前言
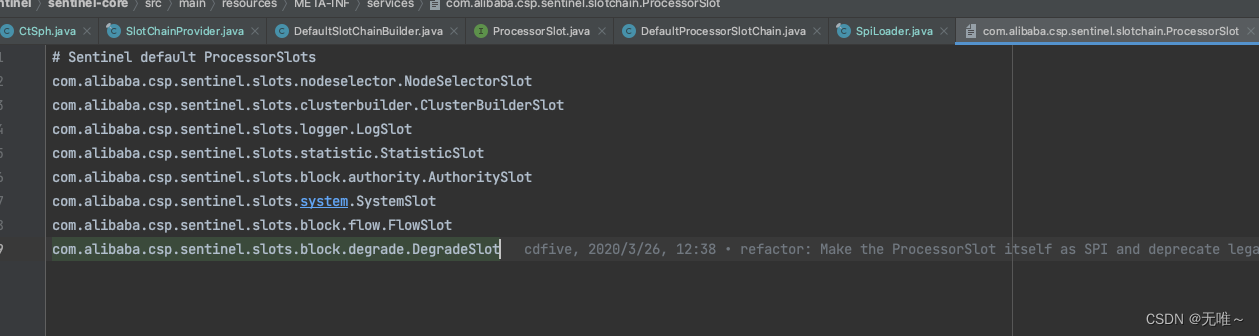
上篇文章中我们已经讲到了构造完处理链,然后会调用对应slot的entry方法,我们根据配置文件中Slot的具体顺序来逐一讲解Slot的具体实现。
一、NodeSelectorSlot
这个
slot主要负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级。
1.1 NodeSelectorSlot#entry
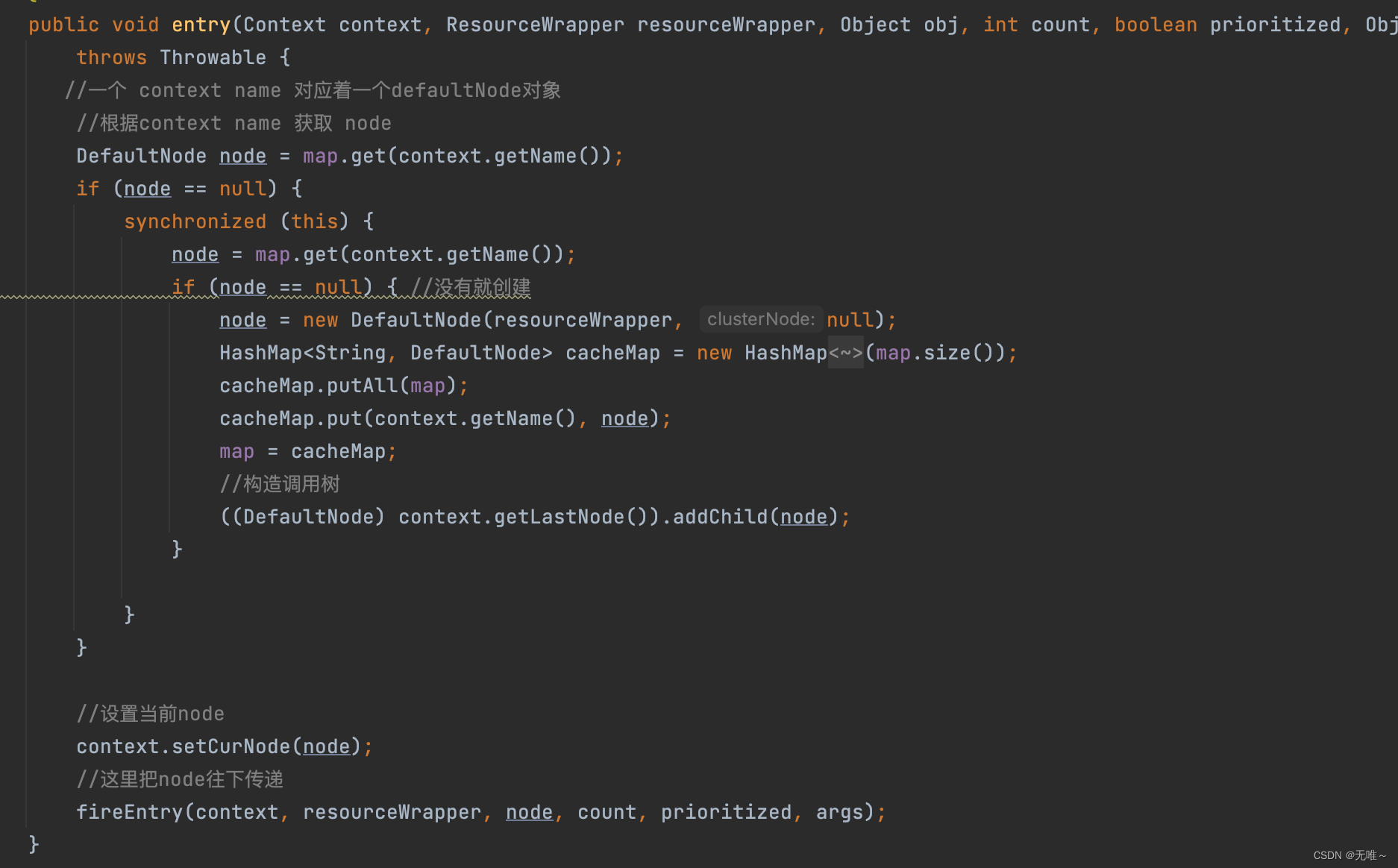
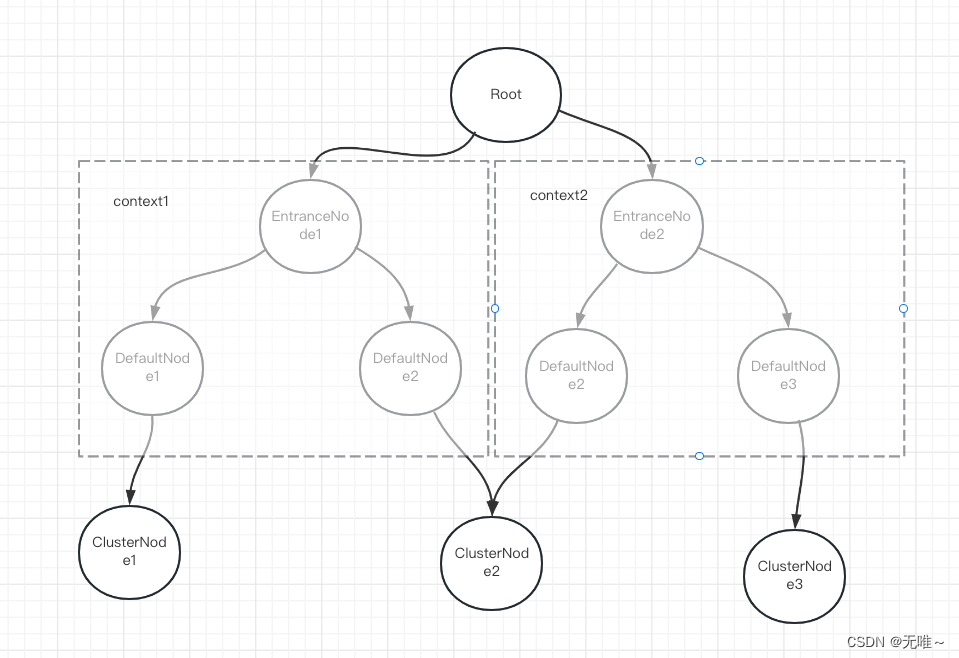
我们看到上面这个
entry方法中会给对应的context name生成一个defaultNode对象并挂载到Entrance Node中
我们看下下面的这个node对应图
Root是根节点,它对应的含义是应用级别
EntranceNode是一个线程节点,是属于context
而我们NodeSelectorSlot中维护的那个map,是对应相同资源不同context的DefaultNode。
1.2 NodeSelectorSlot#exit
这里啥也没做就是传递给下一个slot

二、ClusterBuilderSlot
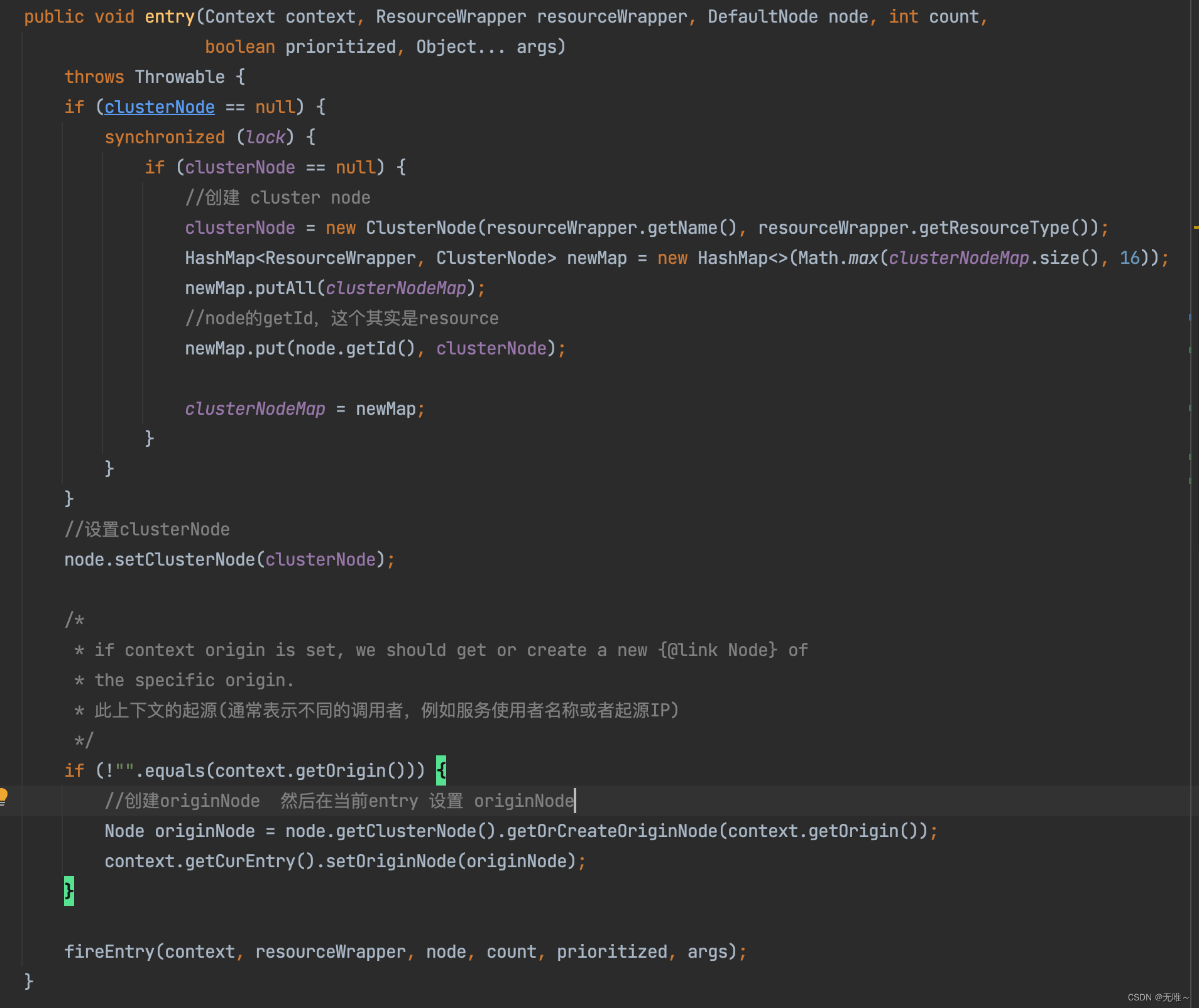
2.1ClusterBuilderSlot#entry
- 这里首先会判断如果这个资源对应的
clusterNode不存在则会创建并放入缓存中,这里我们发现这个ClusterNode其实是和资源相关的,一个资源对应一个Cluster。- 把
ClusterNode设置到DefaultNode中,即不同的DefaultNode都关联了一个ClusterNode,这样我们就可以在不同的上下文中都拿到当前资源一个总的流量统计情况- 从
context中取出origin,这个origin就是上游,sentinel通过一些手段将上层服务资源传递到下层,这里如果originNode不存在也会进行创建
2.2ClusterBuilderSlot#entry
这里啥也没做就是传递给下一个slot

三、LogSlot
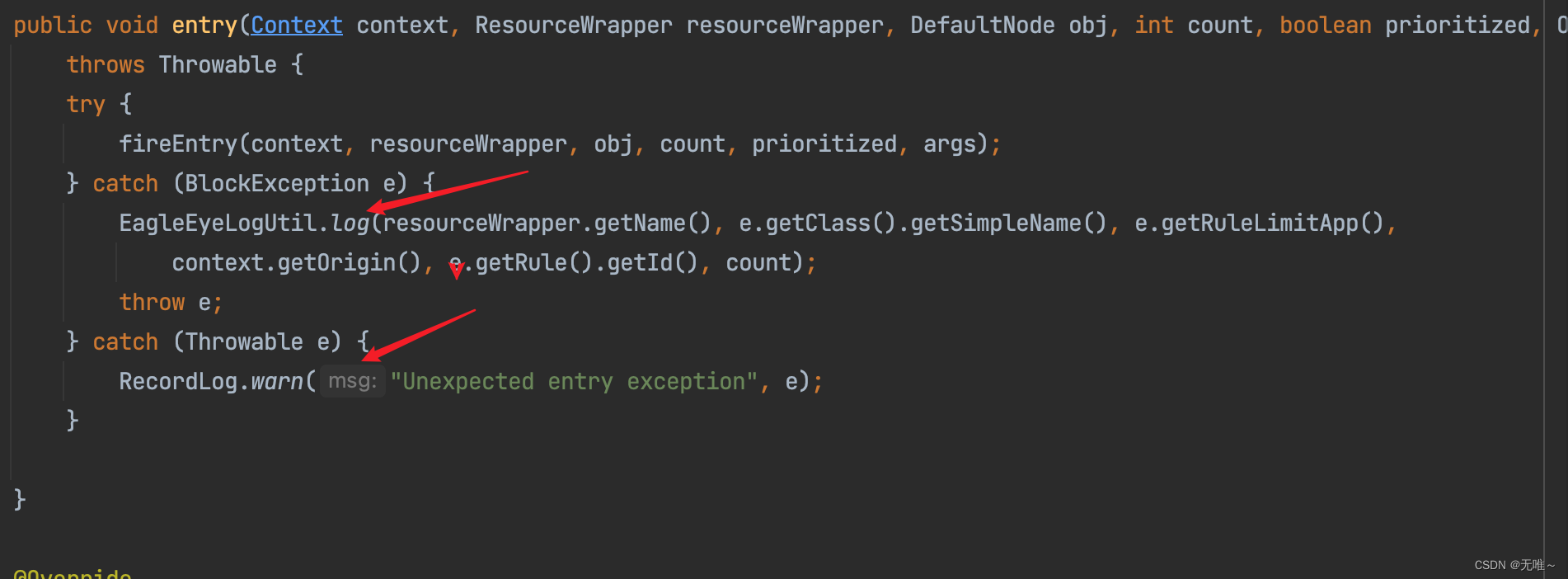
3.1LogSlot#entry
这里发现这个就是打印个日志,如果抛出熔断或限流异常就打印日志并原样抛出,如果抛出其他异常就打印日志并吞掉
3.2LogSlot#exit
抛出异常打印日志并吞掉

