一、背景
近期,我们的kafka 消息队列集群(1.x版本)经过了一次事故。某节点意外宕机,导致 log 文件损坏,重启 kafka 失败,最后导致某个 topic 的分区不可用,本文对此做了简单的分析、解决和复现参考,以此为记录,供各位参考。
二、分析、解决
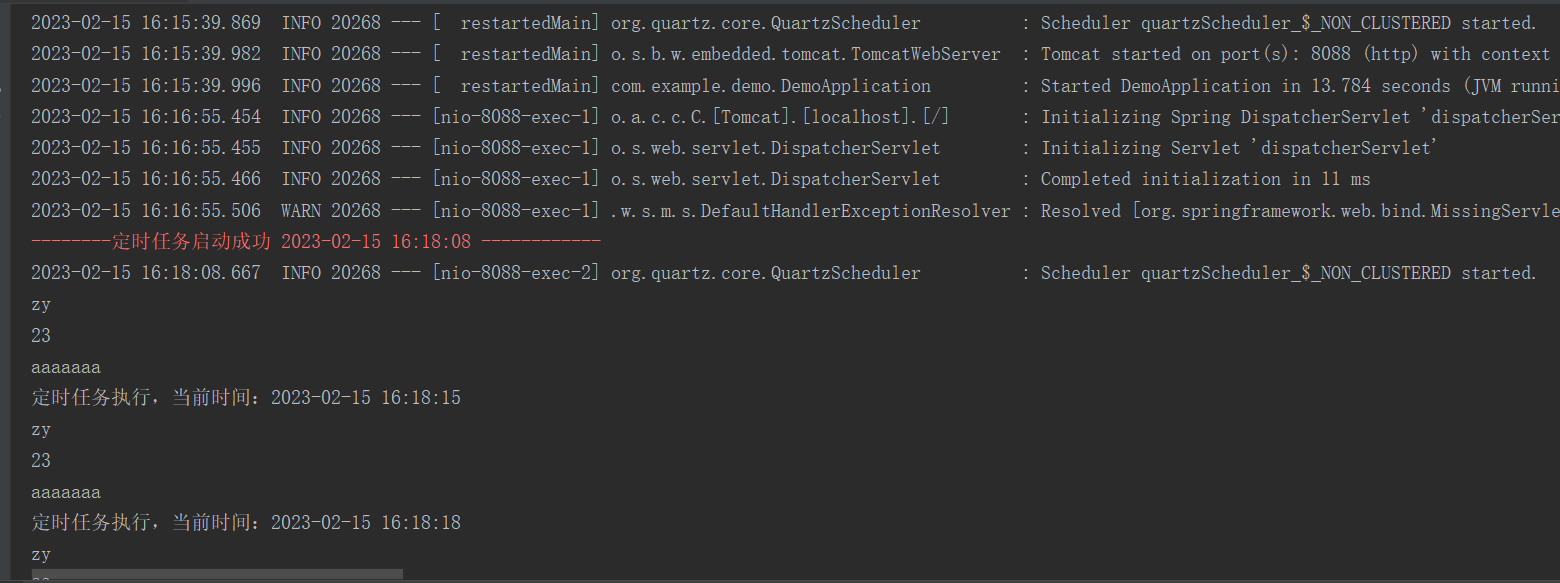
(1)初次启动时异常节点输出的日志
Feb 10 10:53:20 kafka-1.nc.node.prod-1.services.dev run_kafka.sh[6867]: [2023-02-10 10:53:20,632] WARN Found a corrupted index file due to requirement failed: Corrupt index found, index file (/data2/kafka/data/ncuser_user--1/00000000000170016370.index) has non-zero size but the last offset is 170016370 which is no larger than the base offset 170016370.}. deleting /data2/kafka/data/ncuser_user--1/00000000000170016370.timeindex, /data2/kafka/data/ncuser_user--1/00000000000170016370.index, and /data2/kafka/data/ncuser_user--1/00000000000170016370.txnindex and rebuilding index... (kafka.log.Log)
Feb 10 10:53:20 kafka-1.nc.node.prod-1.services.dev run_kafka.sh[6867]: [2023-02-10 10:53:20,632] INFO Loading producer state from snapshot file '/data2/kafka/data/ncuser_user--1/00000000000170016370.snapshot' for partition ncuser_user--1 (kafka.log.ProducerStateManager)(2)参考:https://www.cnblogs.com/felixzh/p/11174439.html,进行数据删除后,异常节点输出的日志
