“2022年11月30日,OpenAI发布了ChatGPT——一个对话式AI,上线仅五天,注册用户数突破100万,爆火出圈,成为社会热议话题。截止今年1月末,ChatGPT的月活用户数量破亿,成为史上用户数增长最快的消费者应用。”

据美国《时代周刊》报道显示,为训练ChatGPT,OpenAI雇佣了大量数据标注人员,甚至还投入了大量博士级别的专业人士来完成高质量的标注任务,以调整GPT-3.5的参数,从而使得GPT-3.5具备理解人类指令的能力。将大量资金投入到人工数据标注上是OpenAI成功的重要决策。
ChatGPT是人工智能技术驱动的自然语言处理工具,拥有语言理解和文本生成能力。可以像人类一样聊天交流,甚至可以区分某些问题中存在的描述性错误,能够拒绝用户不合理、不道德的要求。还能完成撰写邮件、视频脚本、文案、邮件、翻译、代码,创作诗歌、写论文等任务。
ChatGPT在拥有海量数据量的训练基础上,运用“手动标注数据+强化学习”模式,不断调整预训练语言模型。主要目的是为了让LLM模型可以更好地理解人类作出的命令的含义,使LLM模型学会判断对于得到的提示输入指令,从而提升回答的准确性。

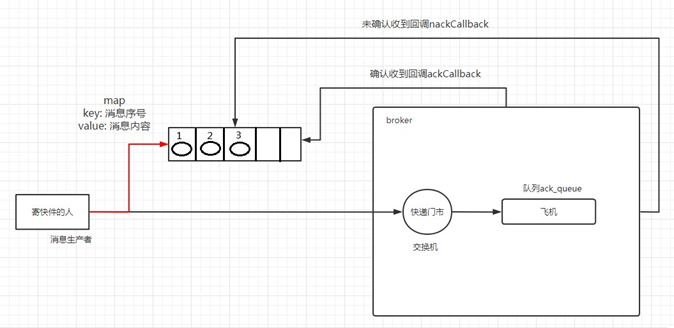
数据标注的工作流程包括数据采集、数据清洗、数据标注、数据质检等,是构建AI模型的数据准备和预处理工作的重要一环。对于ChatGPT这样的一款语言模型来讲,如果没有人工标注来清洗出一些不恰当的内容,那么它很有可能会输出错误信息。
高质量的人工标注数据是使得ChatGPT变得更加智能的关键所在。
景联文科技作为长三角地区规模最大的AI基础数据服务商之一,拥有丰富的文本标注经验,可为NLP领域提供数据采集和数据标注服务,根据客户需求迅速调配有相关经验的标注员。
现有数据库拥有文本成品数据集200T,包括NLP、TTS、NLU、ASR、发音字典等。
针对数据定制标注服务,景联文科技自建先进的数据标注平台与成熟的标注、审核、质检机制,支持自然语言处理:文本清洗、OCR转写、情感分析、词性标注、句子编写、意图匹配、文本判断、文本匹配、文本信息抽取、NLU语句泛化、机器翻译等多类型数据标注。
案例:
2022年景联文科技与某知名实验室合作命名实体标注项目,该项目需要采集不少于18万条的数据,内容涉猎广难度大,对标注人员素质能力要求高,且文本类型多、场景多、篇幅长。景联文科技配备3年以上NLP标注项目管理经验的项目经理和标注团队,安排标注团队对项目背景、目的、规则、注意事项、难点、平台操作、项目要求(准确率、日产量)进行培训和考核,考核成绩前60%的人员进入正式任务。最终以100%的合格率完成了该项目。

景联文科技|数据采集|数据标注|军工业务
助力人工智能技术,赋能传统产业智能化转型升级
文章图文著作权归景联文科技所有,商业转载请联系景联文科技获得授权,非商业转载请注明出处。