读源码是一件非常复杂、困难、枯燥的过程,这个复杂过程我给大家踩了,各位看官躺平看就行啦
初始化入口:
//典型的工厂模式,初始化一个caffeine对象
Caffeine.newBuilder();
@CheckReturnValue
public static Caffeine<Object, Object> newBuilder() {
return new Caffeine<>(); //这里new 的是一个无参构造,内部一些属性是预先设置的
}
static final int UNSET_INT = -1;
//默认的扩容大小
static final int DEFAULT_INITIAL_CAPACITY = 16;
//默认过期时间,不过期
static final int DEFAULT_EXPIRATION_NANOS = 0;
//默认刷新时间,不刷新
static final int DEFAULT_REFRESH_NANOS = 0;
//这个参数主要用来表示是否使用原生配置,如果是false那么需要传入CaffeineSpec对象
//CaffeineSpec对象作用是支持对配置进行自定义解析然后用来初始化caffeine,多个配置用,分隔,配置的key和value用=号
boolean strictParsing = true;
//最大装载量,默认-1 无限大
long maximumSize = UNSET_INT;
long maximumWeight = UNSET_INT;
int initialCapacity = UNSET_INT;
long expireAfterWriteNanos = UNSET_INT;
long expireAfterAccessNanos = UNSET_INT;
long refreshAfterWriteNanos = UNSET_INT;Cache<Long, Long> TAG_CIRCLE_CONFIG_CACHE = Caffeine.newBuilder()
.maximumSize( 3000 ) //设置容量大小
.expireAfterWrite( 1L, TimeUnit.HOURS ) //过期策略是最后一次写入后的一小时
.softValues() //map的值软引用
.removalListener( (o, o2, removalCause) -> log.info( " is {},val is {},caseMessage is {}", o, o2, removalCause )) //数据失效时的监听回调事件
.build();疑问点:
超过容量大小后是抛出异常还是进行数据淘汰?
如果10点写入了一个key=5的数据,10.30又写入一个key=5的数据,那么过期时间会被刷新嘛?
疑问点源码分析:
先将代码执行流程图画出来,这样再看源码会更加直观点
2个疑问点主要看下put方法的实现即可,下面是put方法的入口
/*
put会进入com.github.benmanes.caffeine.cache.BoundedLocalCache这个类中
这里可以看出来当有key相同时会执行覆盖操作
*/
@Override
public @Nullable V put(K key, V value) {
return put(key, value, expiry(), /* onlyIfAbsent */ false);
}Node类分析:
/*
整个node类是一个抽象类,里面大量的抽象方法,这个类实现了访问顺序和写入顺序接口
下面列举一些核心抽象方法,不全部展示了,实在太多
Node这个抽象类的实现类是非常多的,见下面的截图,主要核心是需要子类实现不同的put、get、以及过期方法,这里用到的就是策略模式
*/
@Nullable
public abstract K getKey();
public abstract Object getKeyReference();
@Nullable
public abstract V getValue();
Node实现类解析:
这个类初看还是比较难读懂的,因为用到了很多底层方法,平时写业务代码的时候不太使用
/*
这个类是其中一种的策略实现
*/
class FD<K, V> extends Node<K, V> implements NodeFactory<K, V> {
//这个变量是一个静态final变量,初始化完成后不会改变,key的偏移量
protected static final long KEY_OFFSET = UnsafeAccess.objectFieldOffset(FD.class, "key");
//这个变量是一个静态final变量,初始化完成后不会改变,value的偏移量
protected static final long VALUE_OFFSET = UnsafeAccess.objectFieldOffset(FD.class, "value");
volatile WeakKeyReference<K> key;
volatile SoftValueReference<V> value;
/*
上面提到的两种偏移量作用是为了通过UNSAFE类来设置对象的字段值和获取对象的字段值,那么为什么要用UNSAFE类来操作呢,我认为主要原因是性能和越权。
性能:
1.这个类是java最底层的类如果使用java包装过的对象来操作可能性能有损失
2.可以更加灵活的控制是否需要内存屏障和指令重排
越权:
这个类反射后对于反射对象的操作是可以越权的,无论字段是不是private,但是必须要知道操作字段的偏移量,这时候上面两个在对象初始化时就固定下来的偏移量就有用了
每次put都是新new Node(),这样可以确保不同Node内部固定的偏移量是不同的
*/
/*
下面是两种类的初始化方式,主要区别在于K的类型到底是普通键还是引用对象
普通键:
key会进行hashcode计算(利用java底层计算方法System.identityHashCode),并且初始化一个弱引用对象,里面有个hashcode属性值等于刚刚计算出来的code值
引用对象键:
利用UNSAFE.putObject 方法将对象添加到内存地址中,偏移量是预先固定计算好的
*/
FD(K key, ReferenceQueue<K> keyReferenceQueue, V value, ReferenceQueue<V> valueReferenceQueue, int weight, long now) {
this(new WeakKeyReference(key, keyReferenceQueue), value, valueReferenceQueue, weight, now);
}
FD(Object keyReference, V value, ReferenceQueue<V> valueReferenceQueue, int weight, long now) {
UnsafeAccess.UNSAFE.putObject(this, KEY_OFFSET, keyReference);
UnsafeAccess.UNSAFE.putObject(this, VALUE_OFFSET, new SoftValueReference(keyReference, value, valueReferenceQueue));
}
/*
下面几个方法都是通过内存偏移量获取对象的key和值
*/
public final K getKey() {
return ((Reference)UnsafeAccess.UNSAFE.getObject(this, KEY_OFFSET)).get();
}
public final Object getKeyReference() {
return UnsafeAccess.UNSAFE.getObject(this, KEY_OFFSET);
}
public final V getValue() {
return ((Reference)UnsafeAccess.UNSAFE.getObject(this, VALUE_OFFSET)).get();
}
public final Object getValueReference() {
return UnsafeAccess.UNSAFE.getObject(this, VALUE_OFFSET);
}
}put方法:
搞明白Node对象后,开始吃正菜,由于put方法很长涉及方法也很多,所以我们一部分一部分来解析
/*
大家看到这2行代码有没有发出新的疑问,上面Node方法中的getKey/getValue 用的是@Nullable注解,为什么在put的时候又判空呢,并且如果是null的话会直接抛出空指针异常,这是为什么呢?
其实个人认为是内存屏障的原因,首先上面说过Node这个抽象类实现的策略非常多,不同策略对于getKey和getValue实现逻辑也不相同,有些实现读取getKey和getValue的时候是工作内存读取、有些实现读取getKey和getValue是主内存读取,就可能出现null的情况,所以读取时可以出现null,但是put的时候不能
*/
requireNonNull(key);
requireNonNull(value);
Node<K, V> node = null;
/*
乍一看这是一个很简单的代码容易忽略,但是其实非常关键的一个变量,用来初始化当前时间的纳秒数,Ticker对象可以理解为一个初始时钟,这个时钟又包含了相当多的实现类,不一定都是采用java系统方式获取纳秒所以有很多实现,这个now变量就是后面过期策略生效时的核心参考指标
*/
long now = expirationTicker().read();
int newWeight = weigher.weigh(key, value);put中难啃的代码逻辑
/*
为什么这里采用无限循环呢,命名是put一次为啥需要无限循环,其实原因是因为下面的代码用到的异步线程,通过无限循环判断异步线程是否都完成再来return出无限循环。
那么我又有新的疑问了:为什么不用java原生的fork-join 方式来判断子线程是否都完成呢,这样代码不是更加优美么?让我们带着这个疑问继续看下去先
*/
for (;;) {
/*
这里的data是java的ConcurrentHashMap<Object, Node<K, V>> data,在类初始化的时候这个map也完成了初始化,data = new ConcurrentHashMap<>(builder.getInitialCapacity());
nodeFactory.newLookupKey(key) 是获取当前key的hashcode值,有3中策略实现,但是源码看了下三种策略实现的逻辑是一样的,都是调用System.identityHashCode获取code值
*/
Node<K, V> prior = data.get(nodeFactory.newLookupKey(key));
if (prior == null) {
if (node == null) {
//走到这步代表当前put的key之前不存在,那么需要初始化一次Node
node = nodeFactory.newNode(key, keyReferenceQueue(),
value, valueReferenceQueue(), newWeight, now);
/*
下面这行代码主要是设置数据淘汰的基准时间,如果初始化的是BoundedLocalCache那么这行代码不生效,因为默认是false,如果是其他Cache实现类,那么这行代码就会初始化一个时间轮TimeWheel,并且计算expireAfterCreate首次写入时间之后多少时间失效,但是这个写入时间不一定是数据put时间,前面已经说过有个参数是Long now代表起始时间是可以自定义的
