1、spark history 和 yarn history 的区别?
Spark History Server 和 YARN History Server 是用于查看和分析Spark和YARN 应用程序的执行情况的两个不同的工具。
Spark历史服务器是专门用于Spark应用程序的工具,它提供了一个界面,可以查看Spark应用程序的执行情况,包括执行时间、阶段状态、任务信息等。
YARN历史服务器是一个针对YARN(Hadoop生态系统中的资源管理器)应用程序的工具。它提供了一个界面,可以查看YARN应用程序的执行情况,包括使用的资源、任务执行时间等。
因此,Spark历史服务器专门用于Spark应用程序,而YARN历史服务器专门用于YARN应用程序。如果你想要查看和分析Spark应用程序的执行情况,则应使用Spark历史服务器;如果你想要查看和分析YARN应用程序的执行情况,则应使用YARN历史服务器。
2、SparkHistoryServer是否可以独立启动?
spark history server 使用时需要先开启 yarn history server吗?
不需要。Spark历史服务器是独立于YARN历史服务器运行的。你可以在不开启YARN历史服务器的情况下使用Spark历史服务器,也可以在开启YARN历史服务器的情况下使用Spark历史服务器。它们之间没有直接关系。
注意:如果你使用的是Spark on YARN模式,则需要配置Spark历史服务器以访问YARN历史服务器上的日志,以便能够查看Spark on YARN应用程序的执行情况。
3、sparkHistoryServer中查看executor日志为何要跳转到MR-HistoryServer?
虽然spark和MR的模型不同,都有自己的historyserver, 但是有一个是相通的,就是都是在YARN上运行, 每个container有统一的日志存放地址;
YARN在这里做了一个容易让人混淆的事情,就是YARN把container日志查询和查看的方式,做到MR的historyserver中了.
相当于是MR的historyserver提供了一个功能: 根据containerid或者applicationid,查询日志.
所以,YARN提供了yarn.log.server.url参数,指定查询日志的url,就是下面的配置:
<property>
<name>yarn.log.server.url</name>
<value>http://localhost:19888/jobhistory/logs/</value>
</property>
由于是YARN提供的,所以这个配置项放在: yarn-site.xml里.
所以,就好理解官方文档中如下的话了:
1 The logs are also available on the Spark Web UI under the Executors Tab.
这些日志也可以在Spark Web UI的Executors选项卡下找到。
2 You need to have both the Spark history server and the MapReduce history server running and configure yarn.log.server.url in yarn-site.xml properly. The log URL on the Spark history server UI will redirect you to the MapReduce history server to show the aggregated logs.
您需要运行Spark历史服务器和MapReduce历史服务器,并在yarn-site.xml中正确配置yarn.log.server.url。Spark历史服务器UI上的日志URL会将您重定向到MapReduce历史服务器,以显示聚合的日志。
如果配置了上面的参数, 在Spark的history server中的"Executors"Tab页面, 可以帮你重定向到MapReduce history server中以及聚合的日志.
4、如何配置SparkHistoryServer?
配置spark-defualt.conf文件
spark.eventLog.enabled true
spark.eventLog.dir hdfs://bigdataha/bdp/eventLog