四、StatisticSlot
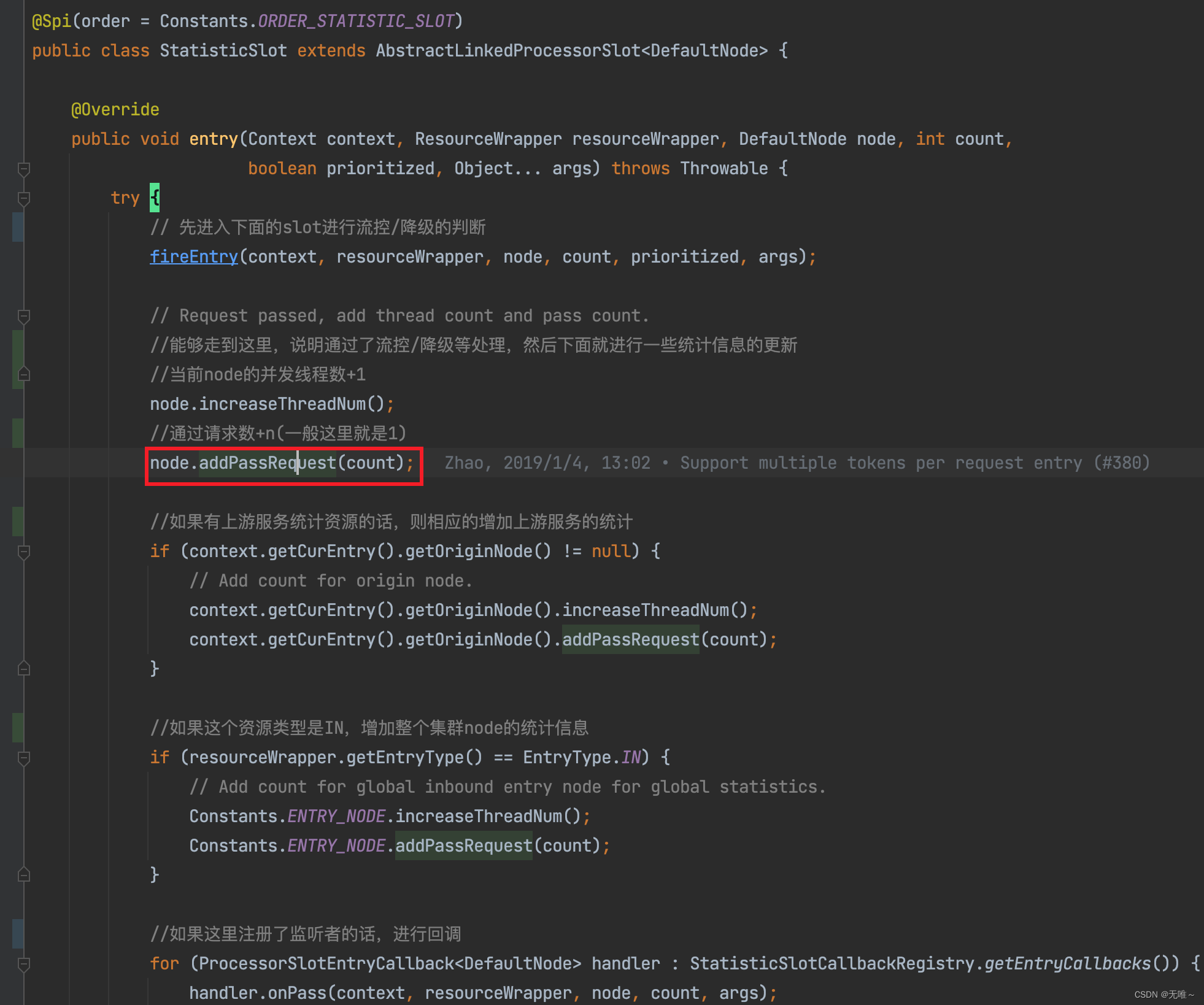
4.1 StatisticSlot#entry
- 先调用
fireEntry方法进入下面的slot进行流控和降级的判断- 如果通过限流和降级的判断,则对
node的请求通过数和并发线程数都进行累加操作- 如果限流和降级没有通过则会走到
catch中,如果是PriorityWaitException,这个处理逻辑里面只增加了并发线程数量,这个就是让他等待,但是还是会占用线程,如果是BlockException,这个是拒绝异常,限流跑出来的,这里会进行拒绝数量的统计。- 回调处理,调用
ProcessorSlotEntryCallback的对应方法
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count,
boolean prioritized, Object... args) throws Throwable {
try {
// 先进入下面的slot进行流控/降级的判断
fireEntry(context, resourceWrapper, node, count, prioritized, args);
// Request passed, add thread count and pass count.
//能够走到这里,说明通过了流控/降级等处理,然后下面就进行一些统计信息的更新
//当前node的并发线程数+1
node.increaseThreadNum();
//通过请求数+n(一般这里就是1)
node.addPassRequest(count);
//如果有上游服务统计资源的话,则相应的增加上游服务的统计
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest(count);
}
//如果这个资源类型是IN,增加整个集群node的统计信息
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest(count);
}
//如果这里注册了监听者的话,进行回调
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (PriorityWaitException ex) {
//线程数量
node.increaseThreadNum();
if (context.getCurEntry().getOriginNode() != null) {
// Add count for origin node.
context.getCurEntry().getOriginNode().increaseThreadNum();
}
//如果这个资源类型是IN,增加集群node的线程数
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseThreadNum();
}
//回调
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (BlockException e) {
// Blocked, set block exception to current entry.
//没有通过,将异常信息保存到当前的entry里面
context.getCurEntry().setBlockError(e);
// Add block count.
//增加拒绝数量
node.increaseBlockQps(count);
//增加上游的拒绝数量
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseBlockQps(count);
}
//增加集群node的拒绝数量
if (resourceWrapper.getEntryType() == EntryType.IN) {
// Add count for global inbound entry node for global statistics.
Constants.ENTRY_NODE.increaseBlockQps(count);
}
//处理回调
for (ProcessorSlotEntryCallback<DefaultNode> handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onBlocked(e, context, resourceWrapper, node, count, args);
}
throw e;
} catch (Throwable e) {
// Unexpected internal error, set error to current entry.
context.getCurEntry().setError(e);
throw e;
}
}
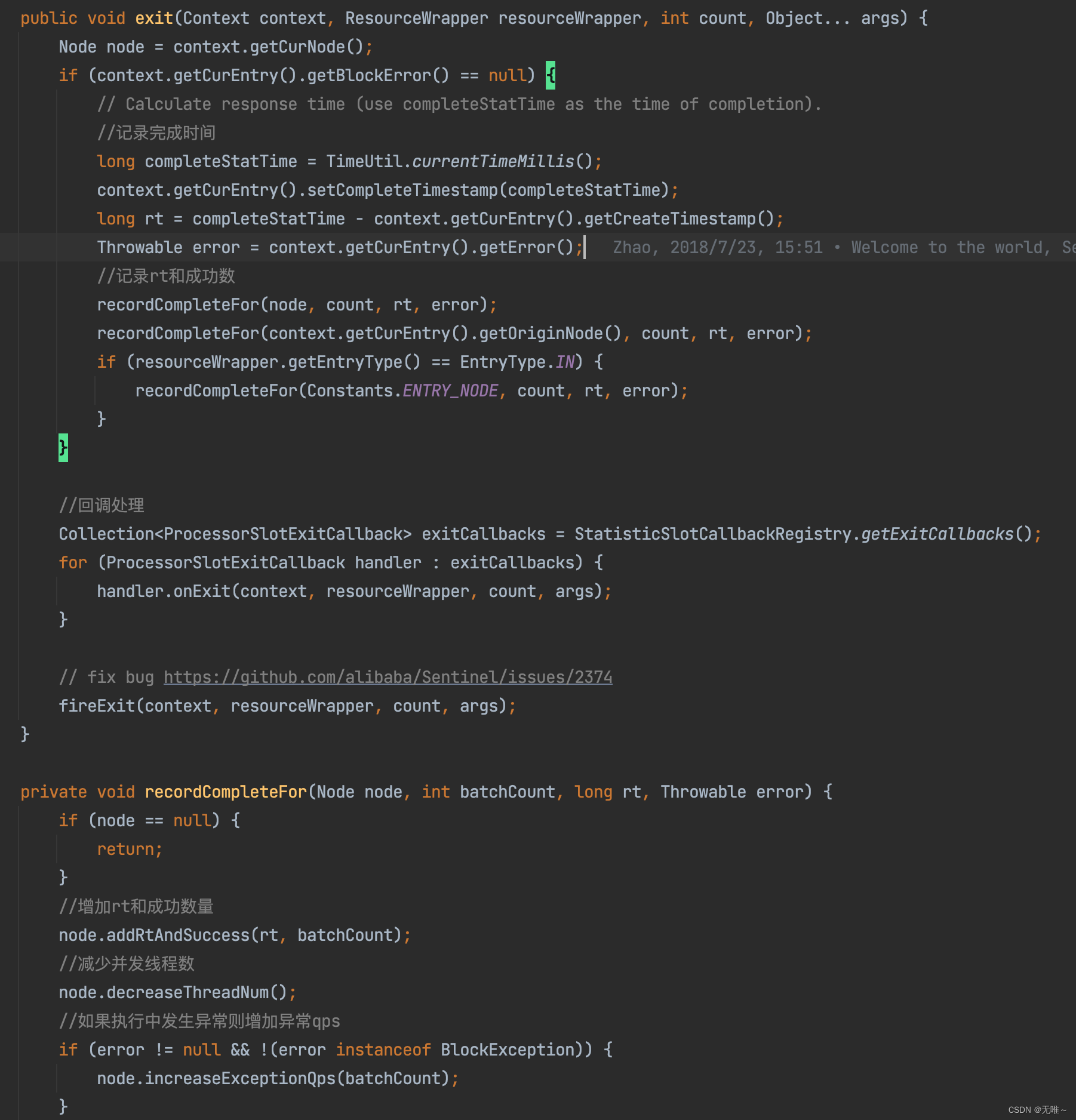
4.2 StatisticSlot#exit
这个
exit调用时机是在entry执行完,执行业务代码,不管执行是否成功都会调用,统计对应的完成时间,rt和成功数和异常qps`
五、AuthoritySlot
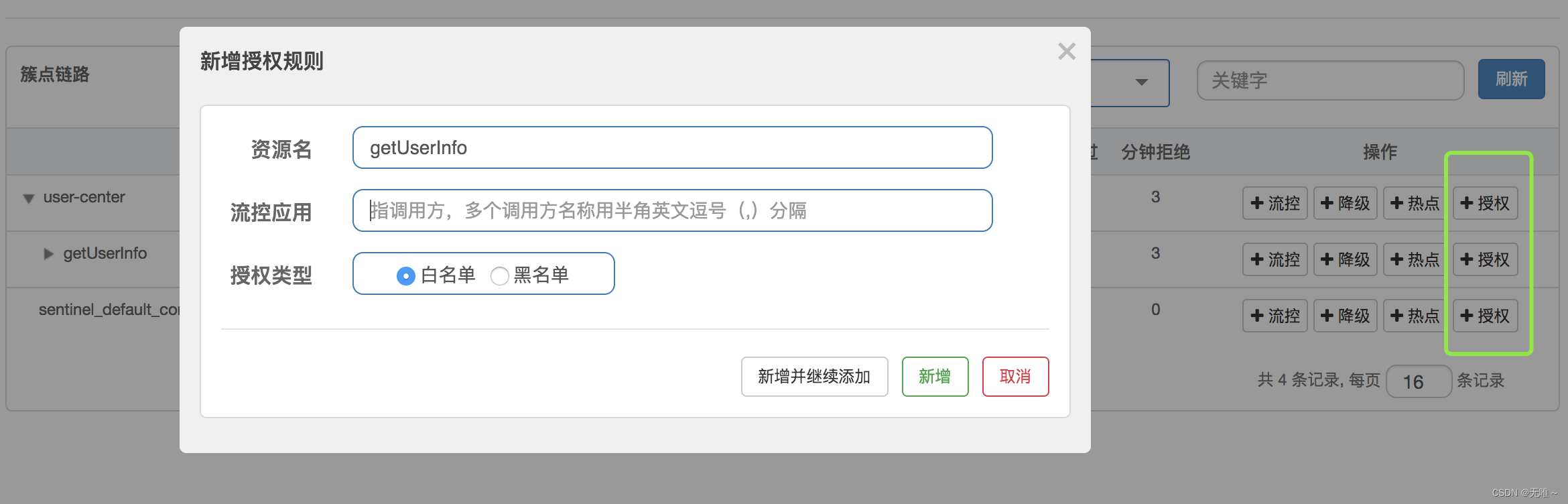
5.1AuthoritySlot#entry
这里会根据黑白名单,来做黑白名单控制,如果该
resource配置了AuthorityRule,则根据策略判断该资源请求的请求来源(origin)是否在配置规则LimitApp中( (,)隔开)和策略判断,是否检查通过。
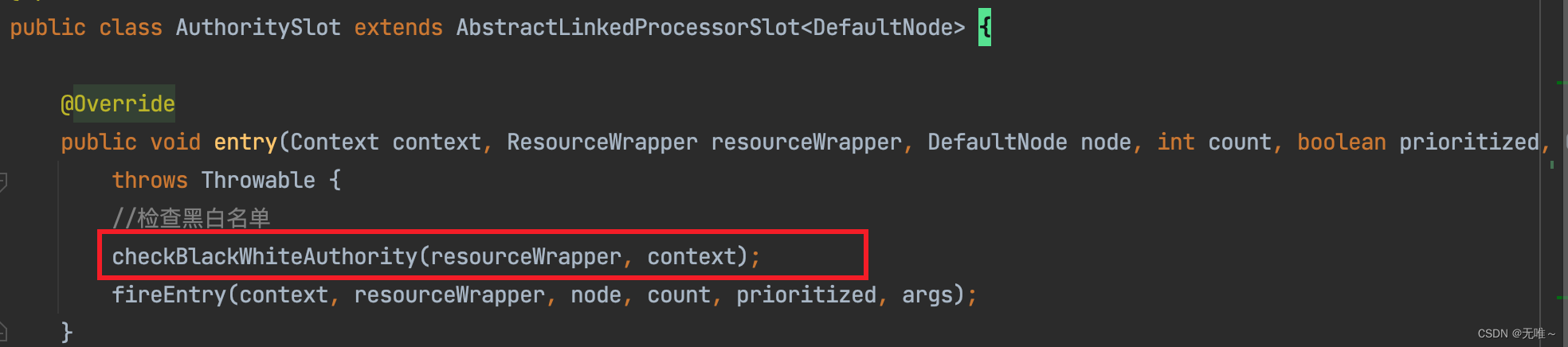
- 获取对该资源的认证规则
- 遍历进行认证检查
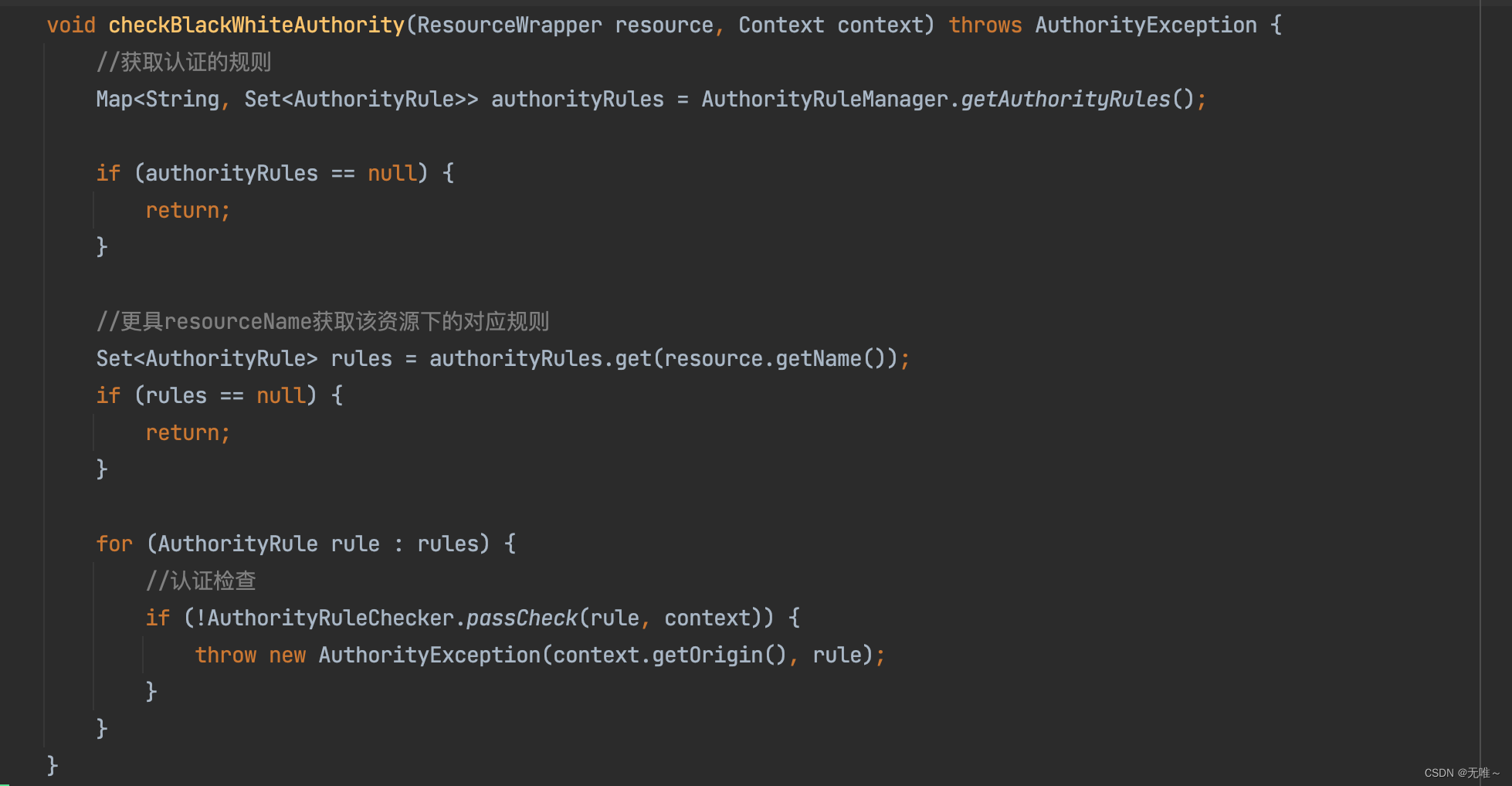
这里就是判断:
1.如果是白名单判断origin是否在limitApp中,如果在,则返回true,否则返回false
2.如果为黑名单,判断origin是否在limitApp中,如果在,则返回false,否则返回true
5.2AuthoritySlot#exit
这里没有任何逻辑,就是调用下一个

六、SystemSlot
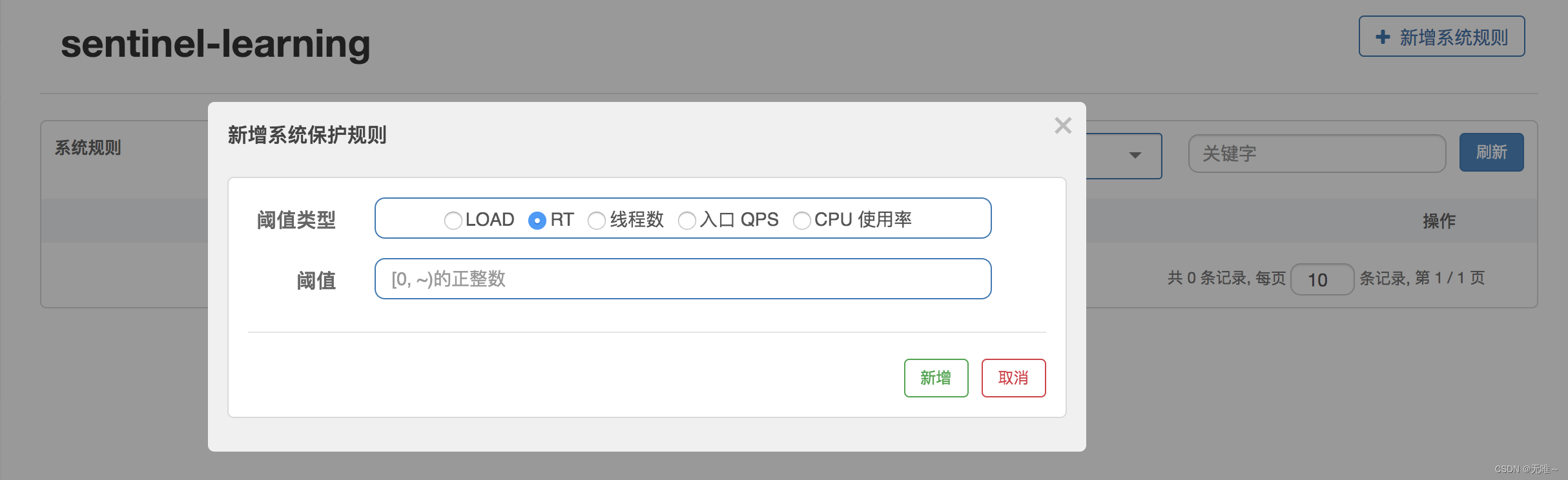
Sentinel系统自适应限流从整体维度对应用入口流量进行控制,结合应用的Load、CPU使用率、总体平均RT、入口QPS和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
通过系统load来做自适应限流有两个问题:
1.load是一个“结果”,如果根据load的情况来调节流量的通过率,那么就始终有延迟性。也就意味着通过率的任何调整,都会过一段时间才能看到效果。当前通过率是使load恶化的一个动作,那么也至少要过 1 秒之后才能观测到;同理,如果当前通过率调整是让load好转的一个动作,也需要 1 秒之后才能继续调整,这样就浪费了系统的处理能力。所以我们看到的曲线,总是会有抖动。
2.恢复慢。想象一下这样的一个场景(真实),出现了这样一个问题,下游应用不可靠,导致应用RT很高,从而load到了一个很高的点。过了一段时间之后下游应用恢复了,应用 RT 也相应减少。这个时候,其实应该大幅度增大流量的通过率;但是由于这个时候load仍然很高,通过率的恢复仍然不高。
所以Sentinel系统自适应限流参考了TCP BBR实现,根据系统能处理的请求和允许进来的请求来做一个平衡,而不是通过一个系统load来做限流,它最终的目的是在系统不被拖垮的情况下,提高系统吞吐量,而不是load一定要低于某个阈值

6.1 原理

我们把系统处理请求的过程想象为一个水管,到来的请求是往这个水管灌水,当系统处理顺畅的时候,请求不需要排队,直接从水管中穿过,这个请求的RT是最短的;反之,当请求堆积的时候,那么处理请求的时间则会变为:排队时间 + 最短处理时间。 如果我们能够保证水管里的水量,能够让水顺畅的流动,则不会增加排队的请求;也就是说,这个时候的系统负载不会进一步恶化。 我们用 T来表示(水管内部的水量),用RT来表示请求的处理时间,用P来表示进来的请求数,那么一个请求从进入水管道到从水管出来,这个水管会存在 P * RT 个请求。换一句话来说,当 T ≈ QPS * Avg(RT)的时候,我们可以认为系统的处理能力和允许进入的请求个数达到了平衡,系统的负载不会进一步恶化。
接下来的问题是,水管的水位是可以达到了一个平衡点,但是这个平衡点只能保证水管的水位不再继续增高,但是还面临一个问题,就是在达到平衡点之前,这个水管里已经堆积了多少水。如果之前水管的水已经在一个量级了,那么这个时候系统允许通过的水量可能只能缓慢通过,RT会大,之前堆积在水管里的水会滞留;反之,如果之前的水管水位偏低,那么又会浪费了系统的处理能力。
当保持入口的流量是水管出来的流量的最大的值的时候,可以最大利用水管的处理能力。
6.2 SystemSlot#entry
这里直接调用
SystemRuleManager#checkSystem来实现自适应限流
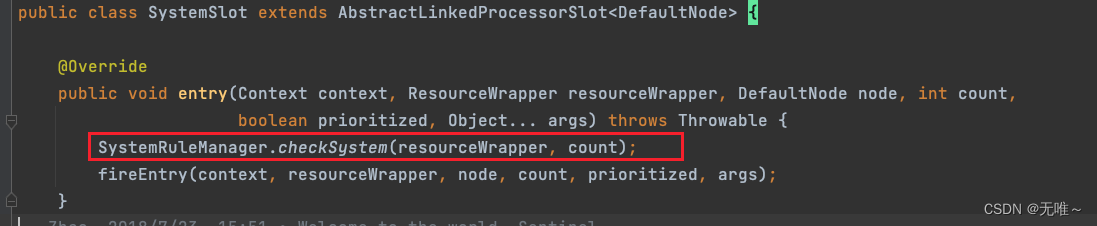
6.2.1 SystemRuleManager#checkSystem
- 如果资源名称为空,则直接跳过,这个是容错机制。如果系统自适应开关为打开,直接放行,该开关初始化时为 false,在加载到一条系统自适应配置规则时该状态会设置为 true,具体在 loadSystemConf 中。如果资源的类型不是入口流量(EntryType.IN),则直接放行。
- 从qps,线程数,响应时间纬度,判断是否需要进行限流,当前的qps,如果 ENTRY_NODE 为空则返回0,否则返回该统计节点的成功 qps,那ENTRY_NODE原来是 Sentinel 特定定义了一个资源,其名称为total_inbound_traffic,用来采集所有入口调用的信息,当资源进入类型为 ENTRY_TYPE_IN 时,会自动采集信息,其具体统计信息在 StatisticSlot 的 entry 方法中被调用
- 如果当前系统的负载超过了设定的阔值的处理逻辑,这里就是自适应的核心所在,并不是超过负载就限流,而是需要根据当前系统的请求处理能力进行综合判断,具体逻辑在 checkBbr 方法中实现,等下解析。
- 如果当前CPU的负载超过了设置的阔值,触发限流,后面会剖析JAVA中是如何获取CPU的使用率。
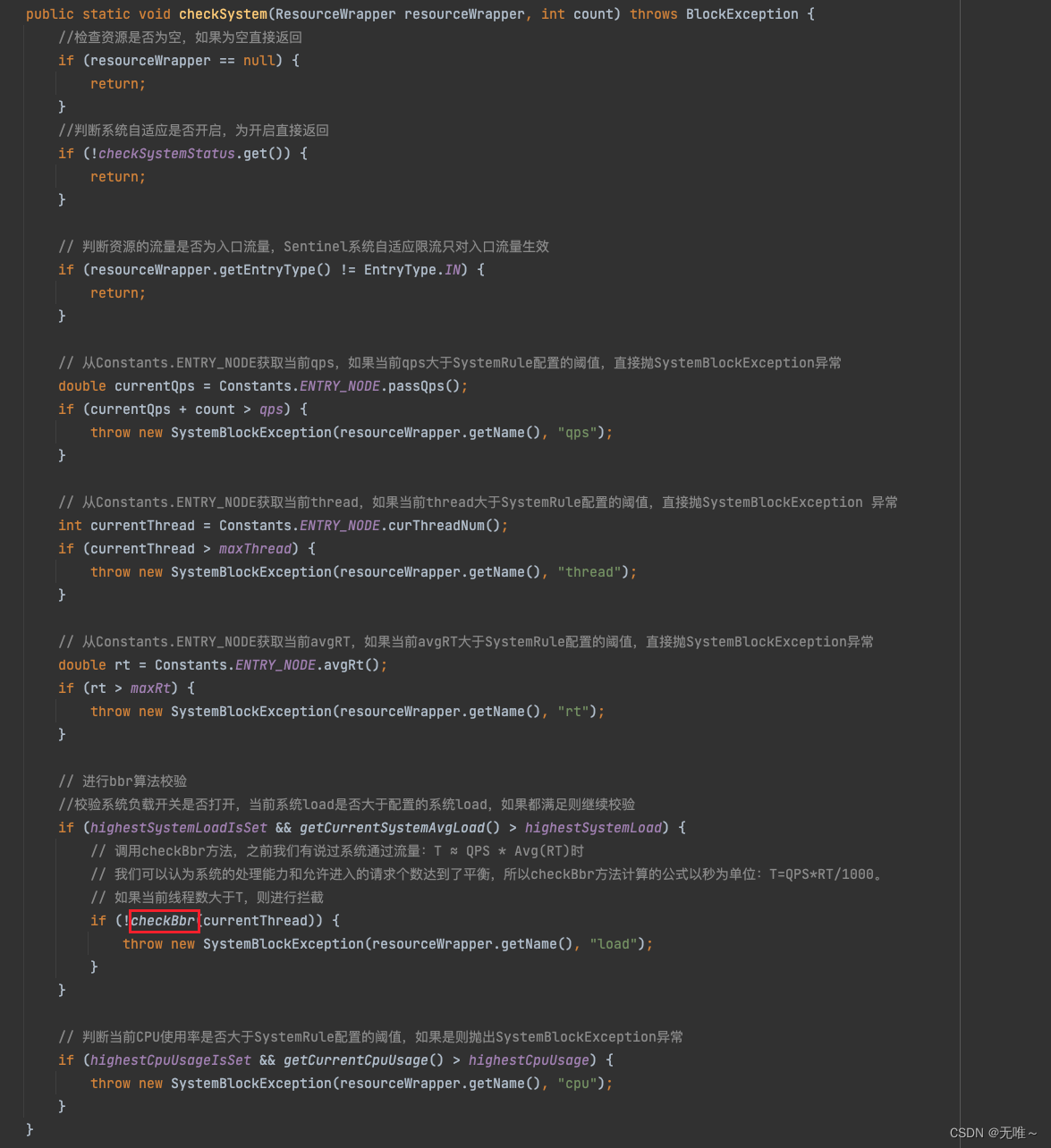
6.2.2 SystemRuleManager#checkBbr
在
Sentinel中估算系统的容量是以1s为度量长度,用该秒内通过的最大qps与 最小响应时间的乘积来表示,具体的计算细节:
•maxSuccessQps的计算取当前采样窗口的最大值乘以1s内滑动窗口的个数,这里其实并不是十分准确。
•minRt最小响应时间取自当前采样窗口中的最小响应时间。
故得出了上述计算公式,除以1000是因为minRt的时间单位是毫秒,统一为秒。从这里可以看出根据系统负载做限流,最终的判断依据是线程数量。这样就防止了系统过载,同时保证达到系统的最大处理能力。

