项目收益
- 整体开发效率提升20%。
- 加快首屏渲染速度,减少白屏时间,弱网环境下页面打开速度提升40%。
权衡
在选择使用SSR之前,需要考虑以下事项!
- SSR需要可以运行Node.js的服务器,学习成本相对较高。
- 对于服务器而言,比仅提供静态文件,必须处理更高负载,考虑页面缓存等问题。
- 一套代码两个执行环境。beforeCreate 和created 生命周期在服务器端渲染和客户端都会执行,如果在两套环境中加入具有副作用的代码或特定平台的API,会引起问题。
推荐在实践之前先了解官方文档,可以对vue ssr有一定的认知。
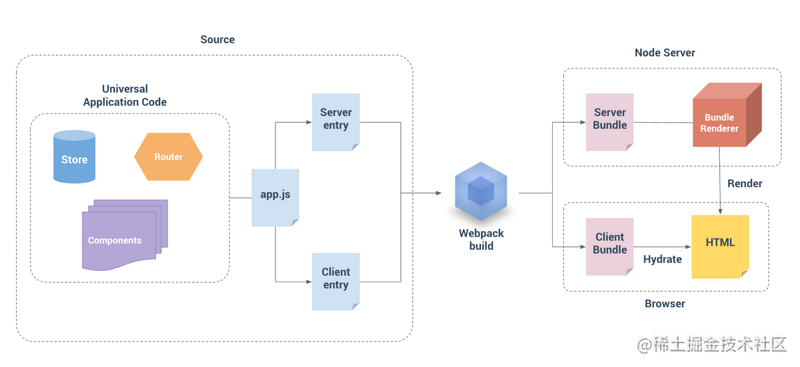
首先搭建一个简单的 SSR 服务
安装依赖
yarn add vue vue-server-renderer koa
复制代码vue-server-renderer 是vue srr 服务器端渲染的核心模块,我们会使用koa搭建服务器。
const Koa = require('koa');
const server = new Koa();
const Vue = require('vue');
const renderer = require('vue-server-renderer').createRenderer();
const router = require('koa-router')();
const app = new Vue({
data: {
msg: 'vue ssr'
},
template: '<div>{{msg}}</div>'
});
router.get('*', (ctx) => {
// 将 Vue 渲染为 HTML后返回
renderer.renderToString(app, (err, html) => {
if (err) {
throw err;
}
ctx.body = html;
})
});
server.use(router.routes()).use(router.allowedMethods());
module.exports = server;
复制代码这样一个简单的服务器端渲染就实现了。
ssr 具体实现
在上面ssr服务的基础上,将逐步完善为实际应用的程序。
- 目录结构
app
├── src
│ ├── components
│ ├── router
│ ├── store
│ ├── index.js
│ ├── App.vue
│ ├── index.html
│ ├── entry-server.js // 运行在服务器端
│ └── entry-client.js // 运行在浏览器
└── server
├── app.js
└── ssr.js
复制代码2、由于服务器端和客户端的差异,需要由不同的入口函数来实现。 这两个入口函数分别是entry-server.js和entry-client.js。
服务器端入口文件:
import cookieUtils from 'cookie-parse';
import createApp from './index.js';
import createRouter from './router/router';
import createStore from'./store/store';
export default context => {
return new Promise((resolve, reject) => {
const router = createRouter();
const app = createApp({ router });
const store = createStore({ context });
const cookies = cookieUtils.parse(context.cookie || '');
// 设置服务器端 router 的位置
router.push(context.url);
// 等到 router 将可能的异步组件和钩子函数解析完
router.onReady(() => {
const matchedComponents = router.getMatchedComponents();
if (!matchedComponents.length) {
return reject(new Error('404'));
}
// 对所有匹配的路由组件调用 asyncData,进行数据预取。
Promise.all(
matchedComponents.map(({ asyncData }) => {
asyncData && asyncData({
store,
route: router.currentRoute,
cookies,
context: {
...context,
}
})
})
)
.then(() => {
context.meta = app.$meta;
context.state = store.state;
resolve(app);
})
.catch(reject);
}, () => {
reject(new Error('500 Server Error'));
});
});
}
复制代码客户端入口文件:
import createApp from './index.js';
import createRouter from './router/router';
export const initClient = () => {
const router = createRouter();
const app = createApp({ router });
const cookies = cookieUtils.parse(document.cookie);
router.onReady(() => {
if (window.__INITIAL_STATE__) {
store.replaceState(window.__INITIAL_STATE__);
}
// 添加路由钩子函数,用于处理 asyncData.
