学习的动力不止于此:
1. 乱码
#include <QApplication>
#include <QLabel>
#include <QFont>
int main(int argc, char *argv[])
{
QApplication a(argc, argv);
QLabel lb;
lb.setFont(QFont("Sans Serif", 24));
lb.setText(" 乱码其实是一件很容易的事情。 ");
lb.show();
return a.exec();
}
兴冲冲地输入一段比如 “XXX 是大神” 的句子,结果却发现,显示的是乱码。
由于字符编码设置不当,导致应用程序无法正常显示文字,称之为乱码。
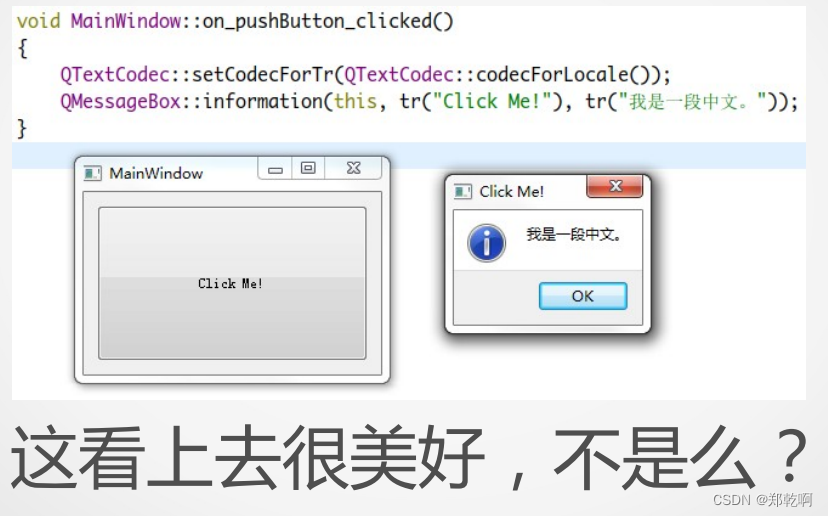
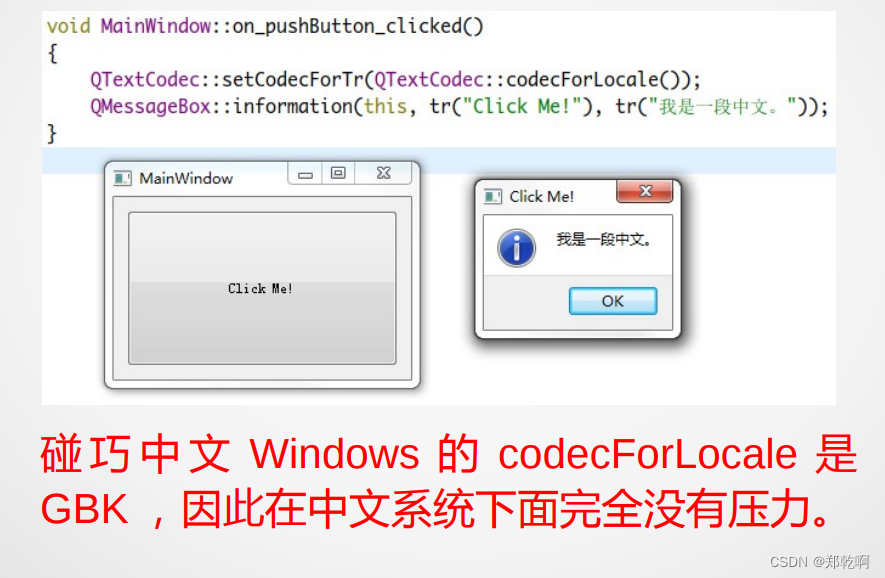
QTextCodec::setCodecForTr(QTextCodec::codecForLocale());
QTextCodec::setCodecForLocale(QTextCodec::codecForLocale());
QTextCodec::setCodecForCStrings(QTextCodec::codecForLocale());
以之问老师,老师给你三行代码
事实上,这三行代码,是相当错误的打开方式!