6.2.3 如何采集系统平均负载和当前cpu使用率
这里会调用statusListener来获取对应的系统平均负载和cpu使用率。
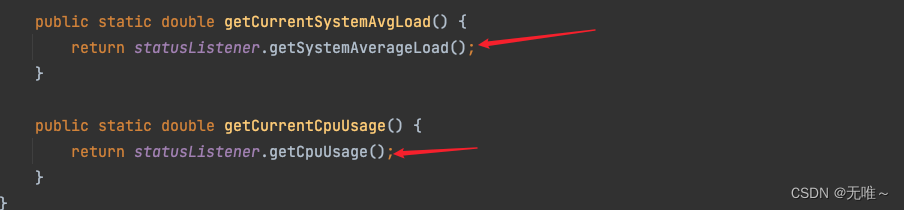
6.2.3.1 SystemStatusListener
在
SystemRuleManager的静态代码块中会初始化statusListener为SystemStatusListener,然后初始化线程池, 定时一秒运行一次,获取系统信息。

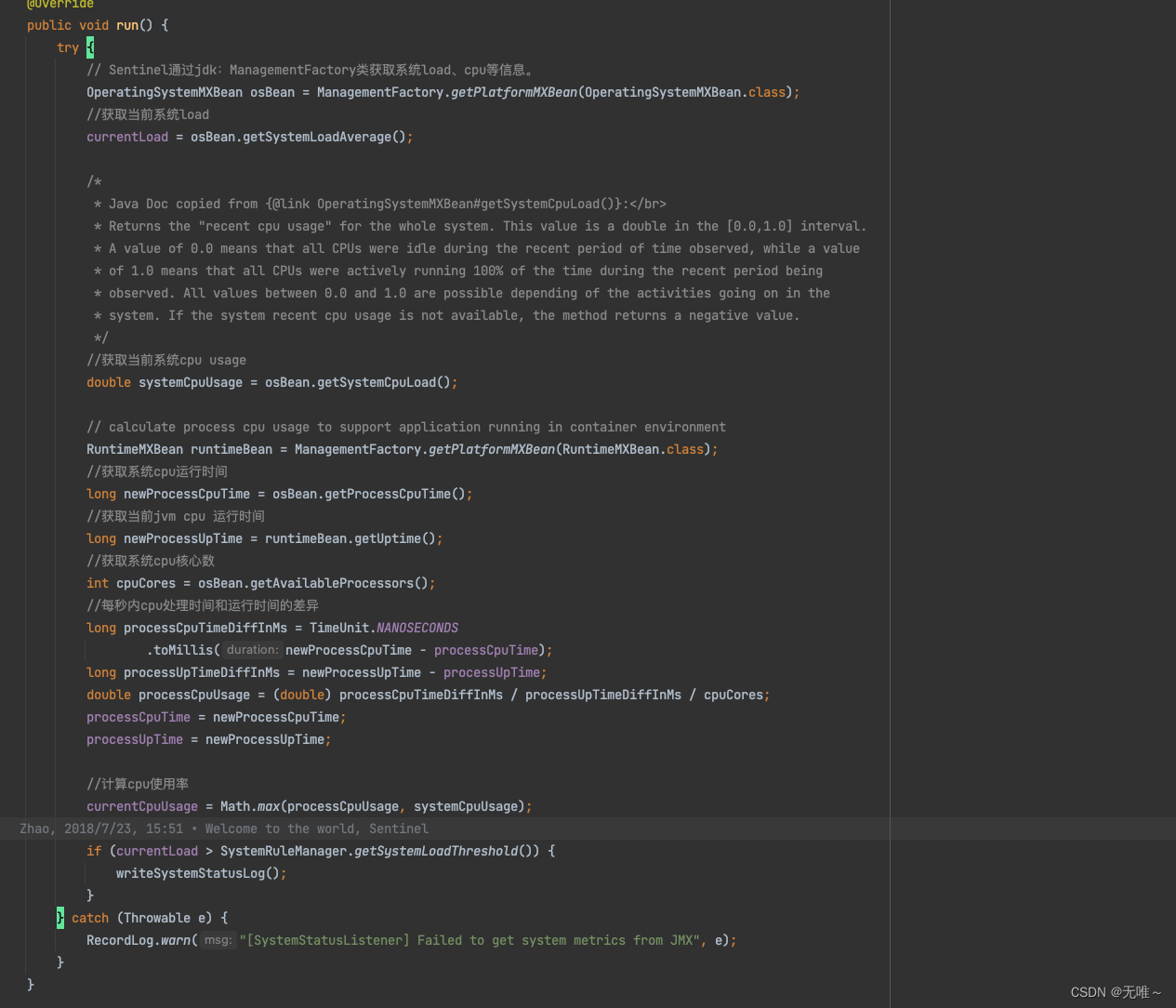
6.2.3.2 SystemStatusListener#run
这里其实就是通过JMX来获取当前系统的
load,cpu等信息,计算出来cpu使用率
6.2 SystemSlot#exit
直接调用下一个slot