// 在初始路由 resolve 后执行,
// 以便我们不会二次预取(double-fetch)已有的数据。
// 使用 `router.beforeResolve()`,以便确保所有异步组件都 resolve。
router.beforeResolve((to, from, next) => {
const matched = router.getMatchedComponents(to);
const prevMatched = router.getMatchedComponents(from);
// 我们只关心非预渲染的组件
// 所以我们对比它们,找出两个匹配列表的差异组件
let diffed = false;
const activated = matched.filter((c, i) => {
return diffed || (diffed = (prevMatched[i] !== c))
});
if (!activated.length) {
return next()
}
Promise.all(activated.map(c => {
if (c.asyncData) {
// 将cookie透传给数据预取的函数,在服务器进行数据预取时需要手动将cookie传给后端服务器。
return c.asyncData({
store,
route: to,
cookies,
context: {
}
})
}
})).then(() => {
next()
}).catch(next)
});
app.$mount('#app')
});
}
复制代码3、改造app.js适应ssr
由于nodejs服务器是一个长期运行的进程,当代码进入该进程时,会进行一次取值并保留在内存中,这将导致请求会共享一个单利对象。为了避免这个问题,程序采用暴露一个重复执行的工厂函数,为每个请求创建不同的实例。
import Vue from 'vue';
import App from './App.vue';
export default function createApp({ router }) {
const app = new Vue({
router,
render: h => h(App),
});
return app;
};
复制代码4、自动加载router 和 store 模块。
一个spa项目,由于router和store都是在统一的入口文件里管理,我们根据项目需要把各个功能模块的相关store和router拆分开来,当项目变大之后,每次手动修改import会产生很多副作用,为了减少修改store和router入口引起的副作用,需要自动加载项目的router和store。下面是store的实现,router实现和store类似。
// store 实现
// ...
// 使用require.context匹配出module模块下的所有store,一次性加载到router里面。
const storeContext = require.context('../module/', true, /\.(\/.+)\/js\/store(\/.+){1,}\.js/);
// ...
const getStore = (context) => {
storeContext.keys().filter((key) => {
const filePath = key.replace(/^(\.\/)|(js\/store\/)|(\.js)$/g, '');
let moduleData = storeContext(key).default || storeContext(key);
const namespaces = filePath.split('/');
moduleData = normalizeModule(moduleData, filePath);
store.modules = store.modules || {};
const storeModule = getStoreModule(store, namespaces); // 递归创建模块
VUEX_PROPERTIES.forEach((property) => {
mergeProperty(storeModule, moduleData[property], property); // 将每个模块的store统一挂载管理
});
return true;
});
};
export default ({ context }) => {
getStore(context);
return new Vuex.Store({
modules: {
...store.modules,
},
});
};
复制代码5、 webpack 构建配置
├── webpack.base.conf.js // 通用配置
├── webpack.client.conf.js // 客户端打包配置
├── webpack.server.conf.js // 服务器端打包配置
复制代码webpack.base.conf.js 是构建项目的通用配置,可以根据需要修改相应的配置,这里说一下 webpack.client.conf.js和webpack.server.conf.js的配置。
webpack.server.conf.js 配置
通过VueSSRServerPlugin插件会生成服务器bundle对象,默认是vue-ssr-server-bundle.json,里面盛放着服务器的整个输出。
const merge = require('webpack-merge');
const nodeExternals = require('webpack-node-externals');
const VueSSRServerPlugin = require('vue-server-renderer/server-plugin');
const path = require('path');
const baseConfig = require('./webpack.base.conf.js');
const resolve = (src = '') => path.resolve(__dirname, './', src);
const config = merge(baseConfig, {
entry: {
app: ['./src/entry-server.js'],
},
target: 'node',
devtool: 'source-map',
output: {
filename: '[name].js',
publicPath: '',
path: resolve('./dist'),
libraryTarget: 'commonjs2'
},
externals: nodeExternals({
// 告诉Webpack不要捆绑这些模块或其任何子模块
}),
plugins: [
new VueSSRServerPlugin(),
]
});
module.exports = config;
复制代码webpack.client.conf.js配置
