字节码新手很容易被厚厚的 JVM 书籍劝退,即使我看过相关书籍,工作真正用到时也全忘了,还得现学。
等我有了一定的字节码阅读经验,才发现字节码其实非常简单,只需要三步就能快速学会:
- 先了解 JVM 的基本结构,只需要了解字节码相关的结构即可
- 然后将指令分成几类,学习每一类是用来操作 Jvm 哪个组件的
- 最后学习字节码的常见模式,比如 new 一般会被翻译成哪几指令,等等
之后按需查询 JVM指令官方文档,就可以出师了。
相比官方文档,本文更加适合顺序阅读,读完后再按需查阅官方文档。
JVM 的基本结构
只需要了解三个和字节码相关的结构。
栈帧
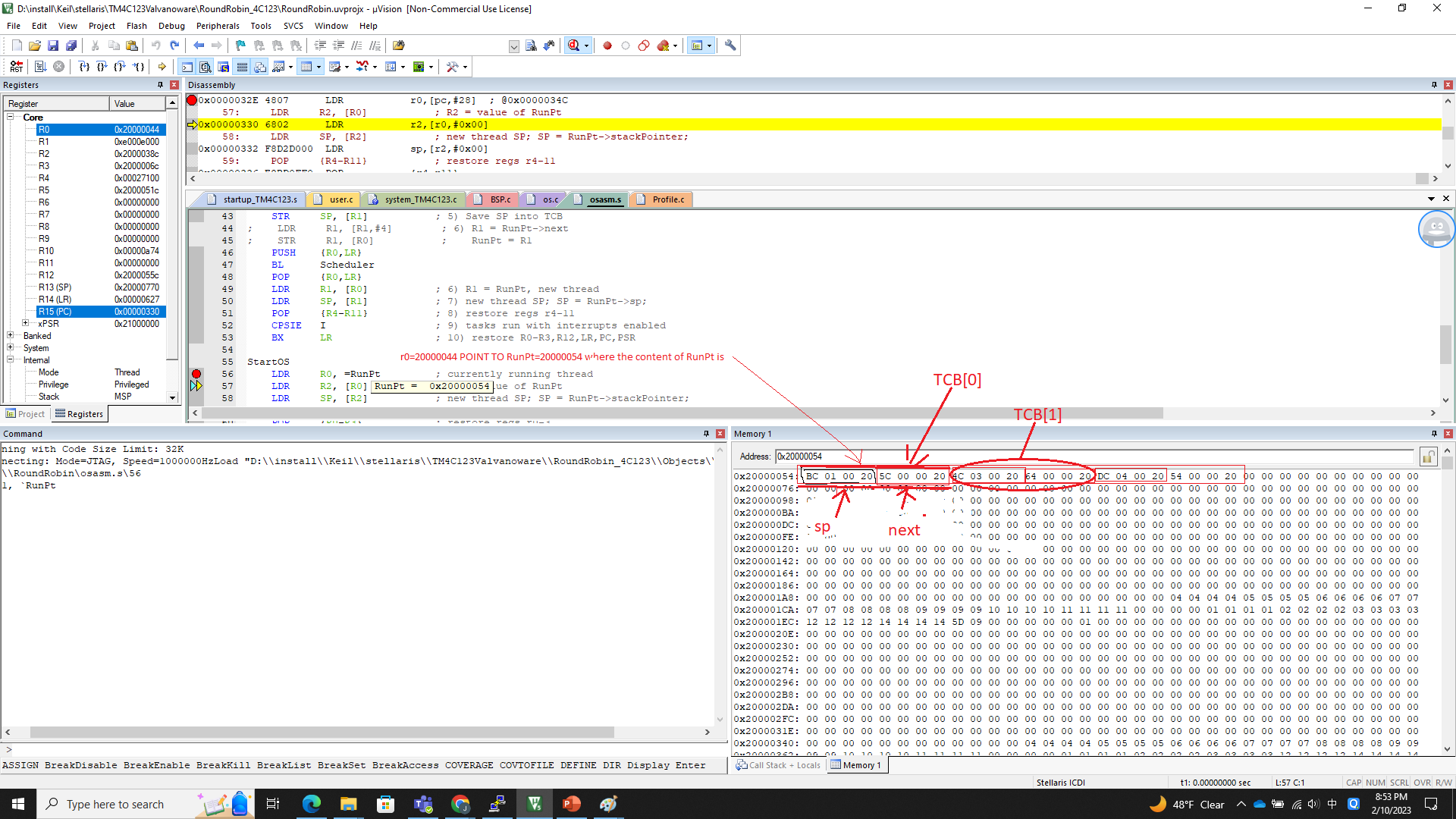
JVM 每调用一个方法就会压入一个新的栈帧到栈上,比如下面的例子:
public static void main() {
a();
}
public static void a() {
b();
}
public static void b() {
//...此处的栈如图所示...