看win7下的例子:
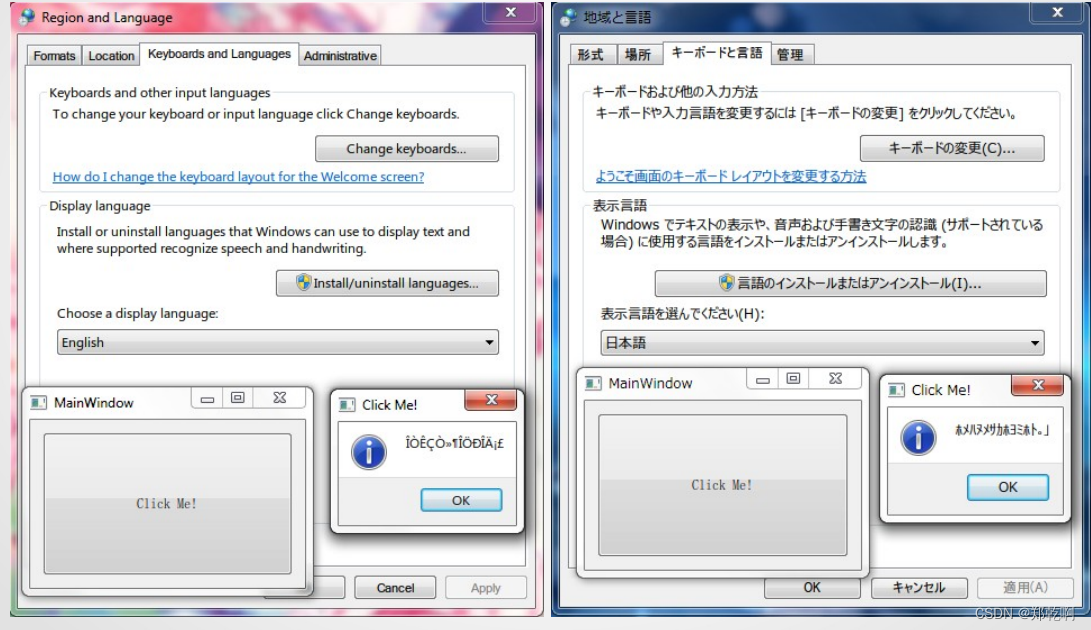
当我们使用非中文windows时:
一、究竟是为什么?
● 其实不仅仅是我们的程序,在其他很多地方都有乱码。
● 打开一个网页,结果显示出来的是不知所云的外星文字。
● 非英语国家的软件,曾经有过那么一段水火不容的历史。
● 玩过日文游戏的人,可能都接触过 AppLocale 这个神器。
● 还有清华计算机系BBS楼 9# 论坛分为 GBK 和 BIG5 两种编码环境。
二、是一个很复杂的历史问题
● 计算机只能存储二进制位。 8 个二进制位是 1 个字节。 1个字节可以表示 0 ~ 255 之间的任何一个数字。
● 文件,无论是「文本文件」还是「音乐文件」,或者是所谓的「二进制文件」,本质上都只是一连串 0 ~ 255 的数字。这个序列被称为字节流。
● 因此,我们眼中的「字符串」,在计算机看来,也不过是一个字节流而已。
● 表示「字符串」的过程,就是将字符映射为字节的过程。
三、发明了 ASCII 字符编码
英文字母很少,一个字节就能全部囊括,因此美国人只
发明了字节和英文字符之间的一一映射关系。
这就是 ASCII 。
后人们发现一个字节不够用,既然一个不够,我们就来俩。
● 在美国人的 ASCII 编码系统中, 128 ~ 255 之间的数字几乎没有使用。而凡是小于等于 127 的数字,二进制表示中首位都是 0 ;大于等于 128 的数字,首位都是 1 。
● 这个特性很快被得到了运用。一般的想法是,在字节流中,如果出现大于等于 0x80 的字符,则被认为(可能)是多字节编码的「前导字节」,需要同下一个字节一起构成完整的「字符」。
● 凭借这个方法,各个国家先后制定了自己的「多字节编码规则」。比如简体中文第一个国家编码,就是 GB2312 。
● 每个国家的文字编码「各自为政」,这导致不同国家
之间交换信息变得非常困难。传输文档之前要实现约
定双方使用的编码方式;当然这不是唯一的问题。
● 更大的问题在于,你甚至不可能在一篇文档里,同
时插入德语字母和中文汉字!于是你在打印一篇语
言混用的文章的时候,很可能需要将文章分批打印,
然后把他们全部粘起来?!
