目录
- SQL
- 数据库分页
- 聚合函数
- 表跟表之间的关联关系
- SQL中怎么将行转成列
- SQL注入
- 将一张表的部分数据更新到另一张表
- WHERE和HAVING的区别
- 索引
- 索引分类
- 如何创建及保存MySQL的索引?
- 怎么判断要不要加索引?索引设计原理
- 只要创建了索引,就一定会走索引吗?
- 如何判断数据库的索引有没有生效?
- 索引是越多越好吗?
- 避免索引失效的办法
- 所有的字段都适合创建索引吗?
- 索引的实现原理
SQL
数据库分页
-- 在所有的查询结果中,返回前5行记录。
SELECT prod_name FROM products LIMIT 5;
-- 在所有的查询结果中,从第6行开始,返回5行记录。
SELECT prod_name FROM products LIMIT 5,5;
在偏移量非常大的时候,例如 LIMIT 10000,20这样的查询,这时MySQL需要查询10020条记录然后只返回最后20条,前面的10000条记录都将被抛弃,这样的代价是非常高的。优化此类分页查询可以使用索引覆盖扫描,而不是查询所有的列,然后根据需要做一次关联操作再返回所需的列。针对:SELECT film_id,description FROM sakila.film ORDER BY title LIMIT 10000,20;,如果表非常大,可改写为:
SELECT film.film_id,film.description
FROM sakila.film
INNER JOIN (
SELECT film_id FROM sakila.film ORDER BY title LIMIT 10000,20
) AS lim USING(film_id);
有时候也可以将LIMIT查询转换为已知位置的查询,让MySQL通过范围扫描获得对应的结果。例如,如果在一个位置列上有索引,并且预先计算出了边界值,上面的查询就可以改写为:SELECT film_id,description FROM skila.film WHERE position BETWEEN 10001 AND 20 ORDER BY position;
LIMIT和OFFSET的问题,其实是OFFSET的问题,它会导致MySQL扫描大量不需要的行然后再抛弃掉。如果可以使用书签记录上次取数的位置,那么下次就可以直接从该书签记录的位置开始扫描,这样就可以避免使用OFFSET。例如,若需要按照租赁记录做翻页,那么可以根据最新一条租赁记录向后追溯,这种做法可行是因为租赁记录的主键是单调增长的。首先使用下面的查询获得第一组结果:SELECT * FROM sakila.rental ORDER BY rental_id DESC LIMIT 20;,假设上面的查询返回的是主键16049到16030的租赁记录,那么下一页查询就可以从16030这个点开始:SELECT * FROM sakila.rental WHERE rental_id < 16030 ORDER BY rental_id DESC LIMIT 20;
聚合函数
COUNT()函数:统计数据表中包含的记录行的总数,或者根据查询结果返回列中包含的数据行数,它有两种用法:
- COUNT(*)计算表中总的行数,不管某列是否有数值或者为空值。
- COUNT(字段名)计算指定列下总的行数,计算时将忽略空值的行。
- COUNT()函数可以与GROUP BY一起使用来计算每个分组的总和。
AVG()函数():
AVG()函数通过计算返回的行数和每一行数据的和,求得指定列数据的平均值。
AVG()函数可以与GROUP BY一起使用,来计算每个分组的平均值。
SUM()函数:
SUM()是一个求总和的函数,返回指定列值的总和。
SUM()可以与GROUP BY一起使用,来计算每个分组的总和。
MAX()函数:
MAX()返回指定列中的最大值。
MAX()也可以和GROUP BY关键字一起使用,求每个分组中的最大值。
MAX()函数不仅适用于查找数值类型,也可应用于字符类型。
MIN()函数:
MIN()返回查询列中的最小值。
MIN()也可以和GROUP BY关键字一起使用,求出每个分组中的最小值。
MIN()函数与MAX()函数类似,不仅适用于查找数值类型,也可应用于字符类型。
表跟表之间的关联关系
表与表之间常用的关联方式有两种:内连接、外连接
内连接:通过INNER JOIN来实现,返回两张表中满足连接条件的数据
等值连接:通过WHERE子句中的条件,将两张表连接在一起,它的实际效果等同于内连接
外连接:通过OUTER JOIN来实现,它会返回两张表中满足连接条件和不满足连接条件的数据。外连接有两种形式:左外连接(LEFT OUTER JOIN)、右外连接(RIGHT OUTER JOIN)。
左外连接:返回左表中的所有记录和右表中满足连接条件的记录。
右外连接:返回右表中的所有记录和左表中满足连接条件的记录。
以上是从语法上来说明表与表之间关联的实现方式,而从表的关系上来说,比较常见的关联关系有:一对多关联、多对多关联、自关联。
一对多关联:这种关联形式最为常见,一般是两张表具有主从关系,并且以主表的主键关联从表的外键来实现这种关联关系。另外,以从表的角度来看,它们是具有多对一关系的
多对多关联:如果两张表具有多对多的关系,那么它们之间需要有一张中间表来作为衔接,以实现这种关联关系。这个中间表要设计两列,分别存储那两张表的主键。因此,这两张表中的任何一方,都与中间表形成了一对多关系,从而在这个中间表上建立起了多对多关系。
自关联:自关联就是一张表自己与自己相关联,为了避免表名的冲突,需要在关联时通过别名将它们当做两张表来看待。一般在表中数据具有层级(树状)时,可以采用自关联一次性查询出多层级的数据。
SQL中怎么将行转成列
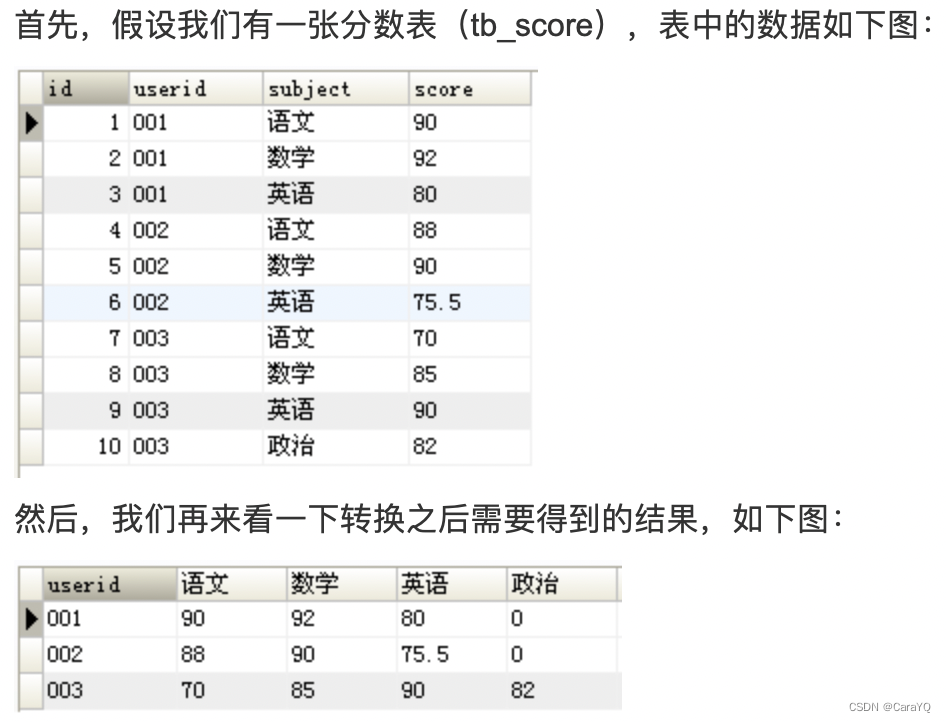
可以看出,这里行转列是将原来的subject字段的多行内容选出来,作为结果集中的不同列,并根据userid进行分组显示对应的score。有两种实现方式:
- 使用 CASE…WHEN…THEN 语句实现:
SELECT userid,
SUM(CASE `subject` WHEN '语文' THEN score ELSE 0 END) as '语文',
SUM(CASE `subject` WHEN '数学' THEN score ELSE 0 END) as '数学',
SUM(CASE `subject` WHEN '英语' THEN score ELSE 0 END) as '英语',
SUM(CASE `subject` WHEN '政治' THEN score ELSE 0 END) as '政治'
FROM tb_score
GROUP BY userid
SUM()是为了能够使用GROUP BY根据userid进行分组,因为每一个userid对应的subject="语文"的记录只有一条,所以SUM()的值就等于对应那一条记录的score的值。假如userid ='001' and subject='语文'的记录有两条,则此时SUM()的值将会是这两条记录的和,同理,使用Max()的值将会是这两条记录里面值最大的一个。但是正常情况下,一个user对应一个subject只有一个分数,因此可以使用SUM()、MAX()、MIN()、AVG()等聚合函数都可以达到行转列的效果。
- 使用IF()函数实现
SELECT userid,
SUM(IF(`subject`='语文',score,0)) as '语文',
SUM(IF(`subject`='数学',score,0)) as '数学',
SUM(IF(`subject`='英语',score,0)) as '英语',
SUM(IF(`subject`='政治',score,0)) as '政治'
FROM tb_score
GROUP BY userid
IF(subject='语文',score,0)作为条件,即对所有subject='语文’的记录的score字段进行SUM()、MAX()、MIN()、AVG()操作,如果score没有值则默认为0。
SQL注入