}
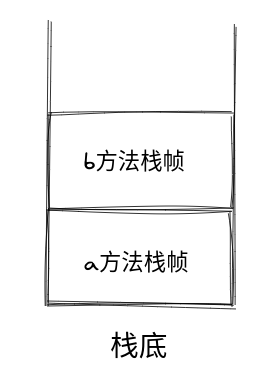
虽然例子中举的是静态方法,但是对象方法也是一样。
重点:栈帧代表一个 Java 方法,里面装的是 Java 方法的运行时数据
操作数栈
每个栈帧中会有一个操作数栈,这其实就是一个用来执行各种计算的工作区,比如加法的执行过程:
- 将 1 压栈
- 将 2 压栈
- 栈顶两个元素相加,将结果 3 压栈
局部变量表
栈帧中除了用于运算的操作数栈,还有用来临时存储变量的 “局部变量表”,比如下面的变量 a:
public static void main() {
// a 会被存入 “局部变量表”
int a = 10;
//...此处省略1w行代码...
// 将 a 从局部变量表中取出
int b = a + 1;
}
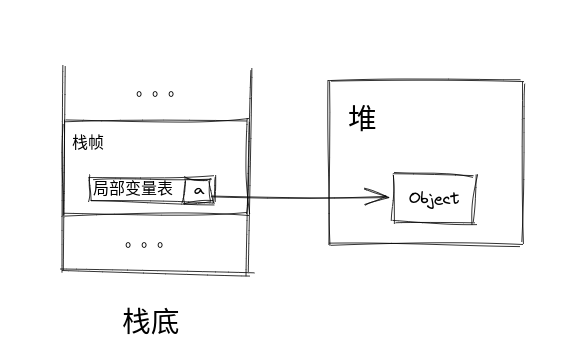
堆
操作数栈是栈帧中的存储,所以其生命周期仅限于一个 Java 方法。
而堆就是能够跨越 Java 方法的存储。一般用 new 新建的对象都是在堆里,然后在栈帧中只保留一个引用指针。
比如 Object a = new Object();
指令分类学习
我们可以根据操作的 JVM 组件,将指令分类。每一类我们只要认识常见的几个,剩下的都非常相似。
指令的结构
JVM 指令的结构和 linux 命令差不多:指令 参数1 参数2 ...;其中每个部分占一个字节,所以叫做 “字节码”。
栈操作
- dup: 复制栈顶元素
- add: 将栈顶两个元素出栈相加,然后将结果入栈
JVM 并不存在
add指令,而是各种专门数据类型的相加指令,比如iadd是整型相加,dadd是浮点类型相加等等,其他指令也是类似的规律
- ldc/bipush/const: 将常量压栈
ldc index: 将常量池中第 index 个元素入栈bipush byte:此时常量不在常量池中,而是作为一个 byte 被编码在了指令中- const 则是一系列指令,比如
