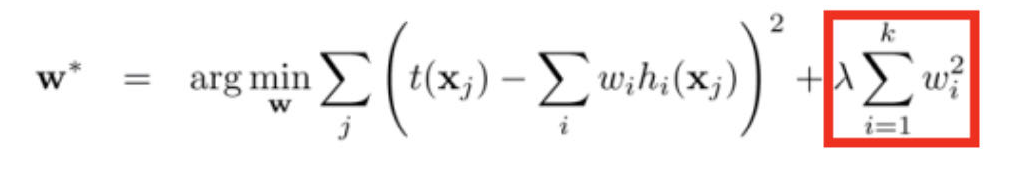注意力机制在NLP中的应用,是早期工作之一

1.为什么使用注意力机制

①在机器翻译的时候,每个生成的词可能相关于源句子不同的词
②语言翻译的时候,中英文存在倒装句,几个相同意思的句子中的词的位置可能近似的对应。翻译句子某部分的时候,只看源句子对应的位置就可以。
③seq2seq模型不能直接建模。Seq2seq模型中编码器向解码器传递的信息是:最后时刻的隐藏状态,解码器只用到编码器最后时刻的隐藏状态作为初始化进行预测。所以编码器看不到解码器最后时刻之前的其他隐藏状态。
④源句子的所有信息都包含在隐藏状态,但是翻译某个词的时候,每个解码步骤使用编码相同的上下文变量。并且并非所有的输入词元对解码某个词元有用。将注意力关注在源句子的对应位置,这也是注意力机制应用在seq2seq的动机
2.加入注意力:用编码器建立索引,解码器定位关注点
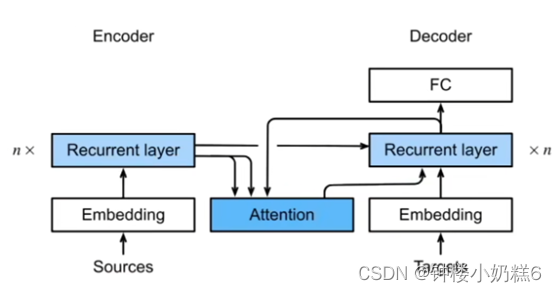
①解码器对每个词的输出(隐藏状态)作为key和value。序列多少词元,就有多少对key-value对,他们是等价的。都是第i个词元的rnn的输出。
②解码器RNN对上一个词的预测输出(隐藏状态)是query
③注意力的输出和下一个词的嵌入合并进入RNN解码器
④对seq2seq的改进:加入注意力机制对模型的索引词进行加权平均,根据翻译的词的不同时刻的RNN编码器输出隐藏状态
【总结】
①seq2seq中通过编码器最后时刻的隐藏状态在编码器和解码器传递信息
②注意力机制可以根据解码器RNN的输出来匹配到合适的编码器RNN的输出来有效地传递信息
③在预测词元时,如果不是所有的输入词元都是相关的,加入注意力机制能够使RNN编码器-解码器有选择地统计输入序列地不同部分(通过将上下文变量视为加性注意力池化地输出实现)
【代码实现】
import torch
from torch import nn
from d2l import torch as d2l# 定义注意力解码器
class AttentionDecoder(d2l.Decoder):
'''带有注意力机制编码器的基本接口'''
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
def attention_weights(self):
raise NotImplementedError''' 1.编码器在所有时间步的最终层隐藏状态,将作为注意力的键和值 2.上一时间步的编码器全层隐状态,作为初始化解码器的隐状态 3.编码器的有效长度 编码器上一个时间步的最终隐状态作为查询 '''
# Seq2SeqAttentionDecoder类中 实现带有Bahdanau注意力的循环神经网络解码器
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,
# num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# query的形状为(batch_size,1,num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# context的形状为(batch_size,1,num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 在特征维度上连结
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# 将x变形为(1,batch_size,embed_size+num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
def attention_weights(self):
return self._attention_weights# 包含7个时间步的4个序列输入的小批量测试Bahdanau
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
print(output.shape, len(state), state[0].shape, len(state[1]), state[1][0].shape)# 训练
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)