一、start_armboot 函数简介

1、一个很长的函数
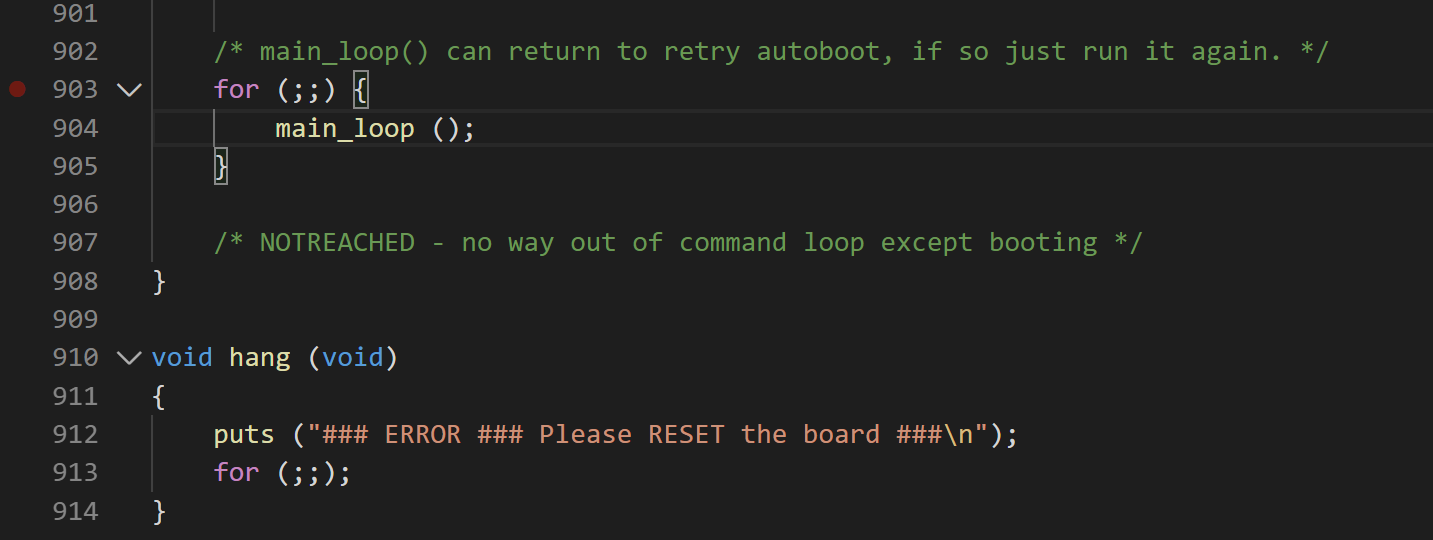
(1) 这个函数在 uboot/lib_arm/board.c 的第 444 行开始到 908 行结束。
(2) 450 行还不是全部,因为里面还调用了别的函数。
(3)为什么这么长的函数,怎么不分成两三个函数?主要因为这个函数整个构成了 uboot 启动的第二阶段。
2、一个函数组成 uboot 第二阶段
3、宏观分析:uboot 第二阶段应该做什么
(1) 概括来讲,uboot 第一阶段主要就是初始化了 SoC 内部的一些部件(譬如看门狗、时钟),然后初始化 DDR 并且完成重定位。
(2) 由宏观分析来讲,uboot 的第二阶段就是要初始化剩下的还没被初始化的硬件。主要是 SoC 外部硬件(譬如 iNand、网卡芯片····)、uboot 本身的一些东西(uboot 的命令、环境变量等····)。然后最终初始化完必要的东西后,进入 uboot 的命令行准备接受命令。
4、思考:uboot 第二阶段完结于何处?
(1) uboot 启动后自动运行打印出很多信息(这些信息就是 uboot 在第一和第二阶段不断进行初始化时,打印出来的信息)。然后 uboot 进入了倒数 bootdelay 秒,然后执行 bootcmd 对应的启动命令。
(2) 如果用户没有干涉,则会执行 bootcmd 进入自动启动内核流程(uboot 就死掉了);此时用户可以按下回车键打断 uboot 的自动启动,进入到 uboot 的命令行下。然后 uboot 就一直工作在命令行下。
(3) uboot 的命令行就是一个死循环,循环体内不断重复:接收命令、解析命令、执行命令。这就是 uboot 最终的归宿。
二、start_armboot 解析1
1、init_fnc_t


(1) typedef int (init_fnc_t) (void); 这是一个函数类型。
(2) init_fnc_ptr 是一个二重函数指针,回顾高级 C 语言中讲过:二重指针的作用有 2 个(其中一个是用来指向一重指针),一个是用来指向指针数组。因此这里的 init_fuc_ptr可以用来指向一个函数指针数组。
