第四章 数据处理分析
在SparkSQL模块中,将结构化数据封装到DataFrame或Dataset集合中后,提供两种方式分析处理数据,正如前面案例【词频统计WordCount】两种方式:
第一种:DSL(domain-specific language)编程,调用DataFrame/Dataset API(函数),类似RDD中函数;
第二种:SQL 编程,将DataFrame/Dataset注册为临时视图或表,编写SQL语句,类似HiveQL;
两种方式底层转换为RDD操作,包括性能优化完全一致,在实际项目中语句不通的习惯及业务灵活选择。比如机器学习相关特征数据处理,习惯使用DSL编程;比如数据仓库中数据ETL和报表分析,习惯使用SQL编程。无论哪种方式,都是相通的,必须灵活使用掌握。
4.1 基于DSL分析
调用DataFrame/Dataset中API(函数)分析数据,其中函数包含RDD中转换函数和类似SQL语句函数,部分截图如下:
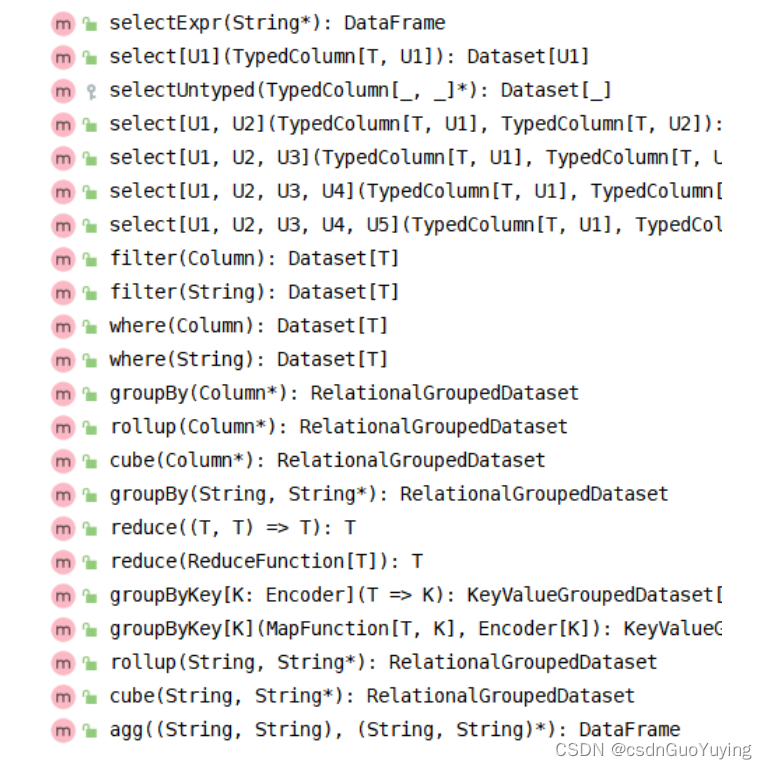
类似SQL语法函数:调用Dataset中API进行数据分析,Dataset中涵盖很多函数,大致分类如下:
1、选择函数select:选取某些列的值

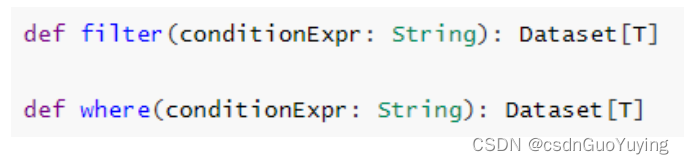
2、过滤函数filter/where:设置过滤条件,类似SQL中WHERE语句
3、分组函数groupBy/rollup/cube:对某些字段分组,在进行聚合统计

4、聚合函数agg:通常与分组函数连用,使用一些count、max、sum等聚合函数操作

5、排序函数sort/orderBy:按照某写列的值进行排序(升序ASC或者降序DESC)

6、限制函数limit:获取前几条数据,类似RDD中take函数
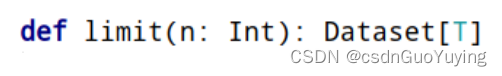
7、重命名函数withColumnRenamed:将某列的名称重新命名

8、删除函数drop:删除某些列

9、增加列函数withColumn:当某列存在时替换值,不存在时添加此列

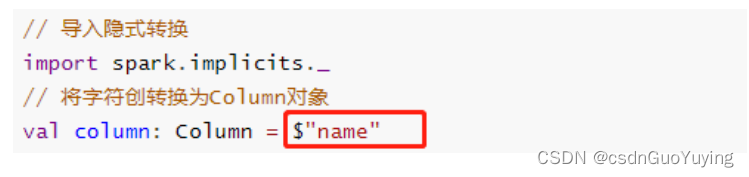
上述函数在实际项目中经常使用,尤其数据分析处理的时候,其中要注意,调用函数时,通常
指定某个列名称,传递Column对象,通过隐式转换转换字符串String类型为Column对象。
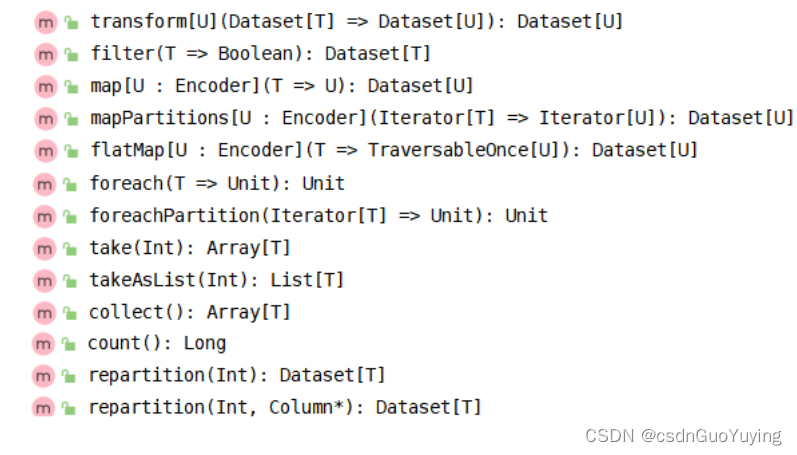
Dataset/DataFrame中转换函数,类似RDD中Transformation函数,使用差不多:
4.2 基于SQL分析
将Dataset/DataFrame注册为临时视图,编写SQL执行分析,分为两个步骤:
第一步、注册为临时视图

第二步、编写SQL,执行分析

其中SQL语句类似Hive中SQL语句,查看Hive官方文档,SQL查询分析语句语法,
官方文档文档:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select