看下expireAfterCreate的代码:
long expireAfterCreate(@Nullable K key, @Nullable V value, Expiry<K, V> expiry, long now) {
if (expiresVariable() && (key != null) && (value != null)) {
long duration = expiry.expireAfterCreate(key, value, now);
return isAsync ? (now + duration) : (now + Math.min(duration, MAXIMUM_EXPIRY));
}
return 0L;
}
expireAfterCreate 计算逻辑:
1.一共存在了7种实现类,大多数实现类long duration = 当前纳秒数
2.duration并不是最终的时效时间,最终的时效时间需要再次判断isAsync
这段代码可以总结我们之前的疑问了,在put时如果我们没有进行任何特殊参数去控制put的逻辑,默认对同一个key进行再次续期,如果我们设定了每次put的now都是固定原始值,那么这个时候key会覆盖但是过期时间不在刷新
*/
setVariableTime(node, expireAfterCreate(key, value, expiry, now));
}
/*
这行代码开始看的时候会容易看不明白,为什么要put一个key的引用,不直接put一个值呢?其实仔细看上面源码分析说明的话可以看到node.getKeyReference()获取的是key的node对象,那么这行代码的意义在于先看下key的Node对象是否还存在,为什么需要看呢?
原因:
1.key的node对象初始化的时候用的是弱引用
2.val的node对象初始化的时候用的是软引用
所以有可能已经被回收了,那么需要再次确认
*/
prior = data.putIfAbsent(node.getKeyReference(), node);
if (prior == null) {
/*
prior=null的原因:
key第一次put不存在 OR 已经被回收了,new AddTask(node, newWeight)会添加一个runnable,这个runnable主要作用是添加一个异步的while(true)循环来判断如果node存活,那么会不断调整几个双端队列的存储这个node的顺序,这个顺序对不同过期失效策略有不同作用
prior!= null的原因:
这个key之前已经存在过了 AND 生命周期还存在
*/
afterWrite(new AddTask(node, newWeight));
return null;
} else if (onlyIfAbsent) {
/*
如果onlyIfAbsent=true,这个时候会获取之前的值进行访问计数,但是不做热点计数,这个时候会拿之前key的值返回并且退出这个无限循环
*/
V currentValue = prior.getValue();
if ((currentValue != null) && !hasExpired(prior, now)) {
if (!isComputingAsync(prior)) {
tryExpireAfterRead(prior, key, currentValue, expiry(), now);
setAccessTime(prior, now);
}
afterRead(prior, now, /* recordHit */ false);
return currentValue;
}
}
} else if (onlyIfAbsent) {
//这个处理逻辑和上面一样,只是对应的if判断不一样
V currentValue = prior.getValue();
if ((currentValue != null) && !hasExpired(prior, now)) {
if (!isComputingAsync(prior)) {
tryExpireAfterRead(prior, key, currentValue, expiry(), now);
setAccessTime(prior, now);
}
afterRead(prior, now, /* recordHit */ false);
return currentValue;
}
} else {
/*
走到这里代表之前的key已经存在,并且需要进行覆盖操作,onlyIfAbsent=false
这个方法内部主要是删除当前key的线程池数据,也就代表删除当前key异步任务
@Nullable volatile ConcurrentMap<Object, CompletableFuture<?>> refreshes;
void discardRefresh(Object keyReference) {
var pending = refreshes;
if (pending != null) {
pending.remove(keyReference);
}
}
*/
discardRefresh(prior.getKeyReference());
}
//走到这里代表这个key已经存在,并且onlyIfAbsent=false,那么下面代码做的事情就是拿新的值替换老的值,但是由于存在并发影响,所以替换值的过程也是相对复杂的
V oldValue;
long varTime;
int oldWeight;
boolean expired = false;
boolean mayUpdate = true;
boolean exceedsTolerance = false;
//先锁定原始Node对象
synchronized (prior) {
/*
如果node已经不在存活,那么继续下一次循环,node为什么会不存活了呢?