2、DECLARE_GLOBAL_DATA_PTR

(1) #define DECLARE_GLOBAL_DATA_PTR register volatile gd_t *gd asm ("r8")
定义了一个全局变量名字叫 gd,这个全局变量是一个指针类型,占 4 字节。用 volatile 修饰表示可变的,用 register 修饰表示这个变量要尽量放到寄存器中,后面的 asm(“r8”)是 gcc 支持的一种语法,意思就是要把 gd 放到寄存器 r8 中。
(2) 综合分析,DECLARE_GLOBAL_DATA_PTR 就是定义了一个要放在寄存器 r8 中的全局变量,名字叫 gd,类型是一个指向 gd_t 类型变量的指针。
(3) 为什么要定义为 register?因为这个全局变量 gd(global data 的简称)是 uboot 中很重要的一个全局变量(准确的说这个全局变量是一个结构体,里面有很多内容,这些内容加起来构成的结构体就是 uboot 中常用的所有的全局变量),这个 gd 在程序中经常被访问,因此放在 register 中提升效率。因此纯粹是运行效率方面考虑,和功能要求无关。并不是必须的。

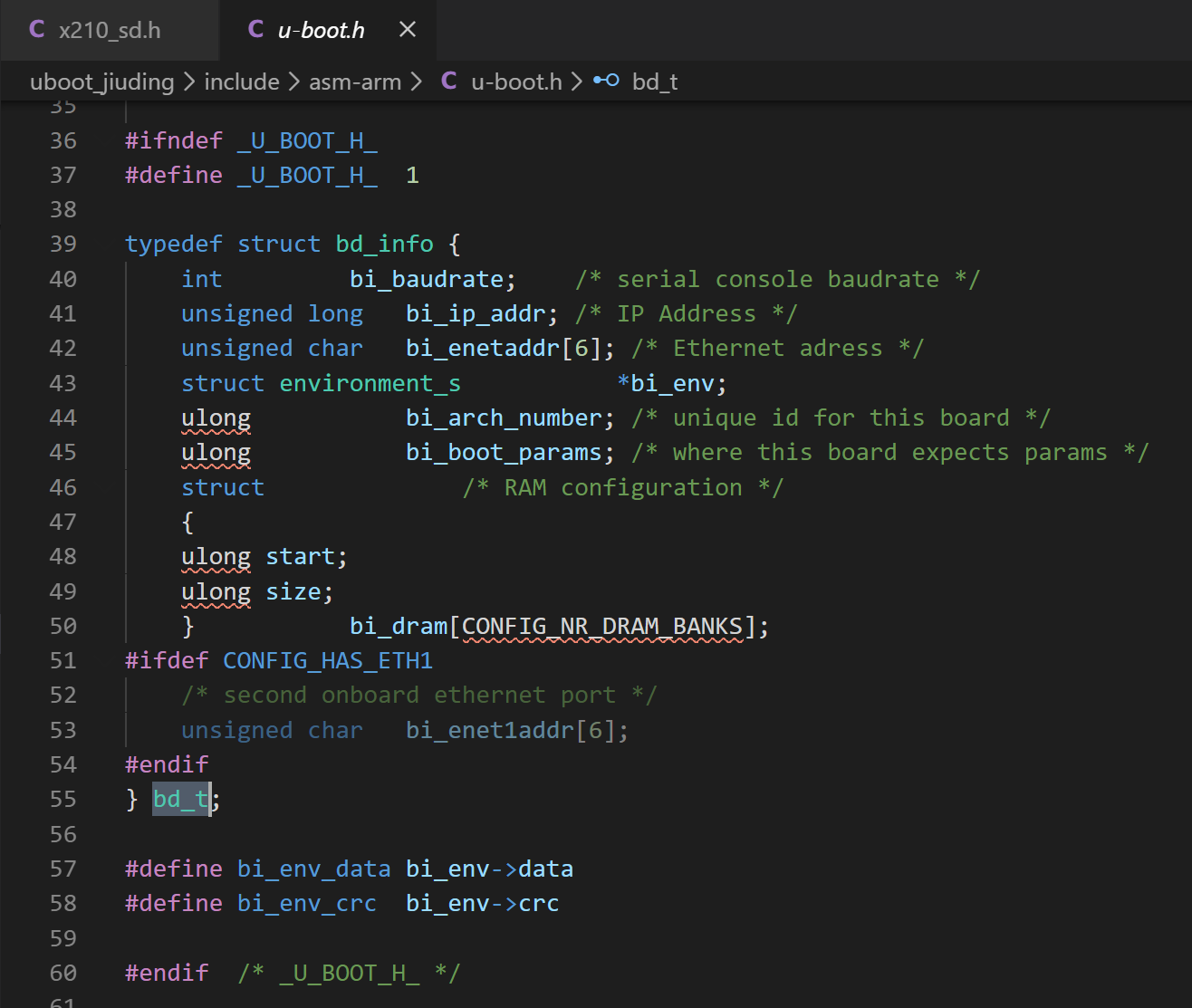
(4) gd_t 定义在 include/asm-arm/global_data.h 中。
gd_t 中定义了很多全局变量,都是整个 uboot 使用的;其中有一个 bd_t 类型的指针,指向一个 bd_t 类型的变量,这个 bd 是开发板的板级信息的结构体,里面有不少硬件相关的参数,譬如波特率、IP 地址、机器码、DDR 内存分布。
三、内存使用排布
1、为什么要分配内存
(1) DECLARE_GLOBAL_DATA_PTR 只能定义了一个指针,也就是说 gd 里的这些全局变量并没有被分配内存,我们在使用 gd 之前要给他分配内存,否则 gd 也只是一个野指针而已。
(2) gd 和 bd 需要内存,内存当前没有被人管理(因为没有操作系统统一管理内存),大片的 DDR 内存散放着可以随意使用(只要使用内存地址直接去访问内存即可)。但是因为 uboot 中后续很多操作还需要大片的连着内存块,因此这里使用内存要本着够用就好,紧凑排布的原则。所以我们在 uboot 中需要有一个整体规划。