四、于是 Unicode 诞生了
● 事实上刚开始的时候, Unicode 编码曾经只有 65536 个字符空间。这个空间被称为「基本多文种平面」。用恒定的两个字节表示所有字符,这种编码方
式被称为 UCS-2 。
● 当 Unicode 字符超过 65536 之后,参考「多字节编码」,通过双字节扩展四字节的方式表示所有字符。这种编码方式被称为 UTF-16 。
● 为了便于网络传输和数据处理,不至于因为遇到“ \0” 而错误地以为文本结束,以及兼容 ASCII 码, UTF-8 被定义。 UTF-8 的每一个字符按规则编码为 1 ~ 4 任一字节组合。中文通常为 3 字节长。
● 当然,也有直接使用 4 字节编码所有字符的编码方式,被称为 UTF-32 或者UCS-4
五、 Windows 的历史遗留问题
● 在 Unicode 尚未成熟的年代, Windows 是使用各个国家的多字节编码,来支持每个国家的语言的。
● 自 WinNT 发布之后, Windows 内核的 API 全部改成使用UTF-16 的编码方式,以更好地支持多语言。但是由于历史原因, Windows 仍然保留多字节编码的 API 。 UTF-16 的 API以 W 结尾,而多字节编码以 A 结尾。
● 例如 CreateWindowA 和 CreateWindowW 。
● 但是直到现在为止,很多 Windows 程序员仍然没有 Unicode字符编码的相关知识,因此写出来的程序,就很容易乱码……
六、 C++ 的字符串常量
● 编译器处理字符串常量,只是把引号里面的字节数组全部复制,待程序运行的时候变成内存中的字节数组而已。
● 因此以下几行等价(以 UTF-8 编码保存 C++ 源文件):
const char s1[] = " 最喜欢 C++ 了! ";
const char s2[] = "\xe6\x9c\x80\xe5\x96\x9c\xe6\xac\xa2\x43\x2b"
"\x2b\xe4\xba\x86\xef\xbc\x81";
const char s3[] = { 0xe6, 0x9c, 0x80, 0xe5, 0x96, 0x9c, 0xe6, 0xac,
0xa2, 0x43, 0x2b, 0x2b, 0xe4, 0xba, 0x86, 0xef,
0xbc, 0x81, 0x00 };
QString 使用的是 UTF-16
● std::string 本质上是字节数组,因此从 const char* 转换为std::string 不会有太大问题。以前大家写程序的时候不注意这方面 的 东 西 , 保 存 的 文 件 自 然 也 都 是 GBK 的 , 在 中 文 版Windows 下面也看不出什么问题。
● 但是 Qt 不同。 Qt 从诞生开始就是国际化的项目,因此特别注重这些东西。在兼顾了计算性能和存储性能之后, Qt 小组决定将 UTF-16 作为 QString 的编码格式。
● 所以诸位源代码中出现的中文字符串常量,在被 Qt 使用之前,都经历了一次由「多字节编码」转换为 UTF-16 的过程。
源文件中的「多字节编码」是什么?
● 如果不特别说明, Qt 4.x 会认为源文件的编码是 Latin-1 (西欧语言多字节编码)。当然, Qt 5.x 已经修正这个坏习惯,默认源文件是 UTF-8
来着。不过谁叫我们现在还在用 4.8 呢?