Feb 10 13:41:05 kafka-1.nc.node.prod-1.services.dev run_kafka.sh[18889]: [2023-02-10 13:41:05,662] WARN Found an orphaned index file, /data2/kafka/data/nc-5/00000000004114316599.timeindex, with no corresponding log file. (kafka.log.Log)其他节点输出的日志
Feb 10 14:04:09 kafka-2.nc.node.prod-1.services.dev run_kafka.sh[111352]: [2023-02-10 14:04:09,086] ERROR [ReplicaFetcher replicaId=135, leaderId=137, fetcherId=0] Current offset 415494641 for partition nc-21 out of range; reset offset to 415548539 (kafka.server.ReplicaFetcherThread)(3)最终参考:https://blog.csdn.net/Javajiaojiaozhe/article/details/108003887 调整了参数,然后重启数据损坏的 kafka broker 节点,才使得问题得以解决
调整参数为:unclean.leader.election.enable=true (确保分区可从非 ISR 中选举 leader)
后期彻底解决:升级 kafka 的版本为较新版本(如 2.8.0),公司使用的版本过老,存在许多 bug。
三、总结
在 kafka 1.x 版本中,处于安全和可靠的考虑,有不少参数过于保守。所以用户需要按需调整
1、将 broker 参数 unclean.leader.election.enable 设置为 true(确保分区可从非 ISR 中选举 leader)
2、将 broker 参数 default.replication.factor 设置为 3(提高高可用,但会增大集群的存储压力,可后续讨论)
3、将 broker 参数 min.insync.replicas 设置为 2(这么做可确保 ISR 同时有两个,但是这么做会造成性能损失,是否有必要?因为我们已经将 unclean.leader.election.enable 设置为 true 了)问题是解决了,但需要思考一些问题,以便我们能更好地理解 kafka。