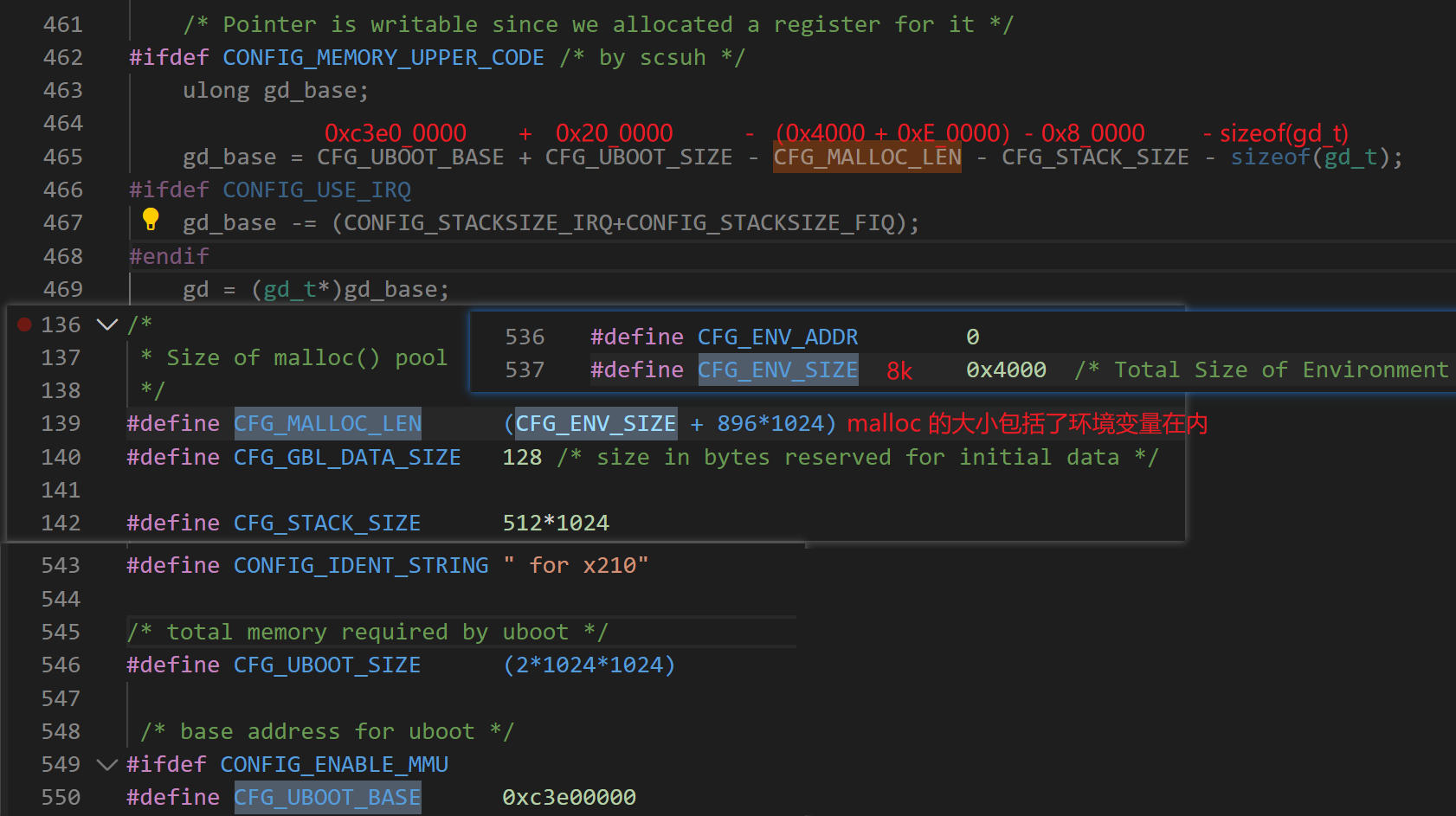
2、内存排布

(1) uboot 区: CFG_UBOOT_BASE ~ xx(长度为 uboot 的实际长度);
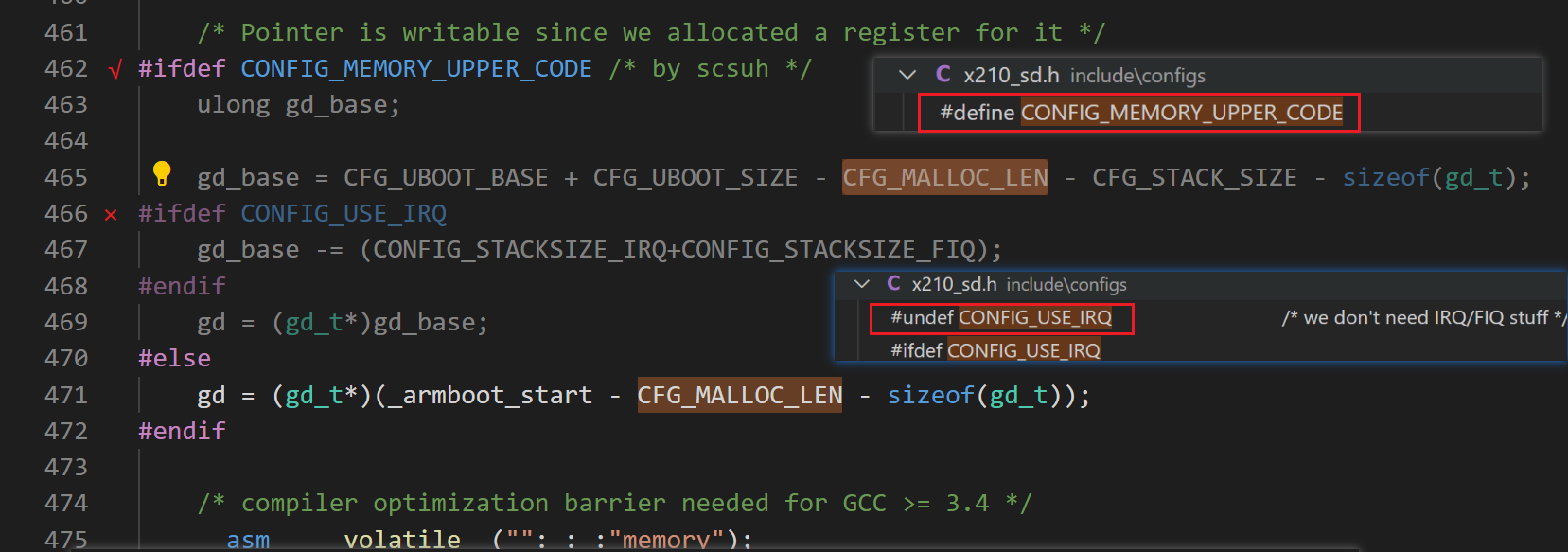
(2) 堆区: 长度为 CFG_MALLOC_LEN,实际为 912 KB;
(3) 栈区: 长度为 CFG_STACK_SIZE,实际为 512 KB;
(4) gd: 长度为 sizeof(gd_t),实际 36 字节;
(5) bd: 长度为 sizeof(bd_t),实际为 44 字节左右;
(6) 内存间隔: 为了防止高版本的 gcc 的优化造成错误。

四、start_armboot 解析2
1、for 循环执行 init_sequence

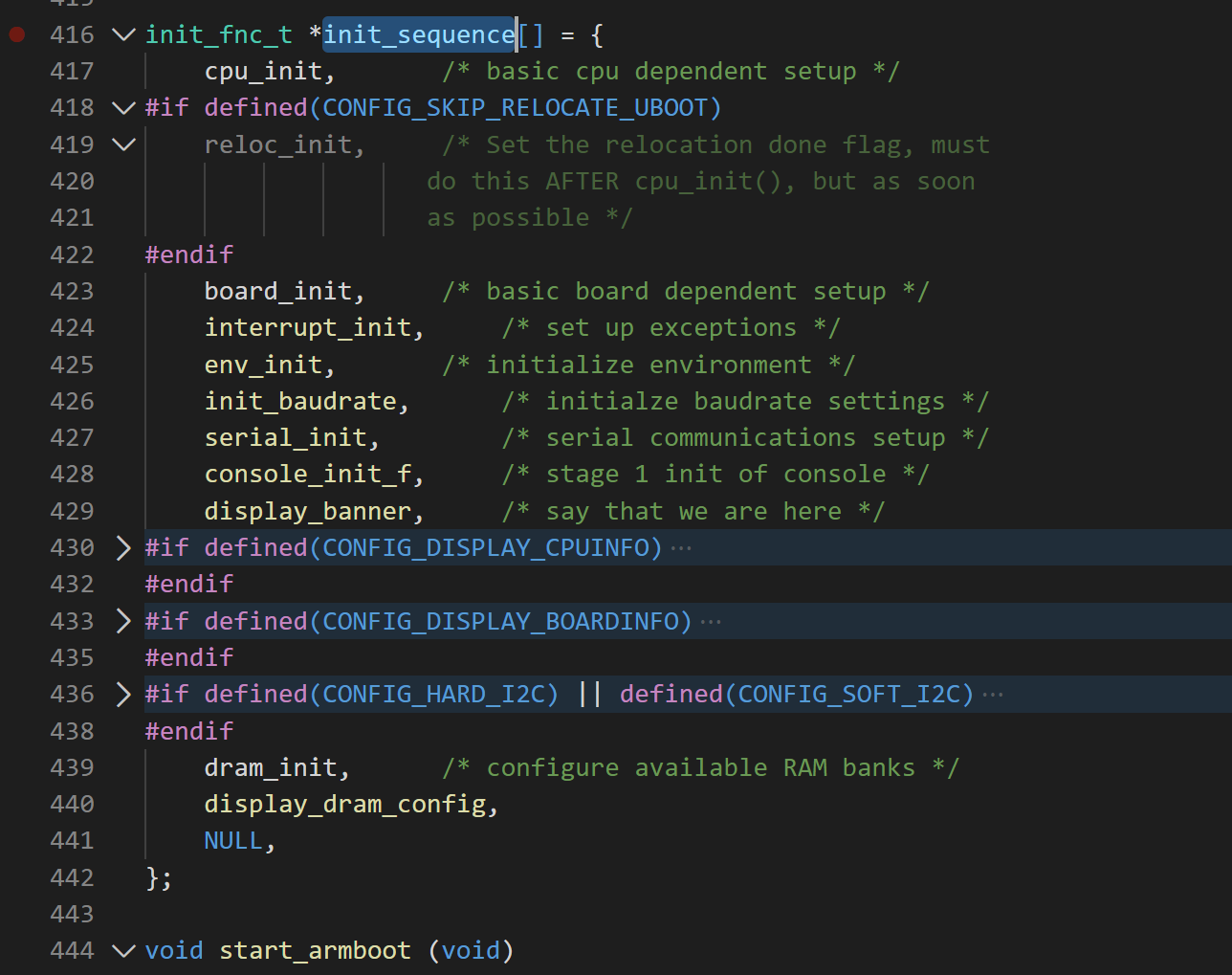
(1) init_sequence 是一个函数指针数组,数组中存储了很多个函数指针,这些指向的函数都是 init_fnc_t 类型(特征是接收参数是 void 类型,返回值是 int)。
(2) init_sequence 在定义时就同时给了初始化,初始化的函数指针都是一些函数名。(C 语言高级专题中讲过:函数名的实质)
(3) init_fnc_ptr 是一个二重函数指针,可以指向 init_sequence 这个函数指针数组。
(4) 用 for 循环肯定是想要去遍历这个函数指针数组(遍历的目的也是去依次执行这个函数指针数组中的所有函数)。思考:如何遍历一个函数指针数组?有 2 种方法:第一种也是最常用的一种,用下标去遍历,用数组元素个数来截至。第二种不常用,但是也可以。就是在数组的有效元素末尾放一个标志,依次遍历到标准处即可截至(有点类似字符串的思路)。
我们这里使用了第二种思路。因为数组中存的全是函数指针,因此我们选用了 NULL 来作为标志。我们遍历时从开头依次进行,直到看到 NULL 标志截至。这种方法的优势是不用事先统计数组有多少个元素。