将一张表的部分数据更新到另一张表
update b set b.col=a.col from a,b where a.id=b.id;
update b set col=a.col from b inner join a on a.id=b.id;
update b set b.col=a.col from b left Join a on b.id = a.id;
WHERE和HAVING的区别
WHERE是在查询结果返回之前约束数据的,WHERE中不能使用聚合函数。
HAVING是在查询返回结果之后对查询结果进行过滤操作,在HAVING中可以使用聚合函数,但不能使用除了分组字段和聚合函数之外的其他字段。
where性能更好,这是因为在需要通过连接从关联表中获取需要的数据,WHERE是先筛选后连接,而HAVING是先连接后筛选。但如果需要使用聚合函数,就要用having
索引
一、索引是一个单独的、存储在磁盘上的数据库结构,包含着对数据表里所有记录的引用指针。使用索引可以快速找出在某个或多个列中有一特定值的行,所有MySQL列类型都可以被索引,对相关列使用索引是提高查询操作速度的最佳途径。
二、索引是在存储引擎中实现的,因此,每种存储引擎的索引都不一定完全相同,并且每种存储引擎也不一定支持所有索引类型。MySQL中索引的存储类型有两种,即BTREE和HASH,具体和表的存储引擎相关。MyISAM和InnoDB存储引擎只支持BTREE索引;MEMORY/HEAP存储引擎可以支持HASH和BTREE索引。
三、索引的优点:
- 类似大学图书馆建书目索引,可以减少磁盘I/O的次数,加快查询速率
- 通过创建唯一索引,可以保证数据库表中每一行数据的唯一性,如果这个数据建了索引,那么会自动给他加上唯一约束 。
- 在实现数据的参考完整性方面,可以加速表和表之间的连接 。换句话说,对于有依赖关系的子表和父表联合查询时,可以提高查询速度
- 在使用分组和排序子句进行数据查询时,可以显著减少查询中分组和排序的时间 ,降低CPU的消耗。因为索引是排好序的能快速查找的数据结构,既然排好序,那进行分组和排序时会更高效
四、缺点:
- 创建索引和维护索引要耗费时间,随着数据量的增加,所耗费的时间也会增加。
- 索引存储在磁盘上,需要占磁盘空间
- 虽然索引大大提高了查询速度,但是当对表中的数据进行增加、删除和修改的时候,索引也要动态地维护,这样就降低了数据的维护速度。因为索引是排好序的能快速查找的数据结构,假如索引现在是1,1,2,2,3,4,4,假如要增加一个索引3,那么4,4,需要移动,删除和修改同理。如何解决这个问题:在维护表时,先删除表中的索引,然后插入数据,插入完成后再建索引
索引分类
MySQL的索引可以分为以下几类:
- 普通索引和唯一索引
普通索引是MySQL中的基本索引类型,允许在定义索引的列中插入重复值和空值。
唯一索引要求索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
主键索引是一种特殊的唯一索引,不允许有空值。
- 单列索引和组合索引
单列索引即一个索引只包含单个列,一个表可以有多个单列索引。
组合索引是指在表的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用。使用组合索引时遵循最左前缀集合。 - 全文索引:全文索引类型为FULLTEXT,在定义索引的列上支持值的全文查找,允许在这些索引列中插入重复值和空值。全文索引可以在CHAR、VARCHAR或者TEXT类型的列上创建。MySQL中只有MyISAM存储引擎支持全文索引。
- 空间索引:空间索引是对空间数据类型的字段建立的索引,MySQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING和POLYGON。MySQL使用SPATIAL关键字进行扩展,使得能够用创建正规索引类似的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MyISAM的表中创建。
如何创建及保存MySQL的索引?
