一、ArrayList 和 LinkedList的区别
1. 底层数据结构不同。ArrayList底层是基于数组实现的,LinkedList底层是基于链表文现的
2. 由于底层数缺结构不同,他们所适电的场景也不同,Araylist史适合随机查战,LinkedList史适合期余和添加,查询、添加、删余的时间复杂度不同
3. ArrayList和LinkedList都实现了list接口, 但是LinkedList还额外实现了Deque接口,还可以当做双端队列
4. ArrayList需要考虑扩容(还不知道ArrayList扩容原理), LinkedList不需要※:补充ArrayList 和hashMap
ArrayList 扩容机制:直接变成1.5倍。最大扩容到 2^31 次方的大小。
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
// 当长度等于最大值时就会扩容
elementData = grow();
elementData[s] = e;
size = s + 1;
}
-----------------------------------------------------
private int newCapacity(int minCapacity) {
int oldCapacity = elementData.length;
// 位运算右移一位相当于直接 /2 这行代码等价于 new = old + old/2
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
// 最后将新的容量和最大值做对比
return (newCapacity - MAX_ARRAY_SIZE <= 0)? newCapacity : hugeCapacity(minCapacity);
}hashMap的扩容:扩容成原来大小的两倍 当占75%的时候就会开始扩容
final HashMap.Node<K,V>[] resize() {
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 如果当前map需要扩容直接 容量和因子变成double
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1;
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else {
// 默认无参调用hashMap
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
HashMap.Node<K,V>[] newTab = (HashMap.Node<K,V>[])new HashMap.Node[newCap];
table = newTab;
}hashMap的put操作,在1.8版本中引入了红黑树的概念,当长度大于8的时候会转换成红黑树,小于6的时候会转换成链表,其中链表的作用是为了防止hash冲突,将发生碰撞的key存储到连表中
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // 当前节点没有元素直接new一个
tab[i] = newNode(hash, key, value, null);
else {
HashMap.Node<K,V> e; K k;
// 存在一个相同node时候会去比较hash
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p; // 取出已存在的node
else if (p instanceof HashMap.TreeNode) // 判断是不是一个树节点
e = ((HashMap.TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
// 当长度大于8就变成红黑树
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { 当有已存在的节点时,新值会覆盖旧值,旧值会返回
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
// 做完插入以后在进行扩容
if (++size > threshold)
resize();
return null;
}二、threadLocal使用
在每个线程Thread中都有threadLocalMap对象(是threadLocal 的一个内部类),key 是threadLocal对象是强引用、value就是缓存的值是弱引用。当线程结束完成以后threadLocal就会被GC清除,所以在线程中使用完成以后可以手动的remove掉,否则会造成内存泄露。
public class Node {
// 初始化一个threadLocal, 通过类方法的形式
private ThreadLocal<Integer> threadLocal = ThreadLocal.withInitial(() -> 0);
private Integer age;
public Integer getAge(){