客户端构建和服务器端类似,是通过VueSSRClientPlugin插件来生成客户端构建清单vue-ssr-client-manifest.json,里面包含了所有客户端需要的静态资源以及依赖关系。因此可以自动推断和注入资源以及数据预取等。
const VueSSRClientPlugin = require('vue-server-renderer/client-plugin');
const merge = require('webpack-merge');
const webpack = require('webpack');
const baseConfig = require('./webpack.base.conf');
const UploadPlugin = require('@q/hj-webpack-upload'); // 将首次加载和按需加载的资源上传到cdn(在开源基础上二次开发)
const path = require('path');
const resolve = (src = '') => path.resolve(__dirname, './', src);
const config = merge(baseConfig, {
...baseConfig,
entry: {
app: ['./src/entry-client.js'],
},
target: 'web',
output: {
filename: '[name].js',
path: resolve('./dist'),
publicPath: '',
libraryTarget: 'var',
},
plugins: [
new VueSSRClientPlugin(),
new webpack.HotModuleReplacementPlugin(),
new UploadPlugin(cdn, {
enableCache: true, // 缓存文件
logLocal: false,
src: path.resolve(__dirname, '..', Source.output),
dist: path.resolve(__dirname, '..', Source.output),
beforeUpload: (content, location) => {
if (path.extname(location) === '.js') {
return UglifyJs.minify(content, {
compress: true,
toplevel: true,
}).code;
}
return content;
},
compilerHooks: 'done',
onError(e) {
console.log(e);
},
}),
],
});
module.exports = config;
复制代码5、SSR服务器端实现
下面是基于koa实现的ssr服务器端,app.js 主要是搭建服务器环境,ssr的实现是在ssr.js中,通过一个中间件的形式和主程序关联。
// ssr.js
//...
// 将bundle渲染为字符串。
async render(context) {
const renderer = await this.getRenderer();
return new Promise((resolve, reject) => {
// 获取到首次渲染的字符串
renderer.renderToString(context, (err, html) => {
if (err) {
reject(err);
} else {
resolve(html);
}
});
});
}
// 获取renderer对象
getRenderer() {
return new Promise((resolve, reject) => {
// 读取模板文件和之前通过构建生成的服务器端和客户端json文件
const htmlPath = `${this.base}/index.html`;
const bundlePath = `${this.base}/vue-ssr-server-bundle.json`;
const clientPath = `${this.base}/vue-ssr-client-manifest.json`;
fs.stat(htmlPath, (statErr) => {
if (!statErr) {
fs.readFile(htmlPath, 'utf-8', (err, template) => {
const bundle = require(bundlePath);
const clientManifest = require(clientPath);
// 生成renderer对象
const renderer = createBundleRenderer(bundle, {
template,
clientManifest,
runInNewContext: false,
shouldPrefetch: () => {
return false;
},
shouldPreload: (file, type) => {
return false;
},
});
resolve(renderer);
});
} else {
reject(statErr);
}
});
});
}
// ...
// app.js
const Koa = require('koa');
const server = new Koa();
const router = require('koa-router')();
const ssr = require('./ssr');
server.use(router.routes()).use(router.allowedMethods());
server.use(ssr(server));
// 错误处理
app.on('error', (err, ctx) => {
console.error('server error', err, ctx);
});
module.exports = server;
复制代码以上便是vue ssr的简单实现,实际项目中需要完善各种项目需要的配置。
下面在此基础上说几个问题。
- 上面提到过,vue的生命周期函数中,只有beforeCreate和created会在服务器端渲染时被调用,并且程序一直存在于服务器并不会销毁,挡在这两个生命周期中产生副作用的代码时,比如在其中使用了setTimeout或setInterval就会产生副作用,为了避免这些问题,可以将产生副作用的代码放到vue的其他生命周期中。服务端没有window、document对象, 如果再服务器端使用就会报错中断,所以需要根据运行环境做相应的兼容处理。
- 预取数据时cookie穿透的问题。
在服务器端asyncData预取数据时,不会把客户端请求中的cookie带上,所以需要手动将客户端中的cookie在预取数据时加到请求头部。 - 在spa中需要动态修改页面的head标签以便利于搜索引擎,这里推荐使用vue-meta。
// src/index.js
// ...
Vue.use(Meta);
// ...
// entry-server.js
// ...
context.meta = app.$meta();
// ...