(1)什么是 LEO、LSO、HW、AR和 ISR?
1、LEO(Log End Offset):日志末端位移值或末端偏移量,表示日志下一条待插入消息的位移值。举个例子,如果日志有10条消息,位移值从0开始,那么,第10条消息的位移值就是9。此时,LEO = 10。
2、LSO(Log Stable Offset):这是Kafka事务的概念。如果你没有使用到事务,那么这个值不存在(其实也不是不存在,只是设置成一个无意义的值)。该值控制了事务型消费者能够看到的消息范围。它经常与Log Start Offset,即日志起始位移值相混淆,因为有些人将后者缩写成LSO,这是不对的。在Kafka中,LSO就是指代Log Stable Offset。
3、HW(High watermark):高水位值,这是控制消费者可读取消息范围的重要字段。一个普通消费者只能“看到”Leader副本上介于Log Start Offset和HW(不含)之间的所有消息。水位以上的消息是对消费者不可见的。
AR(Assigned Replicas):AR是topic 被创建后,分区创建时被分配的副本集合,副本个数由副本因子决定。举例: AR 的副本在 ISR 副本集中
集群有 4台 kafka broker: 207、208、209、210
$ kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 4 --partitions 3 --topic isr_test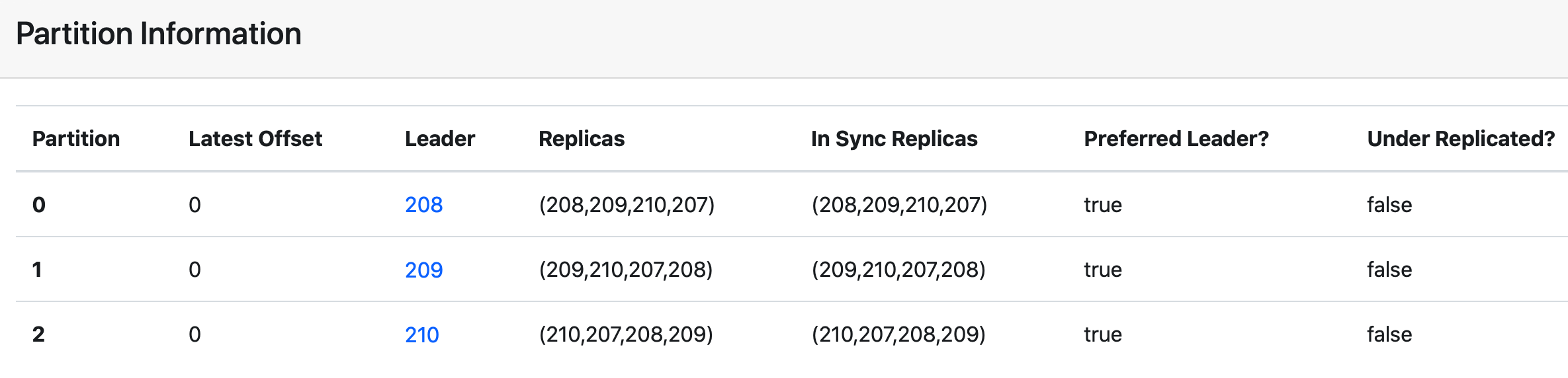
ISR(In-Sync Replicas):Kafka中特别重要的概念,指代的是AR中那些与Leader保持同步的副本集合。在AR中的副本可能不在ISR中,但Leader副本天然就包含在ISR中。
举例: AR 的副本不在 ISR 副本集中
集群有 4台 kafka broker: 134、135、137、138
$ kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 2 --partitions 3 --topic isr_test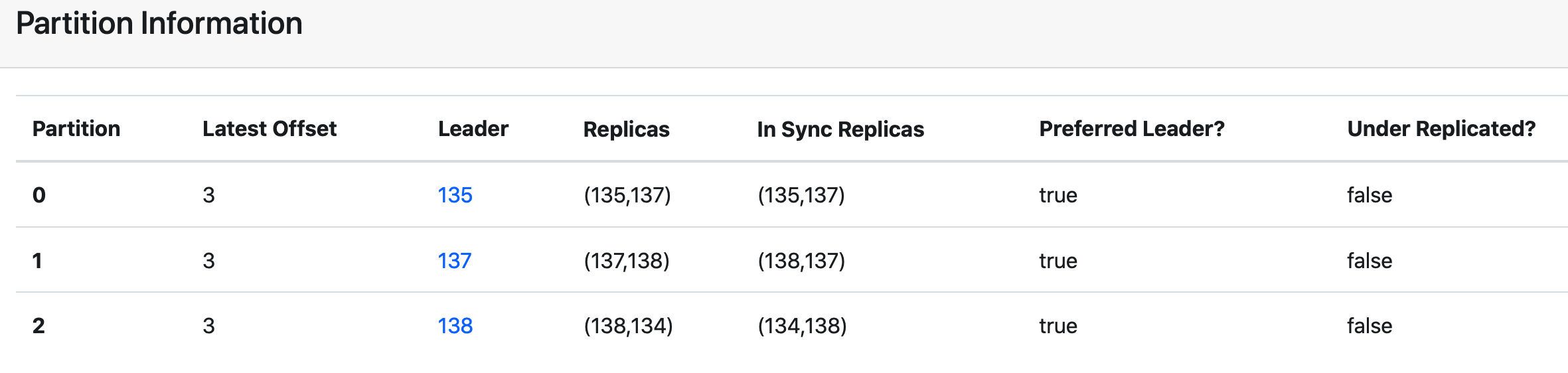
(2)unclean.leader.election.enable的内涵是?
