据分散在不同的数据库中,使得单一数据库和表的数据量变小,从而达到提升数据库操作性能的目的? 可以,这就是数据库分库分表。
分库分表就是把较大的数据库和数据表按照某种策略进行拆分。目的在于:降低每个库、每张表的数据量,减小数据库的负担,提高数据库的效率,缩短查询时间。另外,因为分库分表这种改造是可控的,底层还是基于RDBMS,因此整个数据库的运维体系以及相关基础设施都是可重用的。
一、垂直分片、水平分片
垂直(纵向)分片:按照业务维度将表拆分到不同的数据库中,专库专用,分担数据库压力(提高IO性能)。
水平(横向)分片:按某种规则将单表数据拆分到多张表中。从理论上突破了单机数据量的瓶颈,是分库分表的标准解决方案。
- 垂直切分的最大特点就是规则简单,实施也更为方便,尤其适合各业务之间的耦合度非常低。相互影响非常小,业务逻辑非常清晰的系统。在这样的系统中,能够非常easy做到将不同业务模块所使用的表分拆到不同的数据库中。依据不同的表来进行拆分。对应用程序的影响也更小,拆分规则也会比較简单清晰。
- 水平切分于垂直切分相比。相对来说略微复杂一些。由于要将同一个表中的不同数据拆分到不同的数据库中,对于应用程序来说,拆分规则本身就较依据表名来拆分更为复杂,后期的数据维护也会更为复杂一些。
- 当我们某个(或者某些)表的数据量和访问量特别的大,通过垂直切分将其放在独立的设备上后仍然无法满足性能要求,这时候我们就必须将垂直切分和水平切分相结合。先垂直切分,然后再水平切分。才干解决这样的超大型表的性能问题。
二、常用的数据分片策略
- 取模分片:取模算法来分片,如:id%2=1的一起, id%2=0的一起
优点:数据存放比较均匀。
缺点:扩容需要大量数据迁移。 - 按范围分片
优点:扩容不需要迁移数据。
缺点:数据存放不均匀,容易产生数据倾斜。 - 根据业务场景,灵活定制分片策略。
三、垂直分表、垂直分库、水平分库、水平分表
垂直切分可以分为: 垂直分库和垂直分表,水平切分可以分为:水平分库和水平分表。
-