七、FlowSlot
7.1FlowSlot#entry
- 调用
FlowRuleChecker检查流控,这里有个ruleProvider,这个是个function,他其实是根据resource来获取针对当前资源的所有流控规则。
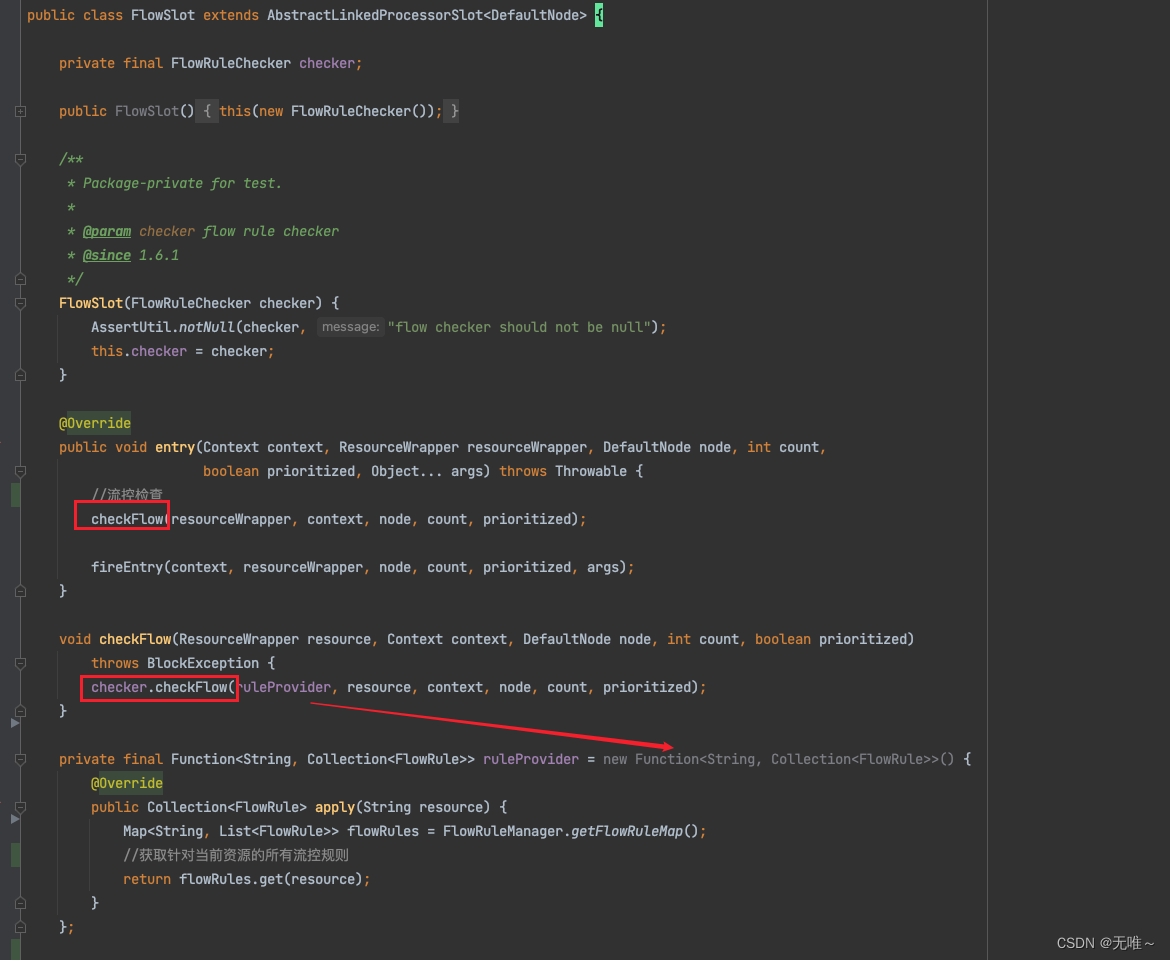
7.1.1FlowRuleChecker#checkFlow
- 遍历所有的规则调用
canPassCheck方法- 根据是单机模式还是集群模式调用不同的流控处理
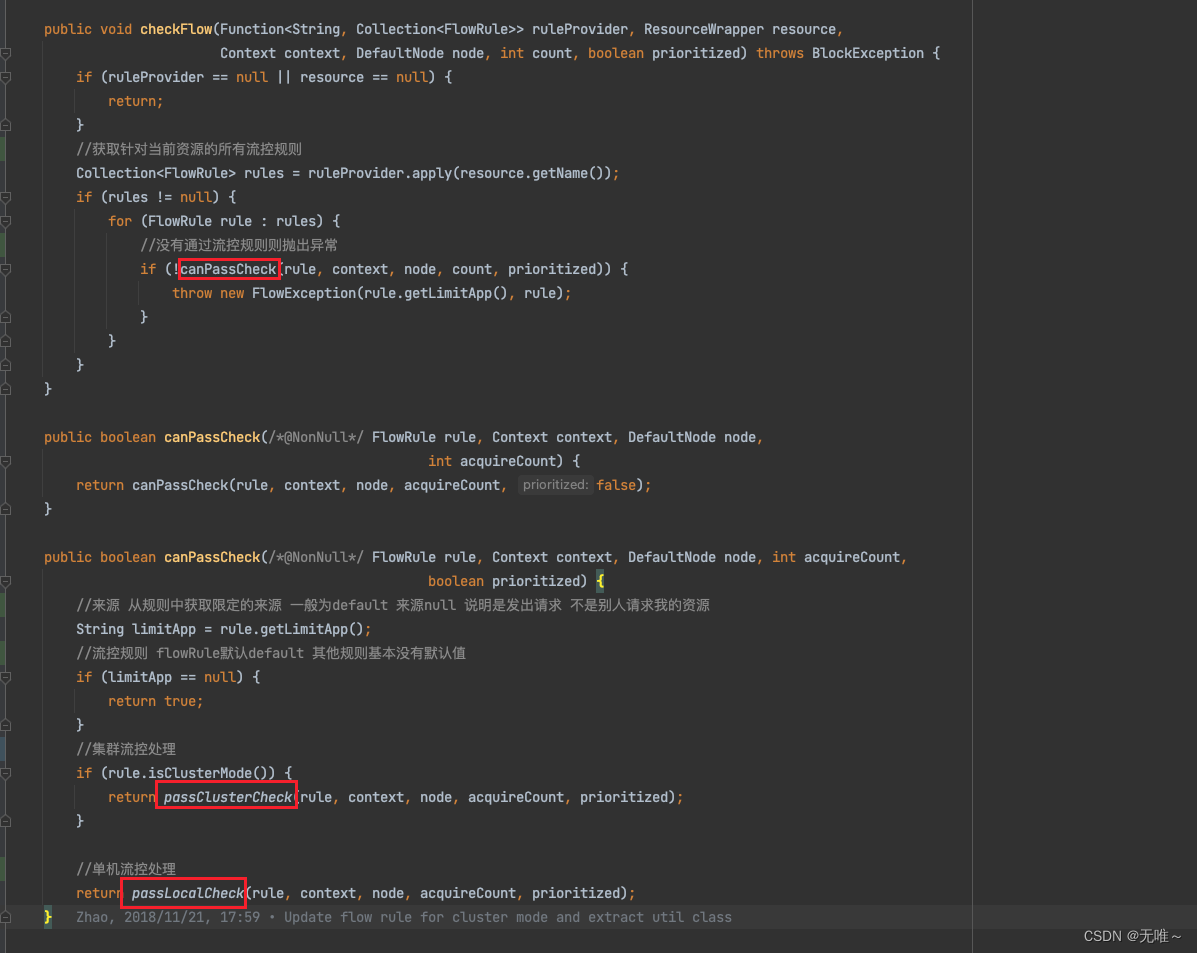
7.1.2. FlowRuleChecker#passClusterCheck
- 直接或远程调用
TokenService获取限流结果- 如果远程限流失败或者连接失败等其他异常情况则根据配置直接通过限流或者退化到
local模式的限流
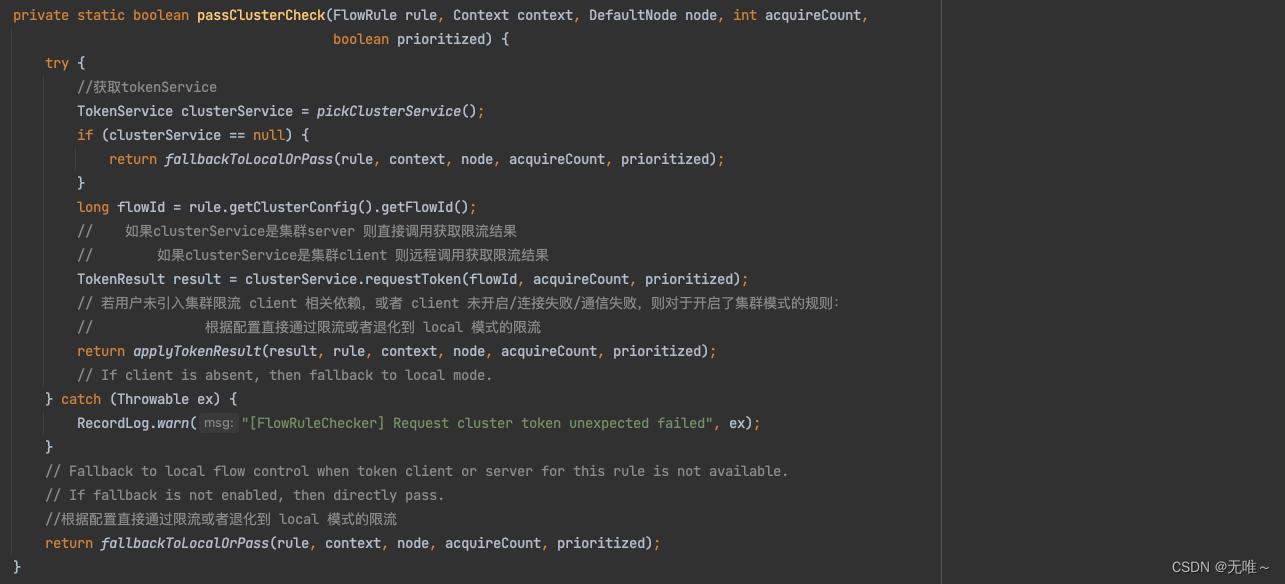
7.1.3 TokenService#requestToken
我们看到TokenService有三个实现:
- DefaultClusterTokenClient:集群流控客户端,用于向所属 Token Server 通信请求 token。集群限流服务端会返回给客户端结果,决定是否限流。
- DefaultEmbeddedTokenServer:内嵌模式的集群服务端,作为内置的token server和服务部署在同一进程中启动,用于处理客户端请求,判断是否发放token
- DefaultTokenService:单独部署的集群服务端,用于处理客户端请求,判断是否发放token。
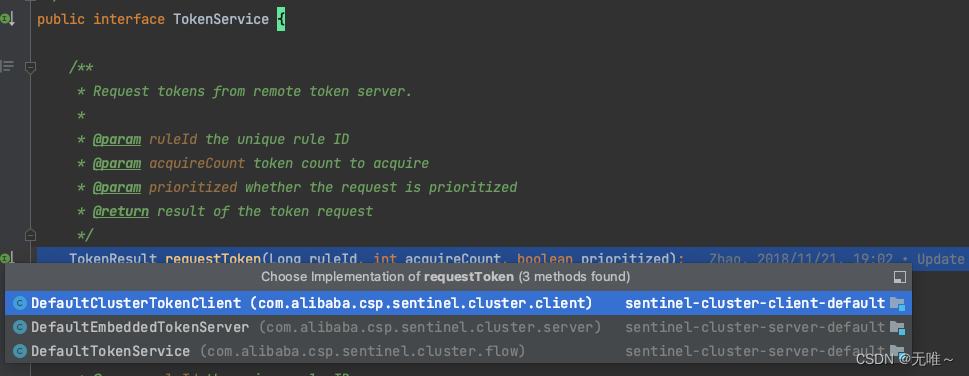
7.1.4 DefaultClusterTokenClient#requestToken
这里就是构造请求数据,然后调用
sendTokenRequest方法发送请求
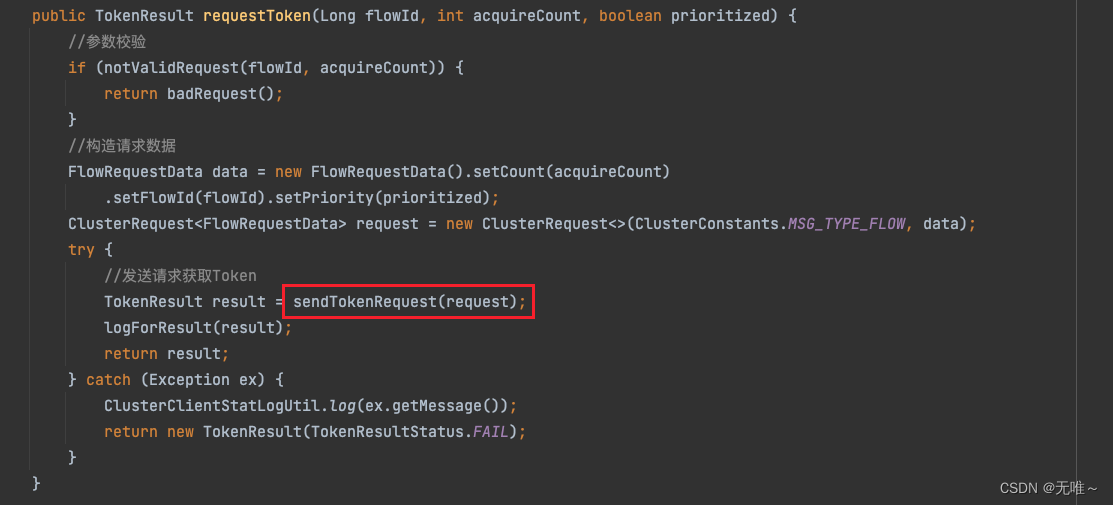
7.1.5 DefaultClusterTokenClient#sendTokenRequest
- 发送请求到服务端
- 构造
TokenResult返回
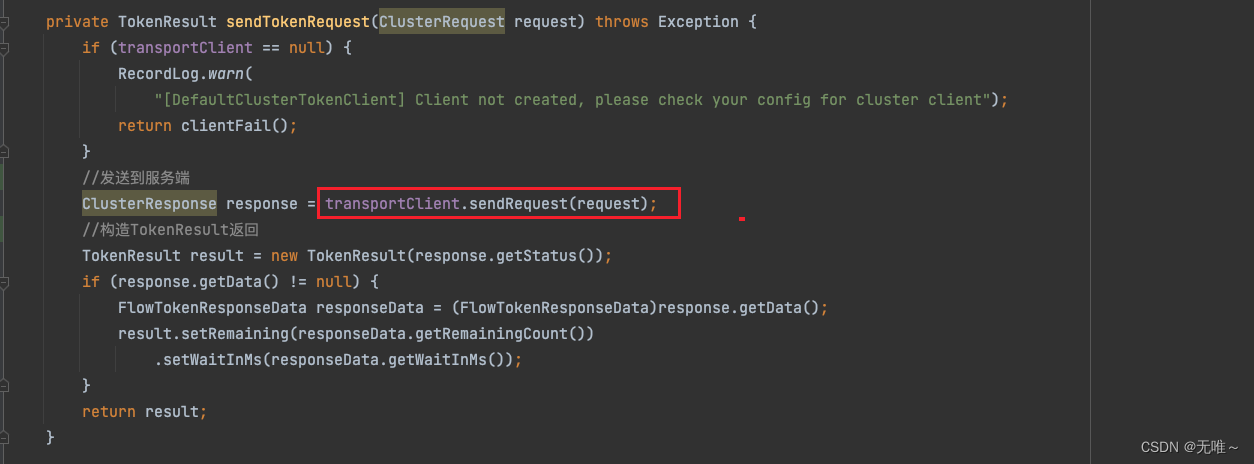
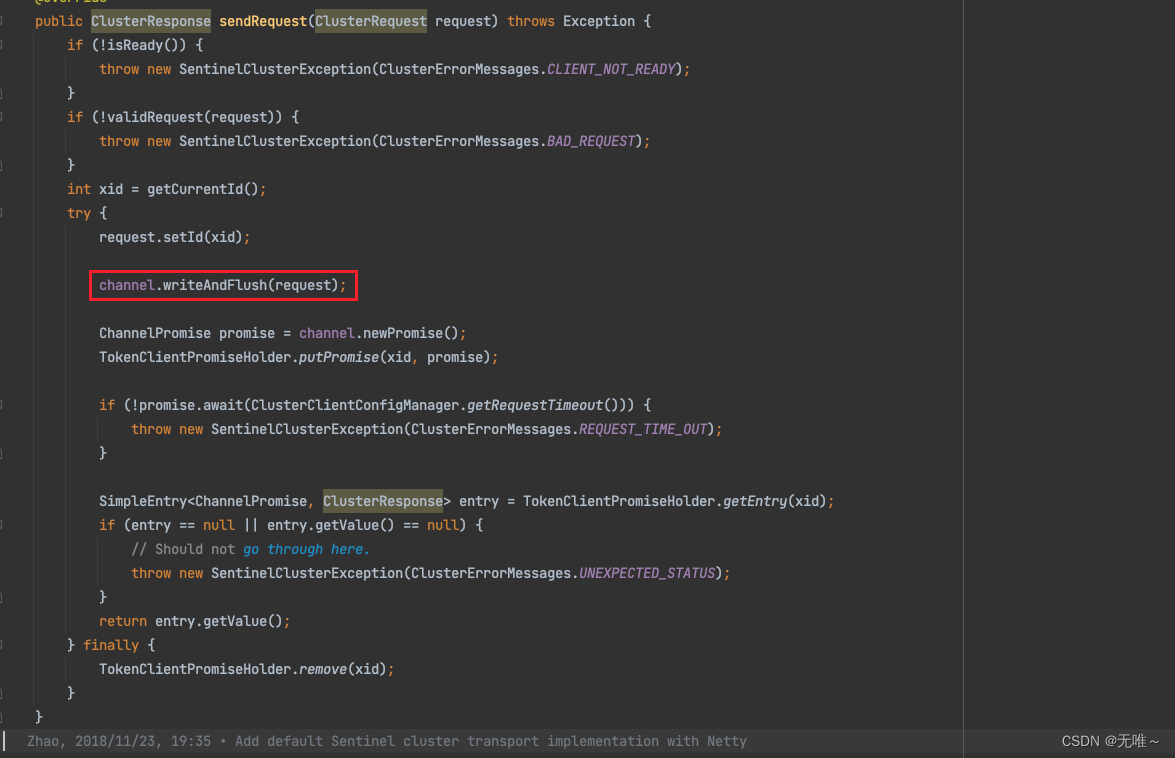
7.1.6 DefaultClusterTokenClient#sendTokenRequest
这里就是通过
netty发送请求到服务端,就是把请求写入到channel中,并通过ChannelPromise等待请求结果并返回
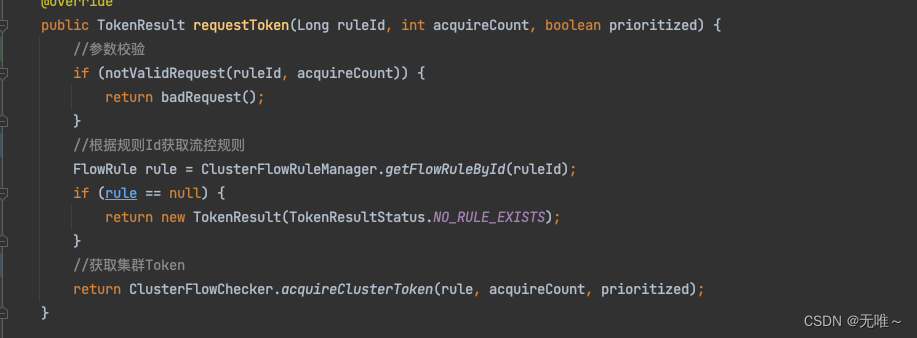
7.1.7 DefaultTokenService#requestToken(服务端处理请求)
- 请求参数校验
- 根据规则
Id获取流控规则- 根据规则获取集群
token
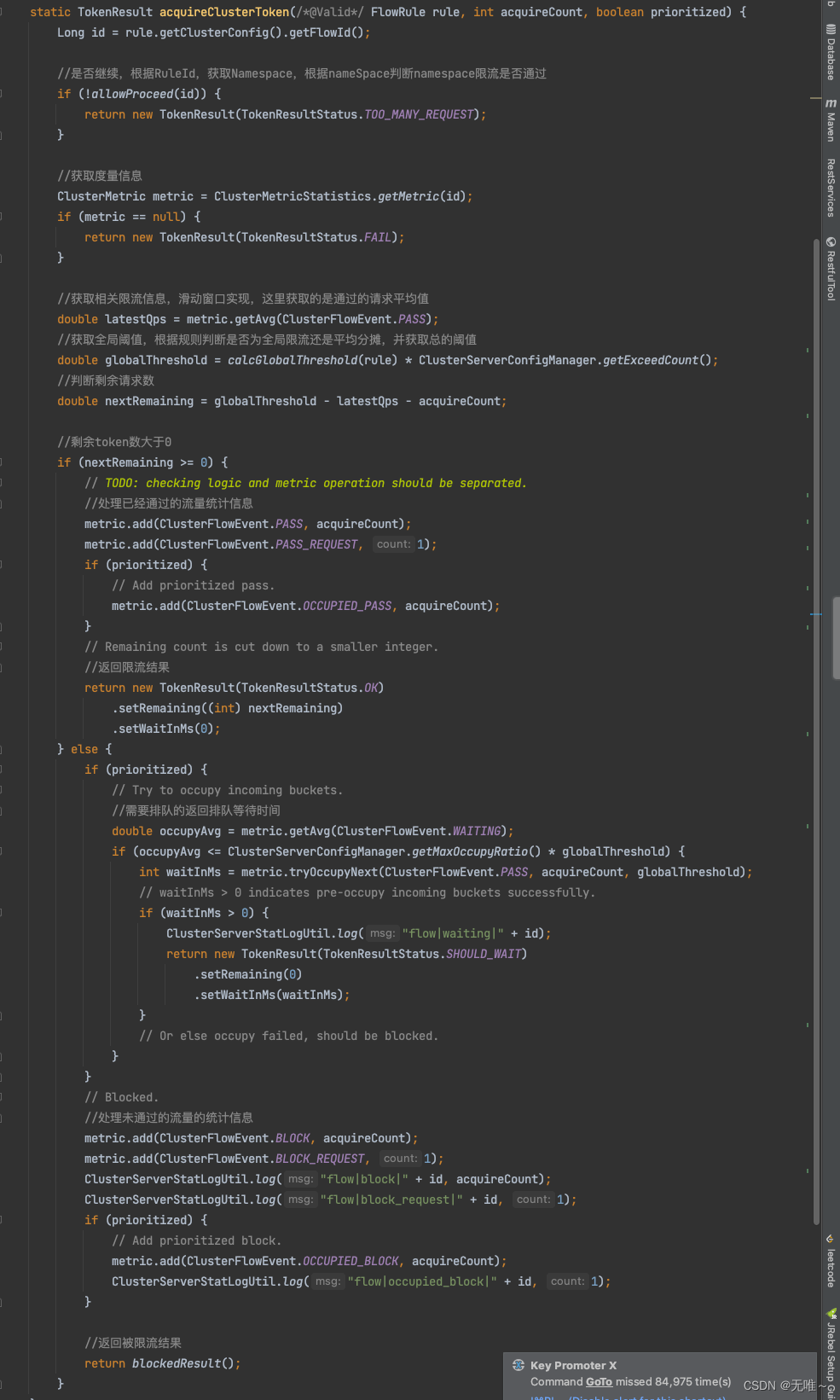
7.1.8 ClusterFlowChecker#acquireClusterToken
- 首先从
metric中获取每秒请求数- 根据规则判断全局限流还是平均分担,其中单机均摊模式下配置的阈值等同于单机能够承受的限额,
token server会根据客户端对应的namespace(默认为project.name定义的应用名)下的连接数来计算总的阈值(比如独立模式下有 3 个client连接到了token server,然后配的单机均摊阈值为 10,则计算出的集群总量就为 30);而全局模式下配置的阈值等同于整个集群的总阈值。- 计算出剩余请求数判断是否通过限流
- 返回限流结果给客户端
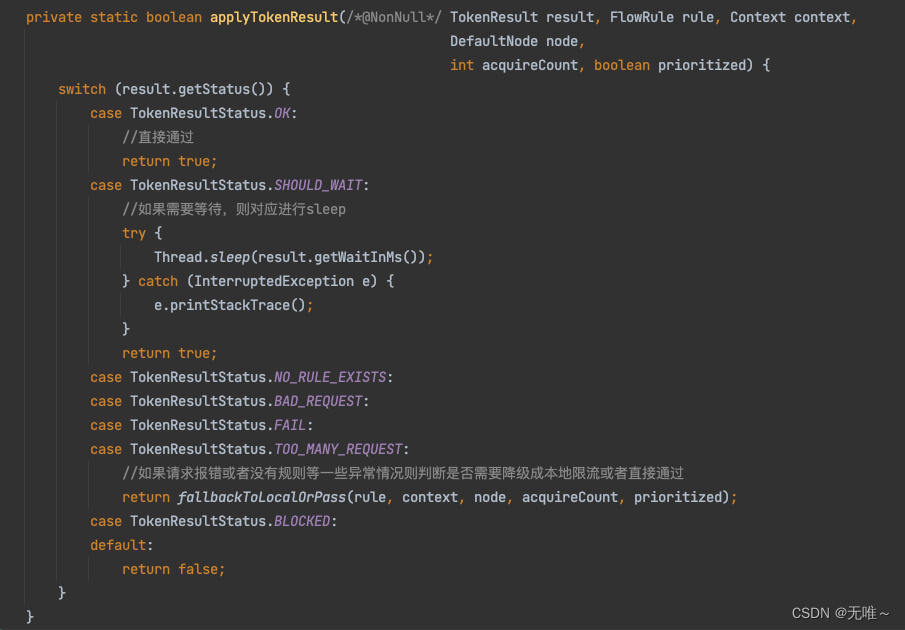
7.1.9 FlowRuleChecker#applyTokenResult
- 客户端接收到服务端限流的结果,根据结果判断是通过,还是需要等待,还是被限流,还是其他异常情况则判断需要降级成本地限流还是直接通过。
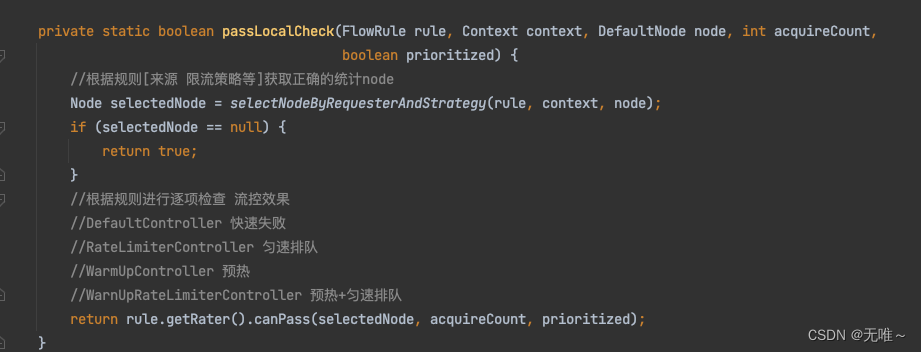
7.1.10 FlowRuleChecker#passLocalCheck
- 根据规则[来源 限流策略等]获取正确的统计
node- 根据配置的流控规则进行逐项检查。
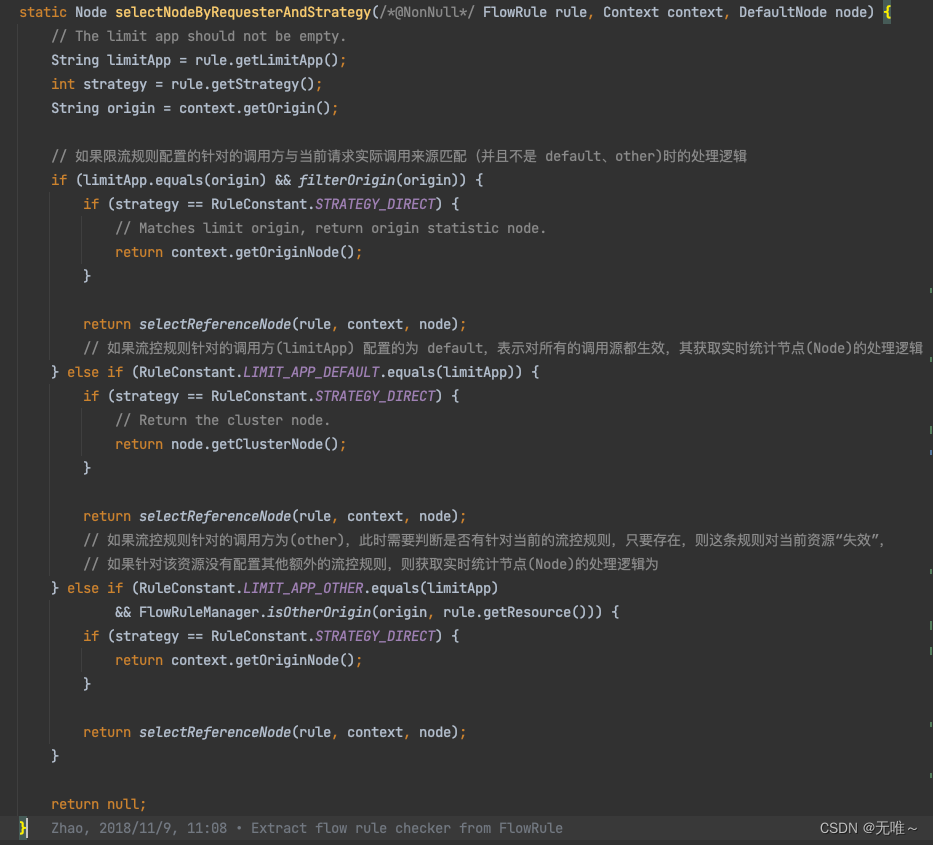
7.1.11 FlowRuleChecker#passLocalCheck
- 这里就是根据对应的流控模式,根据对应模式是直接、关联、链路选取对应的统计
node节点。
直接流控模式(DIRECT):最简单的模式,对当前资源达到条件后直接限流。
关联流控模式(RELATE):定义一个关联接口,当关联接口达到限流条件,当前资源会限流。
链路流控模式(CHAIN):针对来源进行区分,定义一个入口资源,如果当前资源达到限流条件,只会对该入口进行限流
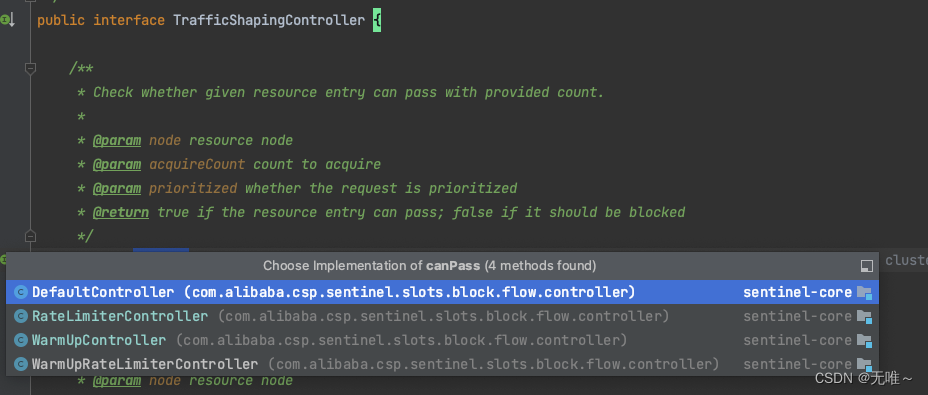
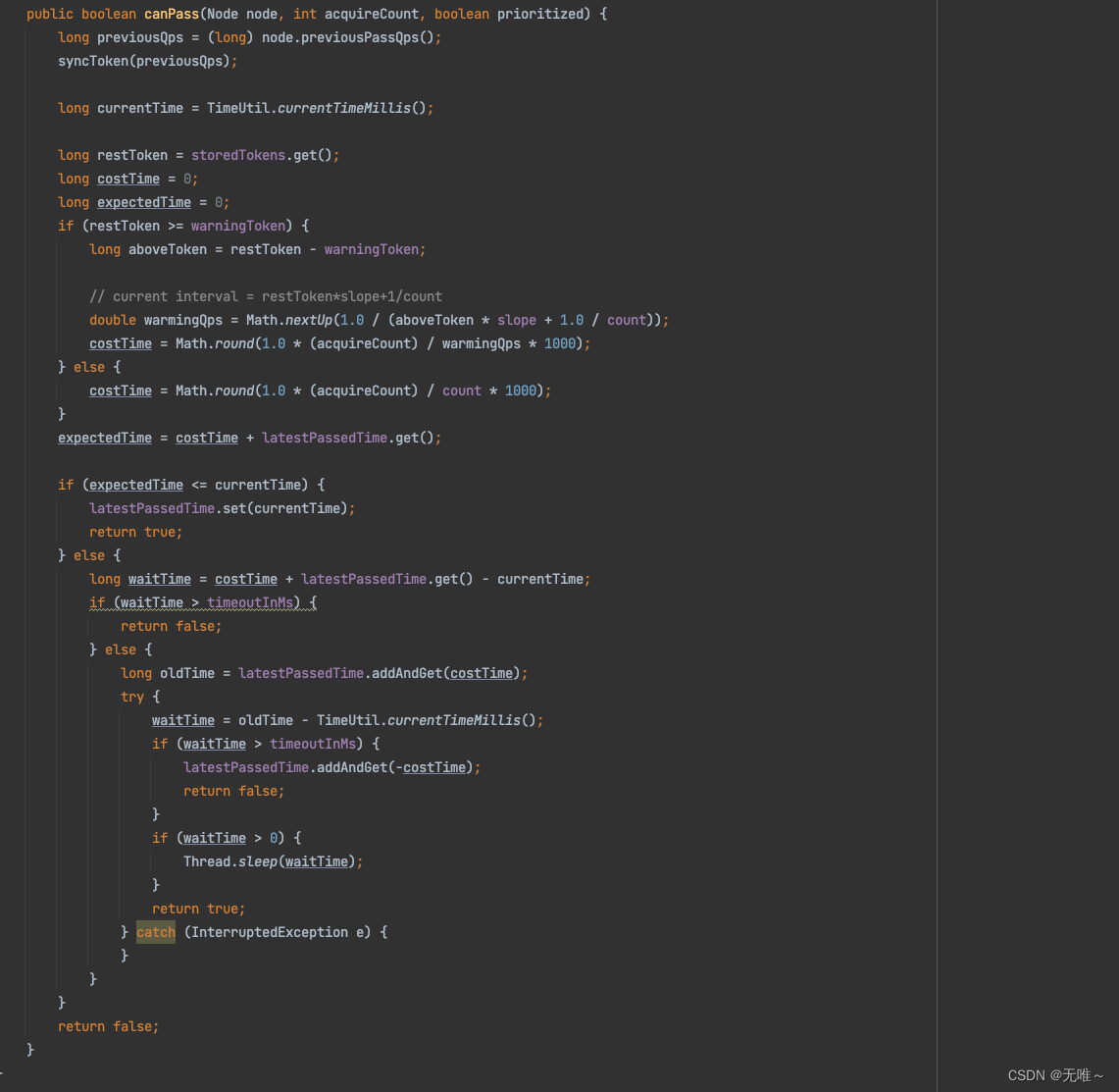
7.1.12 TrafficShapingController#canPass
这里
TrafficShapingController有四种实现
DefaultController:快速失败WarmUpController:预热RateLimiterController:匀速排队WarmUpRateLimiterController:预热+匀速排队
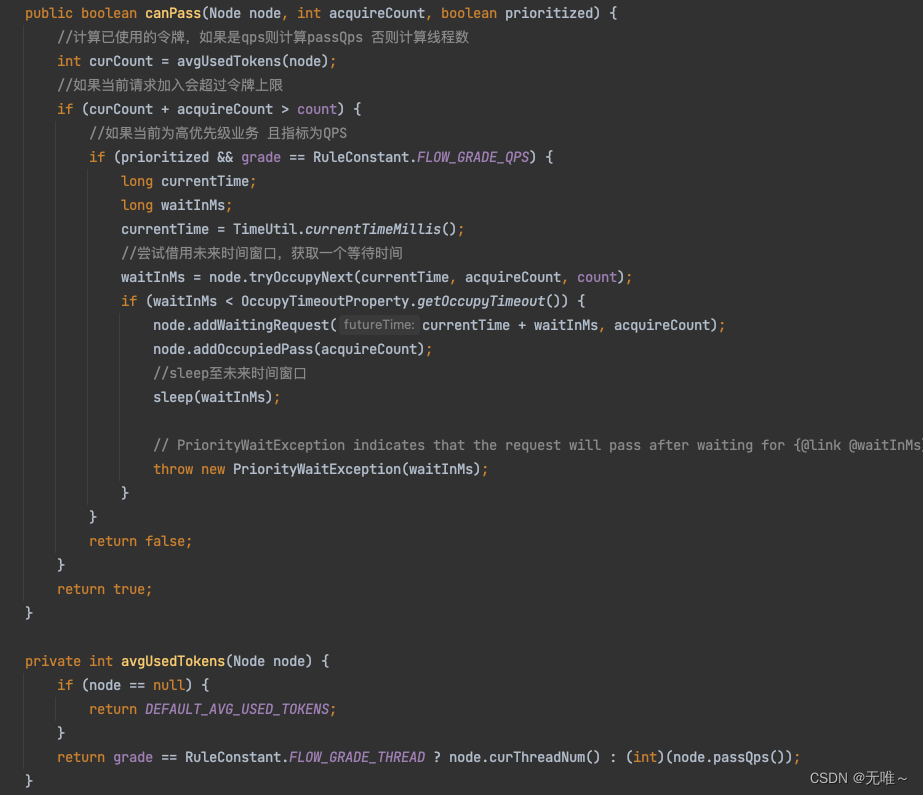
7.1.12.1 DefaultController#canPass
- 这里首先调用
avgUsedTokens方法根据对应的统计阈值类型从统计node获取对应的当前线程数或者每秒请求通过数- 判断加上当前请求有没有到达阈值,如果到达阈值,还会判断是否设置了允许
occupied_pass,会先借用未来的时间窗口,如果都不行则会快速失败。
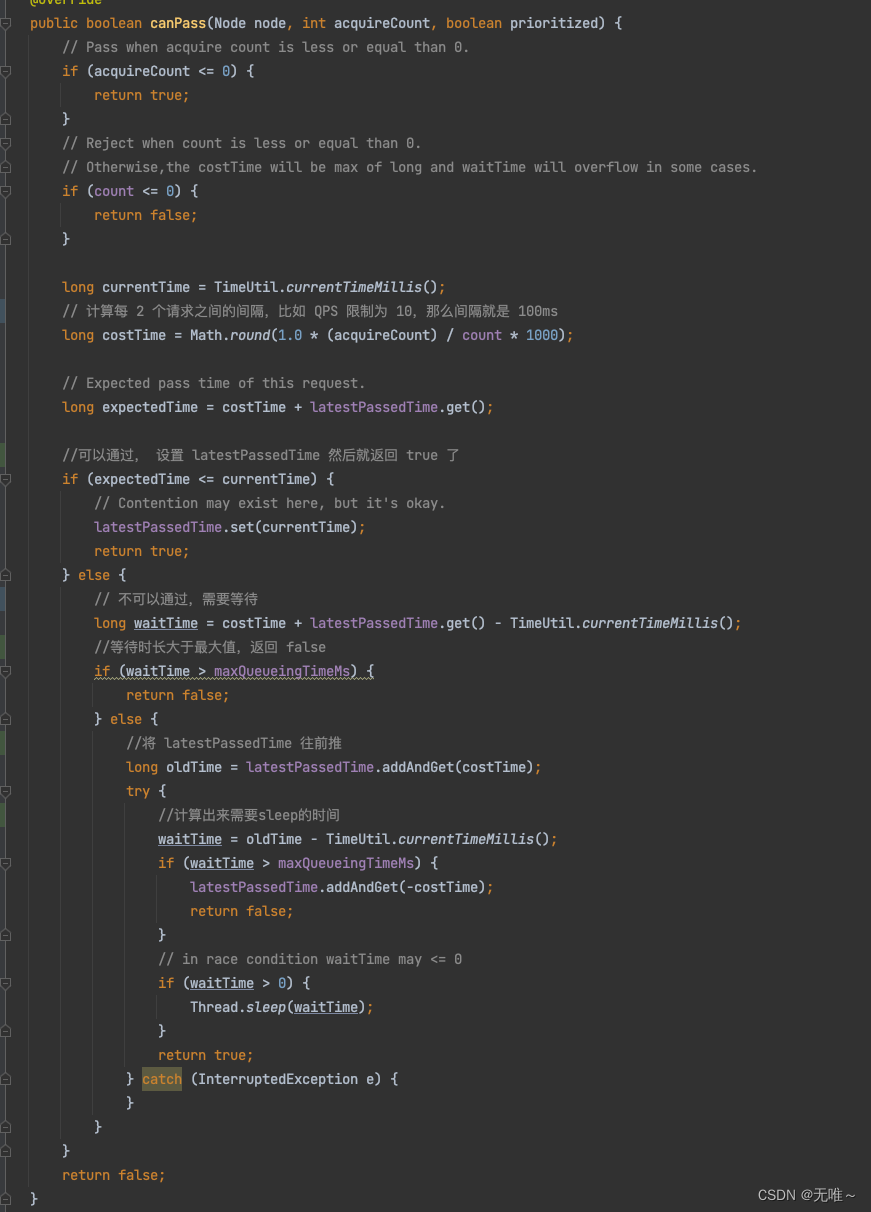
7.1.12.2 RateLimiterController#canPass
- 匀速排队本质上就是漏桶算法,流出的速率是固定的,请求过来如果桶满则溢出丢弃。
- 下面的实现就是通过线程
sleep来调整请求的间隔,达到匀速排队的效果。- 首先计算出每一个请求的最小的间隔,例如
cout设置为1000,表示一秒可以通过1000个请求,匀速排队,那每个请求的间隔为1 / 1000(s),乘以1000将时间单位转换为毫秒,如果一次需要2个令牌,则其间隔时间为2ms,用costTime表示。- 计算下一个请求的期望达到时间,等于上一次通过的时间戳 +
costTime,用expectedTime表示。- 如果
expectedTime大于当前时间,说明还没到令牌发放时间,当前请求需要等待。首先先计算需要等待是时间,用waitTime表示。- 如果计算的需要等待的时间大于允许排队的时间,则返回
false,即本次请求将被限流,返回FlowException。- 进入排队,默认是本次请求通过,故先将上一次通过流量的时间戳增加
costTime,然后直接调用Thread的sleep方法,将当前请求先阻塞一会,然后返回true表示请求通过。
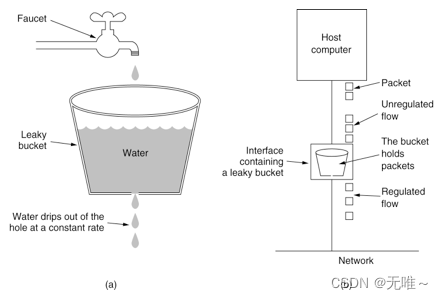
例:设置 QPS 为10,那么每100毫秒允许通过一个,通过计算当前时间是否已经过了上一个请求的通过时间latestPassedTime之后的100毫秒,来判断是否可以通过。
// 假设才过了50ms,那么需要当前线程再 sleep50ms,然后才可以通过。如果同时有另一个请求呢?那需要 sleep150ms才行。
7.1.12.3 WarmUpController#canPass
- 所谓冷启动,或预热是指,系统长时间处理低水平请求状态,当大量请求突然到来时,并非所有请求都放行,而是慢慢的增加请求,目的时防止大量请求冲垮应用,达到保护应用的目的。
Sentinel中冷启动是采用令牌桶算法实现。
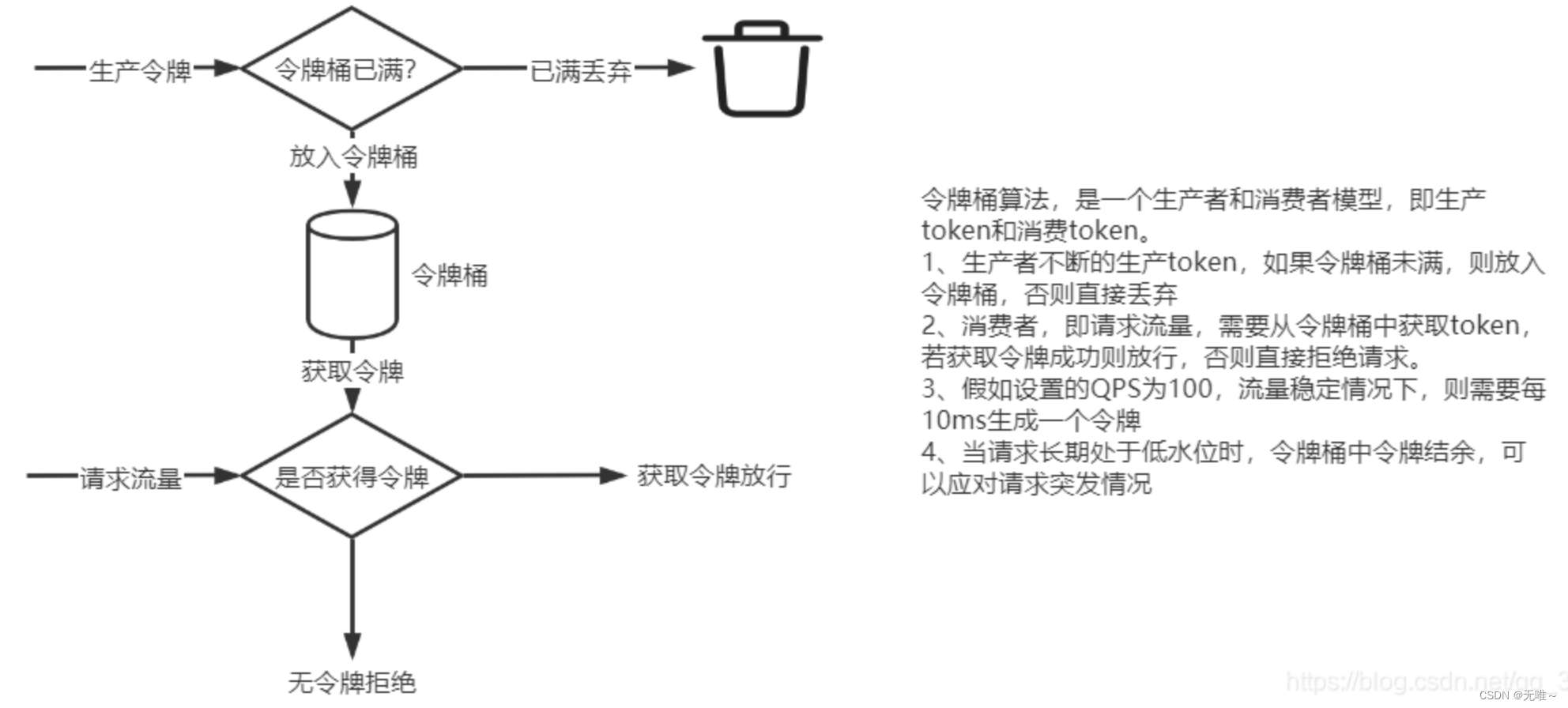
Sentinel中的令牌桶算法,是参照Google Guava中的RateLimiter,在学习Sentinel中预热算法之前,先了解下整个预热模型,如下图:
Guava中预热是通过控制令牌的生成时间(Guava的理念是,假设qps上限为100,那么稳定状态下的时间间隔就应该是10ms。Guava通过如让线程sleep的方式,来调整时间间隔,从而达到预热缓慢让qps上升的效果,从而实现流量的控制。),而Sentinel中实现不同,不控制每个请求通过的时间间隔,而是控制每秒通过的请求数。
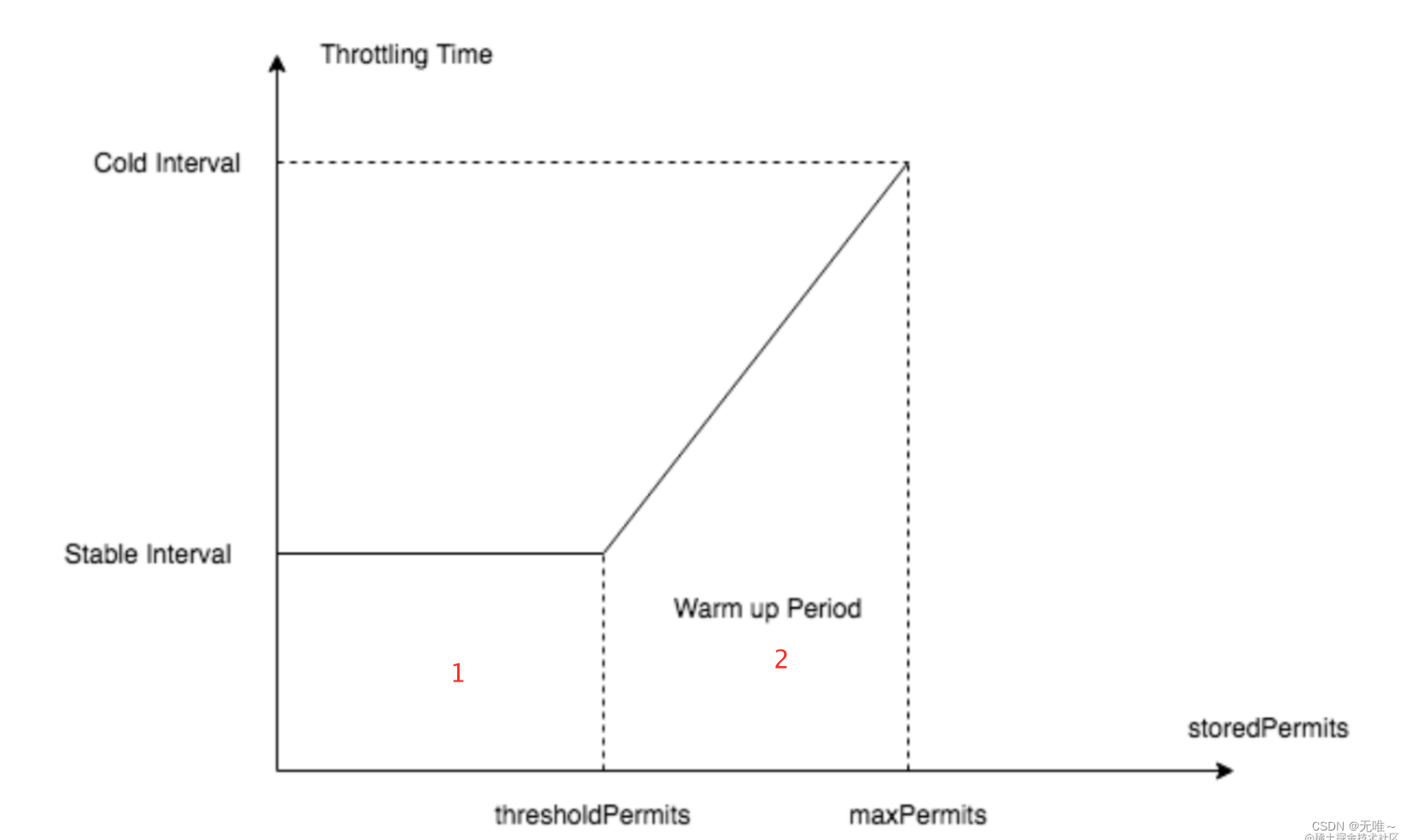
如上图所示:X轴表示令牌桶中的令牌数量,y轴表示生产一个令牌需要的时间(秒),相关参数如下所示:
stableInterval(稳定区间):稳定生产一个令牌需要时间coldInterval:生产一个令牌需要的最长时长,与冷启动因子coldFactor有关;可以通过-Dcsp.sentinel.flow.cold.factor设置,默认为3。warmUpPeriodSec(预热时间秒):预热时长,默认10秒,对应坐标图中为(2)梯形面积。thresholdPermits阈值允许(warningToken):令牌桶中一个阈值,超过该值时开启预热。maxPermits(maxtoken):令牌桶中最⼤令牌数
相关公式:
count:由用户设置,表示每秒允许通过请求数量
warmUpPeriodInSec:由用户设置,默认10s,上图区域(2)梯形区域coldFactor,默认为3.
coldFactor 表示的含义为 coldIntervalMicros 与 stableIntervalMicros 的比值。
公式1:
这里表示稳定产生一个令牌需要的时间,这里count是每秒允许通过请求数量,我们要达到这个允许通过请求量就得每10ms生产一个令牌
stableInterval=1/count
公式2:
这里表示生产一个令牌需要的最长时长,这里对应上图的y轴,我们需要*冷启动因子
coldInterval=stableInterval*coldFactor
公式3:
前提:由于coldFactor默认为3,y轴stableInterval-coldInterval的距离是0-stableInterval的距离两倍,时间区域上(2)梯形区域是(1)的长方形区域的两倍
这里是上图(1)区域的长方形的面积
长方形区域面积=长(thresholdPermits(waringToken))*宽(stableInterval)
公式4:
因为我们知道冷却因子是3,也就是coldIntervalMicros是stableIntervalMicros的3倍,梯形区域是长方形区域的2倍。
长方形区域面积=0.5*warmUpPeriodSec
公式5:
因为warmUpPeriodSec是梯形区域,梯形区域是长方形区域的2倍,所以warmUpPeriodSec*0.5就是长方形区域,然后长方形区域等于长(thresholdPermits(waringToken))*宽(stableInterval),所以thresholdPermits(waringToken)就等于下面公式:
(thresholdPermits(warningToken))=0.5*warmUpPeriodSec/stableInterval
代码:
这里warmUpPeriodInSec是我们的预热时长,count是每秒产生的令牌数,coldFactor-1是梯形区域的冷却因子。
warningToken=(int)(warmUpPeriodInSec*count)/(coldFactor-1);
公式6:
前提:梯形的面积=(上低+下低)*高/2推导出maxPermits(maxToken)值、
warmUpPeriodSec = 0.5 * (stableInterval + coldInterval) * (maxPermits - thresholdPermits) (梯形面积,(上底 + 下底 * 高 / 2) )
1. 两边同时*2
2. 2*warmUpPeriodSec= (stableInterval + coldInterval) * (maxPermits - thresholdPermits)
3. 两边同时/ (stableInterval + coldInterval)
4. 2*warmUpPeriodSec/(stableInterval+coldInterval)=(maxPermits - thresholdPermits)\
5. 两边同时+thresholdPermits
6. maxPermits=2*warmUpPeriodSec/(stableInterval+coldInterval)+thresholdPermits(warningToken)
代码:
maxToken=warningToken+(int)(2*warmUpPeriodInSec*count/(1.0+coldFactor));
公式7:
前提:斜率公式=(y1-y2)/(x1-x2)
slope=(coldInterval-stableInterval)/(maxToken-warningToken)
代码:
slope=(coldFactor-1.0)/count/(maxToken-warningToken);
原理:
- 当令牌桶中的令牌 <
thresholdPermits(warningToken)时,令牌按照固定速率生产,请求流量稳定。 - 当令牌 >
thresholdPermits(warningToken)时,开启预热,生产的令牌的速率 < 令牌滑落的速度,一段时间后,令牌 <=thresholdPermits(warningToken),请求回归到稳定状态,预热结束。
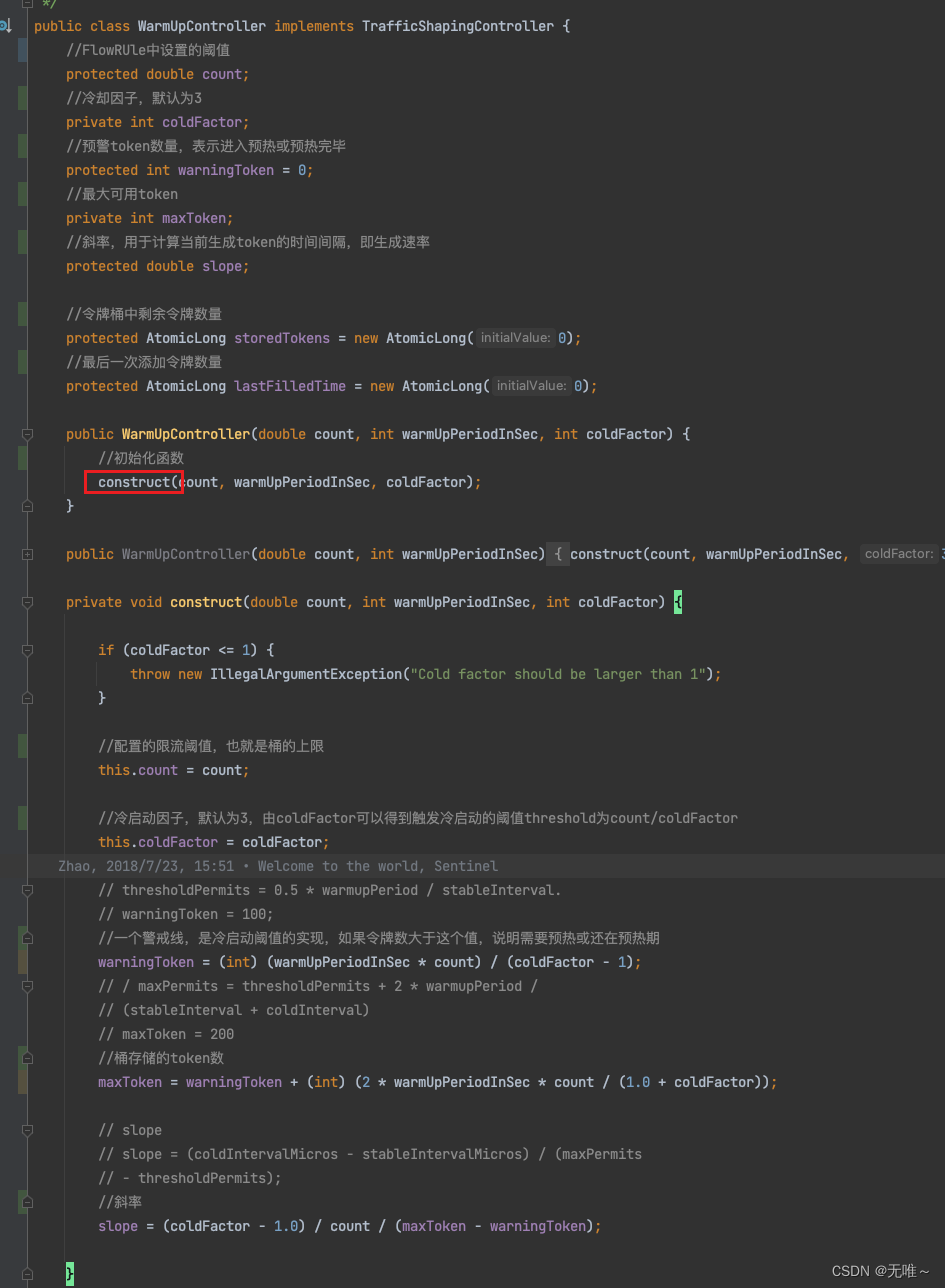
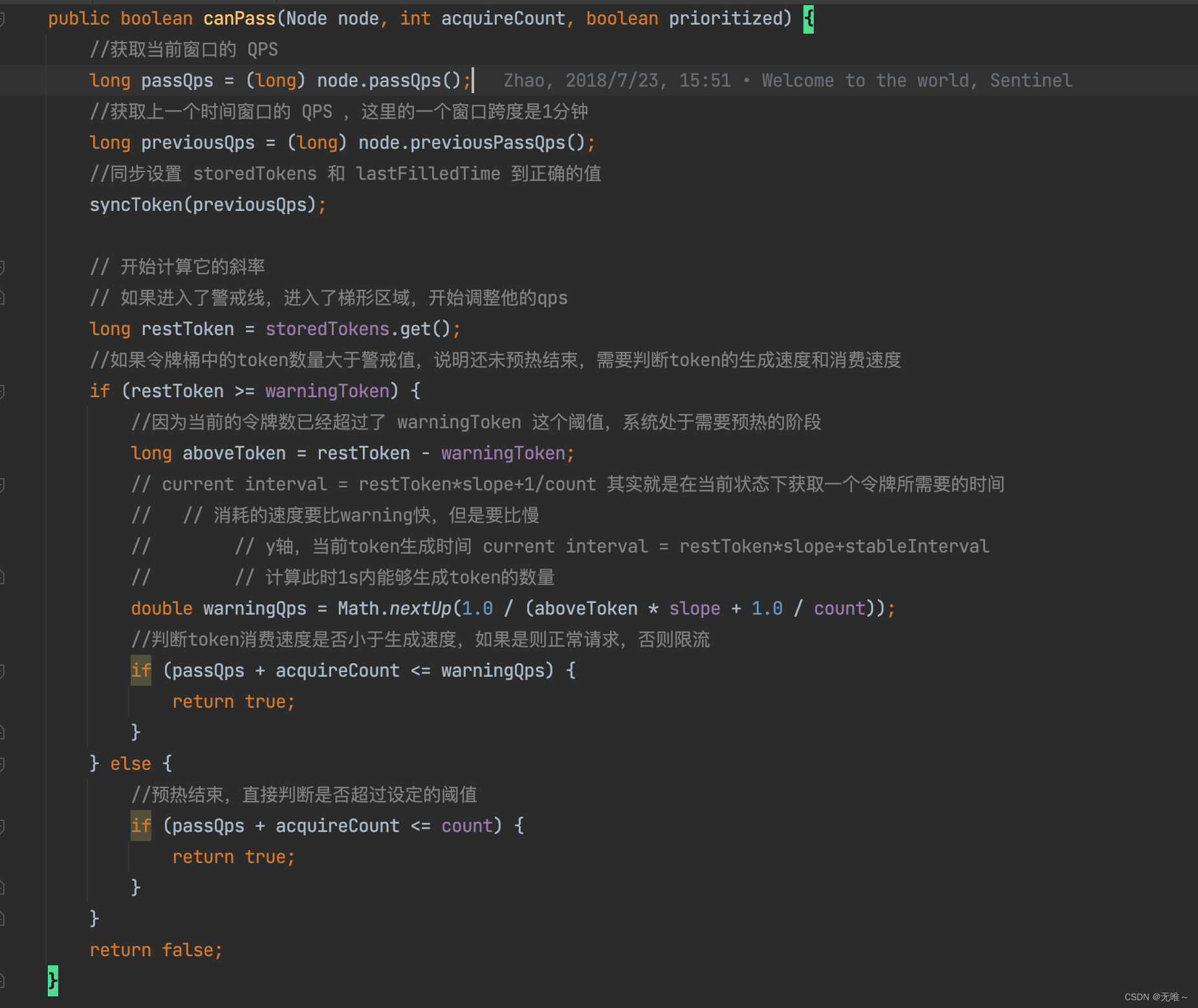
WarmUpController是如何进行限流的,我们接下来看canPass()方法:
- 先获取当前节点已通过的
QPS。- 获取当前滑动窗口的前一个窗口收集的已通过
QPS。- 调用
syncToken更新storedTokens与lastFilledTime的值,即按照令牌发放速率发送指定令牌,这里为什么storedTokens剩余许可数越大,限制其通过的速率竟然会越慢,因为一开始就会将storedTokens的值设置为maxToken,即开始就会超过warningToken,从而一开始进入到预热阶段,此时的速率有一个爬坡的过程,类似于数学中的斜率,达到其他启动预热的效果。- 如果当前存储的许可大于
warningToken的处理逻辑,主要是在预热阶段允许通过的速率会比限流规则设定的速率要低,判断是否通过的依据就是当前通过的TPS与申请的许可数是否小于当前的速率(这个值加入斜率,即在预热期间,速率是慢慢达到设定速率的。- 当前存储的许可小于
warningToken,则按照规则设定的速率进行判定。
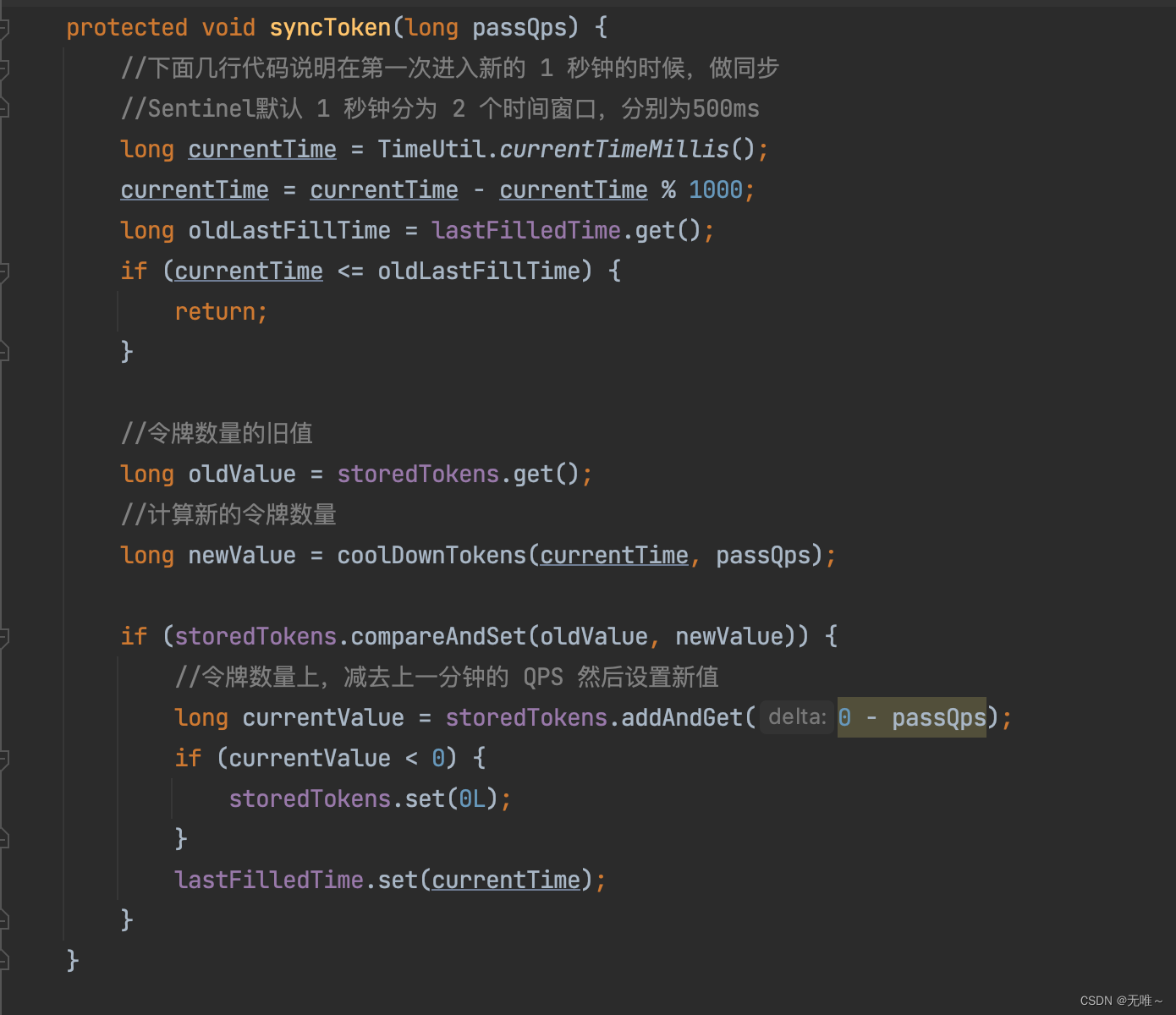
- 这个是计算出当前时间秒的最开始时间。例如当前是
2020-04-06 08:29:01:056,该方法返回的时间为2020-04-06 08:29:01:000。- 如果当前时间小于等于上次发放许可的时间,则跳过,无法发放令牌,即每秒发放一次令牌。
- 具体方法令牌的逻辑,稍后详细介绍。
- 更新剩余令牌,即生成的许可后要减去上一秒通过的令牌。
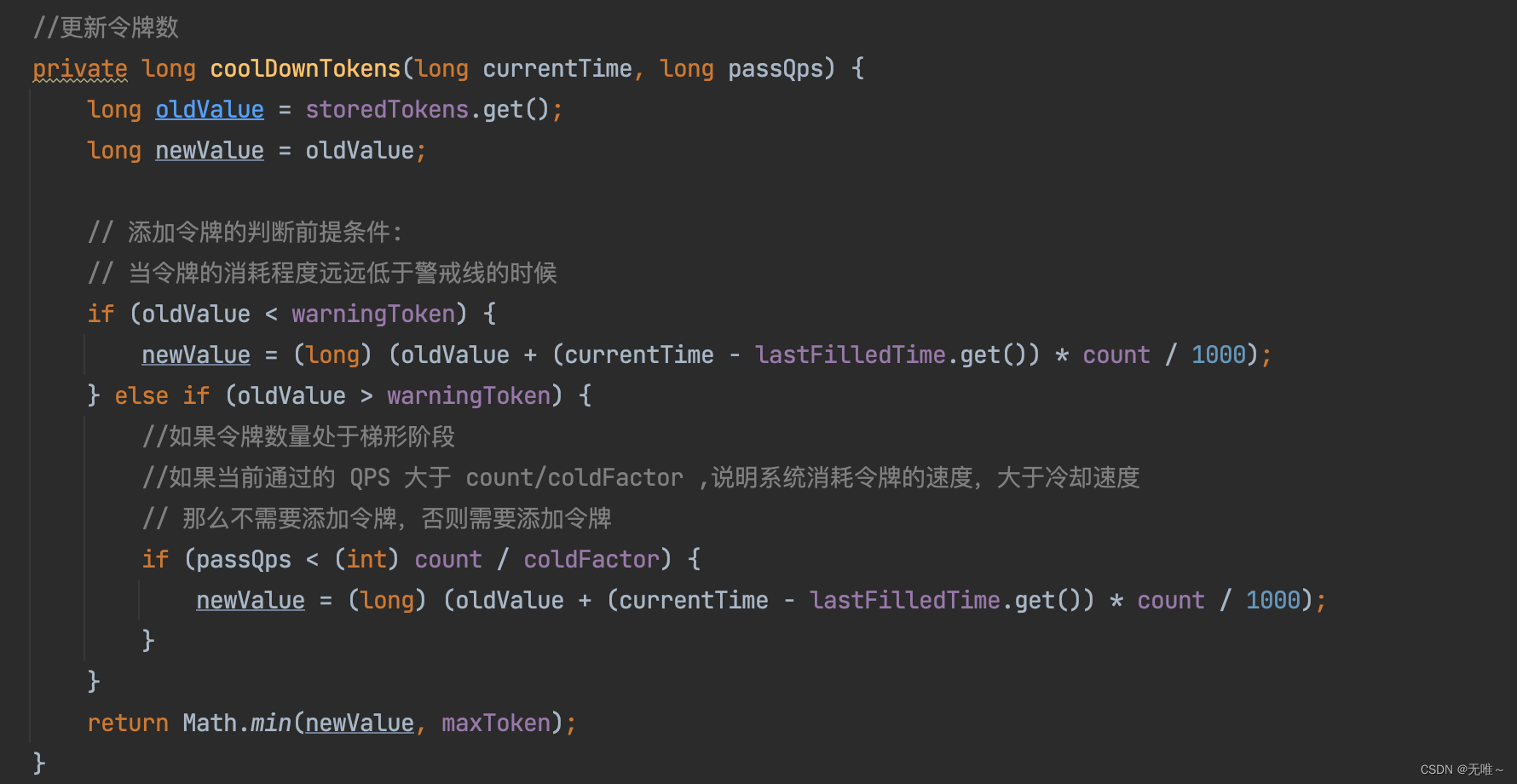
- 如果当前剩余的
token小于警戒线,可以按照正常速率发放许可。- 如果当前剩余的
token大于警戒线但前一秒的QPS小于 (count与 冷却因子的比),也发放许可- 第一次运行,由于
lastFilledTime等于0,这里将返回的是maxToken,故这里一开始的许可就会超过warningToken,启动预热机制,进行速率限制。
7.1.12.4 WarmUpRateLimiterController#canPass
这个类继承自
WarmUpController,它实现的流控效果是排队等待,他本质上就是RateLimiterController+WarmUpController的结合体,在RateLimiter的代码中加入了预热的功能,在RateLimiter中,单个请求的costTime是固定的,就是1/count,比如设置100 qps,那么costTime就是100ms。但是这边,加入了WarmUp的内容,就是说,通过令牌数量,来判断当前系统的QPS应该是多少,如果当前令牌数超过warningTokens,那么系统的QPS容量已经低于我们预设的QPS,相应的,costTime就会延长。
7.2FlowSlot#exit
啥也没做就传递给下一个了