(5) init_fnc_t 的这些函数的返回值定义方式一样的,都是:函数执行正确时返回 0,不正确时返回 -1。所以我们在遍历时去检查函数返回值,如果遍历中有一个函数返回值不等于0,则 hang() 挂起。从分析 hang 函数可知:uboot 启动过程中初始化板级硬件时不能出任何错误,只要有一个错误整个启动就终止,除了重启开发板没有任何办法。

(6) init_sequence 中的这些函数,都是 board 级别的各种硬件初始化。
2、cpu_init
(1) 看名字这个函数应该是 cpu 内部的初始化,所以这里是空的。
3、board_init
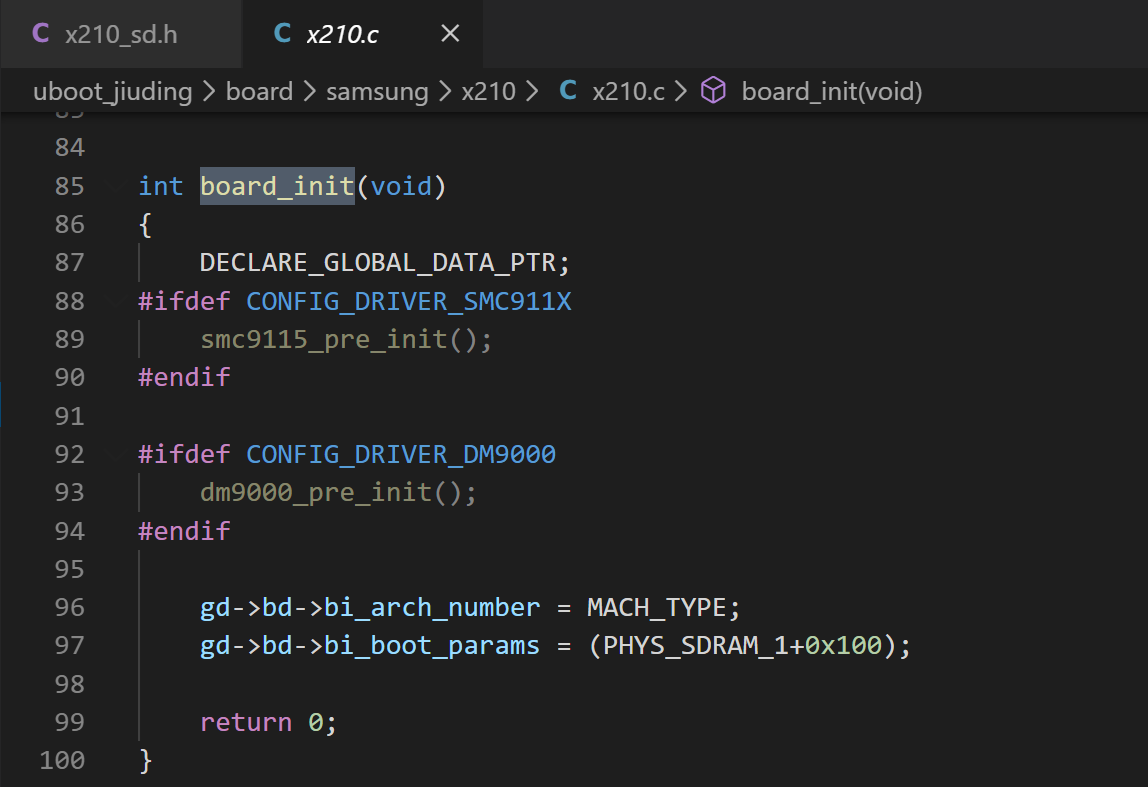
(1) board_init 在 uboot/board/samsung/x210/x210.c 中,这个看名字就知道是 x210 开发板相关的初始化。
(2) DECLARE_GLOBAL_DATA_PTR 在这里声明是为了后面使用 gd 方便。可以看出,把 gd 的声明定义成一个宏的原因就是,我们要到处去使用 gd,因此就要到处声明,定义成宏比较方便。

(3) 网卡初始化。CONFIG_DRIVER_DM9000 这个宏是 x210_sd.h 中定义的,这个宏用来配置开发板的网卡的。dm9000_pre_init 函数就是对应的 DM9000 网卡的初始化函数。开发板移植 uboot 时,如果要移植网卡,主要的工作就在这里。
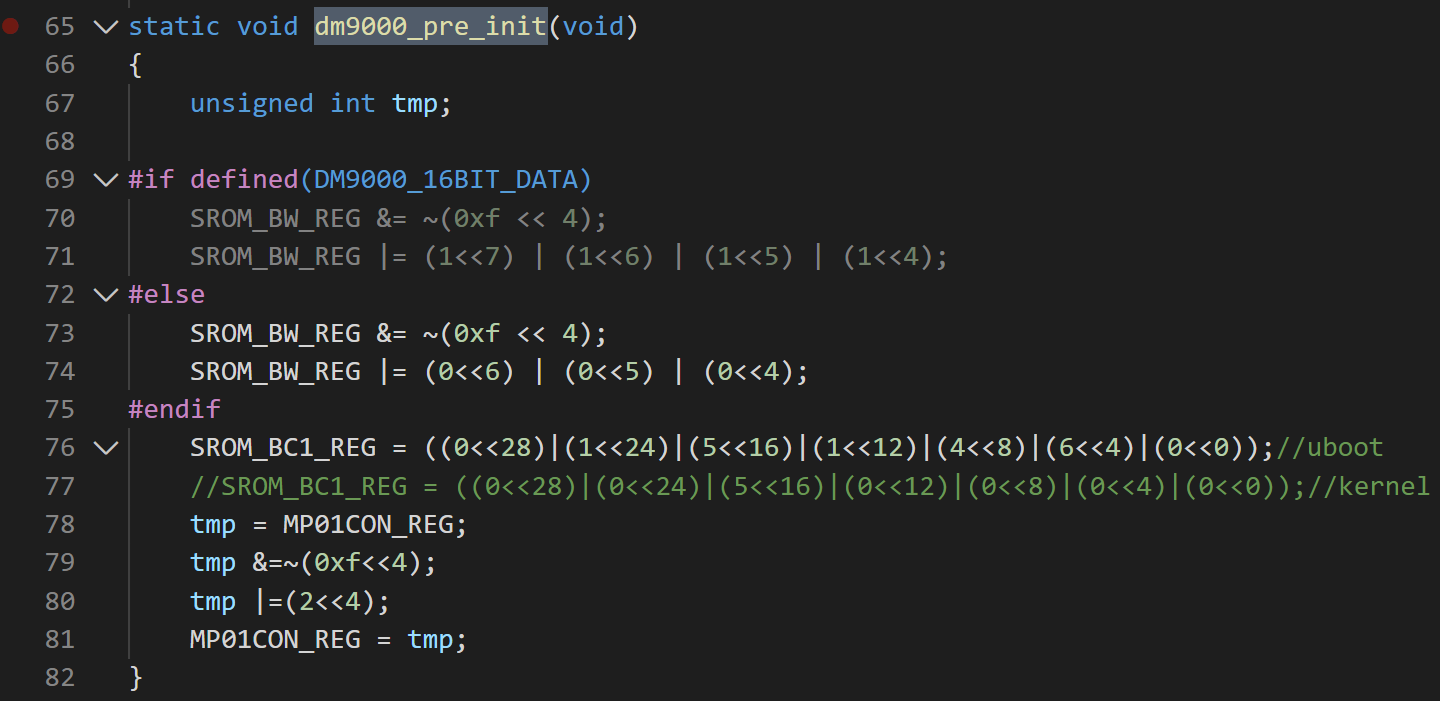
(4) 这个函数中主要是网卡的 GPIO 和端口的配置,而不是驱动。因为网卡的驱动都是现成的正确的,移植的时候驱动是不需要改动的,关键是这里的基本初始化。因为这些基本初始化是硬件相关的。
五、start_armboot 解析3

1、gd->bd->bi_arch_number
(1) bi_arch_number 是 board_info 中的一个元素,含义是:开发板的机器码。所谓机器码就是 uboot 给这个开发板定义的一个唯一编号。
(2) 机器码的主要作用就是,在 uboot 和 linux 内核之间进行比对和适配。