从 kafka 1.x的官方解释如下:
https://kafka.apache.org/10/documentation.html

指示是否使不在ISR集中的复制体作为最后手段被选为领导者,即使这样做可能导致数据丢失。需要结合 AR(Assigned Replicas)和 ISR (In Sync Replicas)来理解这个参数。以这个 topic 为例
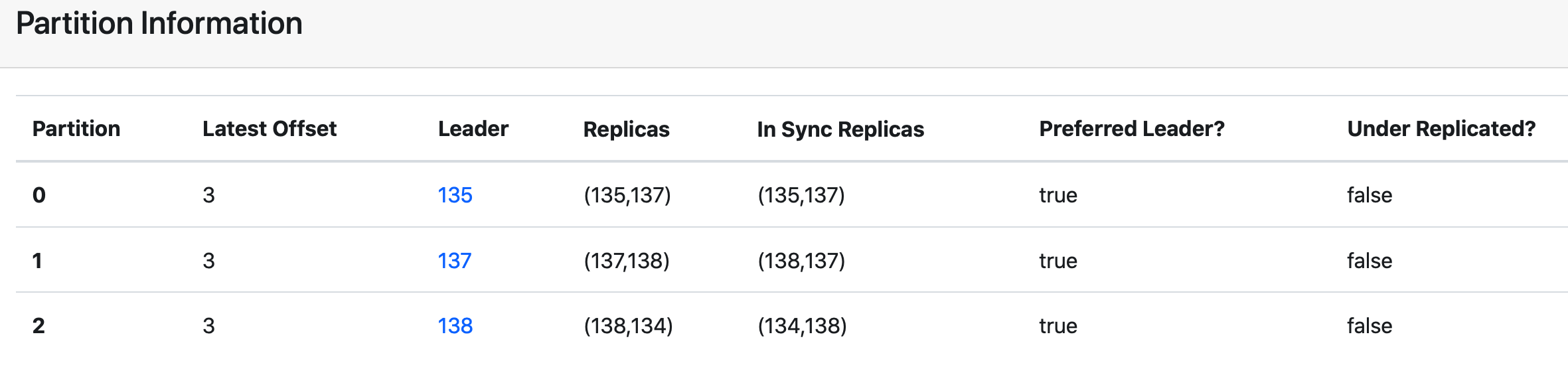
在 134 和 138 节点都下线的情况下, 138 节点的 follower2( 134 节点) 副本落后 leader 副本很多,并且也不在 leader (135节点)副本和 follower1 (135节点)副本所在的ISR集合之中。
follower2 副本正在努力的追赶 leader 副本以求迅速同步,并且能够加入到 ISR 中。但是很不幸的是,此时他(138)的 ISR中的所有副本都突然下线,只留下 partition0 和 partition1。
此时 follower2 副本(134节点)还在,就会进行新的选举,但在选举之前首先要判断 unclean.leader.election.enable 参数的值。
1、如果 unclean.leader.election.enable=false,那么就意味着非ISR中的副本不能够参与选举,此时无法进行新的选举,此时整个分区处于不可用状态。
2、如果 unclean.leader.election.enable=true,那么可以从非ISR集合(135 和 137 节点)中选举 follower 副本成为新的leader。产生新的 leader 后,随着时间的推进,新的 leader 副本从客户端收到了新的消息,此时,原来的leader副本恢复,成为了新的follower副本,准备向新的leader副本同步消息,但是它发现自身的LEO比leader副本的LEO还要大。
限制条件:Kafka 中有一个准则,follower副本的 LEO 是不能够大于 leader 副本的,所以新的 follower 副本就需要截断日志至leader副本的 LEO 处。
那么新的 follower 副本需要删除一部分消息,之后才能与新的leader副本进行同步。之后新的 follower 副本和新的leader副本组成了新的ISR集合。
(3)异常复现
请参考:https://developer.aliyun.com/article/918789