源码来自作者Bubbliiiing,我对参考链接的代码略有修改,网盘地址
链接:百度网盘 请输入提取码 提取码:bfvs
目录
1 参考
2 环境
3 数据集准备
3.1 VOCdevkit/VOC2007
3.2 model_data/voc_classes.txt
3.3 voc_annotation.py
4 训练 train.py
5 训练结果
6 预测
6.1 yolo.py
6.2 predict.py
6.3 预测
1 参考
视频地址 Pytorch 搭建自己的YoloV7目标检测平台(Bubbliiiing 源码详解 训练 预测)_哔哩哔哩_bilibili
博客地址:睿智的目标检测61——Pytorch搭建YoloV7目标检测平台_pytorch yolov7_Bubbliiiing的博客-CSDN博客
GIthub地址:GitHub - bubbliiiing/yolov7-pytorch: 这是一个yolov7的库,可以用于训练自己的数据集。
2 环境
- 系统 Linux
- 显卡 NVIDIA GeForce RTX 3060
- CUDA 11.1
- CUDNN 无 (cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2与cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2都查不到)
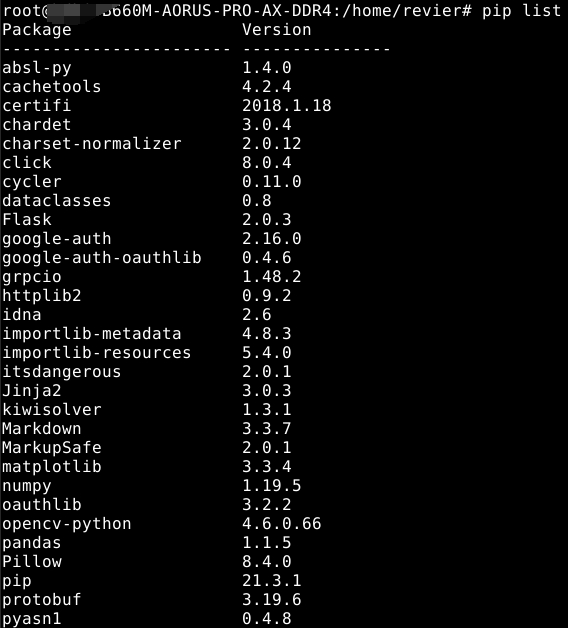
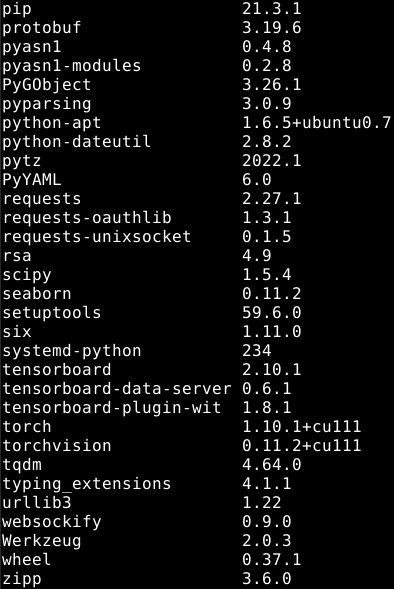
python版本3.6,环境如下
3 数据集准备
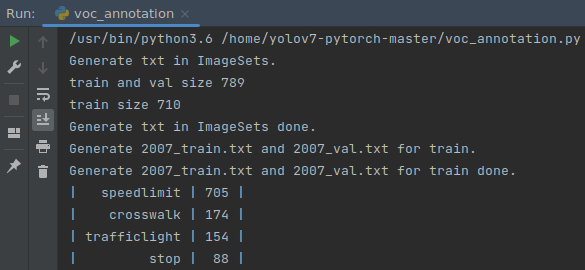
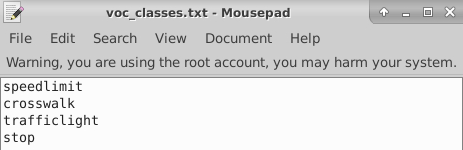
数据集为877张图像,4分类,其中speedlimit 705个框,crosswalk 174个框,traffclight 154个框,stop 88个框
3.1 VOCdevkit/VOC2007
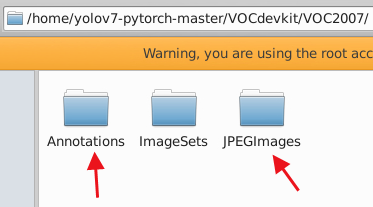
在项目路径下的VOCdevkit/VOC2007中,将Annotations放入标注的XML文件,JPEGImages放入标注的图片文件(我使用的是jpg格式的图像)
进入ImageSets/Main,删除其中的所有内容
- 删不删都行
删除项目路径下的 2007_train.txt与2007_val.txt
