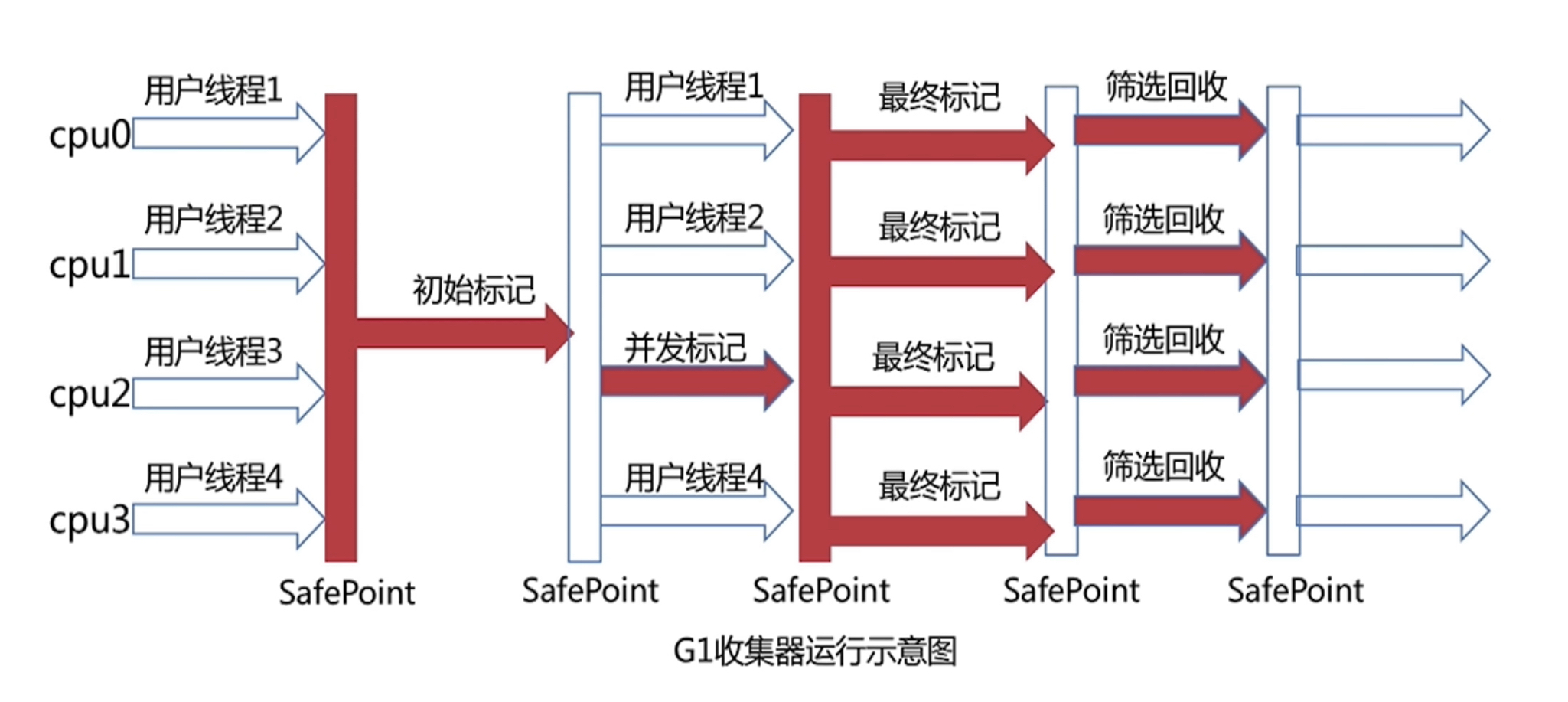
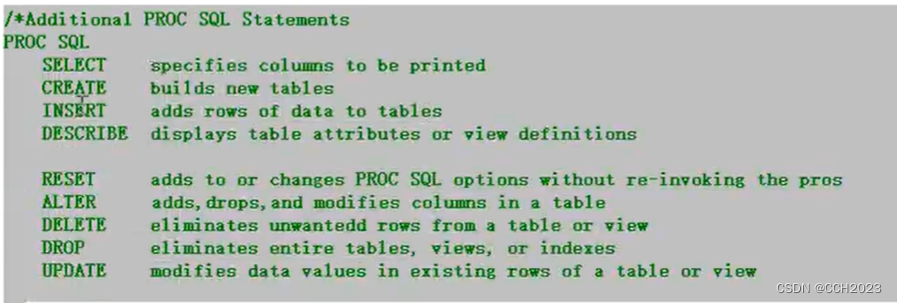
SQL (SAS):
Features:
1)不需要在每个query中重复调用每个SQL;
2)每个statement都是独立去完成的;
3)我们是没有proc print和proc sort语句的;(order by)
key syntax:
1)不写run,而是用quit来退出,这是SAS中一个很关键的点;
proc sql;
select data, air
from sashelp.air
where air>110
order by air desc;
quit;代码说明:
1)air大于110的,然后按照降序排列的。
2)不需要proc print的功能;
3)order by就起到了print sort的功能;
proc sql;
select *