● 就像 std::string 做的一样, QString 可以在必要的时候由 const char* 隐
式 或 显 式 转 换 而 成 。 这 个 过 程 中 使 用 的 编 码 , 就 是QTextCodec::codecForCStrings 。
● Qt 有一个函数, QObject::tr ,也可以将 const char 转换为 QString* 。这个过程中使用的编码方式由 QTextCodec::codecForTr 指定。
● 另外 QTextCodec::codecForLocale 表明当前系统所用编码。一般中文Windows 应该是 GBK 。中文 Linux 则一般为 UTF-8 。
Qt Creator 保存源文件的编码是
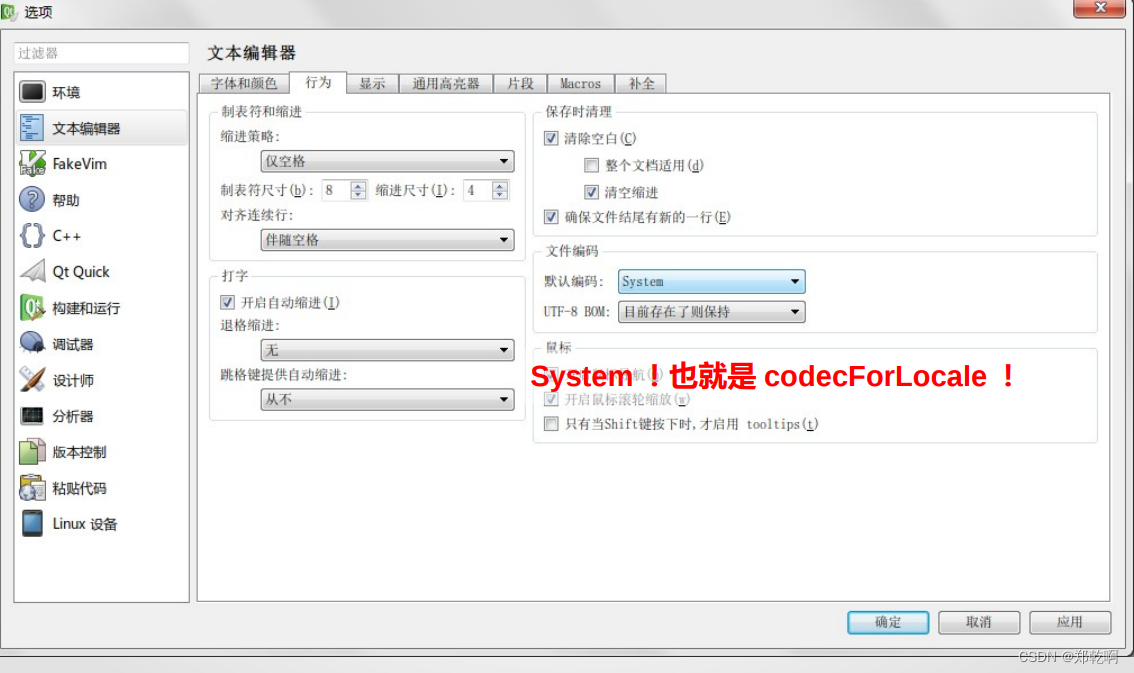
GBK 的源文件自然需要 GBK 解码
在非中文系统下就成了个悲剧
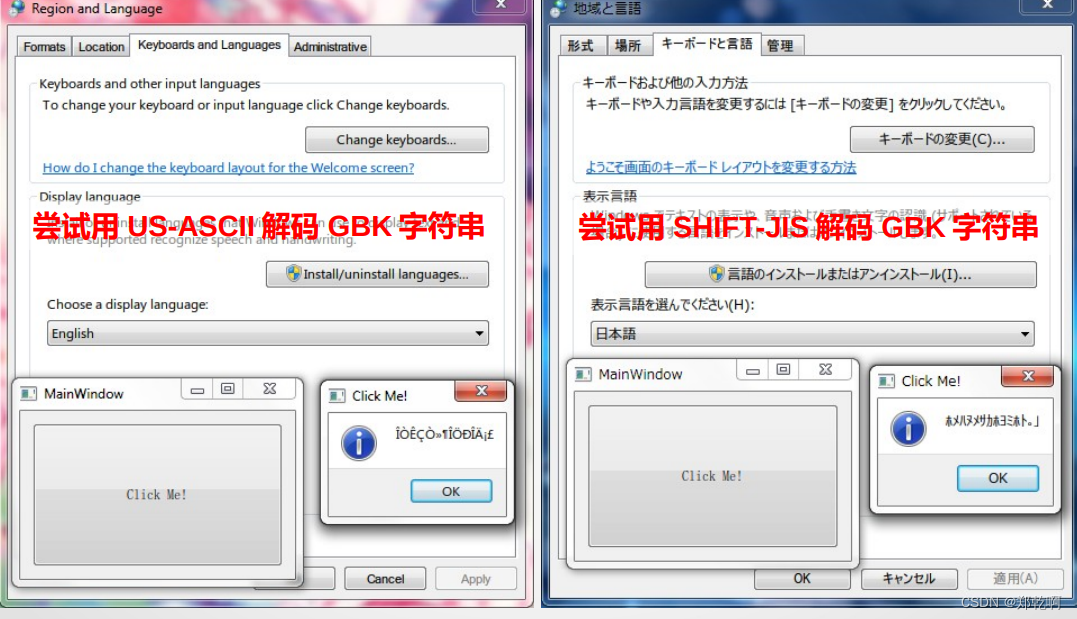
这个时代用 GBK 写程序就应该沙拉!!!