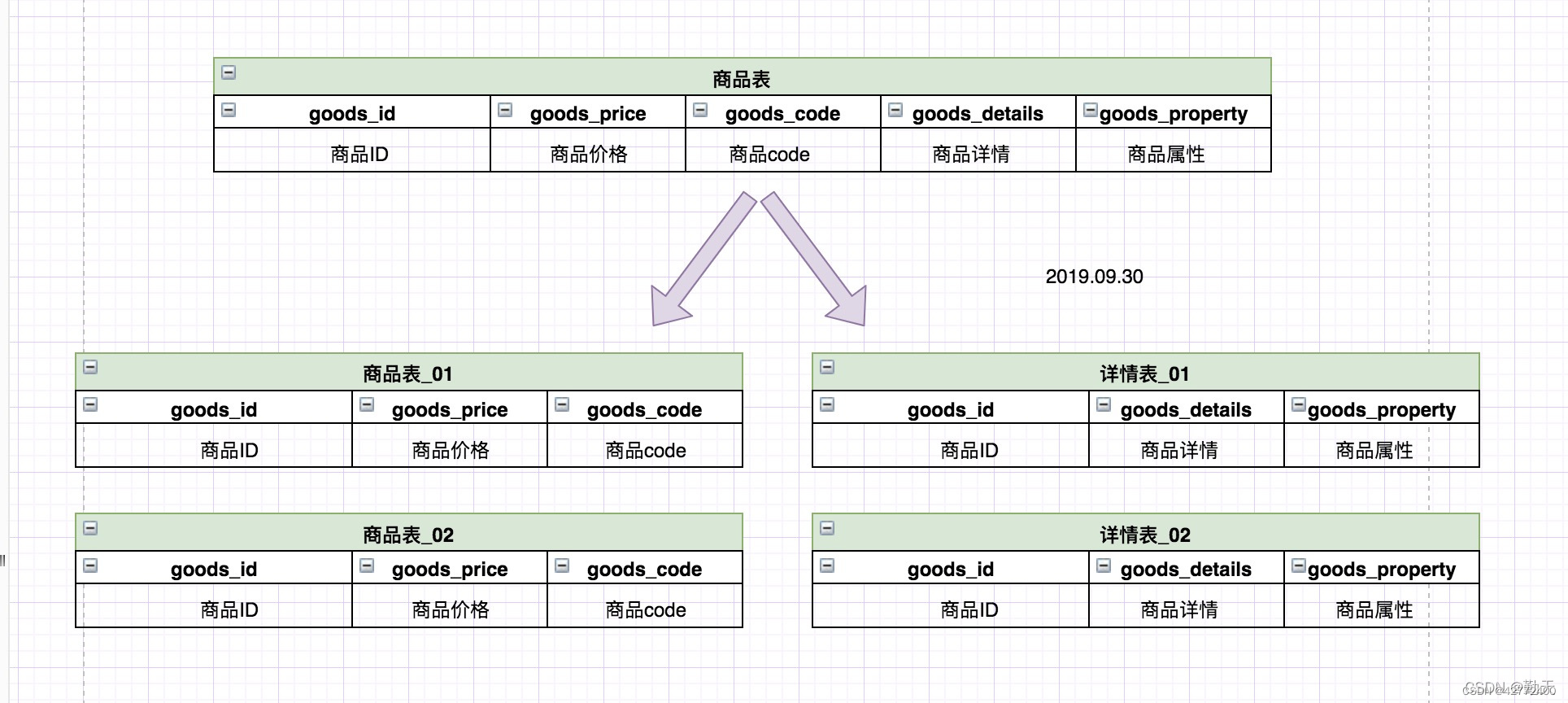
垂直分表:可以把一个宽表的字段按访问频次、业务耦合松紧、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。

说明:一开始商品表中包含商品的所有字段,但是我们发现:
(1)商品详情和商品属性字段较长。
(2)商品列表的时候我们是不需要显示商品详情和商品属性信息,只有在点进商品商品的时候才会展示商品详情信息。
所以可以考虑把商品详情和商品属性单独切分一张表,提高查询效率。 -
垂直分库:可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。

-
水平分库:可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题。

-
水平分表:可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。若数据量极大,且持续增长,再考虑水平分库分表方案。
四、垂直切分、水平切分优缺点
- 垂直切分优缺点
-
优点:解决业务系统层面的耦合,业务清晰 - 与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等 - 高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈
-
缺点:分库后无法Join,只能通过接口聚合方式解决,提升了开发的复杂度 - 分库后分布式事务处理复杂 - 依然存在单表数据量过大的问题(需要水平切分)
- 水平切分优缺点
-
优点:不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力 - 应用端改造较小,不需要拆分业务模块
-
缺点:跨分片的事务一致性难以保证 - 跨库的Join关联查询性能较差 - 数据多次扩展难度和维护量极大
五、数据分片规则