iconst_0表示将整型0入栈,iconst_1表示将整型1入栈,dconst_0表示将浮点型 0 入栈等等,以此类推。可见 const 相比前两个是更加压缩的表示,一个iconst_1同时表达了指令(iconst)和常量值(1),这么做的好处是可以节约一个字节。
从
add和const指令中可以看出 JVM 指令会用前缀表示指令操作的数据类型,比如i表示整型,d表示浮点型等等
局部变量表操作
局部变量表是一个数组,通过下标访问。
store i: 将栈顶的值存储到局部变量表的 i 位置load i:将局部变量表 i 位置的值加载到栈顶
store 和 load 也都是一系列指令,比如
istore i,iload i,dstore i,dload i等等,甚至
虽然我们看到代码里的变量都是有具体的名字的,比如 int a = 1,b = 2 中的变量 a, b。其实在运行时,这些变量都会按照方法中出现的顺序被翻译成局部变量表的一个下标,int a = 1,b = 2 对应的字节码就是:
// 常量 1 入栈
0: iconst_1
// 将常量 1 存储到局部变量表的 1 位置(其实就是变量 a)
1: istore_1
// 常量 2 入栈
2: iconst_2
// 将常量 2 存储到局部变量表的 2 位置(其实就变量 b)
3: istore_2
如图所示:
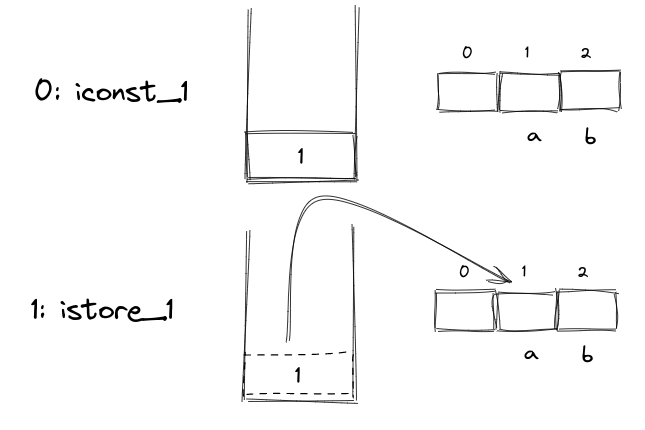
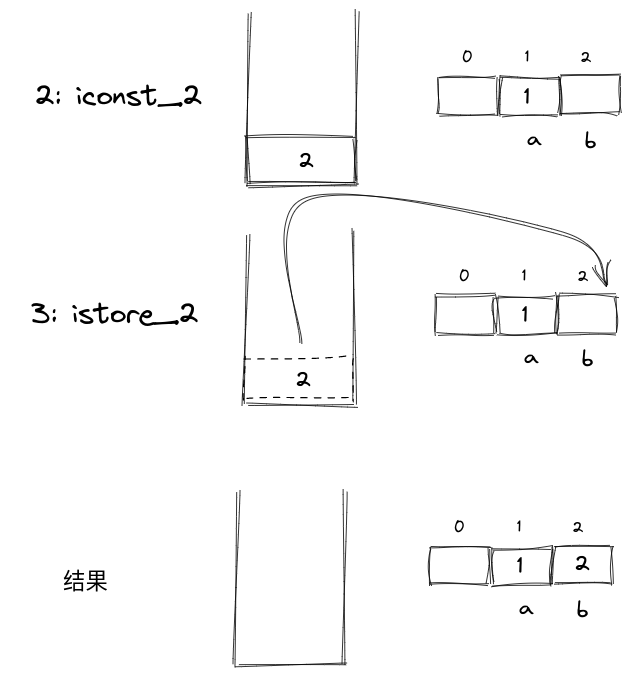
局部变量表的 0 号位置一般是用来保存
this引用的,所以图中没有使用。
堆操作
堆主要还是依靠保存在栈中的引用来操作的。
通过 new 指令在堆中新建一个对象,然后将引用保存在栈顶。
常见模式
静态方法调用
- 将参数入栈
- 然后使用
invokestatic指令调用静态方法
如下代码:
static void a() {
b(1,2,3);
}
static void b(int a, int b, int c) {
//...