(3) 嵌入式设备中,每一个设备的硬件都是定制化的,不能通用。嵌入式设备的高度定制化,导致硬件和软件不能随便适配使用。这就告诉我们:这个开发板移植的内核镜像绝对不能下载到另一个开发板去,否则也不能启动,就算启动也不能正常工作,有很多隐患。因此 linux 做了个设置:给每个开发板做个唯一编号(机器码),然后在 uboot、linux 内核中都有一个软件维护的机器码编号。然后开发板、uboot、linux 三者去比对机器码,如果机器码对上了就启动,否则就不启动(因为软件认为我和这个硬件不适配)。
(4) MACH_TYPE 在 x210_sd.h 中定义,值是 2456,并没有特殊含义,只是当前开发板对应的编号。这个编号就代表了 x210 这个开发板的机器码,将来这个开发板上面移植的 linux 内核中的机器码也必须是 2456,否则就启动不起来。
(5) uboot 中配置的这个机器码,会作为 uboot 给 linux 内核的传参的一部分,传给 linux 内核,内核启动过程中会比对这个接收到的机器码,和自己本身的机器码相对比,如果相等就启动,如果不相等就不启动。
(6) 理论上来说,一个开发板的机器码不能自己随便定。理论来说有权利去发放这个机器码的只有 uboot 官方,所以我们做好一个开发板并且移植了 uboot 之后,理论上应该提交给 uboot 官方审核并发放机器码(好像是免费的)。但是国内的开发板基本都没有申请(主要是因为国内开发者英文都不行,和国外开源社区接触比较少),都是自己随便编号的。随便编号的问题就是有可能和别人的编号冲突,但是只要保证 uboot 和 kernel 中的编号是一致的,就不影响自己的开发板启动。
2、gd->bd->bi_boot_params
(1) bd_info 中另一个主要元素,bi_boot_params 表示 uboot 给 linux kernel 启动时的传参的内存地址。也就是说,uboot 给 linux 内核传参的时候是这么传的:uboot 事先将准备好的传参(字符串,就是 bootargs)放在内存的一个地址处(就是 bi_boot_params ),然后 uboot 就启动了内核(uboot 在启动内核时,真正是通过寄存器 r0 r1 r2 来直接传递参数的,其中有一个寄存器中就是 bi_boot_params)。内核启动后从寄存器中读取bi_boot_params 就知道了 uboot 给我传递的参数到底在内存的哪里。然后自己去内存的那个地方去找 bootargs。