- 创建表时:
CREATE TABLE table_name [col_name data_type] [UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name [length]) [ASC | DESC]
# 1. UNIQUE、FULLTEXT、SPATIAL为可选参数,分别表示唯一索引、全文索引和空间索引;
#2. INDEX与KEY的作用相同,用来指定创建索引,INDEX较常用;
#3. index_name指定索引的名称(给索引起别名),为可选参数,如果不指定,那么MySQL默认col_name为索引名;
#4. col_name为需要创建索引的字段列,该列必须从数据表中定义的多个列中选择;
#5. length为可选参数,表示索引的长度,只有字符串类型的字段才能指定索引长度;
#6. ASC或DESC指定升序或者降序的索引值存储。
# 创建联合索引
CREATE TABLE book4(
book_id INT ,
book_name VARCHAR(100),
AUTHORS VARCHAR(100),
info VARCHAR(100) ,
COMMENT VARCHAR(100),
year_publication YEAR,
#声明索引
INDEX mul_bid_bname_info(book_id,book_name,info)
);
- 在已经存在的表上创建索引
ALTER TABLE table_name ADD [UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name[length],...) [ASC | DESC]
CREATE TABLE book5(
book_id INT ,
book_name VARCHAR(100),
AUTHORS VARCHAR(100),
info VARCHAR(100) ,
COMMENT VARCHAR(100),
year_publication YEAR
);
ALTER TABLE book5 ADD INDEX idx_cmt(COMMENT);
ALTER TABLE book5 ADD UNIQUE uk_idx_bname(book_name);
ALTER TABLE book5 ADD INDEX mul_bid_bname_info(book_id,book_name,info);
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name ON table_name (col_name[length],...) [ASC | DESC]
CREATE TABLE book6(
book_id INT ,
book_name VARCHAR(100),
AUTHORS VARCHAR(100),
info VARCHAR(100) ,
COMMENT VARCHAR(100),
year_publication YEAR
);
CREATE INDEX idx_cmt ON book6(COMMENT);
CREATE UNIQUE INDEX uk_idx_bname ON book6(book_name);
CREATE INDEX mul_bid_bname_info ON book6(book_id,book_name,info);
怎么判断要不要加索引?索引设计原理
- 避免对经常更新的表进行过多的索引,并且索引中的列要尽可能少。应该经常用于查询的字段创建索引,但要避免添加不必要的字段。
- 数据量小的表最好不要使用索引,由于数据较少,查询花费的时间可能比遍历索引的时间还要短,索引可能不会产生优化效果。
- 在条件表达式中经常用到的不同值较多的列上建立索引,在不同值很少的列上不要建立索引。比如在学生表的“性别”字段上只有“男”与“女”两个不同值,因此就无须建立索引
- 当唯一性是某种数据本身的特征时,指定唯一索引。
- 在频繁进行排序或分组(即进行group by或order by操作)的列上建立索引,如果待排序的列有多个,可以在这些列上建立组合索引。
只要创建了索引,就一定会走索引吗?
不一定。比如,在使用组合索引的时候,如果没有遵从“最左前缀”的原则进行搜索,则索引是不起作用的。假设在id、name、age字段上已经成功建立了一个名为MultiIdx的组合索引。索引行中按id、name、age的顺序存放,索引可以搜索id、(id,name)、(id, name, age)字段组合。如果列不构成索引最左面的前缀,那么MySQL不能使用局部索引,如(age)或者(name,age)组合则不能使用该索引查询。
如何判断数据库的索引有没有生效?
使用EXPLAIN语句查看:EXPLAIN SELECT * FROM book WHERE year_publication=1990;
EXPLAIN语句将为我们输出详细的SQL执行信息,如果key的值包含了year_publication字段,则说明在查询时使用了该索引。
索引是越多越好吗?
不是。一个表中如有大量的索引,不仅占用磁盘空间,还会影响INSERT、DELETE、UPDATE等语句的性能,因为在表中的数据更改时,索引也会进行调整和更新。
避免索引失效的办法
- 使用组合索引时,需要遵循“最左前缀”原则;
- 不在索引列上做任何操作,例如计算、函数、类型转换,会导致索引失效而转向全表扫描;
- 尽量使用覆盖索引(之访问索引列的查询),减少 select * 覆盖索引能减少回表次数;
- MySQL在使用不等于(!=或者<>)的时候无法使用索引会导致全表扫描;
- LIKE以通配符开头(%abc)MySQL索引会失效变成全表扫描的操作;
- 字符串不加单引号会导致索引失效(可能发生了索引列的隐式转换);
- 少用or,用它来连接时会索引失效。
所有的字段都适合创建索引吗?
不是。不适合创建索引的情况:
- 频繁更新的字段不适合建立索引;
- where条件中用不到的字段不适合建立索引;
- 数据比较少的表不需要建索引;
- 数据重复且分布比较均匀的的字段不适合建索引,例如性别、真假值;
- 参与列计算的列不适合建索引。