八、DegradeSlot
7.1熔断器原理
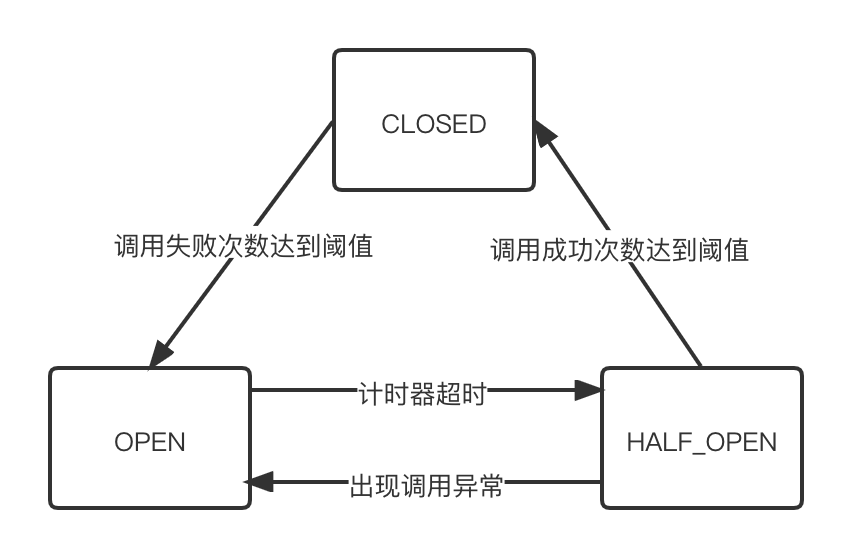
7.1.1 熔断器状态
- 断路器初始状态为
CLOSED,此时服务可用正常调用; - 当调用失败的次数达到阈值时,熔断状态从
CLOSED切换到OPEN状态。一般在实现时,如果调用成功一次,就会重置调用失败次数; - 当断路器处于
OPEN状态时,我们会启动一个超时计时器,当计时器超时后,状态切换到HALF_OPEN半打开状态。你也可以通过设置一个定时器,定期地探测服务是否恢复; - 在断路器处于
HALF_OPEN状态时,请求可以达到后端服务,如果累计一定的成功次数后,状态切换到CLOSED;如果仍然出现调用失败的情况,则重新切换到CLOSED状态。
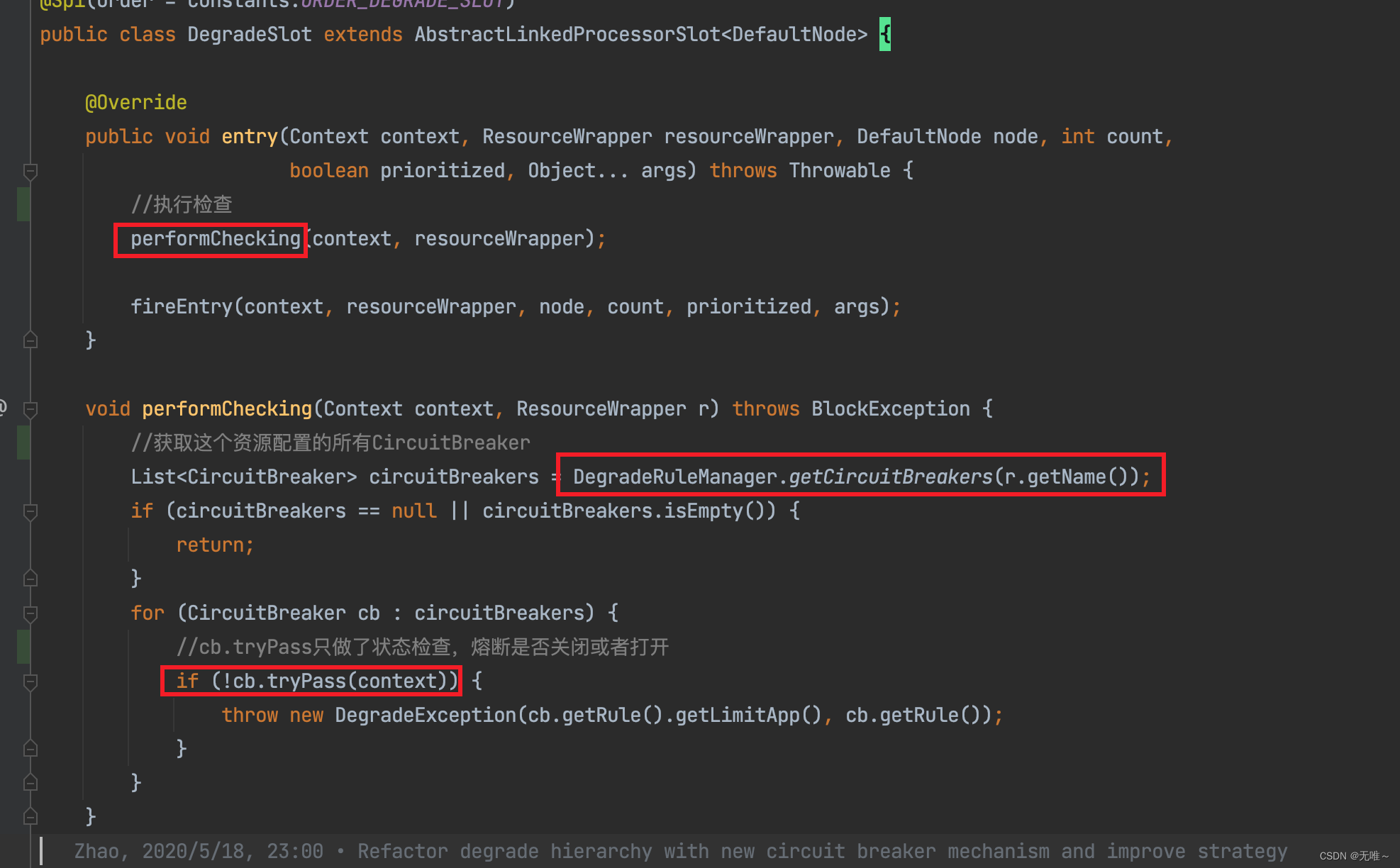
7.2 DegradeSlot#entry
- 先获取这个资源配置的所有断路器规则
- 遍历断路器,判断熔断会否开启,如果开启则会抛出熔断异常
7.2.1 CircuitBreaker#tryPass
- 这里判断熔断器状态是否是
close状态的,如果是则放行- 判断熔断器是否是开启状态的,如果是开启状态则会判断上一个请求距离现在是否已经过了重试时间间隔,如果是则会尝试把状态变成半启动状态,这里使用
CAS变更状态,如果变更成功,则当前请求会放行。
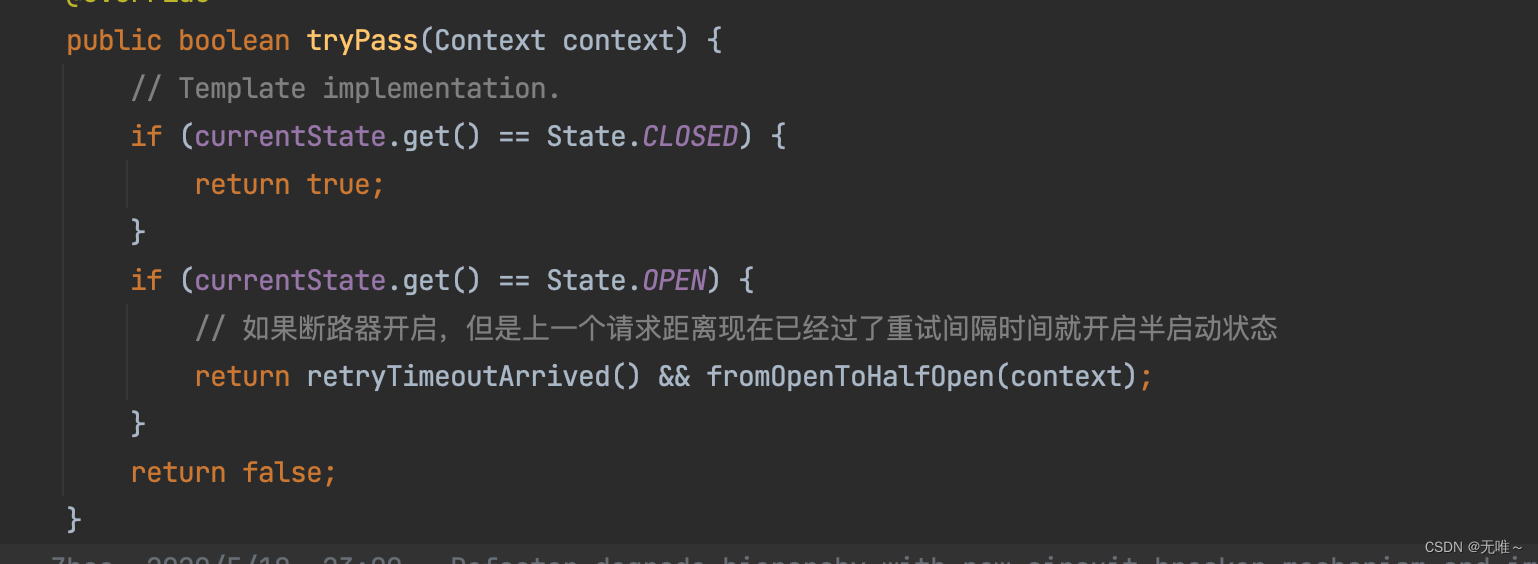
7.2.2 AbstractCircuitBreaker#retryTimeoutArrived
判断上一次请求重试的时间距离当前时间有没有过重试间隔