七、正确的打开方式
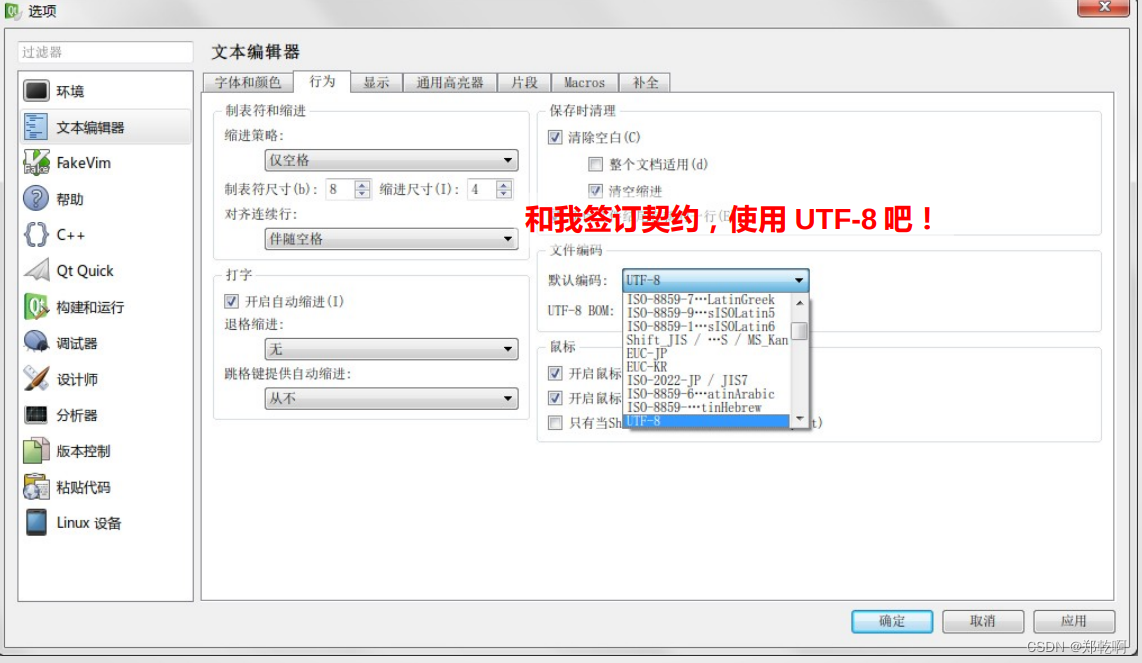
然后改变那三行代码……不,两行代码
QTextCodec::setCodecForTr(QTextCodec::codecForName("utf-8"));
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("utf-8"));
将 QObject::tr 和 const char* 的编码都改成 UTF-8 ,并且使用 UTF-8 保存文件。这样就可以保证在任何语言的操作系统上面都可以显示正确的中文。
但是要特别注意的是,修改 codecForLocale 要慎重!在 Qt 里面, codecForLocale 的作用主要有两个,一个是与外部文件读写的时候使用的默认编码,一个是向命令行输出信息( qDebug )使用的编码。
于是我们的程序终于不乱码了。
八、Qt 的整个框架都使用 UTF-16 编码
● 合理遵循 Qt 的规则,基本不会出现字符乱码的问题。
● 除了 const char* 的隐式转换和 QObject::tr 的转换之外,Qt 事实上有更一般的字符编码转换方式。
// 我们的源文件是 UTF-8 格式的,因此建立一个 QString 。
QString s = QString::fromUtf8(" 这是 UTF-8 的字符串 ");
// 将 QString 转换为 GBK 格式的 QByteArray 字符数组。
// QByteArray::data() 可以拿到 const char* 。
QByteArray gbk_s = QTextCodec::codecForName("gbk")->fromUnicode(s);
// 然后再从 GBK 字符数组转换回 QString 。
QString s2 = QTextCodec::codecForName("gbk")->toUnicode(gbk_s);
九、 有关文件 IO 的编码处理
● 事实上 Qt 读取文件可以用任何一种编码,只是默认以codecForLocale 而已。
● 使用 QTextStream 可以通过文本方式读取 QFile ,而QTextStream 则可以设定使用的编码方式。
● 就算文件名有中文也不怕。只要正确转换为 QString ,剩下的就交给 Qt 吧!
