QT版本 v5.12.10
元素
// 重点说明QHashData的函数,QHashData是QHash的基础
struct QHashData
{
struct Node {
Node *next;
uint h;
};
Node *fakeNext; // 永为null
Node **buckets; // Node *数组
QtPrivate::RefCount ref;
int size; // node个数
int nodeSize; // node字节对齐后的大小
short userNumBits; // 用户设定的bit数,但不一定会取用
short numBits; // 位数,通过numBits可以计算出numBuckets的值,计算方法参考:http://oeis.org/A092131
int numBuckets; // 桶的总数量,为素数
uint seed; // hash计算时的种子
uint sharable : 1; // 是否共享,默认共享
uint strictAlignment : 1; // 是否字节对齐, 默认对齐
uint reserved : 30; // 保留字段
void *allocateNode(int nodeAlign);
void freeNode(void *node);
QHashData *detach_helper(void (*node_duplicate)(Node *, void *), void (*node_delete)(Node *),
int nodeSize, int nodeAlign);
void rehash(int hint);
void free_helper(void (*node_delete)(Node *));
Node *firstNode();
static Node *nextNode(Node *node);
static Node *previousNode(Node *node);
static const QHashData shared_null;
};
template <class Key, class T>
struct QHashNode
{
QHashNode *next;
const uint h;
const Key key;
T value;
inline QHashNode(const Key &key0, const T &value0, uint hash, QHashNode *n)
: next(n), h(hash), key(key0), value(value0) {}
inline bool same_key(uint h0, const Key &key0) const { return h0 == h && key0 == key; }
private:
Q_DISABLE_COPY(QHashNode)
};
allocateNode & freeNode
字节对齐时的申请释放内存,字节对齐通过aligneof计算
detach_helper
当两个QHash存在共享且一个QHash产生写操作时,QHash调用此函数来完成分离操作。
具体操作是遍历每个桶及每个桶的链表,复制node插入到新的链表
rehash
void QHashData::rehash(int hint)
{
// 以下代码找出合适的bit数,
if (hint < 0) {
hint = countBits(-hint);
if (hint < MinNumBits)
hint = MinNumBits;
userNumBits = hint;
while (primeForNumBits(hint) < (size >> 1))
++hint;
} else if (hint < MinNumBits) {
hint = MinNumBits;
}
// 此时hint为4 - 31其中一个(其实只到26,后面五个为0,参考prime_deltas)
if (numBits != hint) {
Node *e = reinterpret_cast<Node *>(this); // 将QHashData强转为Node类型,作为end标志
Node **oldBuckets = buckets;
int oldNumBuckets = numBuckets;
int nb = primeForNumBits(hint);
buckets = new Node *[nb]; // 创建新的桶
numBits = hint;
numBuckets = nb;
for (int i = 0; i < numBuckets; ++i) // 为每个桶初始化,第一个元素都指向end
buckets[i] = e;
// 以下代码,将旧桶的链表打破,放入到新桶中,所以rehash所涉及的内存申请只有(n * 8)
// 并不会为每个node都申请一遍
for (int i = 0; i < oldNumBuckets; ++i) {
Node *firstNode = oldBuckets[i];
while (firstNode != e) {
uint h = firstNode->h;
Node *lastNode = firstNode;
// 以下代码是找出同一个桶中相同hash值的末尾节点
while (lastNode->next != e && lastNode->next->h == h)
lastNode = lastNode->next;
Node *afterLastNode = lastNode->next; // maybe afterLastNode == end
Node **beforeFirstNode = &buckets[h % numBuckets];
while (*beforeFirstNode != e) // 找到新桶的最后一个节点
beforeFirstNode = &(*beforeFirstNode)->next;
// 尾插法
lastNode->next = *beforeFirstNode;
*beforeFirstNode = firstNode;
firstNode = afterLastNode;
}
}
delete [] oldBuckets;
}
}
设计细节
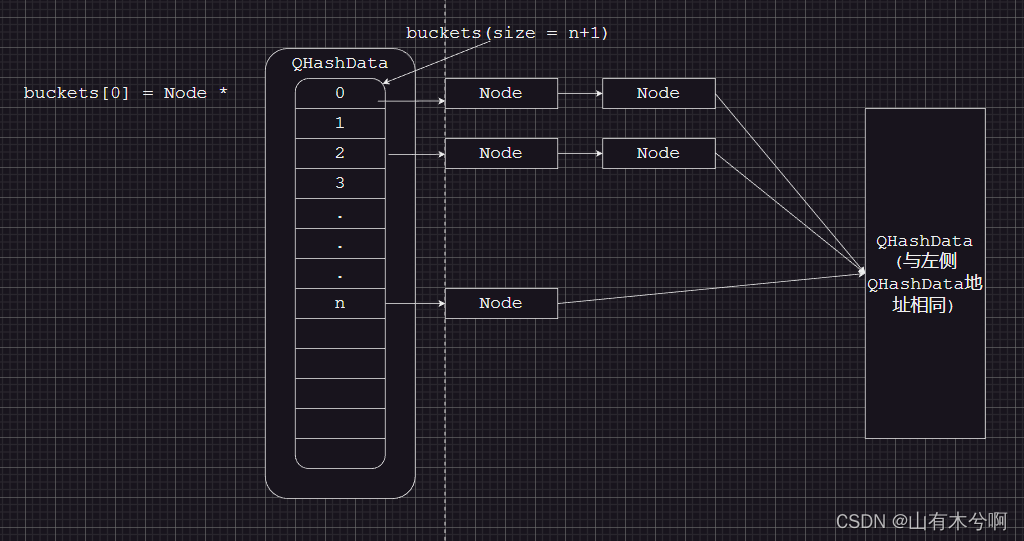
1、每个桶的结尾都指向QHashData,以此来判断是否到达结尾
为什么可以使用QHashData作为结尾呢?
因为QHashData的fakeNext变量放在第一个,fakeNext永为null,当将QHashData强转成Node类型时,Node的next值正好等于fakeNext,当判断到Node->next == nullptr时就可知道到达结尾,另外对于任意一个Node,都可以获取到QHashData的指针,nextNode,previousNode就是利用此特点
2、rehash涉及的内存只有n * sizeof(void *)大小
rehash函数中先创建n个桶,并初始化,然后打断旧桶的链表,根据hash值放入到新的桶
3、QHashNode的前两个变量正好对应Node的变量(类似linux下的双向链表),这样做就使得键值的类型与操作无关
4、暂时只想到这么多
结构图