}
此时 a 方法的字节码就是:
// 将参数入栈
0: iconst 1
1: iconst_2
2: iconst3
// 调用静态方法
3: invokestatic b:(III)V
成员方法调用
- 将调用对象入栈
- 将参数入栈
- 调用成员方法
如下代码:
class Test {
void a() {
b(1,2,3);
}
void b(int a, int b, int c) {
}
}
此时 a 方法的字节码:
// 将调用对象入栈
// 回忆前文, this 引用存储在局部变量表的 0 号位置, 所以可以从局部变量表的 0 号位置加载到
0: aload_0
// 调用参数入栈
1: iconst_1
2: iconst_2
3: iconst_3
// 调用成员方法
4: invokevirtual b:(III)V
成员方法的调用,本质上是将对象作为隐藏的第 0 个参数,比如当调用 object.a(1) 时,在 JVM 层面相当于 a(object, 1)。
另外,针对不同的情况,invoke 有一些 invokeXxx 方法:
invokeinterface:调用接口方法invokevirtual: 调用对象的成员方法,是最常见的invokespecial: 调用构造器等特殊方法。比如下文中的构造函数就是使用这个指令调用的
构造对象
总体步骤如下:
- 用
new指令新建一个空对象 - 用
dup复制栈顶 - 像 “方法调用” 中一样将构造函数的参数逐个入栈
invokespecial <init>调用对应的构造函数完成初始化
比如下面的代码:
Integer a = new Integer(10);
对应的指令就是:
// 步骤 1.
0: new java/lang/Integer
// 步骤 2.
3: dup
// 步骤 3.
4: bipush 10
// 步骤 4.
6: invokespecial java/lang/Integer."<init>":(I)V
前面编号代表的是指令位于第几个字节,从上面可以看出,除了 dup 以外,其他指令都需要占用多个字节
在编码阶段,对象看起来是构造好才返回的,但在字节码层面,其实对象新建和初始化是两个步骤,先新建一个空对象,然后才调用的初始化方法。
为什么需要一个 dup,因为构造方法在 JVM 层面其实就是一个普通的成员方法, invokespecial 需要将对象和参数一起从栈中弹出,而构造方法执行完后还需要在栈上保留一个对象,因此需要 dup 保留一个副本。