复制代码部署方案
在完成整体代码的开发后 , 我们还需要考虑部署问题 。 在之前的活动 SSR 改造中 , 我们通过外部负载均衡到各服务器 , 在各服务器上使用 PM2 对各个服务器上的 Node 进程进行管理 。 这种方式在实际使用中存在一些问题 。
-
运行环境
- 人肉运维 。 手动在运行服务器上配置相关环境 ( Node 、 PM2 ) 。 后续如果遇到需要扩容 、 更新环境依赖时 , 需要同步人工同步各服务器之间环境 。
- 本地开发环境与服务端环境需完全一致 。 出现过不一致导致的问题 。 概率较小但需谨慎对待
-
运维
- 回滚机制 , 现在的回滚机制是相当于发布一个新版本到线上 , 重新触发 CI 发布流程 。 如果是运行环境出现了问题 , 是比较棘手的 。 没办法快速的先回滚到指定版本和环境 。
为了解决以上提到的一些问题 。 我们引入了新的技术方案 。
-
Docker : 容器技术 。 轻量级 、 快速的 ”虚拟化“ 方案
-
Kubernetes : 容器编排方案
使用 Docker 接入整个开发 、 生产 、 打包流程 , 保证各运行环境一致 。
使用 Kubernetes 作为容器编排方案。
整合后 , 大概方案流程如下
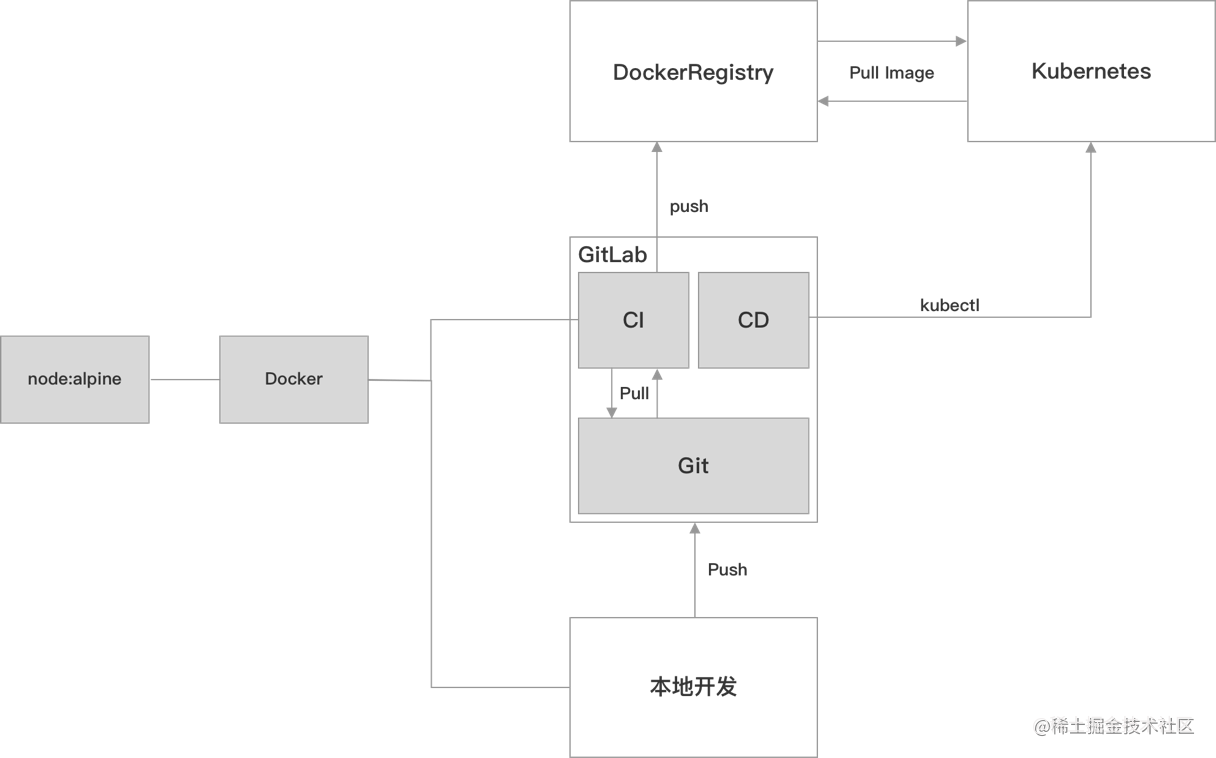
- 本地开发时使用 Docker 开发
- 推送代码至 Gitlab 触发 CI
- CI 基于基础镜像打包 , 每个 COMMIT ID 对应一个镜像 , 推送至私有仓库 ,触发 CD
- CD 通过 kubectl 控制 K8s 集群更新应用
整个开发 、 打包 、 部署上都使用了 Docker , 以此来保证所有阶段的环境一致 。
本地开发
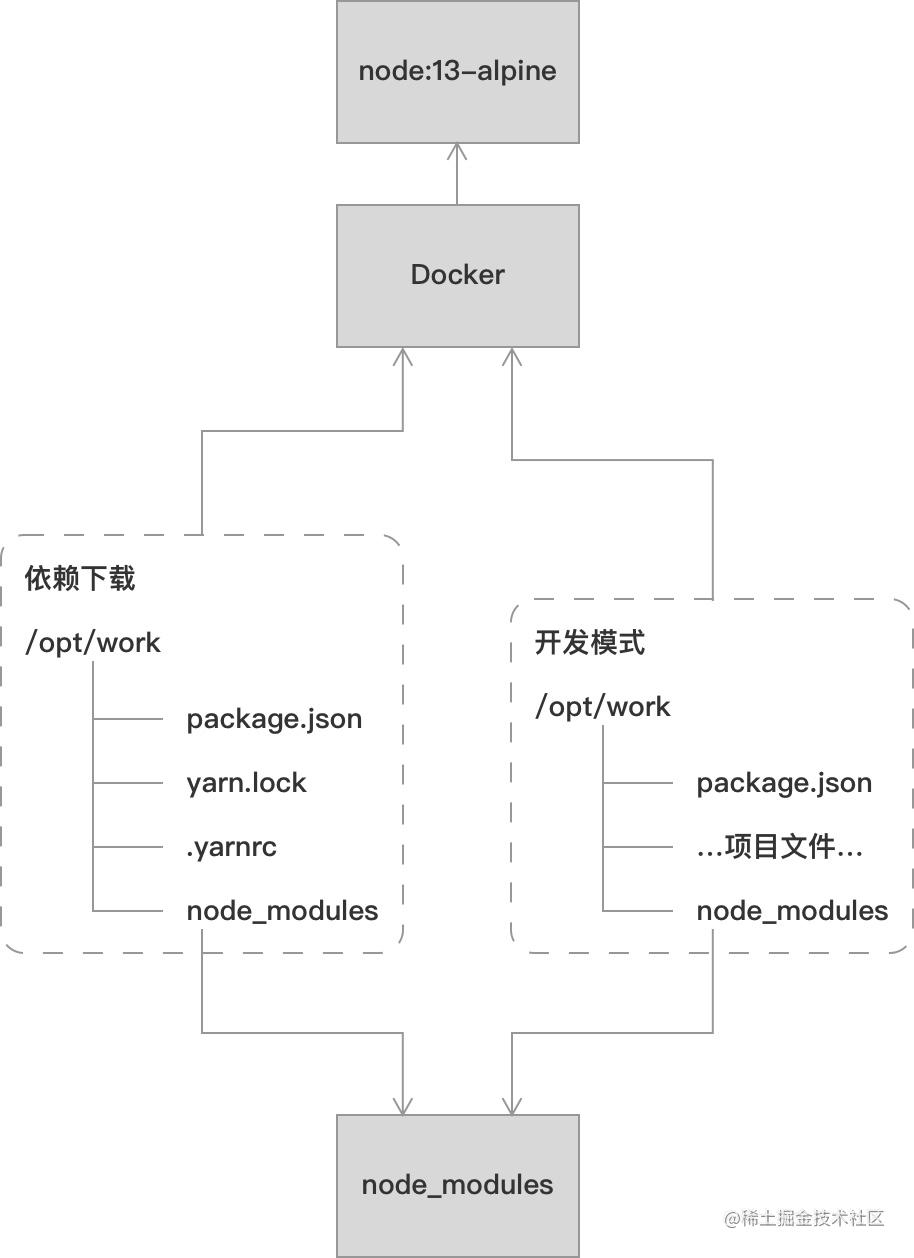
在本地开发阶段 , 我们将依赖下载及开发模式分开 。
# 依赖下载
docker run -it \
-v $(pwd)/package.json:/opt/work/package.json \
-v $(pwd)/yarn.lock:/opt/work/yarn.lock \
-v $(pwd)/.yarnrc:/opt/work/.yarnrc \