- 删不删都行
3.2 model_data/voc_classes.txt
打开项目路径下model_data中的voc_classes.txt
将里面的内容改为自己要训练的类别,顺序无所谓
3.3 voc_annotation.py
不需要改动代码直接运行 voc_annotation.py
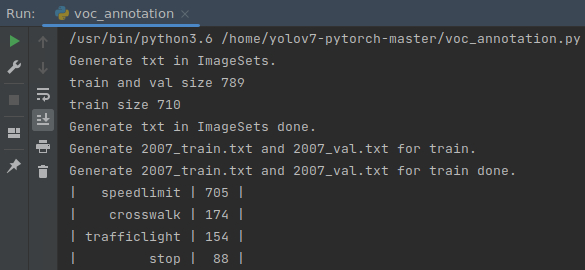
运行后会生成这些文件
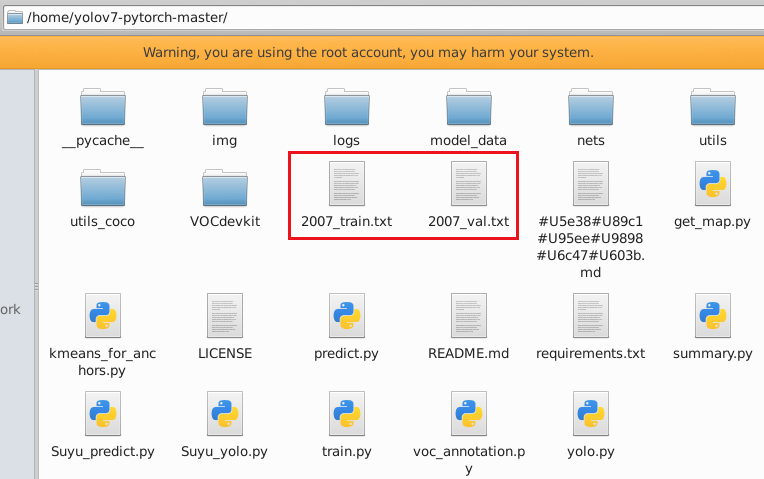
4 训练 train.py
根据需要修改这里的epoch
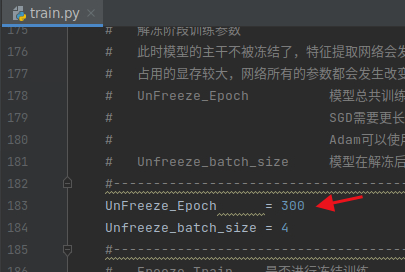
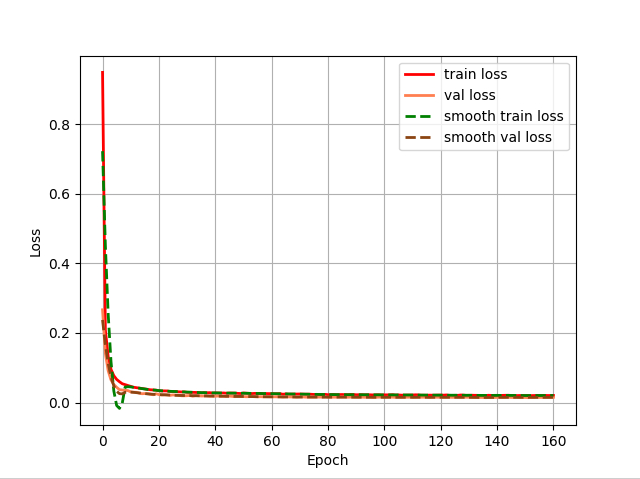
在该项目中训练,loss的收敛速度很快,loss的起步值也很低,所以不需要很多的epoch,我本来设置的是300,当他跑到160的时候我就停掉了
然后直接运行就好了,训练并不会持续很长时间
5 训练结果
训练结束后会在logs中出现一些文件,我们预测的时候使用 best_epoch_weights.h5 就可以了
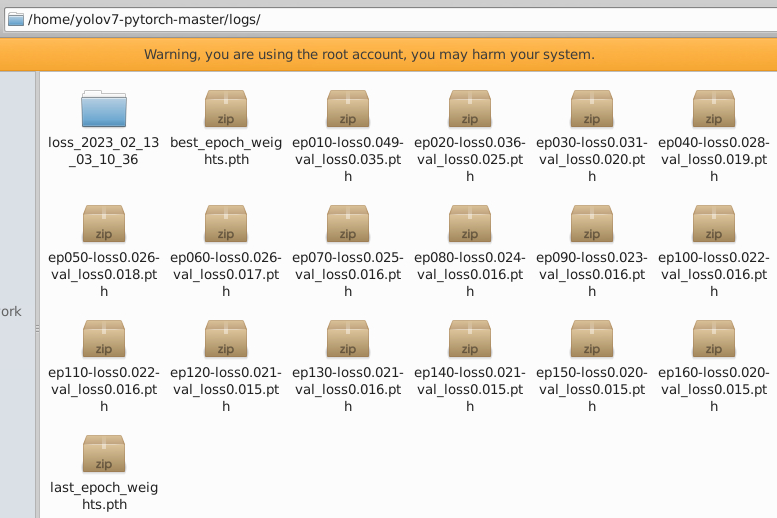
我们可以在训练过程中,或者在训练好的loss文件中,查看loss情况

在epoch_loss.txt中可以查看具体的数值
- 看下面这两个哪个都行
6 预测
6.1 yolo.py
修改yolo.py这里的模型信息
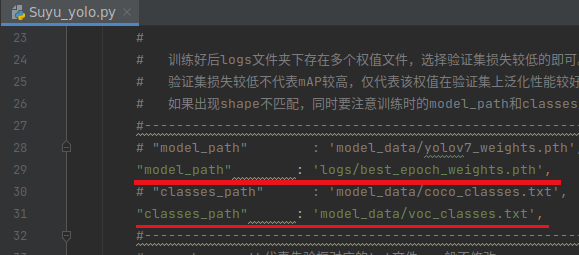
- 文件名改为了Suyu_yolo.py,下面的predict.py中会进行调用
我简单改了一下源代码中yolo.py的detect_image方法,目的是拿到预测的信息,而不是直接得到图像
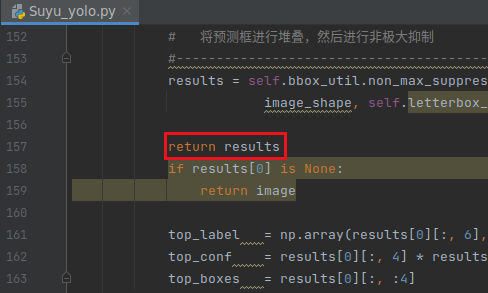
6.2 predict.py
然后改了一下源码中的predict.py(文件名我改为了Suyu_predict.py)
import time
import cv2
import numpy as np
from PIL import Image
from utils.utils import get_classes
from Suyu_yolo import YOLO
yolo = YOLO()
classes_path = 'model_data/voc_classes.txt'
class_names, num_classes = get_classes(classes_path)
img = './img/road49.jpg'
# img = './img/street.jpg'
image = Image.open(img)
results = yolo.detect_image(image)
result_image = cv2.imread(img)
if results[0] is None:
pass
else:
top_label = np.array(results[0][:, 6], dtype='int32')
top_conf = results[0][:, 4] * results[0][:, 5]
top_boxes = results[0][:, :4]
for i, c in list(enumerate(top_label)):
predicted_class = class_names[int(c)]
box = top_boxes[i]
score = top_conf[i]
top, left, bottom, right = box
top = max(0, np.floor(top).astype('int32'))
left = max(0, np.floor(left).astype('int32'))
bottom = min(image.size[1], np.floor(bottom).astype('int32'))
right = min(image.size[0], np.floor(right).astype('int32'))
label = '{} {:.2f}'.format(predicted_class, score)
result_image = cv2.putText(result_image,label,(left,top),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,0),2)
result_image = cv2.rectangle(result_image,(left,top),(right,bottom),(0,255,0),2)
cv2.imshow('result_image',result_image)
cv2.waitKey(0)
cv2.destroyAllWindows()6.3 预测
之后我们将一张图像放在文件夹img中
之后运行predict.py就可以得到结果了