7.2.3 AbstractCircuitBreaker#fromOpenToHalfOpen
- 这里首先把熔断器状态成
OPEN变更HALF_OPEN- 如果请求发生异常,则会把状态再从
HALF_OPEN变成OPEN状态- 注:这里我们只看到了断路器状态从
HALF_OPEN变成OPEN,和从OPEN变成HALF_OPEN,那么从CLOSE状态变成OPEN状态和从HALF_OEPN状态变成CLOSE状态我们还没看到,我们后续看下DegradeSlot#exit方法
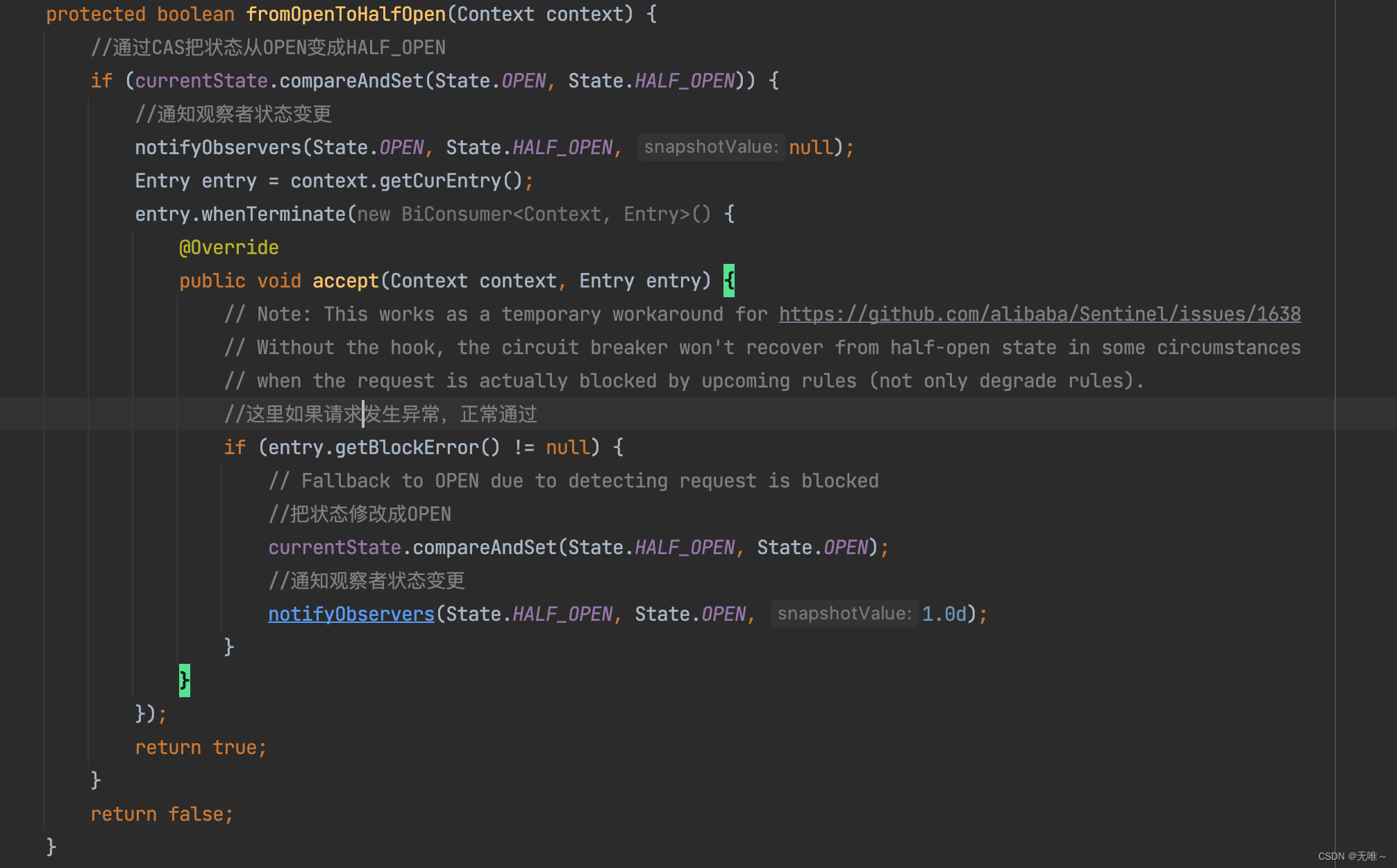
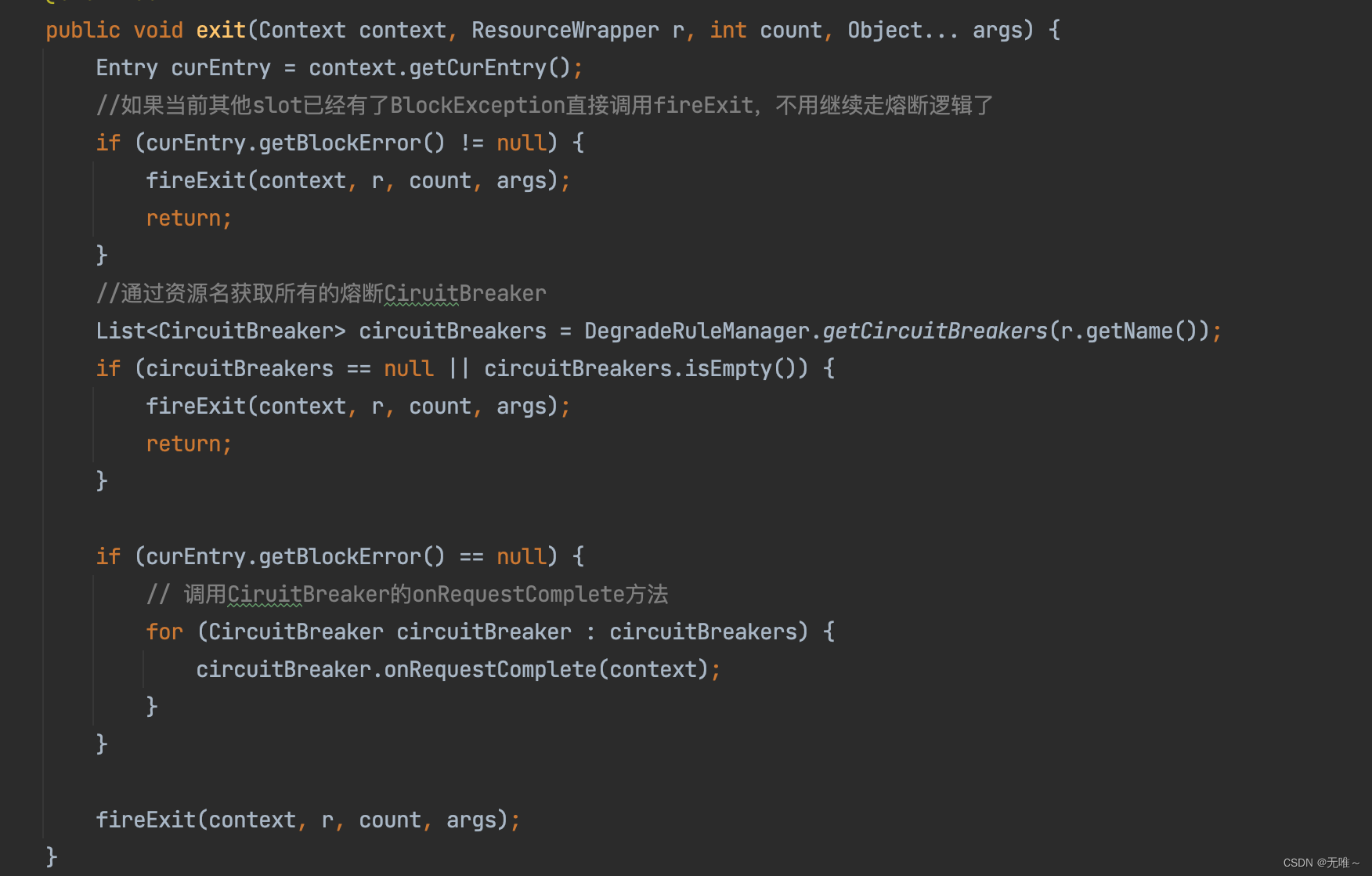
7.3 DegradeSlot#exit
- 如果已经被限流了,则不需要走熔断的逻辑了
- 根据资源名获取所有熔断器
- 调用熔断器的
onRequestComplete方法。
7.3 CircuitBreaker#onRequestComplete
我们发现下面有2个实现,分别对应上面我们选择的按照[异常比例,异常数],和响应时间。