# 挂载 package.json 、 yarn.lock 、 .yarnrc 到 /opt/work/ 下
-v mobile_node_modules:/opt/work/node_modules \
# /opt/work/node_modules 挂载为 mobile_node_modules 数据卷
--workdir /opt/work \
--rm node:13-alpine \
yarn
复制代码在依赖下载中 , 思路是将 node_modules 目录作为一个数据卷 。 在需要使用时将其挂载到指定目录下 , 之后只需要将会影响到依赖下来的相关文件挂载到容器中 , 将 node_modules 数据卷挂载到文件夹 。 这样子就能持久化存储依赖文件 。
# 开发模式
docker run -it \
-v $(pwd)/:/opt/work/ \
# 挂载项目目录至 / opt/work/ 下
-v mobile_node_modules:/opt/work/node_modules \
# 挂载 node_modules 数据卷到 /opt/work/node_modules 目录下
--expose 8081 -p 8081:8081 \ # HotReload Socket
--expose 9229 -p 9229:9229 \ # debugger
--expose 3003 -p 3003:3003 \ # Node Server
# 暴露各个端口
--workdir /opt/work \
node:13-alpine \
./node_modules/.bin/nodemon --inspect=0.0.0.0:9229 --watch server server/bin/www
复制代码开发模式下 , 我们只需要将之前的 node_modules 数据卷挂载到 node_modules 目录 , 再将项目目录挂载到容器中 。 暴露指定端口即可开始开发 。 这里 8081 为写死的 HotReload Socket 接口 、 3003 为 Node 服务接口 、 9229 为 debugger 接口 。 再把启动命令设置为开发模式指令就可以正常开发 。