我们我们考虑去水平切分表,将一张表水平切分成多张表,这就涉及到数据分片的规则,比较常见的有:
- Hash取模分表
- 数值Range分表
- 一致性Hash算法分表
- Hash取模分表
概念 一般采用Hash取模的切分方式,例如:假设按goods_id分4张表。(goods_id%4 取整确定表)
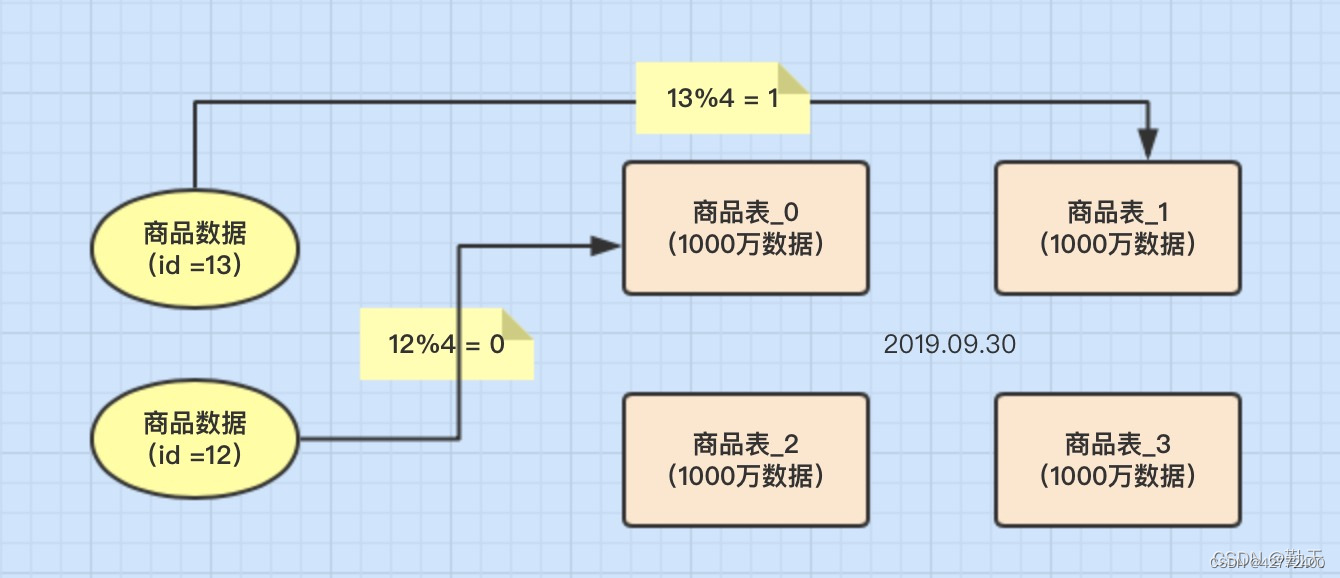
- 优点:数据分片相对比较均匀,不容易出现热点和并发访问的瓶颈。
- 缺点:后期分片集群扩容时,需要迁移旧的数据很难。 - 容易面临跨分片查询的复杂问题。
比如上例中,如果频繁用到的查询条件中不带goods_id时,将会导致无法定位数据库,从而需要同时向4个表发起查询,再在内存中合并数据,取最小集返回给应用,分库反而成为拖累。
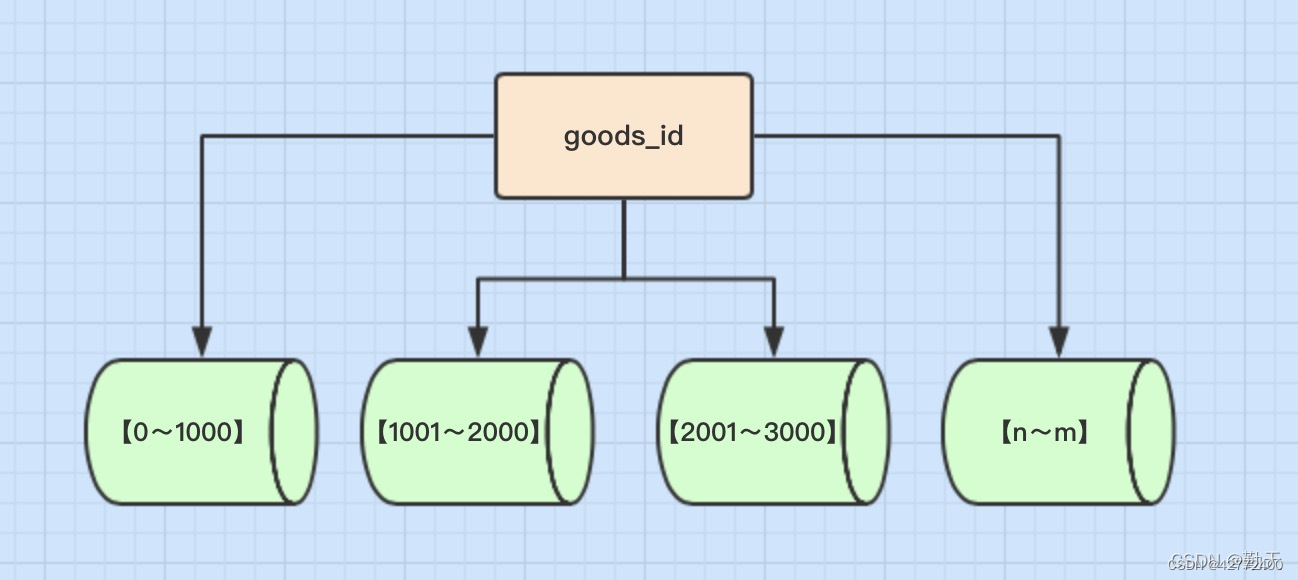
- 数值Range分表
概念 按照时间区间或ID区间来切分。例如:将goods_id为11000的记录分到第一个表,10012000的分到第二个表,以此类推。
-
优点:单表大小可控 - 天然便于水平扩展,后期如果想对整个分片集群扩容时,只需要添加节点即可,无需对其他分片的数据进行迁移 - 使用分片字段进行范围查找时,连续分片可快速定位分片进行快速查询,有效避免跨分片查询的问题。
-
缺点: 热点数据成为性能瓶颈。
例如:按时间字段分片,有些分片存储最近时间段内的数据,可能会被频繁的读写,而有些分片存储的历史数据,则很少被查询
- 一致性Hash算法
一致性Hash算法能很好的解决因为Hash取模而产生的分片集群扩容时,需要迁移旧的数据的难题。
六、分库分表带来的问题
分库分表有效的缓解了大数据、高并发带来的性能和压力,也能突破网络IO、硬件资源、连接数的瓶颈,但同时也带来了一些问题。
- 事务一致性问题
由于分库分表把数据分布在不同库甚至不同服务器,不可避免会带来分布式事务问题,我们需要额外编程解决该问题。 - 跨节点join
