在自动化测试的过程中,我们会经常遇到需要进行文字识别的场景,比如 识别验证码、识别截图中的文字、读取截图中的数值 等等,遇到这些情况时我们可以如何处理呢?
本机要有PaddleOCR环境,PaddleOCR可参考我另一篇
PaddleOCR,图像检测识别_木瓜星灵的博客-CSDN博客_paddleocr configsPaddleOCR,图像识别https://blog.csdn.net/qq_38312411/article/details/127567810
打开我们的AirtestIDE,在 选项--设置--自定义python.exe路径 中设置我们刚才安装好对应库的python环境:

截全屏+识别
在airtest客户端,连接真机后输入以下脚本
# -*- encoding=utf8 -*-
__author__ = "AirtestProject"
from airtest.core.api import *
from airtest.aircv import *
from PIL import Image
from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
auto_setup(__file__)
screen = G.DEVICE.snapshot()
# # 局部截图
# screen = aircv.crop_image(screen,(301,502,372,540))
# 保存局部截图到指定文件夹中
pil_image = cv2_2_pil(screen)
pil_image.save("E:/airtestLog/1.png", quality=99, optimize=True)
# 读取截图并识别截图中的文字
ocr = PaddleOCR(use_angle_cls=True, lang="ch") # need to run only once to download and load model into memory
img_path = r'E:/airtestLog/1.png'
result = ocr.ocr(img_path, cls=True)
for line in result:
print(line)
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in line]
# print(boxes)
txts = [line[1][0] for line in line]
# print(txts)
scores = [line[1][1] for line in line]
# print(scores)
im_show = draw_ocr(image, boxes, txts, scores, font_path='/path/to/PaddleOCR/doc/simfang.ttf')
im_show = Image.fromarray(im_show)
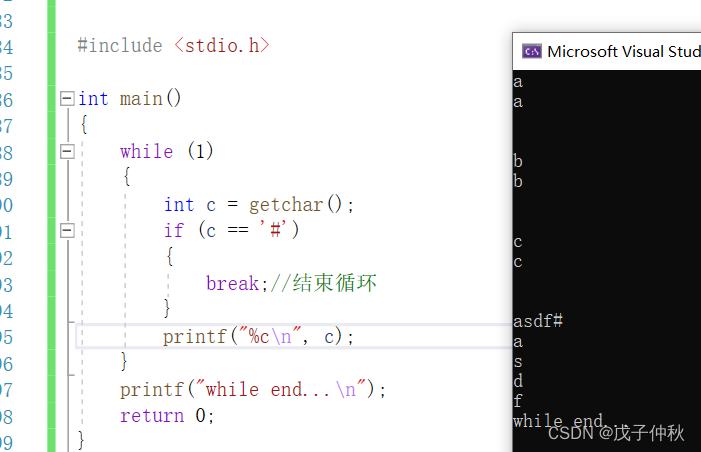
im_show.save('result.jpg')结果展示

局部截图+识别
现在想看局部的文字,识别验证码是个常见场景

# 局部截图
screen = aircv.crop_image(screen,(301,502,372,540))
结果展示
 局部截图也可以用另一个开源ocr软件Tesseract,参考,2行代码帮你搞定自动化测试的文字识别需要做验证码识别、读取截图文字的童鞋看过来啦~
局部截图也可以用另一个开源ocr软件Tesseract,参考,2行代码帮你搞定自动化测试的文字识别需要做验证码识别、读取截图文字的童鞋看过来啦~https://mp.weixin.qq.com/s/mrx2fndE9t_477yViZrpRA
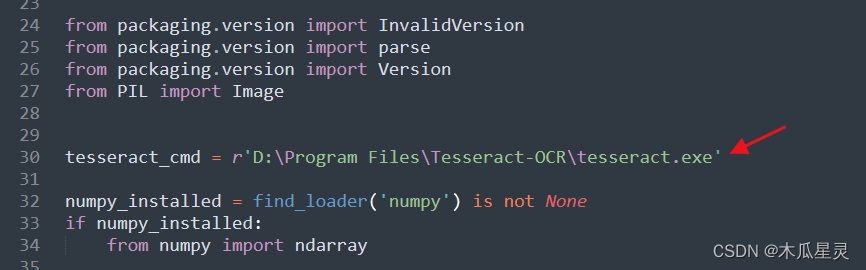
Tesseract若报错Python tesseract is not installed or it’s not in your path,将源码开头tesseract_cmd改成本机安装目录