前面,我们罗列了一些面试时可能会到的一些技术上的问题。但都是基于理论,也就是外面所说的八股文。应付一些基础的或者中级的开发岗位来说,是没什么问题的,但如果想拿高薪,或者升职的话,仅靠八股文是仅仅不够的,所以今天就开始进行场景实战,以此来提升大家的内功。
如何设计一个分布式环境下全局唯一的信号器
今天,叶秋面试到最后环节,一位美女面试官问了一个分布式的基础实战问题:如果让你去设计一个分布式环境下的全局唯一的信号器,你会怎么设计?
这里先说下本人的思路,完整的正确答案放到后面。
我刚听到这个问题第一反应就是:
- 使用UUID
优点:全球唯一,如果后续有项目迁移或者数据合并之类的,就完全不用担心数据冲突问题
缺点:使用字符串存储,会消耗一定量的存储空间,如果数据比较大,会很耗性能。
- 使用数据库自增的id
优点:它的优点就是UUID的缺点,简单且节省空间和性能
缺点:它的缺点就是UUID的优点,数据库自增的id是仅限于单库,如果后续数据合并冲突问题会很令人头疼。可以说,它和UUID的优缺点刚好相反。
- 使用雪花算法生成的ID
优点:它是个long型ID,灵活方便,不担心数据冲突的问题
缺点:这个没说上来,是叶秋考虑不周了。(一般分布式项目中使用的都是雪花算法,倒是没考虑到它的缺点)。
这边说了一些通用对方法,但实际上还要考虑到具体的场景和产品需求来确定采用哪一种方法。
只见那个美女面试官,微笑着点了点头说,整体来看,说的还是不错,但还是少了一种常用的方法,然后巴拉巴拉了一堆,最后总结如下:
- UUID
利用程序生成的ID,一般来说全球唯一。
优点:
- 简单,代码方便,且生成ID性能非常好,基本不会有性能问题。
- 全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对。
缺点:
- 没有排序,无法保证趋势递增。
- UUID往往是使用字符串存储,查询的效率比较低。
- 存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
- 传输数据量大
- 不可读。
是叶秋菜鸡了,自以为回答的很不错了,结果还是漏说了许多,看来还得加强学习。基础不牢固。
- 数据库自增长序列或字段
最常见的方式。利用数据库,当前数据库唯一。
优点:
- 简单,代码方便,性能可以接受。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
- 在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
- 如果遇见多个系统需要合并或者涉及到数据迁移会相当痛苦。
- 分表分库的时候会有麻烦。
优化方案:
针对主库单点,如果有多个Master库,则每个Master库设置的起始数字不一样,步长一样,可以是Master的个数。比如:
Master1 生成的是 1,4,7,10,Master2生成的是2,5,8,11 Master3 生成的是 3,6,9,12。这样就可以有效生成集群中的唯一ID,也可以大大降低ID生成数据库操作的负载。
汗,真是汗颜,看到这个优化方案,真是醍醐灌顶啊,竟然连这个也没想到,顿感对不起当前拿的工资了。是安逸太久了,不说了,这次要真去面试了。
- snowflake算法
snowflake 是 twitter 开源的分布式ID生成算法,其核心思想为,一个long型的ID:
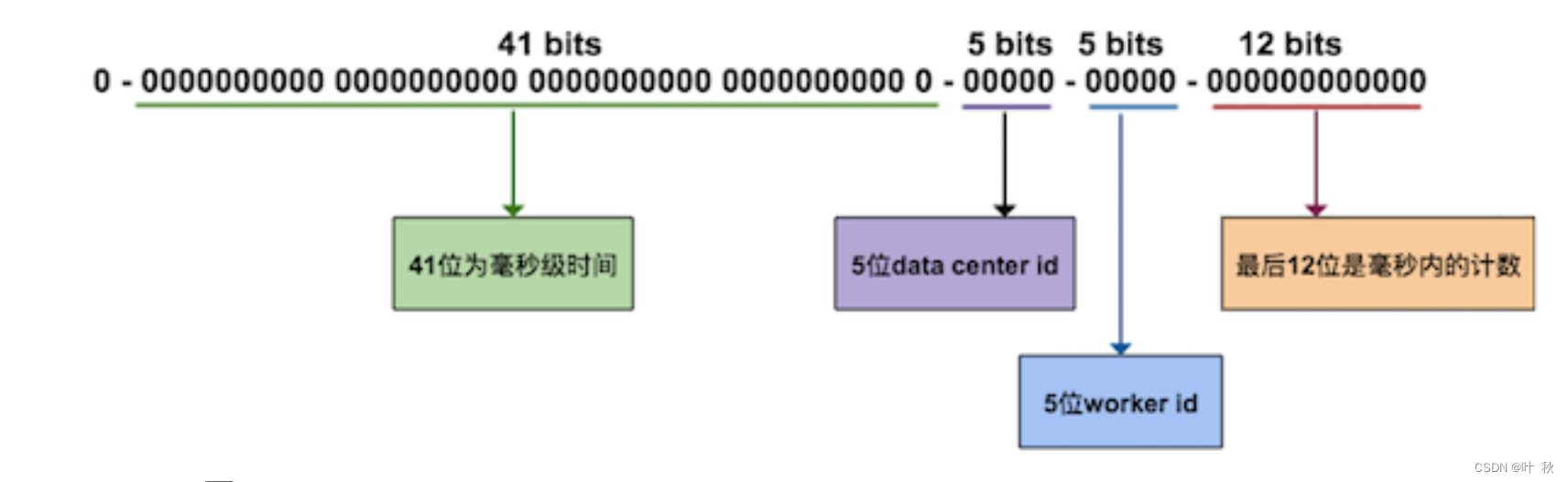
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- ID按照时间在单机上是递增的。
缺点:
- 在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况。
4 Redis生成ID
我们可以通过Redis生成全局唯一的ID。用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
- 需要编码和配置的工作量比较大。




![[22] Rodin: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion](https://img-blog.csdnimg.cn/b291938c0e0046918c2d66b799eab2dd.png)