在没有进行分库分表前,我们检索商品时可以通过以下SQL对店铺信息进行关联查询:
SELECT p.*,s.[店铺名称],s.[信誉]
FROM [商品信息] p
LEFT JOIN [店铺信息] s ON p.id = s.[所属店铺]
WHERE...ORDER BY...LIMIT...
但经过分库分表后,**[商品信息]和[店铺信息]**不在一个数据库或一个表中,甚至不在一台服务器上,无法通过sql语句进行关联查询,我们需要额外编程解决该问题。
- 跨节点分页、排序和聚合函数
跨节点多库进行查询时,limit分页、order by排序以及聚合函数等问题,就变得比较复杂了。需要先在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序。例如,进行水平分库后的商品库,按ID倒序排序分页,取第一页:
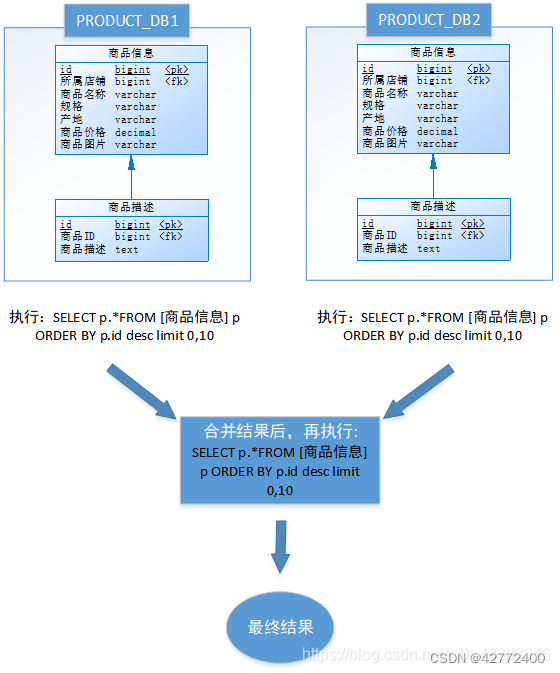
以上流程是取第一页的数据,性能影响不大,但由于商品信息的分布在各数据库的数据可能是随机的,如果是取第N页,需要将所有节点前N页数据都取出来合并,再进行整体的排序,操作效率可想而知,所以请求页数越大,系统的性能也会越差。
在使用Max、Min、Sum、Count之类的函数进行计算的时候,与排序分页同理,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终将结果返回。
- 主键避重
在分库分表环境中,由于表中数据同时存在不同数据库中,主键值平时使用的自增长将无用武之地,某个分区数据库生成的ID无法保证全局唯一。因此需要单独设计全局主键,以避免跨库主键重复问题。

由于分库分表之后,数据被分散在不同的服务器、数据库和表中。因此,对数据的操作也就无法通过常规方式完成,并且它还带来了一系列的问题。我们在开发过程中需要通过一些中间件解决这些问题,市面上有很多中间件可供我们选择,其中Sharding-JDBC和mycat较为流行。