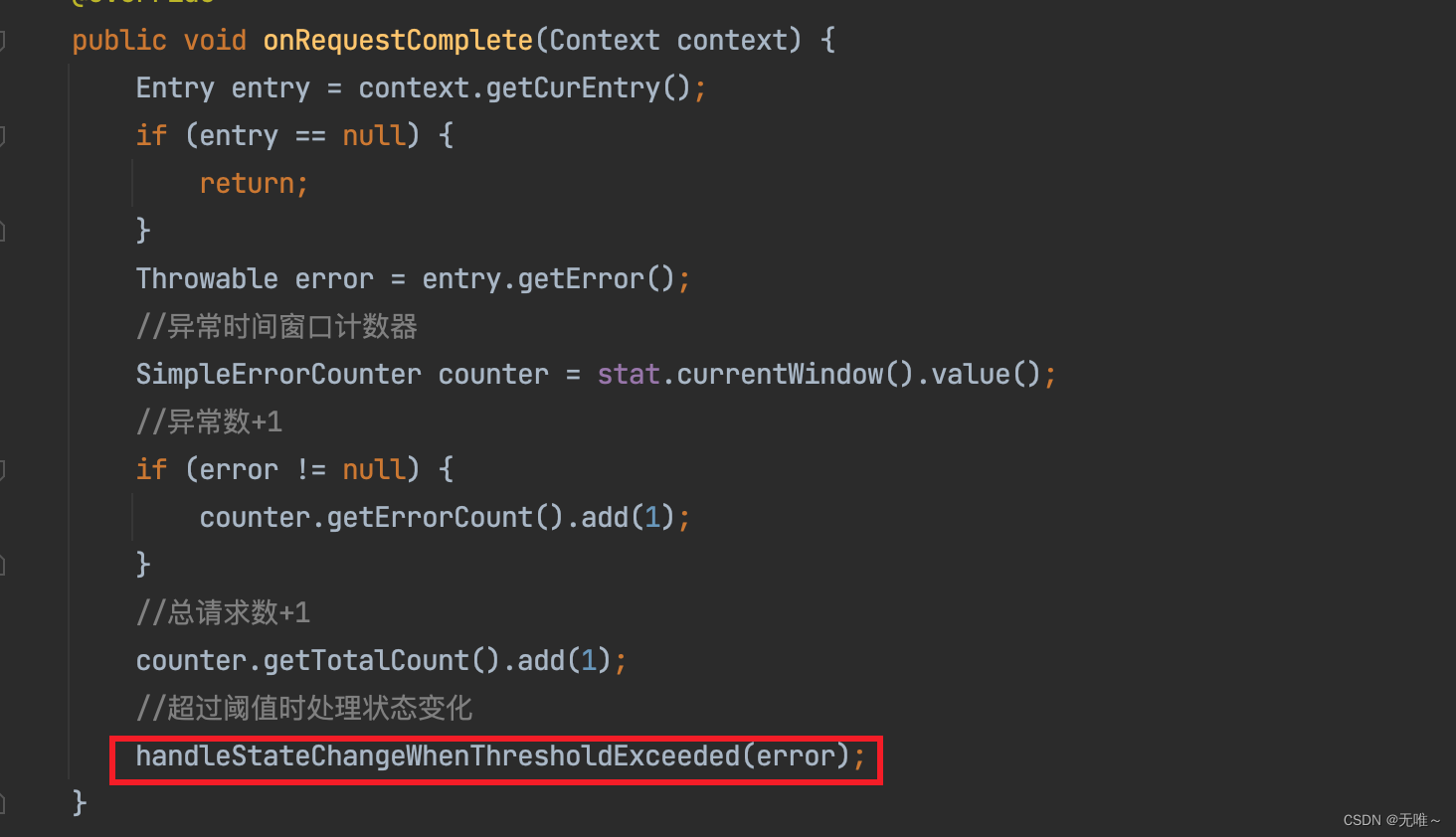
7.4 ExceptionCircuitBreaker#onRequestComplete
- 这里首先获取了当前窗口内的异常数
- 判断如果发生了异常则对异常数量
+1,总的请求数量也+1- 调用
handleStateChangeWhenThresholdExceeded方法判断如果超过阈值了则进行断路器状态的处理。
7.4.1 ExceptionCircuitBreaker#onRequestComplete
- 如果断路器开启直接返回
- 如果断路器处于半打开状态,则判断本次请求是否发生异常,这个请求就是上次发送的探活的请求,如果没有发生异常,就关闭掉断路器,如果发生了异常,就开启断路器
- 获取所有窗口内的请求数和异常数,根据配置的策略是异常比例还是异常数来判断是否需要开启断路器

7.5 ResponseTimeCircuitBreaker#onRequestComplete
- 首先获取到当前窗口的计数
- 计算本次请求的
rt,如果大于最大允许rt,则对当前窗口内的慢请求进行+1,窗口内的总请求数也+1- 判断是否超过阈值,超过阈值进行断路器的状态变更。
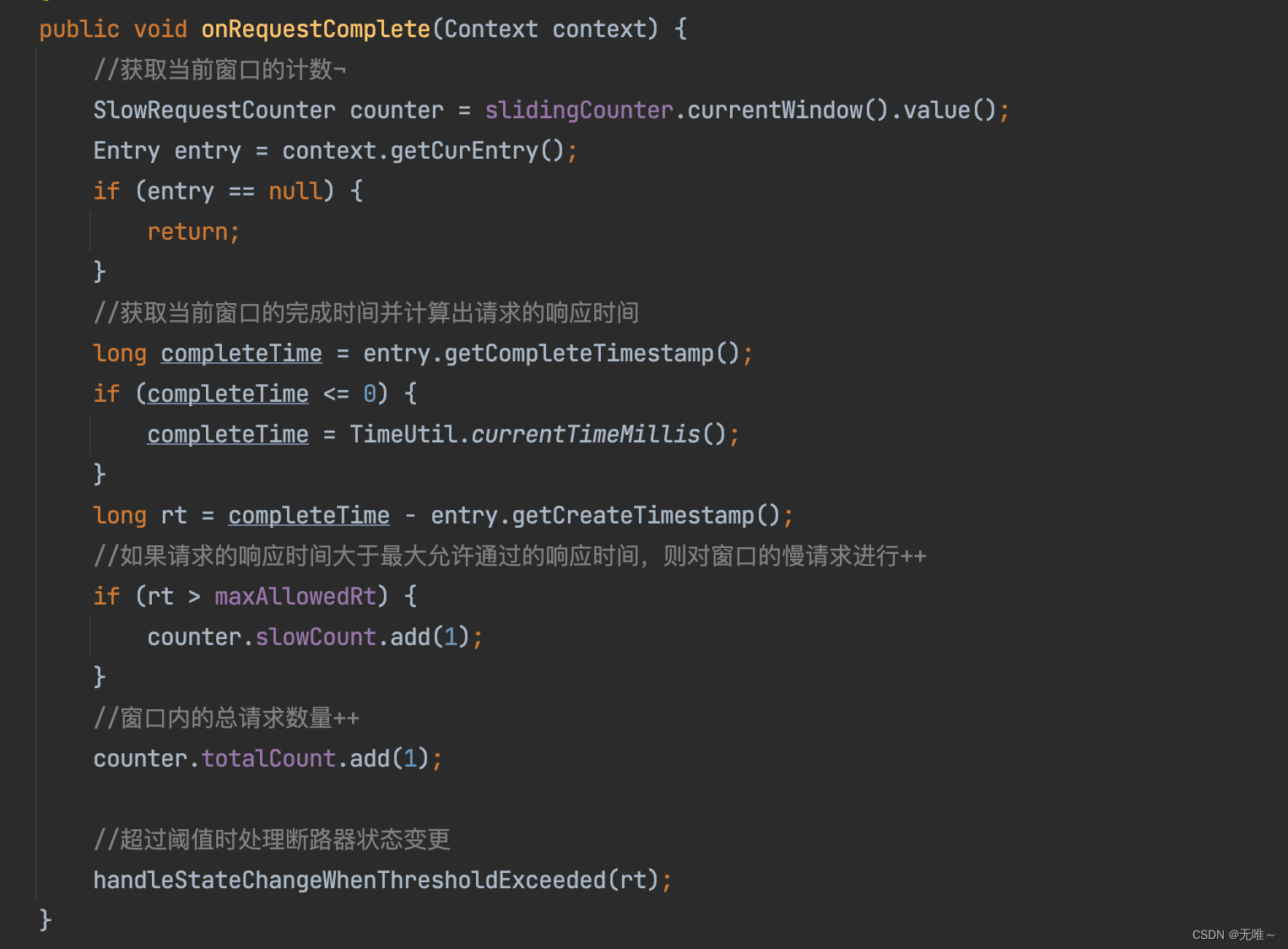
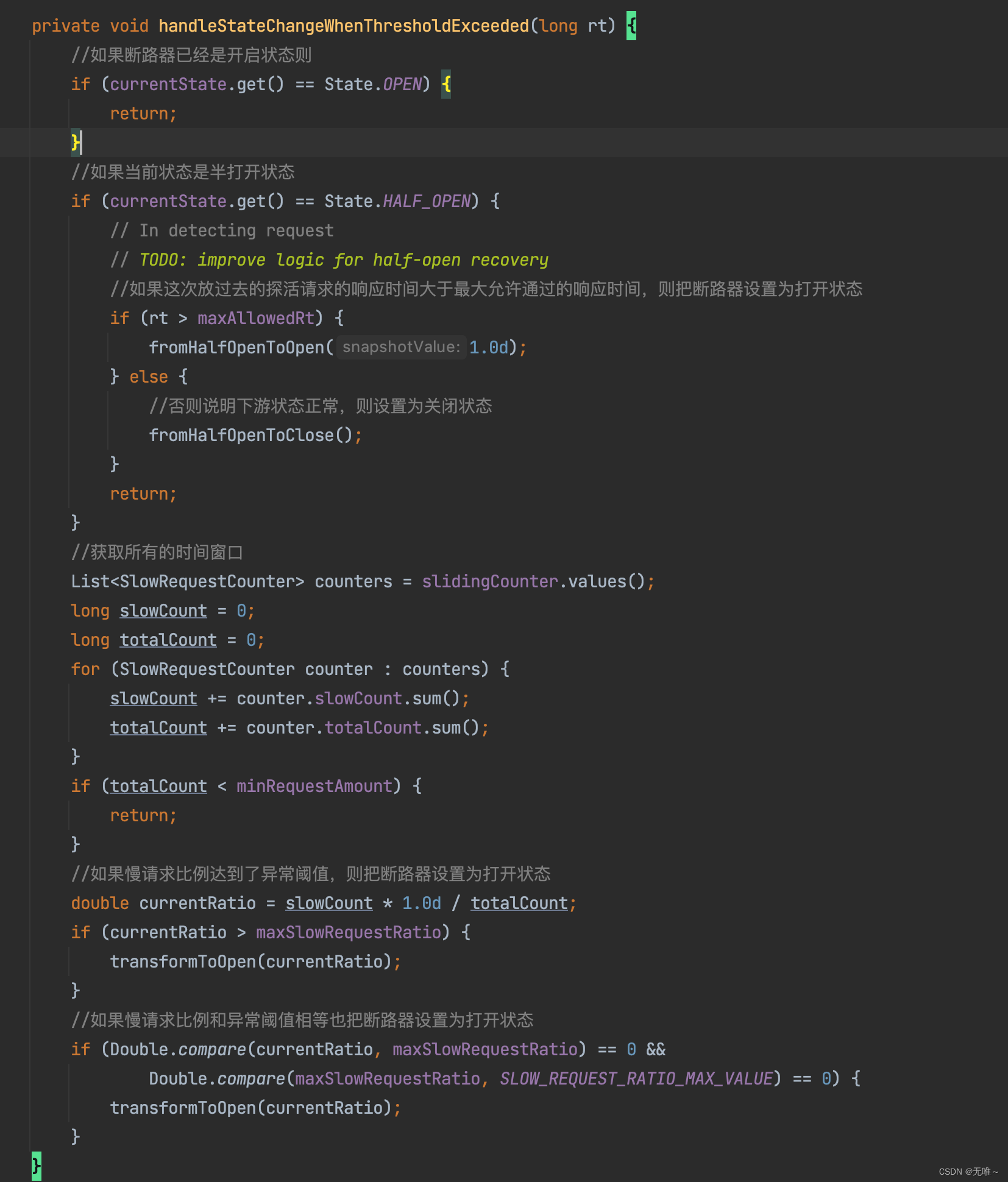
7.5 ResponseTimeCircuitBreaker#handleStateChangeWhenThresholdExceeded
- 判断如果断路器已经是打开状态则直接返回
- 如果断路器状态是半打开状态,判断之前放过去的请求的响应时间有没有超过最大允许通过的响应时间,如果超过,则把断路器设置为打开状态,如果没超过,则把断路器设置为关闭状态。
- 获取所有的时间窗口,计算出来请求总数和慢请求总数,判断满请求比例是否大于等于设置的异常阈值,如果达到异常阈值,则把断路器状态设置为打开状态
九、滑动时间窗口
我们在
StatisticSlot中会做请求各种纬度的统计,并且后续的限流即熔断也会从node中获取统计信息,Sentinel节点的统计是基于滑动窗口实现的实时指标数据收集统计,底层采用高性能的滑动窗口数据结构LeapArray来统计实时的秒级指标数据,可以很好地支撑写多于读的高并发场景。