from sashelp.air
where air>110
order by air desc;
quit;代码说明:这是将所有的变量都选取出来。
然后我们看下select语句:
/* select statement syntax with selected clauses
select:
from: 从那个表中查询
where:查询条件
group by:把数据进行分组
having: 基于group进行条件设定
order by: 类似于proc sort
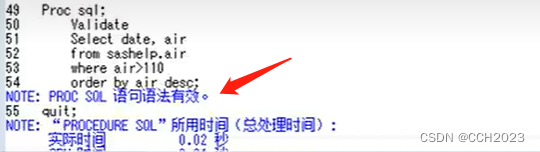
proc sql;
validate
select date, air
from sashelp.air
where air>110
order by air desc;
quit代码说明:
1)validate是进行SQL语法验证。
2)validate 关键字:
# 没有执行的时候进行测试;
# 检查列名称是否有效;
# 打印错误;
# 只能使用select语句;
proc sql noexec;
select date, air
from sashelp.air
where air>110
order by air desc;
quit;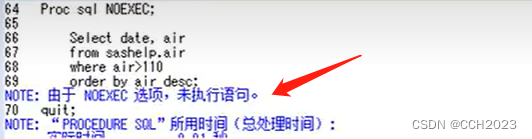
代码说明:
1)我不让你执行,去做一个验证。
1)describe:desc描述表属性。
2)这是SAS中使用中到的一些语句。
/* Describe */
proc sql;
describe table sashelp.class;
quit;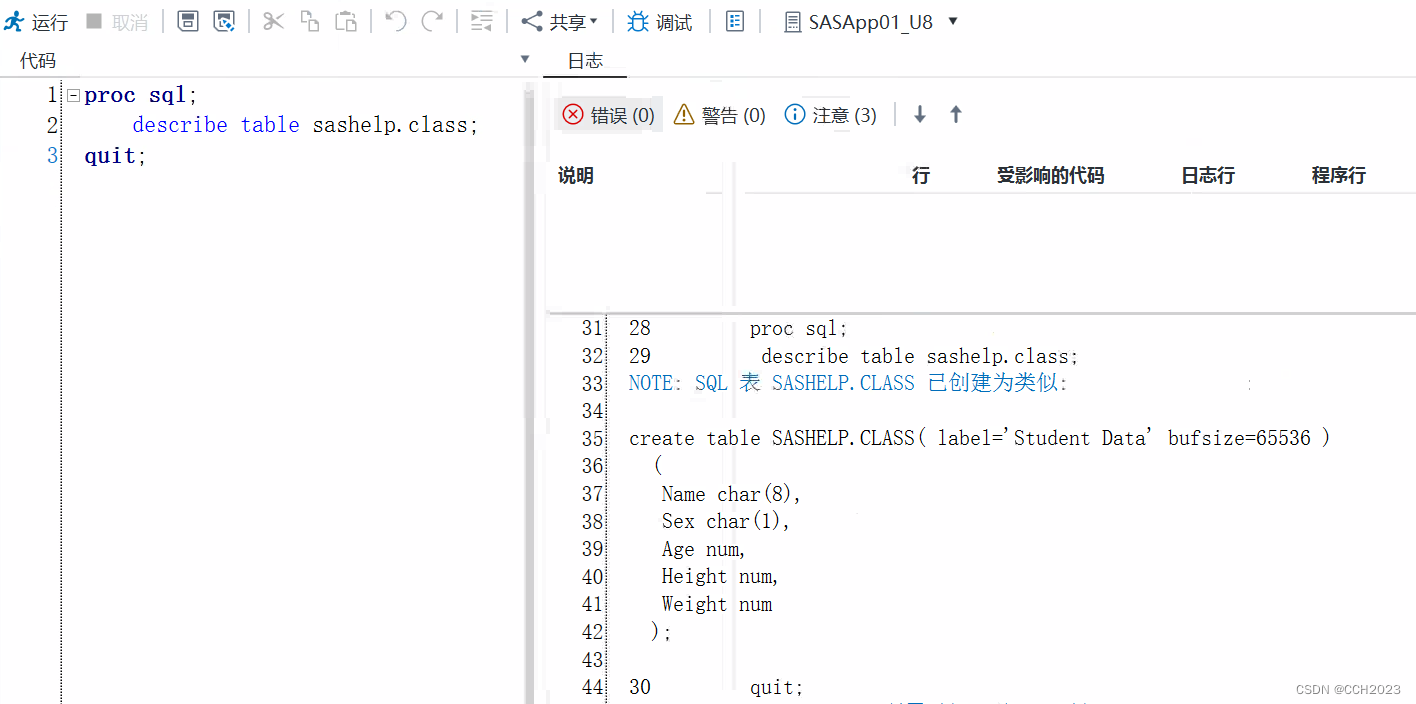
获取到了数据集的属性和变量属性。
label:标签名称。通过format命令来增加label。
char:字符型
8:表示8位。
对数据集不清楚的情况下,就使用这种方式进行操作。