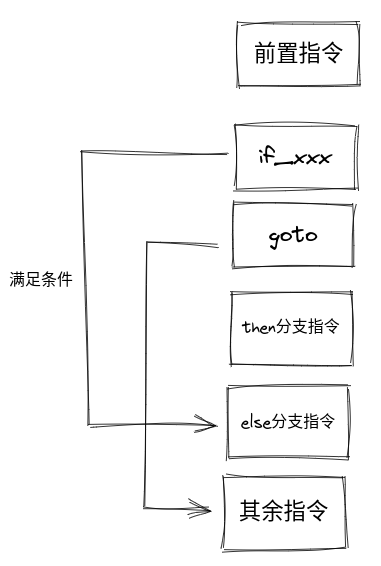
分支判断
分支判断主要使用 if_xxx index 系列指令,如果满足条件就跳转到 index 位置的指令执行。
如下代码:
public void b(int a, int b) {
int c;
if (a > b) {
c = 1;
} else {
c = 2;
}
return;
}
编译后的字节码是:
// 加载局部变量 a
0: iload_1
// 加载局部变量 b
1: iload_2
// 如果 a <= b, 则跳转到位置 10 执行(其实就是 else 分支的位置)
2: if_icmple 10
5: iconst_1
6: istore_3
// 跳转到位置 12 执行(其实就是跳过 else 分支的指令)
7: goto 12
10: iconst_2
11: istore_3
12: return
大体逻辑如图:
做字节码实验时的注意点
当我们编写好测试的 Java 代码 Test.java,可以用下面两条命令查看它的字节码:
javac Test.java
javap -c -v -l Test.class
需要注意的是,javac 中会做一些优化,导致字节码和源码对不上,比如下面的代码:
public static void main(String[] args) {
if (2 < 1) {
int a = 2;
} else {
int a = 1;
}
}
编译后字节码是:
0: iconst_1
1: istore_1
2: return
可以看出,字节码其实只编译了 int a = 1 这一行代码,没有编译 if ... else ... 逻辑。这是因为 2 < 1 肯定是 false,于是编译器就把这段逻辑优化掉了。
如何阅读字节码官方文档
这篇文章只是带大家入个门,重点还是要能在遇到不认识的字节码时自主查阅 Java字节码官方文档。
比如下面的 iadd 字节码
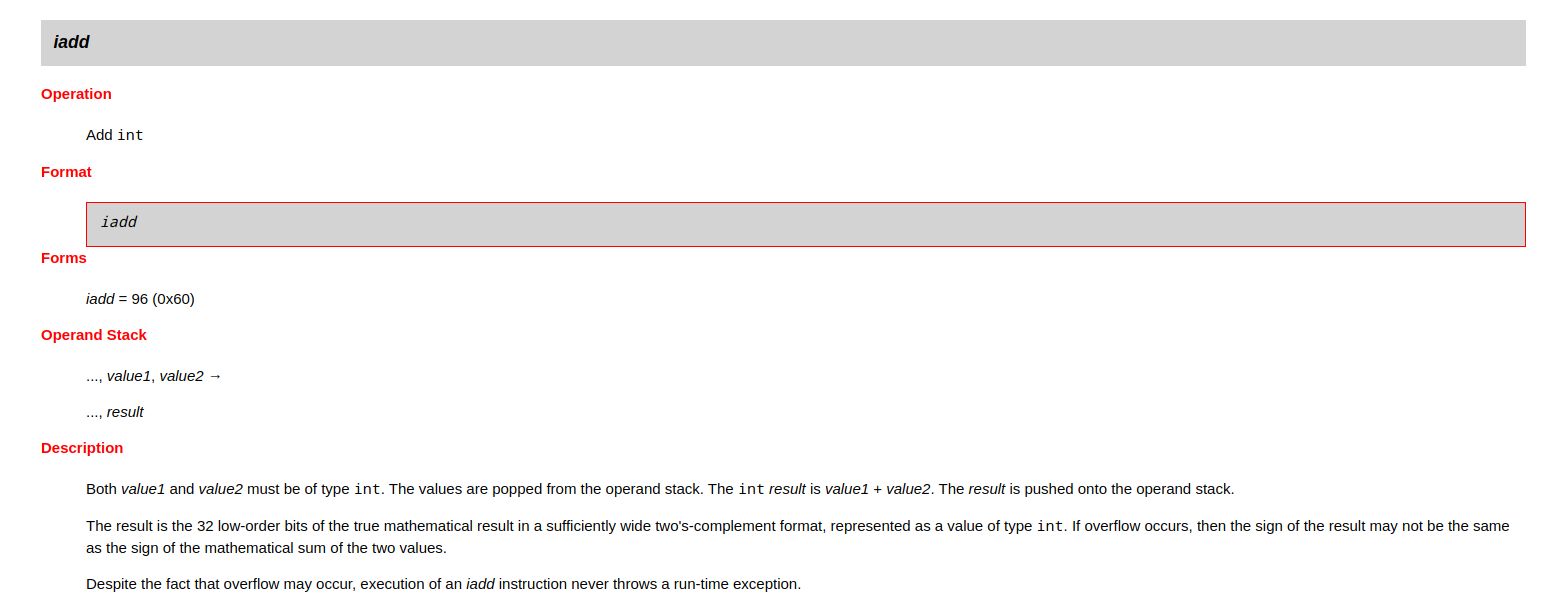
- Operation:可看出是做 int 型加法操作
- Operand Stack:表示指令执行会导致栈变化,
iadd会将栈顶两个元素出栈,然后将结果入栈
End
作者:元青
微信公众号 「技乐书香」