(2) 经过计算得知:X210 中 bi_boot_params 的值为 0x3000_0100,这个内存地址就被分配用来做内核传参了。所以在 uboot 的其他地方使用内存时要注意,千万不敢把这里给淹没了。
六、背景:关于 DDR 的配置
(1) 注意:这里的初始化 DDR 和汇编阶段 lowlevel_init 中初始化 DDR 是不同的。当时 lowlevel_init 是硬件的初始化,目的是让 DDR 可以开始工作。现在是软件结构中一些 DDR 相关的属性配置、地址设置的初始化,是纯软件层面的。
(2) 软件层次初始化 DDR 的原因:对于 uboot 来说,他怎么知道开发板上到底有几片 DDR 内存,每一片的起始地址、长度这些信息呢?
在 uboot 的设计中,采用了一种简单直接有效的方式:程序员在移植 uboot 到一个开发板时,程序员自己在 x210_sd.h 中使用宏定义去配置出来板子上 DDR 内存的信息,然后 uboot 只要读取这些信息即可。(实际上还有另外一条思路:就是 uboot 通过代码读取硬件信息来知道 DDR 配置,但是 uboot 没有这样。实际上 PC 的 BIOS 采用的是这种)
(3) x210_sd.h 的 496 行到 501 行中使用了标准的宏定义来配置 DDR 相关的参数。主要配置了这么几个信息:有几片 DDR 内存、每一片 DDR 的起始地址、长度。这里的配置信息我们在 uboot 代码中使用到内存时就可以从这里提取使用(想象 uboot 中使用到内存的地方都不是直接用地址数字的,都是用宏定义的)

七、start_armboot 解析4
1、interrupt_init

(1) 看名字,函数是和中断初始化有关的,但是实际上不是,实际上这个函数是用来初始化定时器的(实际使用的是Timer4)。
(2) 裸机中讲过:210 共有 5 个 PWM 定时器。其中 Timer0 - Timer3 都有一个对应的 PWM 信号输出的引脚。而 Timer4 没有引脚,无法输出 PWM 波形。Timer4 在设计的时候就不是用来输出 PWM 波形的(没有引脚,没有 TCMPB 寄存器),这个定时器被设计用来做计时。