注意 spark.eventLog.dir 需要我们手动创建,最好chmod一下权限
如果集群hadoop环境需要kerberos认证,参考官网配置:https://spark.apache.org/docs/3.3.1/monitoring.html#spark-history-server-configuration-options
5、启停spark history server 服务
sh sbin/start-history-server.sh
sh sbin/stop-history-server.sh
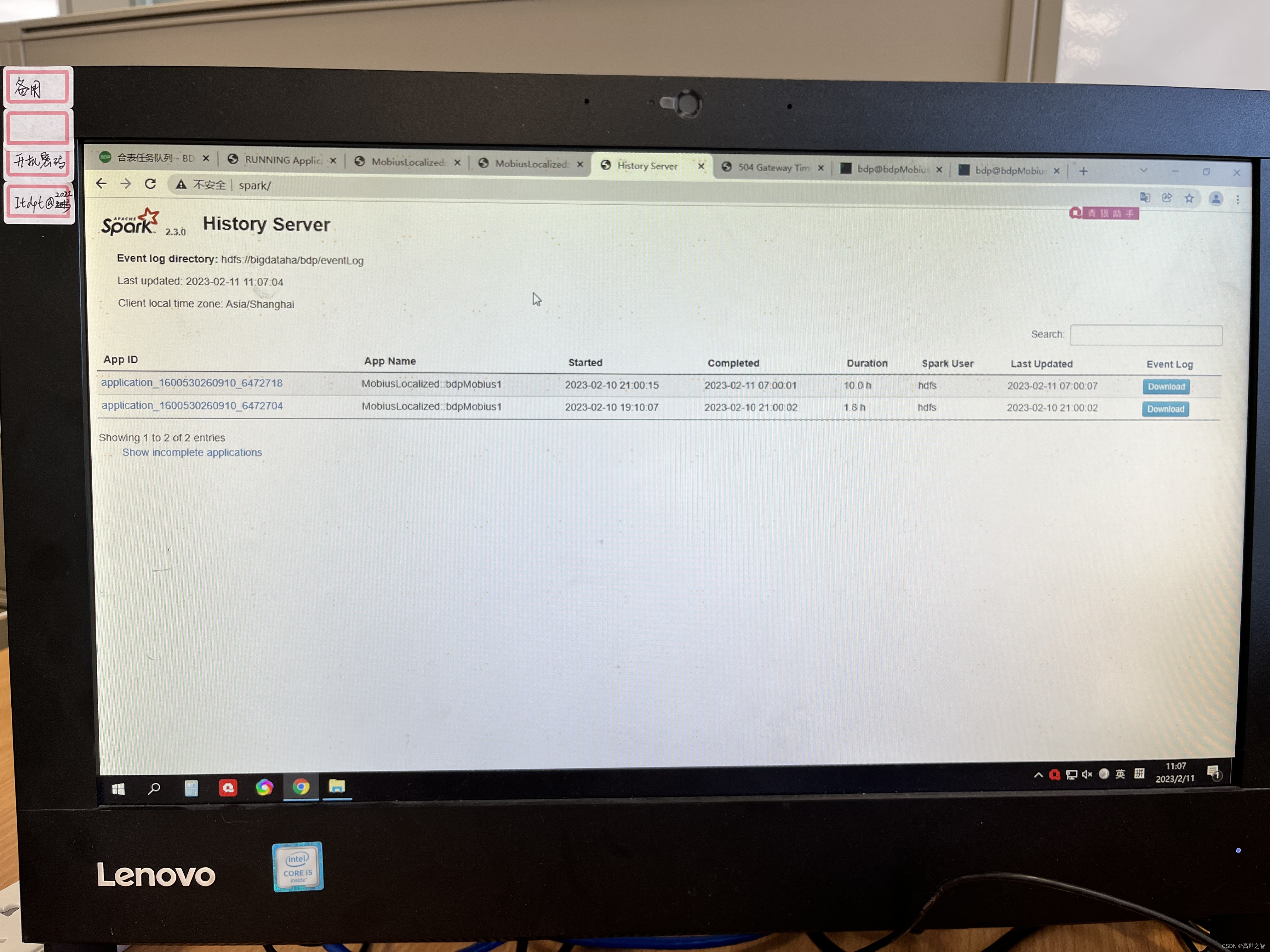
6、查看history ui
7、查看结束的spark-executor日志
8、关于spark_history_opts参数
网上经常说需要再spark-env.sh中配置spark_history_opts参数
# Configuration for the Spark History Server
# Optional: sets the URL for the Spark history server to listen on, if not set defaults to 0.0.0.0:18080
export SPARK_HISTORY_OPTS="$SPARK_HISTORY_OPTS -Dspark.history.ui.port=18080"
# Optional: sets the location of the Spark event logs that the history server reads, if not set defaults to file:/tmp/spark-events
export SPARK_HISTORY_OPTS="$SPARK_HISTORY_OPTS -Dspark.history.fs.logDirectory=hdfs://your-hdfs-cluster/spark/applicationHistory"
解释:
SPARK_HISTORY_OPTS是一个环境变量,用于指定启动Spark历史服务器时的选项。这些选 项将用于设置Spark历史服务器的内存大小、运行时的日志级别等。
下面是一个SPARK_HISTORY_OPTS变量的示例:
SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=10"
在这个示例中,我们将Spark历史服务器的Web UI监听端口设置为18080,并限制保留的应用程序数量为10。
注意:SPARK_HISTORY_OPTS变量通常用于设置Spark历史服务器的运行时参数,而不是用于配置Spark历史服务器本身。
因此,不配置SPARK_HISTORY_OPTS也能查看Spark历史作业。SPARK_HISTORY_OPTS仅用于指定启动Spark历史服务器时的选项,并不影响查看历史作业的功能。
在没有配置SPARK_HISTORY_OPTS的情况下,Spark历史服务器将使用默认的配置启动,你仍然可以通过浏览器访问Spark历史服务器并查看历史作业。
9、关于历史服务器保存多久的application和历史文件是否压缩等配置
spark.history.updateInterval
#默认值:10,以秒为单位,更新日志相关信息的时间间隔
spark.history.retainedApplications
#默认值:50,在内存中保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,当再次访问已被删除的应用信息时需要重新构建页面。
spark.history.ui.port
#默认值:18080,HistoryServer的web端口
spark.history.ui.acls.enable
#默认值:false,授权用户查看应用程序信息的时候是否检查acl。如果启用,只有应用程序所有者和spark.ui.view.acls指定的用户可以查看应用程序信息;否则,不做任何检查
spark.eventLog.compress
#默认值:false,是否压缩记录Spark事件,前提spark.eventLog.enabled为true,默认使用的是snappy
更多配置参考官网:https://spark.apache.org/docs/3.3.1/monitoring.html#viewing-after-the-fact