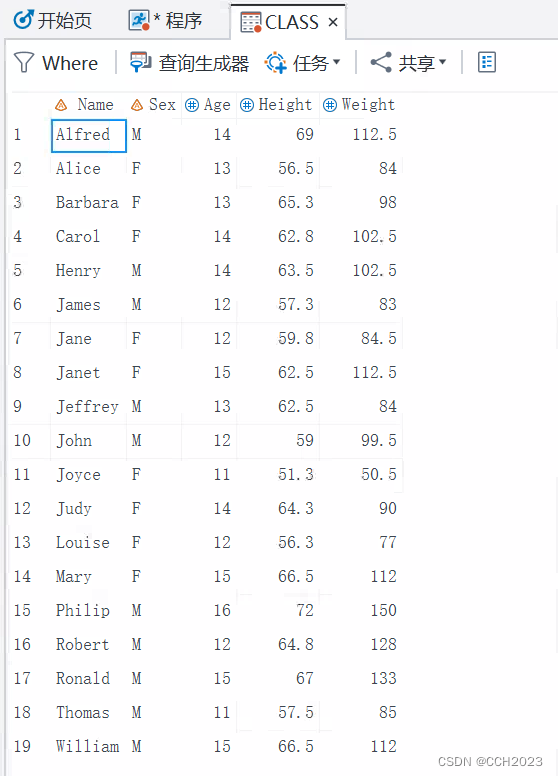
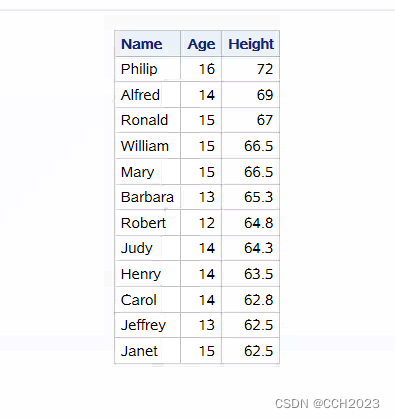
重新再看上面select语句的例子:

得到的结果:
SQL new vars with AS keyword
如何通过数据集中现有变量生成新的变量:
/* Calcluate the new column's value using the data in an existing column and name the new
columns using the as keyword */
proc sql;
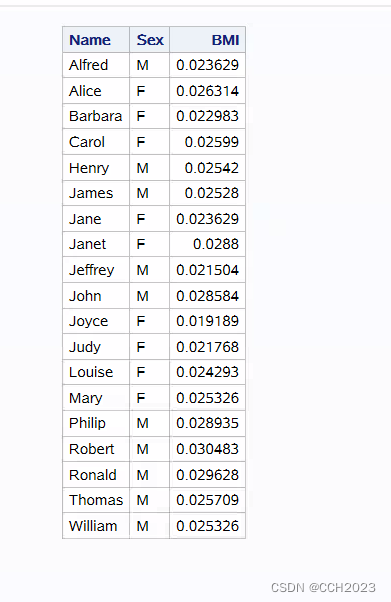
select name,sex,
weight/(height*height) as BMI
from sashelp.class;
quit;代码说明:
1)注意sex后面有一个逗号;