9.1 核心数据结构
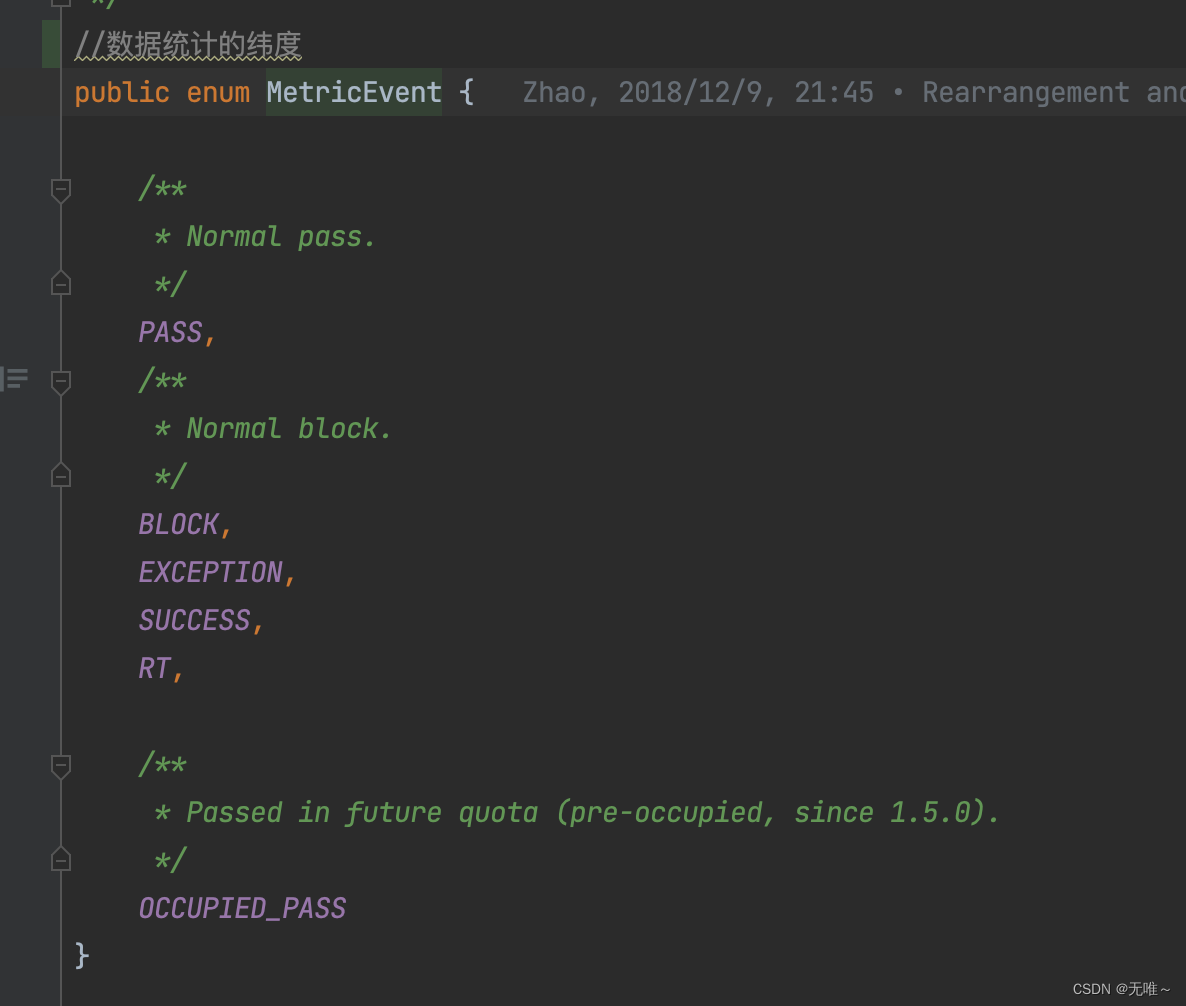
ArrayMetric:滑动窗口核心实现类。LeapArray:滑动窗口顶层数据结构,包含一个一个的窗口数据。WindowWrap:每一个滑动窗口的包装类,其内部的数据结构用 MetricBucket 表示。MetricBucket:指标桶,例如通过数量、阻塞数量、异常数量、成功数量、响应时间,已通过未来配额(抢占下一个滑动窗口的数量)。
-MetricEvent:指标类型,例如通过数量、阻塞数量、异常数量、成功数量、响应时间等。
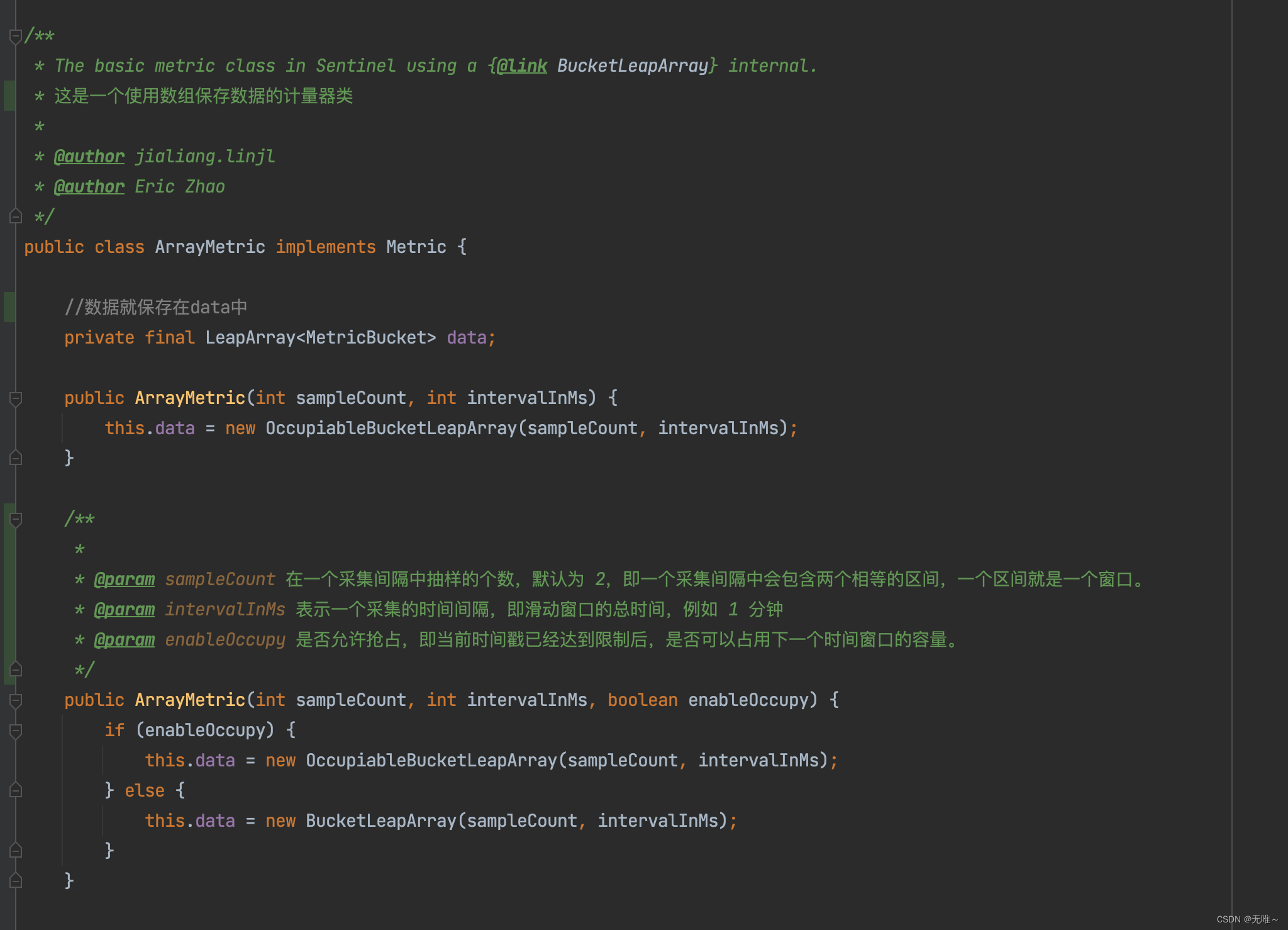
9.1.1 ArrayMetric
- 滑动窗口的入口类,定义了一个滑动内成功的数量、异常数量、阻塞数量、
TPS、响应时间等数据,其内部数据的存储使用LeapArray来存储
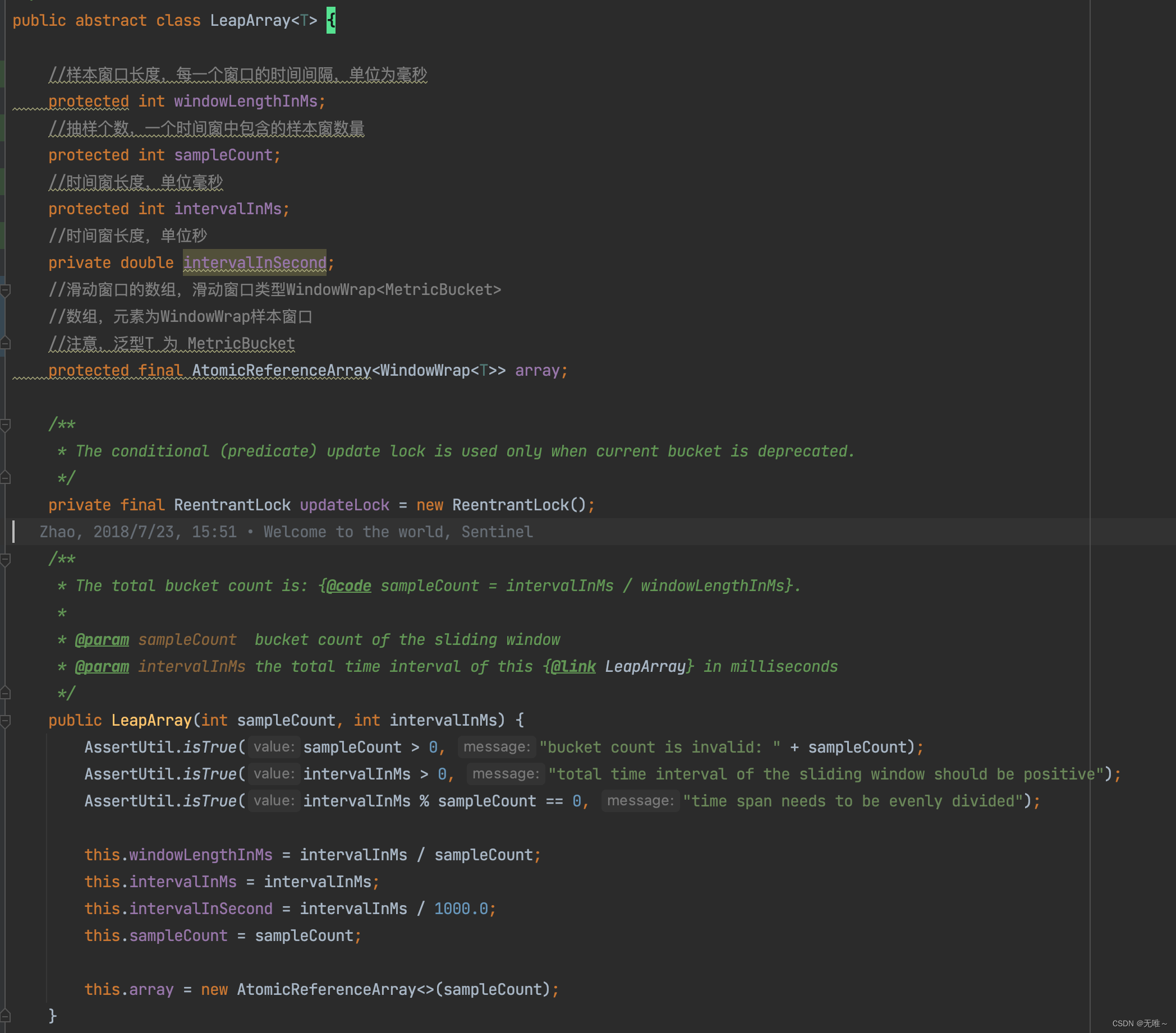
9.1.2 LeapArray
LeapArray是具体实现滑动窗口,其成员array就是具体承载的滑动窗口的数据,还有一些其相关的属性,采样率,窗口大小等。
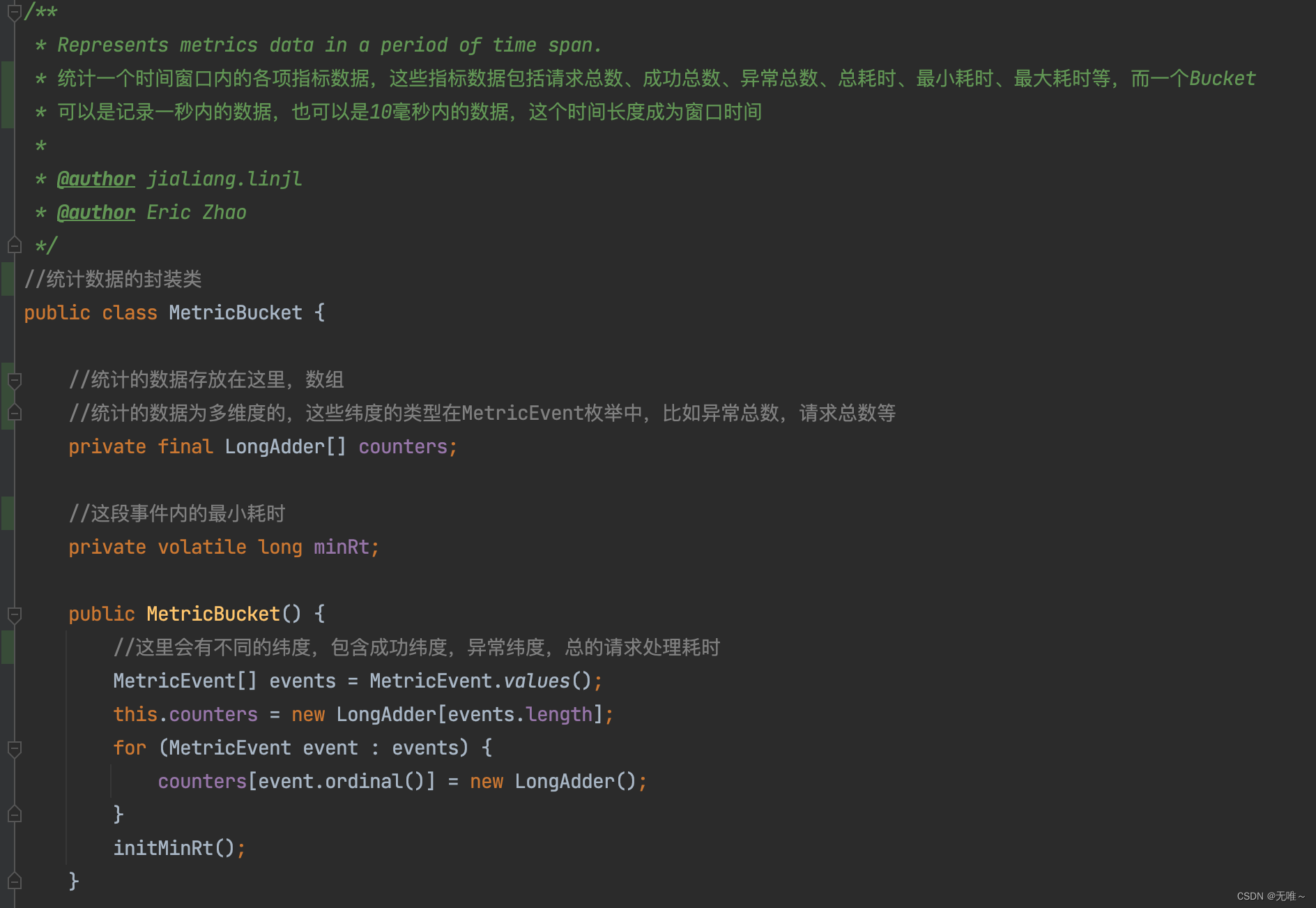
9.1.3 MetricBucket
- 统计一个窗口时间内的各项指标,如
MetricEvent所列举的包括请求总数、请求总数、异常总数、总耗时、最小耗时、最大耗时等多个指标,其底层使用了LongAdder数组,数组的每一个元素都代表一种纬度,LongAdder是实现高并发场景下数据统计的利器。
9.1.4 WindowWrap
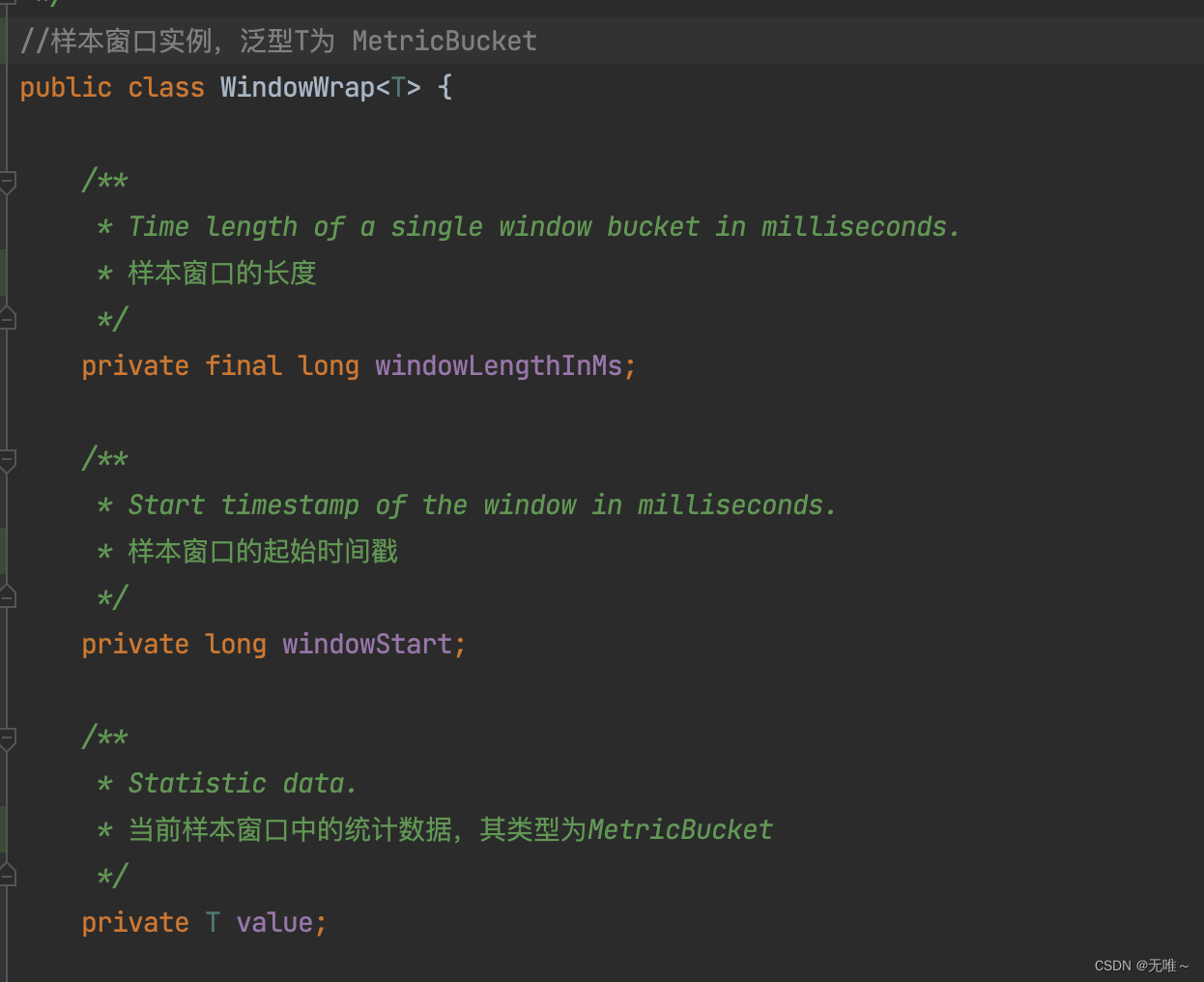
因为
Bucket自身不保存时间窗口信息,所以Sentinel给Bucket加了一个包装类WindowWrap。Bucket用于统计各项指标数据,WindowWrap用于记录Bucket的时间窗口信息(窗口的开始时间、窗口的大小),WindowWrap数组就是一个滑动窗口。
9.2 滑动窗口具体实现
这里我们在
StatisticSlot#entry代码中看具体的一个node是如何使用滑动窗口统计的,我们看一下node#addPassRequest方法
9.2.1 Default#addPassRequest
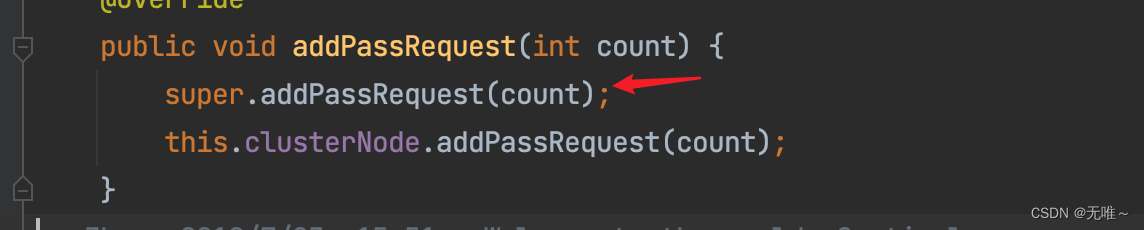
9.2.2 StatisticNode#addPassRequest
这里
rollingCounterInSecond和rollingCounterInMinute是Metric,它是统计每秒和每分钟的各种指标。
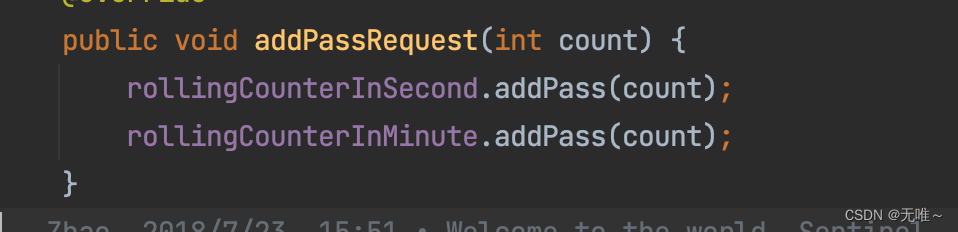
9.2.3 ArrayMetric#addPass
- 这里首先定位到了当前窗口
- 然后对当前窗口的请求通过数进行++

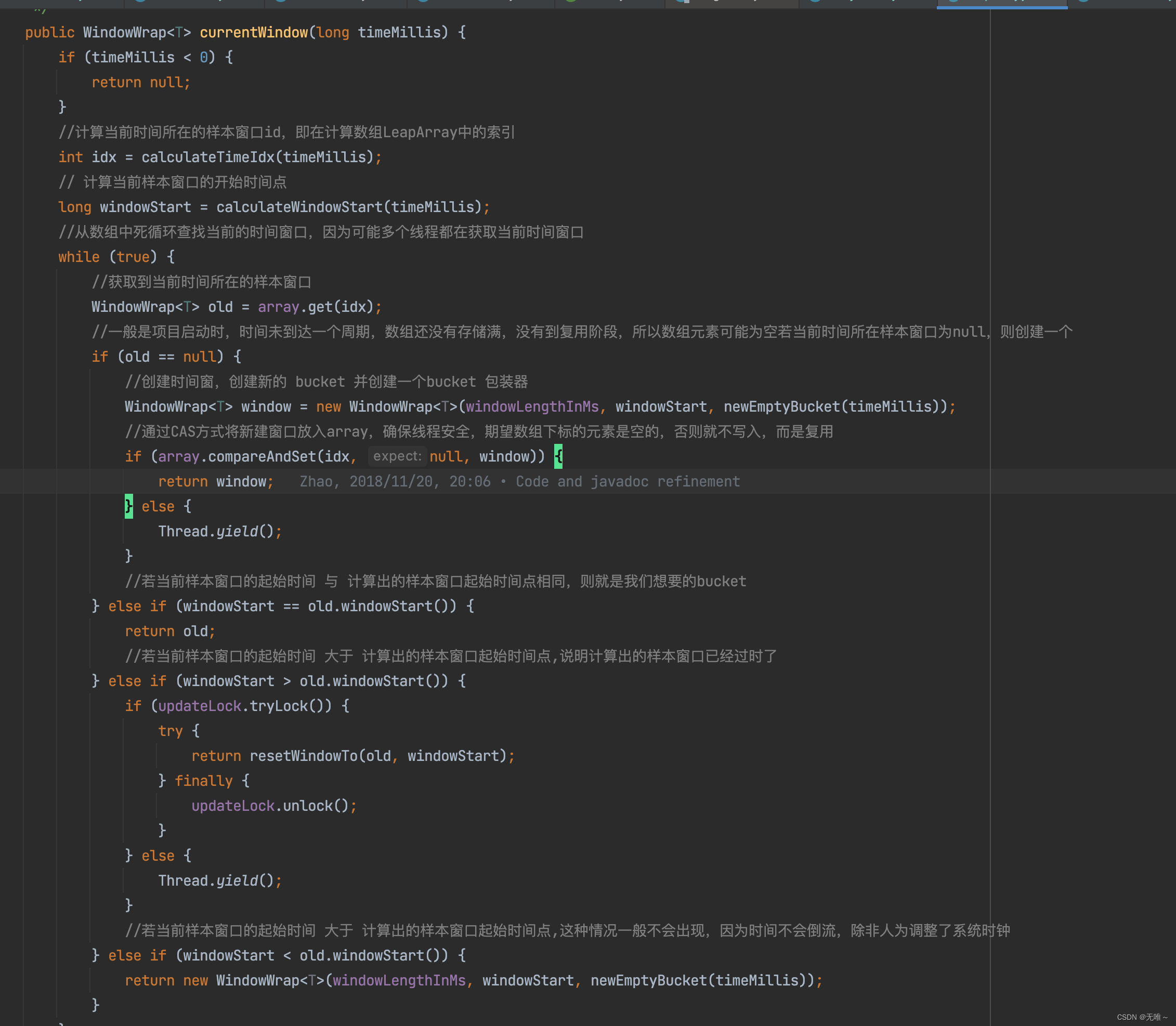
9.2.4 LeapArray#currentWindow

- 这里首先根据当前时间戳计算出对应窗口在窗口数组中的索引位置,以及窗口的起始时间
- 从窗口数组中获取这个位置的窗口,判断是不是等于
null,如果等于null的话,说明之前没有创建过这个窗口,就新创建一个窗口并放到窗口数组中- 如果窗口不是
null,则比较这个窗口的起始时间和我们计算出来的窗口起始时间是否一样,如果一样说明这个bucket就是我们想要的bucket,直接返回- 如果我们要获取的窗口时间比这个数组中那个位置的窗口时间要小的话,说明我们要的窗口已经过期了,这种一般产生时间回拨会导致,异常情况,这里直接
new一个新的返回- 如果我们要获取的窗口时间比这个数组中那个位置的窗口时间要大的话,说明数组中的那个窗口已经比较老的,这时候枷锁重置一下窗口,就是把统计值置为
0,然后重置一下窗口起始时间。
9.2.5 LeapArray#calculateTimeIdx
计算出来当前时间对应的窗口在数组中的哪个位置。
- 首先拿当前的时间戳/窗口长度,算出来是多少个窗口数量
- 然后拿计算出来的窗口数量%数组长度得到对应在数组中的下标

9.2.6 LeapArray#calculateWindowStart
计算时间戳对应窗口的起始时间,
- 这里
timeMillis % windowLengthInMs,计算出来余数,就是在对应窗口的哪个位置- 这里
timeMillis - timeMillis % windowLengthInMs,就计算出来对应那个窗口的起始位置