原因是可能失效时间到了,那么继续下一次循环的时候就不会走到这里了,而是在上面就会直接put结束
*/
if (!prior.isAlive()) {
continue;
}
//取出原始值,后面需要进行CAS
oldValue = prior.getValue();
oldWeight = prior.getWeight();
//如果value失效 OR 软引用回收,那么重新计算有效时间
if (oldValue == null) {
varTime = expireAfterCreate(key, value, expiry, now);
//初始化RemovalCause.COLLECTED,初始化新的收集器
notifyEviction(key, null, RemovalCause.COLLECTED);
} else if (hasExpired(prior, now)) {
expired = true;
varTime = expireAfterCreate(key, value, expiry, now);
//将老的value有效期重新设置成无效,避免在CAS期间老的val突然失效node不存在了
notifyEviction(key, oldValue, RemovalCause.EXPIRED);
} else if (onlyIfAbsent) {
mayUpdate = false;
varTime = expireAfterRead(prior, key, value, expiry, now);
} else {
//更新下key的更新有效期时间
varTime = expireAfterUpdate(prior, key, value, expiry, now);
}
}经过上面Put代码的分析,疑问点已经排除:
不做任何特殊初始化的话,同一个key在put的时候有效期也会刷新
超过设置的最大容量时,如果没有可失效key,此时会直接抛出异常
key过期的核心实现:
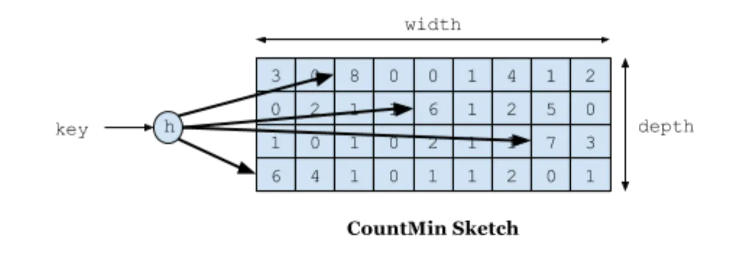
guava的loading cache是使用lru的淘汰策略, 但是很多场景最近的数据不一定热,反而容易把稍旧的热数据挤出去,所以最好还是能统计访问次数得到数据的热度。
基本原理:对一个key会取他的hash值,找到对应位置,然后累加得到访问次数。
问题1:hash会冲突
解决:如果用hashmap的方式,相同的下标变成链表,这种方式会占用很大的内存,而且速度也不是很快。 其实一个hash函数会冲突是比较低的,我多搞4个hash函数,4个都冲突的概率就微乎其微了。取这4个hash函数对应值的最小的那个,基本就是访问次数了。
问题2:用4个hash函数会存访问次数,那空间就是4倍了。怎么优化呢
解决:访问次数超过15次其实是很热的数据了,没必要存太大的数字。所以用4位就可以存到15了。一个long有64位,可以存16个4位。而且hash冲突的概念和数组的大小也正相关,一个long 是64位,除以4个hash,在除以4位,一个long对应的数组大小其实是容量的4倍了。进一步降低了冲突的概率。
public void increment(E e) {
if (isNotInitialized()) {
return;
}
int hash = spread(e.hashCode());
int start = (hash & 3) << 2;
//对同一个key的四个hash都增加次数,然后再取最小的那个做输出值
int index0 = indexOf(hash, 0);
int index1 = indexOf(hash, 1);
int index2 = indexOf(hash, 2);
int index3 = indexOf(hash, 3);
boolean added = incrementAt(index0, start);
added |= incrementAt(index1, start + 1);
added |= incrementAt(index2, start + 2);
added |= incrementAt(index3, start + 3);
if (added && (++size == sampleSize)) {
reset();
}
}这个思路真的很巧妙,既避免为了记录访问次数而进行很大的空间开销,也解决了性能的查询问题