2)这个BMI的值是不对的,需要进行换算;
scan函数:
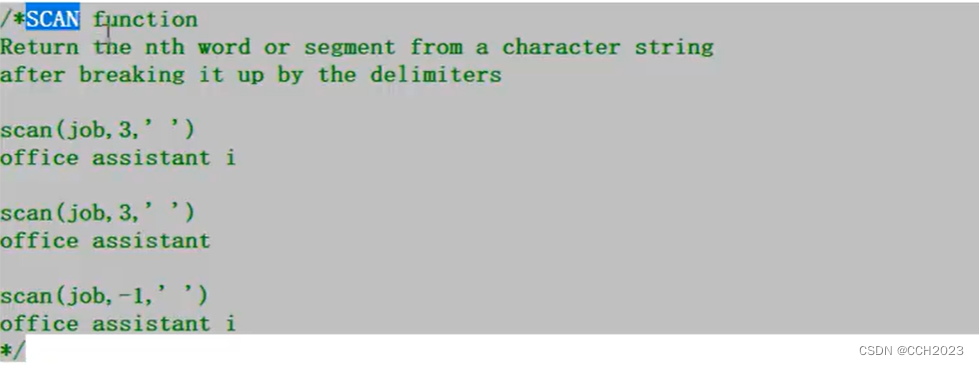
代码说明:
1)第一个返回为i;
2)第二个返回一个空值;
3)-1,表示的倒数第一位,返回为i;
case-when语句:
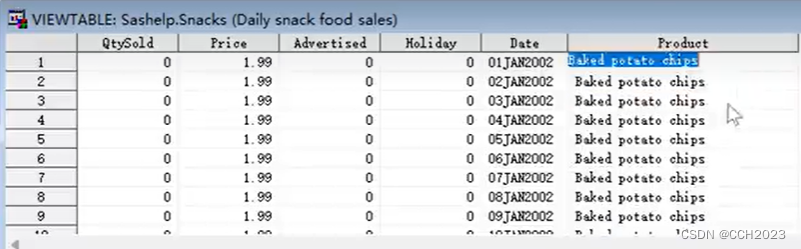
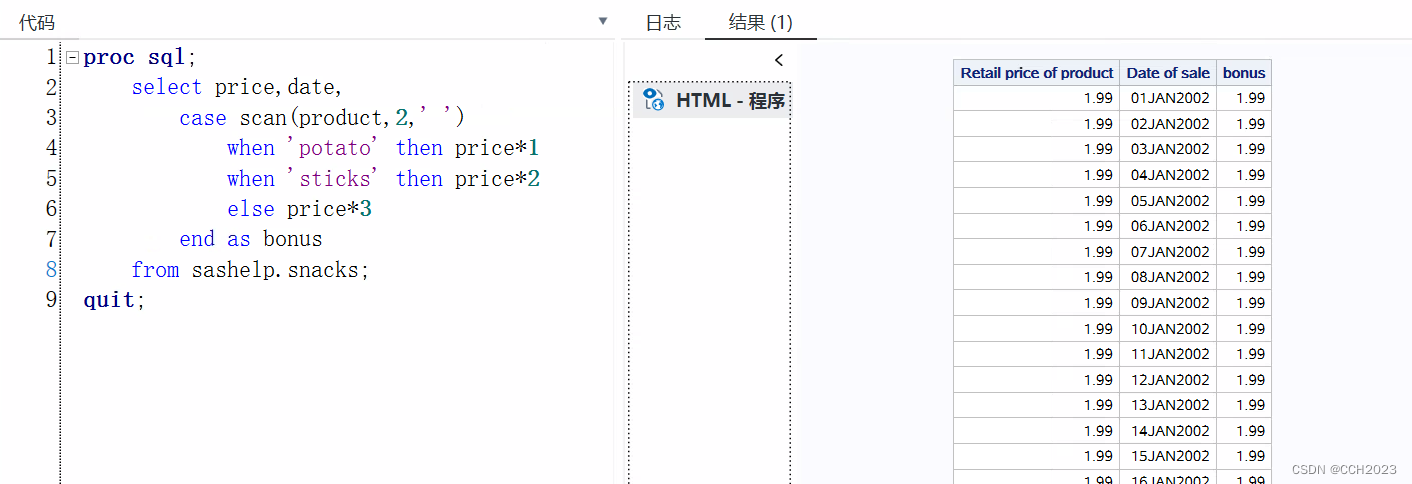
1)scan可以过滤变量第几位;
2)该数据集比较大,所以运行稍微慢点;
3)如果条件统一,可以这么写,如果条件不统一:

可以使用这种方法来进行。
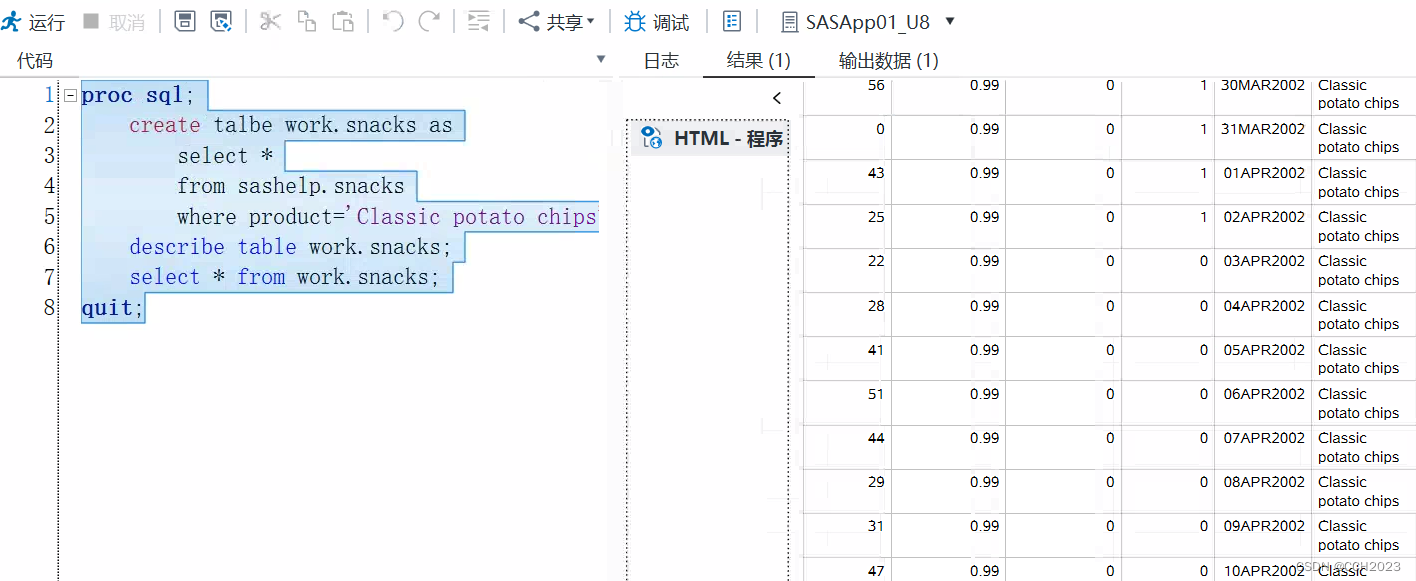
create table语句:

代码说明:
1)每个语句都是独立运行的;如果describe语句不正确,不影响上面语句的执行;
2)如果我不想打开work,然后再去看我的数据集,