文章目录
- 前言
- 一、Learning to Navigate in Cities Without a Map
- 二、Unsupervised Predictive Memory in a Goal-Directed Agent
- 三、Zero-Shot Imitation Learning
- Imitation Learning:
前言
研究生不读论文还是不行的呀,在这里结合下别人的总结等下一次组会吹水。
一、Learning to Navigate in Cities Without a Map
先上网络架构:

输入是目标位置g和当前的视觉状态x,然后输出具体的动作和相应的价值。作者专门为目标位置g构造了一个rnn的模块,来让神经网络来感知位置信息,同时这样实现了模块化,从而可以直接实现多个城市的训练和迁移。
与此同时,文章对目标位置g做了一点特殊的改造,比如使用周围的地标距离来描述。整个网络使用IMPALA的一个分布式RL算法来进行训练,并且使用了curriculumn learning 来循序渐进地训练整个网络,让网络能够记忆各种未知导航的方式。同时,文章中说了模型使用了512个actor来分布式训练。
总的来说,这个文章的模型的创新点不多,但是效果却出奇的好。
二、Unsupervised Predictive Memory in a Goal-Directed Agent

该文章主要实现的是one shot navigation. 也就是走一遍就可记住路线,下次不用再进行探索。因为是one shot,意味着需要很好的记忆。所以该模型的关键在于构造了一个非常复杂的记忆模块来更好地提取记忆信息。
这里的MERLIN其实是Meta Reinforcement Learning的模型,他将之前的reward信息也一并输入进去,这是meta的一个关键点所在。
所以,该模型能够做到one shot navigation的基础是这个模型具备meta属性,其次是复杂的memory模块大幅度提升了记忆之前信息的能力。有了这些做铺垫,才可以通过一次探索构建出整个地图模型,从而能够提取信息到下一步的policy网络进行处理。
三、Zero-Shot Imitation Learning
在这里首先介绍一下imitation learning(模仿学习).
Imitation Learning:
在传统的强化学习任务中,通常通过计算累积奖赏来学习最优策略(policy),这种方式简单直接,而且在可以获得较多训练数据的情况下有较好的表现。然而在多步决策(sequential decision)中,学习器不能频繁地得到奖励,且这种基于累积奖赏及学习方式存在非常巨大的搜索空间。而模仿学习(Imitation Learning)的方法经过多年的发展,已经能够很好地解决多步决策问题,在机器人、 NLP 等领域也有很多的应用。
模仿学习是指从施教者提供的范例中进行学习,一般提供人类专家的决策数据{t1,t2,…,tm},每一个决策包含状态和动作序列ti = {s1i,a1i,s2i,a2i,…,sni,ani}. 在这里我们可以将所有【状态-动作对】抽取出来构造新的集合D = {(s1,a1),(s2,a2),(s3,a3),…}
之后我们就可以把状态作为特征,动作作为标记来进行分类(对于离散动作)或者回归(对于连续动作)的学习从而得到最优的策略模型。模型的训练目标是使的模型生成的状态-动作轨迹分布和输入的轨迹分布匹配。从某种角度来看,很像自动编码器,也和GANs很类似。

在简单的自动驾驶任务中,状态就是汽车摄像头观测到的画面Ot(很多强化学习任务中Ot和St也就是状态其实是可以互换的),动作有转向角度,汽车速度,汽车的相关操作等等。根据人类提供的状态动作对来习得驾驶策略。这个任务也叫做行为克隆,即监督学习范式下的模仿学习。
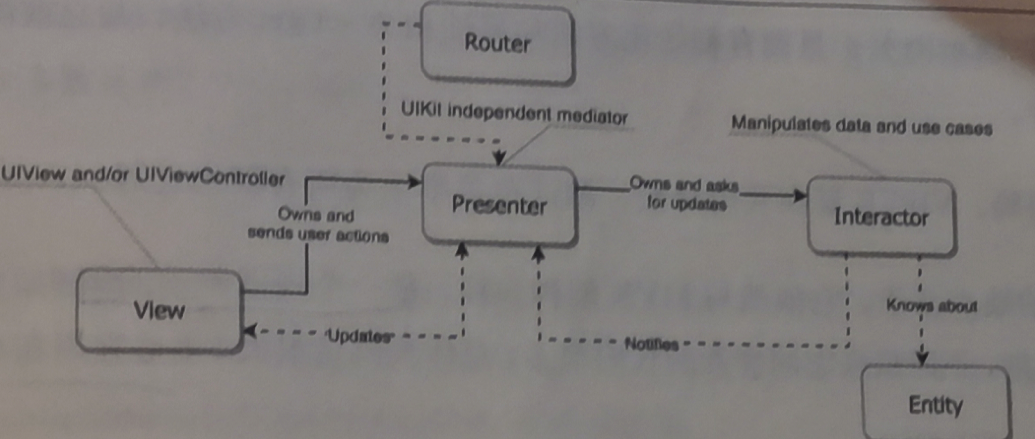
好了,扯了那么多,回来介绍这个论文,模型的网络结构如下图所示:

这个网络模型在训练的时候是没有使用任何的专家动作的,那么怎么训练呢?使用随机探索的trajectory (s1,a1,s2,a2,s3,a3…) 有这样的轨迹,我们可以把任何一点的状态s作为目标位置。它还加一个对未来state St+1的预测模块,进一步强化了其学习效果。