return this.threadLocal.get();
}
public void setAge(Integer age){
this.threadLocal.set(age);
}
}public static void main(String[] args) throws InterruptedException {
Node node = new Node();
new Thread(() -> {
try{
node.setAge(65);
System.out.println("a线程===>"+node.getAge());
}finally {
threadLocal.remove();
}
}).start();
new Thread(() -> {
try{
node.setAge(48);
System.out.println("b线程===>"+node.getAge());
}finally {
threadLocal.remove();
}
}).start();
}关于threadLocalMap的扩容机制,其机制和hashMap底层的扩容原理是不同的,hashMap采用的是链地址法(数组加链表的形式),threadLocalMap采用的是开放地址法(冲突的时候会寻找下一个位置是不是有元素,一直找到有空位的地方进行插入)。
三、fast-fail 和 fast-safe机制
fail-fast的字面意思是“快速失败”。当我们在遍历集合元素的时候,经常会使用迭代器,但在迭代器遍历元素的过程中,如果集合的结构被改变的话,就会抛出异常,防止继续遍历。这就是所谓的快速失败机制。它是java集合中的一种错误检测机制。
工作原理 :迭代器每次执行next方法都会去调用checkForComodification方法,当expectedModcount 和 modCount值不相等的时候就会抛出异常,当删除或者添加元素的时候都会使modCount++所以会出现不相等的情况。
@Override
public void forEachRemaining(Consumer<? super E> action) {
final int size = ArrayList.this.size;
int i = cursor;
if (i < size) {
final Object[] es = elementData;
if (i >= es.length)
throw new ConcurrentModificationException();
for (; i < size && modCount == expectedModCount; i++)
action.accept(elementAt(es, i));
cursor = i;
lastRet = i - 1;
checkForComodification();
}
}
// 这里是关键
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}fail-safe 当集合的结构被改变的时候,fail-safe机制会在复制原集合的一份数据出来,然后在复制的那份数据遍历。例如copyOnWriteArrayList,缺点是: 开销大。
4. switch 和 if
switch的速度要比 if 判断快。当switch的key是连续的要远比switch的key不连续的执行速度要快。因为连续的switch在字节码层面生成的是 tableswitch,不连续生成的是lookupswitch。
5. try..catch.finally
如果在 try 和 finally中都有return ,会走finally的return方法。
当只在try中return,但是在finally中还对return的变量有操作分为两种情况:
在try 里面进行基本数据类型值的返回,在finally里在对该值进行操作,最终返回的值还是try里面的值。
在try里ruturn一个引用类型的对象,在finally里对该对象进行属性修改,最终返回都对象是finally里修改过的对象。
6.布隆过滤器
其目的是为了防止缓存穿透,本质上是一个二进制的数组。
如何实现一个bit类型的数组,可以通过基本类型进行操作。具体流程是先进行一次hash函数,然后对bit数组长度进行取模操作。
public void test09(){
// 先通过一个hash得到一个值 然后在%上一个bits的长度
int a = 65;
int[] bits = new int[4]; // 每个都是32bit 第一个位置是 0 ~ 31
int index = a / 32; // 确定在第几个桶
int offset = a % 32;
int state = ((bits[index] >> offset) & 1); // 查看某个位置的状态
bits[index] = bits[index] | (1 << offset); // 变成某个位置变成1
bits[index] = bits[index] & ~(1 << offset); // 变成某个位置变成0
}布隆过滤器的也是会存在误判的情况,误判取决于bit数组的长度和hash函数的次数。具体关系如下:
n是样本量,m是位图的长度,p是错误率,v是选取位图的长度,k是哈希函数的次数。
在n确定的情况下,m和p是一个反比例函数图像的关系,m和p的关系如下,算出来的m除8才是bit使用的空间:
在m确定的情况下,p和n是一个二次函数的图像 应选取最低点 ,当k越大就会消耗掉的m越多 则p一定会上升,k和n的关系如下:
真实的错误率为(k和m都是真实的):
当查询参数 word到来,会经过多个hash函数从而得到多个hash结果值,从而将计算结果所对应的下标值置为1,判断是不是同一个word是需要,所有hash结果相同才会判定为相同。可以通过增加hash函数的数量 和 二进制数组的容量来减少布隆过滤器的误判率。
业务场景中 可以先判断这个数据在不在布隆过滤器(相当于一个白名单或者一个黑名单)中,然后再判断redis缓存,如果没有再判断mysql,然后将查出来的数据更新到redis中。
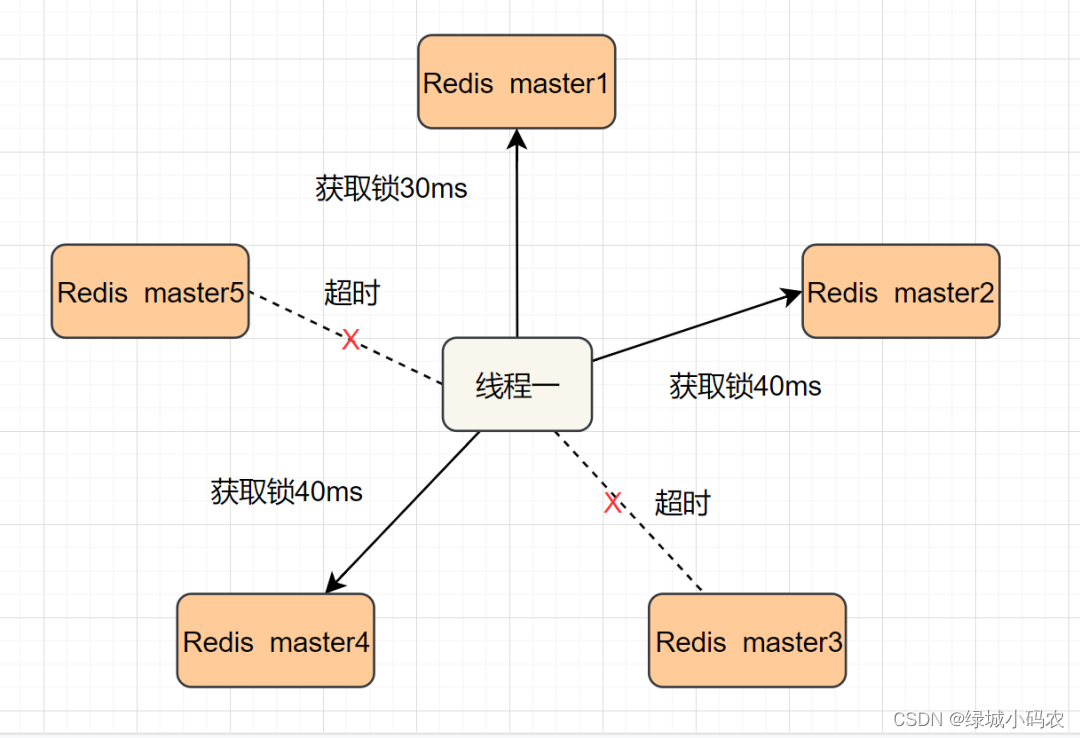
7. 分布式锁
zk实现分布式锁:用的是临时有序节点。每个客户端连接的时候都会创建一个临时节点,如果自己是最小的就去执行任务,如果不是则监听比自己小1的节点,等待节点的消失。
redis分布式锁:
是通过 Lua 脚本去保证 redis操作的原子性。
加锁核心:
// 如果key不存在直接进行set,会将当前线程号,过期时间等全部set进去。
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// 如果key存在,并且是当前线程,则进行重入次数+1
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
// 如果key存在value(value就是线程号)不匹配,直接通过pttl命令 返回剩余时间
"return redis.call('pttl', KEYS[1]);",解锁核心:
// 判断当前线程号不一致则忽略,线程号就是value
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
// 是当前线程就进行减一的操作,因为有可重入的情况,如果大于0,就需要重新设置时间这是重入锁,
// 小于等于0直接删除key进行释放
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " +
"return 1; " +
"end; " +
"return nil;",对于提高容错可以使用redlock。
8、原子类LongAdder 和 LongAccumulator
原子类型的累加器,在高争用的情况下比atomicLong吞吐量要大很多,代价是消耗更大的空间,减少了CAS的重试次数;在低争用的情况下两者相差无几。
1. LongAdder 初值为0的累加器, 是striped64的子类
LongAdder longAdder = new LongAdder();
longAdder.add(2); // +2
longAdder.increment(); // +1
longAdder.sum(); // 多线程不保证准确度
longAdder.sumThenReset(); // 求和并重置为0
longAdder.reset(); // 重置为0
2. LongAccumulator 自定义初值和计算方式的累加器,接收两个参数 [计算方式, 起始值]
LongAccumulator accumulator = new LongAccumulator((x, y) -> x + y, 0);
accumulator.accumulate(1); // +1
accumulator.accumulate(2); // +2
System.out.println(accumulator.get());LongAdder底层的原理是热点分散,类似开多个窗口进行处理,将value值分散到多个数组里,不同线程会命中不同的槽位,各个槽位进行CAS的操作,获取result就是所有槽位值相加 + base。
LongAdder的add时候代码解析:
变量说明:
base:基础值,在没有竞争的情况下直接累加到base,cells扩容后也需要部分累加到base上。
collide:是否还能扩容,false不扩容 true可以扩容。
cellsBusy:初始化/扩容的时候需要获取锁 0 标识无锁,1 标识其他线程已经持有锁了。
getProbe():得到当前线程的hash值。
CASCellsBusy(): 通过CAS修改 cellsBusy的值。true表示抢锁成功。
public void add(long x) {
Cell[] cs; long b, v; int m; Cell c;
// 只有一个线程的时第一次进来cells为null,casBase做的是自旋锁的比较,如果竞争失败了进行扩容
// base 是基础值, x 是更新值。
if ((cs = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true; // 有没有竞争,false代表有竞争产生
// 这里有四个层层递进的判断,当cs 为空,会进行初始化