开发完成后 , 我们推送代码 , 触发 CI 。
CI
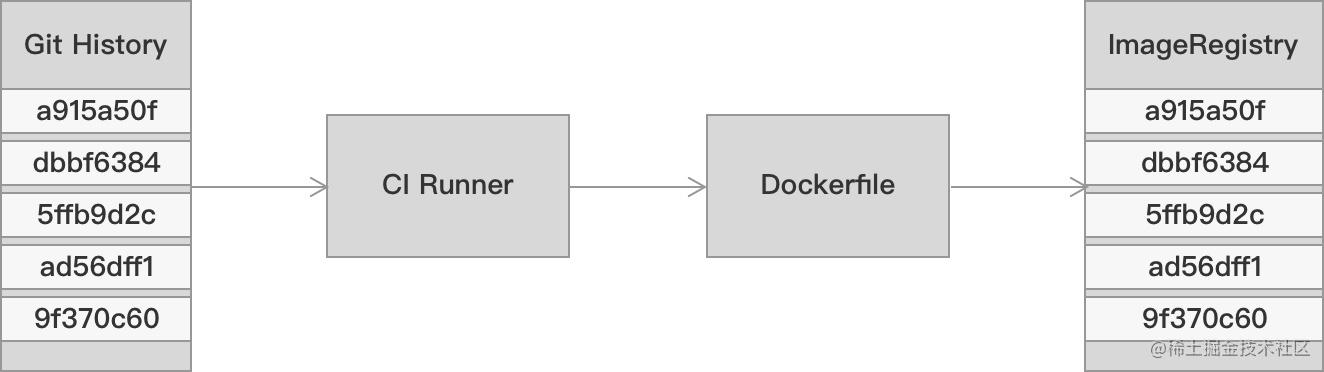
上面是我们的 CI 流程 。
在 CI 阶段 , 我们通过 Dockerfile 为每一次提交记录都生成一个与之对应的镜像 。 这样做的好处在于我们能随时通过提交记录找到对应的镜像进行回滚 。
FROM node:13-alpine
COPY package.json /opt/dependencies/package.json
COPY yarn.lock /opt/dependencies/yarn.lock
COPY .yarnrc /opt/dependencies/.yarnrc
RUN cd /opt/dependencies \
&& yarn install --frozen-lockfile \
&& yarn cache clean \
&& mkdir /opt/work \
&& ln -s /opt/dependencies/node_modules /opt/work/node_modules
# 具体文件处理
COPY ci/docker/docker-entrypoint.sh /usr/bin/docker-entrypoint.sh
COPY ./ /opt/work/
RUN cd /opt/work \
&& yarn build
WORKDIR /opt/work
EXPOSE 3003
ENV NODE_ENV production
ENTRYPOINT ["docker-entrypoint.sh"]
CMD ["node", "server/bin/www"]
复制代码上面是我们使用到的一个 Dockerfile 。
- 使用 node:13-alpine 作为基础镜像
- 复制依赖相关文件到容器中下载依赖 , node_modules 软连接到 /opt/work 下 。 清理安装缓存
- 复制项目文件到容器中 , 执行客户端代码打包命令
- 设置环境变量 , 对外暴露服务端口 , 设置镜像启动命令
docker build -f Dockerfile --tag frontend-mobile:COMMIT_SHA .