(3) Timer4 用来做计时时,要使用到 2 个寄存器:TCNTB4、TCNTO4。TCNTB 中存了一个数,这个数就是定时次数(每一次时间是由时钟决定的,其实就是由 2 级时钟分频器决定的)。我们定时时,只需要把定时时间 / 基准时间 = 数,将这个数放入 TCNTB 中即可;我们通过 TCNTO 寄存器即可读取时间有没有减到 0,读取到 0 后就知道定的时间已经到了。
(4) 使用 Timer4 来定时,因为没有中断支持,所以 CPU 不能做其他事情同时定时,CPU 只能使用轮询方式来不断查看 TCNTO 寄存器才能知道定时时间到了没。因为 Timer4 的定时是不能实现微观上的并行。uboot 中定时就是通过 Timer4 来实现定时的。所以 uboot 中定时时,不能做其他事(考虑下,典型的就是 bootdelay,bootdelay 中实现定时并且检查用户输入是用轮询方式实现的,原理参考裸机中按键章节中的轮询方式处理按键)
(5) interrupt_init 函数将 timer4 设置为定时 10ms。关键部位就是 get_PCLK 函数获取系统设置的 PCLK_PSYS 时钟频率,然后设置 TCFG0 和 TCFG1 进行分频,然后计算出设置为 10ms 时需要向 TCNTB 中写入的值,将其写入 TCNTB,然后设置为 auto reload 模式,然后开定时器开始计时就没了。
总结:在学习这个函数时,注意标准代码和之前裸机代码中的区别,重点学会:通过定义结构体的方式来访问寄存器,通过函数来自动计算设置值以设置定时器。
2、env_init
(1) env_init,看名字就知道是和环境变量有关的初始化。
(2) 为什么有很多 env_init 函数,主要原因是 uboot 支持各种不同的启动介质(譬如 norflash、nandflash、inand、sd卡·····),我们一般从哪里启动就会把环境变量 env 放到哪里。而各种介质存取操作 env 的方法都是不一样的。因此 uboot 支持了各种不同介质中 env 的操作方法。所以有好多个 env_xx 开头的 c 文件。
实际使用的是哪一个要根据自己开发板使用的存储介质来定(这些 env_xx.c 同时只有1个会起作用,其他是不能进去的,通过 x210_sd.h 中配置的宏来决定谁被包含的),对于 x210 来说,我们应该看 env_movi.c 中的函数。
