一、L1 和 L2范数(norm)
A norm is a mathematical thing that is applied to a vector. The norm of a vector maps vector values to values in [0,∞). In machine learning, norms are useful because they are used to express distances: this vector and this vector are so-and-so far apart, according to this-or-that norm.
简单说,范数是将向量取值映射在 [0,∞) ,机器学习中,被用于表示距离
二、正则化(表示模型的复杂度)
1、概念
正则化 是 结构风险最小化 策略的实现。[参考3]
结构风险 = 经验风险 + 正则化

其中:
J(f)为模型复杂度
 >= 0是系数,权衡经验风险和模型复杂度
>= 0是系数,权衡经验风险和模型复杂度
正则化项一般事模型复杂度的单调递增函数
2、作用
降低模型复杂度,减小过拟合的风险。减少模型参数,或者使参数尽可能的小[参考4]
平衡经验风险和模型复杂度,使得经验风险和模型复杂度都尽可能的小
三、奥卡姆剃刀
如果一件事情有两个解决方案,那么最优的方案一定是简单的那个。同理,深度学习提出简单模型的概念(参数量尽可能少的模型),且简单模型一定比复杂模型效果好,因为复杂模型容易过拟合。[参考4]
四、L1和L2公式

L1-norm

L2-norm

Lp-norm
五、L1和L2区别
1、L1正则的稀疏性
取决于正则化约束后的解空间 和 凸优化问题中目标函数的等高线 的交点[参考2]
L1:解空间为菱形,交点在轴上,w为0,所以会产生稀疏性结果
L2:解空间为圆形,交点一般在象限里,w不为0

2、L2解唯一
L1-norm解是不唯一的

其中:
绿色是L2-norm的解
其他是L1-norm的解
L2-norm是两个黑点的距离(与 一、L1 和 L2范数 相呼应)
六、Lasso回归、岭回归
1、Lasso回归
Lasso回归是在逻辑回归的损失函数后添加L1正则

2、岭回归
岭回归是在逻辑回归的损失函数后添加L2正则
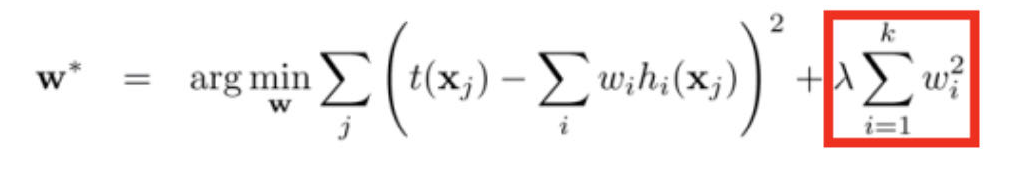
参考:
https://mp.weixin.qq.com/s/vVEAZoGEVxkaDR465XwZSA
百面机器学习
统计学习方法
python深度学习