复制代码最后使用以上命令将该版本打包为一个镜像 , 推送至私有仓库 。
我们在 Dockerfile 优化编译速度及镜像体积时使用到的一些技巧:
- 前置合并不变的操作 , 将下载依赖和编译分开为两个RUN 指令 , 可以利用 Docker 的层缓存机制 。 在依赖不变的情况下 , 跳过依赖下载部分 , 直接使用之前的缓存。
- 每次操作后清理不需要的文件 , 如 yarn 生成的全局缓存 ,这些缓存不会影响到我们程序的运行 。 还有很多包管理工具也会生成一些缓存 , 按各种需要清理即可 。
- ‘.dockerignore’ 中忽略不影响到编译结果的文件 , 下次这些文件变动时 , 打包会直接使用之前的镜像 , 改个 README 或者一些 K8s 发布配置时就不会重新打包镜像 。
在打包完成后 , 我们推送镜像至私有仓库 , 触发 CD 。
CD
部署阶段 , 我们使用 Kubernetes 进行容器编排 。引用官方介绍
K8s 是用于自动化部署 , 扩展和管理容器化应用程序的开源系统 。
K8s 非常的灵活且智能 。 我们只需要描述我们需要怎么样的应用程序 。 K8s 就会根据资源需求和其他约束自动放置容器 。括一些自动水平扩展 , 自我修复 。能方便我们去追踪监视每个应用程序运行状况 。
我们使用的目的很简单 , 就是自动运维还有非侵入式日志采集和应用监控 。
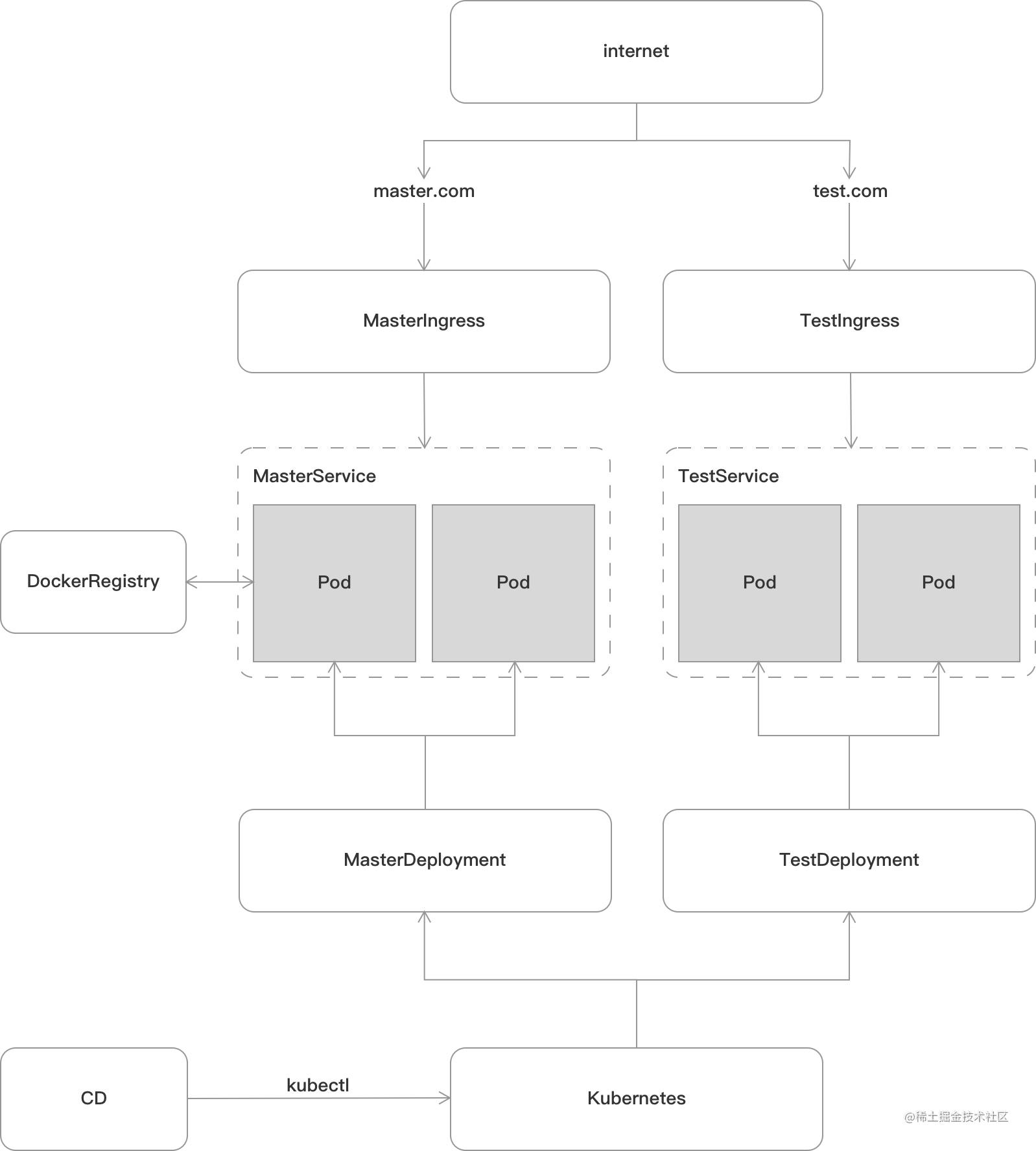
Deployment 表示一个期望状态 。 描述需要的应用需求 。
Service 负责对外提供一个稳定的入口访问我们的应用服务或一组 Pod 。
Ingress 路由 , 外部的请求会先到达 Ingress 。 由它按照已经制定好的规则分发到不同的服务 。
Pod 在集群中运行的进程 , 是最小的基本执行单元 。
CD 容器通过 kubectl 控制 K8s 集群 。在每个分支提交代码触发 CD 之后 , 会为每个分支单独创建一个 Deployment 。 对应每个分支环境 。通过 Service 暴露一组指定 Deployment 对应的 Pod 服务 , Pod 运行的是 Deployment 指定的应用镜像 。最后使用 Ingress 根据域名区分环境对外提供服务 。
K8s 配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend-mobile # deployment 名称
namespace: mobile # 命名空间
labels:
app: frontend-mobile # 标签
spec:
selector:
matchLabels:
# 对应的 Pod 标签, 被其选择的 Pod 的现有副本集将受到此部署的影响
app: frontend-mobile
replicas: 8 # Pod 节点数量, 默认为 1
template: # 相当于 Pod 的配置
metadata:
name: frontend-mobile # Pod 名称
labels:
app: frontend-mobile # Pod 标签
spec:
containers:
- name: frontend-mobile