(3) 经过基本分析,这个函数只是对内存里维护的那一份 uboot 的 env 做了基本的初始化,或者说是判定(判定里面有没有能用的环境变量)。当前因为我们还没进行环境变量从 SD 卡到 DDR 中的 relocate,因此当前环境变量是不能用的。
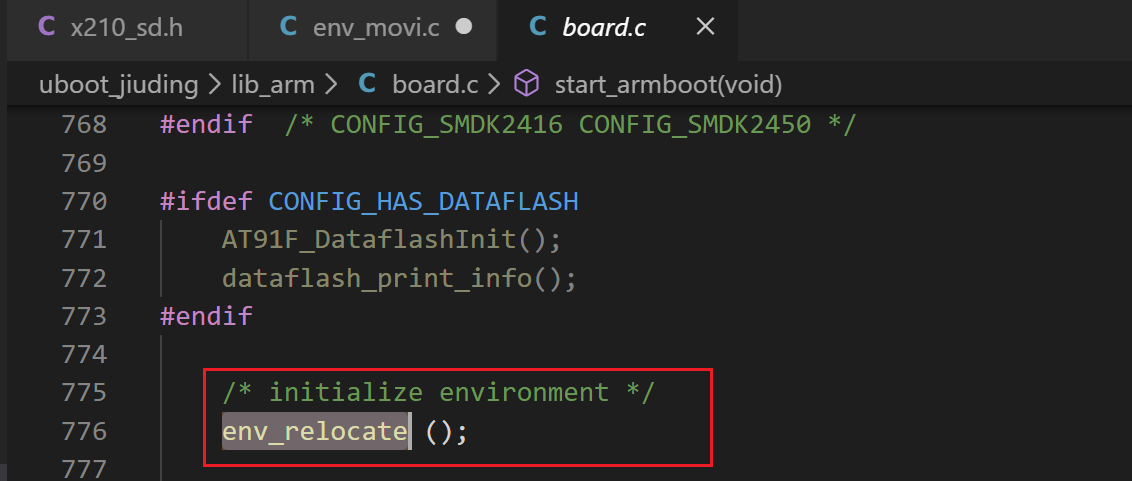
(4) 在 start_armboot 函数中(776行)调用 env_relocate 才进行环境变量从 SD 卡中到 DDR 中的重定位。重定位之后需要环境变量时,才可以从 DDR 中去取,重定位之前如果要使用环境变量只能从 SD 卡中去读取。
八、start_armboot 解析5
1、init_baudrate
(1) init_baudrate 看名字就是初始化串口通信的波特率的。

(2) getenv_r 函数用来读取环境变量的值。用 getenv 函数读取环境变量中 “baudrate” 的值(注意读取到的不是 int 型,而是字符串类型),然后用 simple_strtoul 函数将字符串转成数字格式的波特率。
(3) baudrate 初始化时的规则是:先去环境变量中读取 “baudrate” 这个环境变量的值。如果读取成功,则使用这个值作为环境变量,记录在 gd->baudrate 和 gd->bd->bi_baudrate 中;如果读取不成功,则使用 x210_sd.h 中的 CONFIG_BAUDRATE 的值作为波特率。从这可以看出:环境变量的优先级是很高的。
2、serial_init

(1) serial_init 看名字是初始化串口的。(疑问:start.S 中调用的 lowlevel_init.S 中已经使用汇编初始化过串口了,这里怎么又初始化?这两个初始化是重复的还是各自有不同?)
(2) 搜索发现, uboot 中有很多个 serial_init 函数,我们使用的是 uboot/cpu/s5pc11x/serial.c 中的 serial_init 函数。
(3) 进来后发现,serial_init 函数其实什么都没做。因为在汇编阶段串口已经被初始化过了,因此这里就不再进行硬件寄存器的初始化了。
源自朱有鹏老师.