// 当cs进行了初始化并赋初值后,某个槽位如果为空,则进行初始化一个cell
// 当cs进行了初始化并赋初值,对某个槽位的值CAS竞争失败,会进行扩容
if (cs == null || (m = cs.length - 1) < 0 ||
(c = cs[getProbe() & m]) == null ||
!(uncontended = c.cas(v = c.value, v + x)))
longAccumulate(x, null, uncontended);
}
}在对Cell数组初始化可以分为以下三种情况:
final void longAccumulate(long x, LongBinaryOperator fn,boolean wasUncontended) {
int h; // 值为0需要对线程进行强制初始化
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // 强制初始化
h = getProbe();
wasUncontended = true;
}
boolean collide = false;
done: for (;;) {
Cell[] cs; Cell c; int n; long v;
// cells已经被初始化了,进行某个槽位的争抢
if ((cs = cells) != null && (n = cs.length) > 0) {
// (n - 1) & h 得到了某个坑位值,如果值为null代表cell没有进行初始化
if ((c = cs[(n - 1) & h]) == null) {
if (cellsBusy == 0) { // 如果抢占失败,将collide = false
Cell r = new Cell(x); // 初始化一个cell并赋初值。
if (cellsBusy == 0 && casCellsBusy()) { // 双端校验 高并发就需要这样
try {
Cell[] rs; int m, j;
// cell数组不为空且长度大于0 某个坑位为null 就将当前坑位赋值过去
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
break done;
}
} finally {
cellsBusy = 0;
}
continue; // Slot is now non-empty
}
}
collide = false;
}
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // 跳出来之后在重新获取hash值进行循环
// 某个坑位c再次进行CAS抢锁 如果为成功直接break
else if (c.cas(v = c.value, (fn == null) ? v + x : fn.applyAsLong(v, x)))
break;
else if (n >= NCPU || cells != cs)
collide = false; // 已经到达CPU的上限不会进行扩容
else if (!collide)
collide = true; // 值是false则允许扩容
else if (cellsBusy == 0 && casCellsBusy()) { // 进行扩容的逻辑
try {
if (cells == cs) // 左移相当*2
cells = Arrays.copyOf(cs, n << 1);
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
h = advanceProbe(h);
}
// cells没有加锁也没有初始化了,尝试加锁并初始化
// cells == cs cs一进来就是null 可以看成 cells==null
else if (cellsBusy == 0 && cells == cs && casCellsBusy()) {
try {
// 进行初始化
if (cells == cs) {
Striped64.Cell[] rs = new Striped64.Cell[2]; // 永远都是二的次幂
rs[h & 1] = new Striped64.Cell(x); // 给每个数组进行赋值 x是1
cells = rs;
break done;
}
} finally {
cellsBusy = 0;
}
}
// 兜底的方法。其他线程正在初始化,多个线程更新base的时候直接break。
// fn是 LongAccumulator 初始化定义的自定义计算方法。
else if (casBase(v = base,(fn == null) ? v + x : fn.applyAsLong(v, x)))
break done;
}
}当sum的代码解析:一句话就是 .
public long sum() {
Cell[] cs = cells;
long sum = base;
if (cs != null) {
for (Striped64.Cell c : cs)
if (c != null)
sum += c.value;
}
return sum;
}