image: nginx:latest
ports:
- containerPort: 3003
resources: # 设置资源限制
requests:
memory: "256Mi"
cpu: "250m" # 0.25 个cpu
limits:
memory: "512Mi"
cpu: "500m" # 0.5 个cpu
livenessProbe:
httpGet:
path: /api/serverCheck
port: 3003
httpHeaders:
- name: X-Kubernetes-Health
value: health
initialDelaySeconds: 15
timeoutSeconds: 1
---
apiVersion: v1
kind: Service
metadata:
name: frontend-mobile # Service 名称
namespace: mobile # 命名空间
labels:
app: frontend-mobile # 标签
spec:
selector:
app: frontend-mobile # 对应的 Pod 标签
ports:
- protocol: TCP
port: 8081 # 服务端口
targetPort: 3003 # 代理端口
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: frontend-mobile
namespace: mobile # 命名空间
labels:
app: frontend-mobile # 标签
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /
spec:
rules:
- host: local-deploy.com
http:
paths:
- path: /
backend:
serviceName: frontend-mobile # 引用的服务名称
servicePort: 8081 # 引用的服务端口, 对应 Service 中的 port
复制代码在 Deployment 配置上选择资源配额小 , 数量多的方式进行部署 。把单个 Pod 资源配额设置小的原因是 SSR 服务容易内存泄漏 , 设置小一些可以在出现内存泄漏问题时直接将 Pod 重启 。 在排查到问题之前先解决暂时解决服务问题 。
其他配置可自行参考官方文档 , 不过多介绍 。
kubernetes.io/docs/refere…
至此 , 部署流程已全部结束 。
更多工作
Gitlab 联动 Kubernetes
日志收集
AliNode 接入
绵薄之力【软件测试全套资源分享】
最后感谢每一个认真阅读我文章的人,看着粉丝一路的上涨和关注,礼尚往来总是要有的,虽然不是什么很值钱的东西,如果你用得话可以直接拿走 【保证100%免费】
这些资料,对于从事【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴我走过了最艰难的路程,希望也能帮助到你!凡事要趁早,特别是技术行业,一定要提升技术功底。希望对大家有所帮助……