QFile file(QString::fromUtf8(" 中文名 .txt"));
if (file.open(QIODevice::ReadOnly)) {
QTextStream fin(&file);
fin.setCodec(QTextCodec::codecForName("utf-8"));
fin.readLine();
}
反而是 QObject::tr 不应滥用
● 可能有不少人随手写过这样的代码吧:
tr(" 新建文本文档 .txt")
● 能用 tr 轻易解决中文乱码,这似乎很方便。但是 tr 绝不应该用在这种地方!使用 tr 标记的文本,可以被 Qt 配套的工具扫描出来,然后交给「精通各国外语的牛人」进行翻译。
● 翻译完成之后, QObject::tr 函数就会在已经加载的翻译文件中,查找这个字符串的翻译。如果找到,就会用翻译好的字符串替换原来的字符串。
● 那么,文件名算什么「需要翻译的字符串」啊亲?
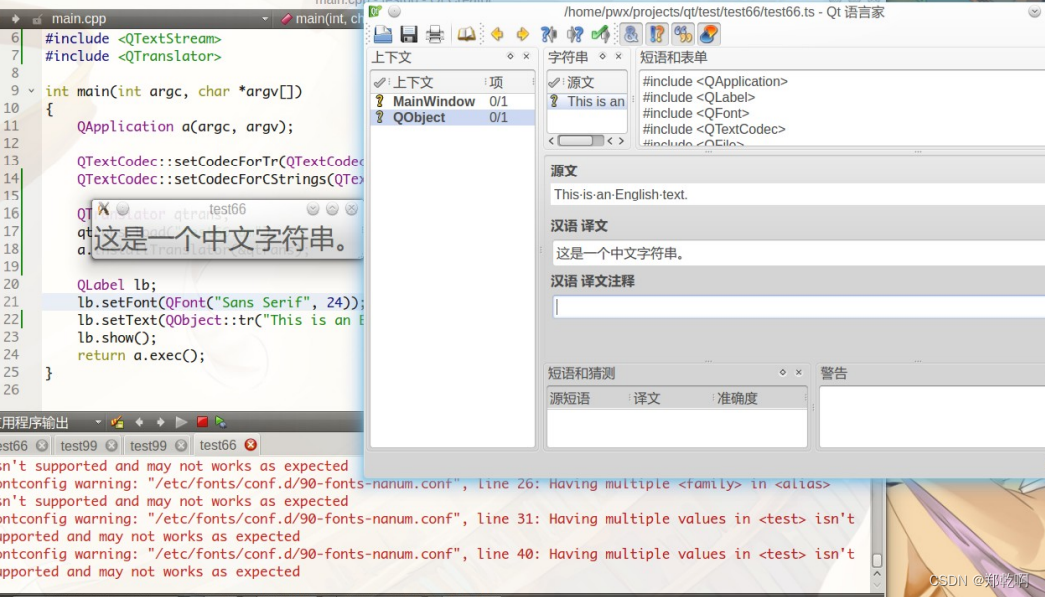
QObject::tr 的真正作用
十、还有很多话题
● 比如在没有 Qt 的情况下,怎么在 C++ 程序里正确处理 UTF-8 。( Windows 环 境 下 面 使 用 MultiByteToWideChar 和WideCharToMultiByte 这 两 个 API 。 Linux 嘛 , 这 年 头 不 用zh_CN.UTF-8 简直没脸见人了……)
● 比如 C++11 的 UTF-8 支持,还有 Qt 5.x 的一些改变。
● 比如在 Python 里面怎么正确处理 UTF-8 , GBK 和 UTF-16 。(其实 Python 2.x 编码处理更麻烦,因为 2.x 对于 str 和 unicode两个类型会动不动自动转换,而且默认编码还改不了。有些函数对于 str 和 unicode 有不同返回值,行为又诡异,会让你想哭!)
● 比如 HTML 文件的编码, URL 的编码之类的。