索引
索引是一个列表 —— 若干列集合和这些值的记录在数据表存储位置的物理地址
作用
- 加快检索速度
- 唯一性索引 —— 保障数据唯一性
- 加速表的连接
- 分组和排序进行检索的时候 —— 减少时间消耗
一般建立原则
- 经常查询的数据
- 主键
- 外键
- 连接字段
- 排序字段
- 少涉及、重复值多的字段不建立索引
MySQL中 InnoDB存储引擎支持索引
| name | use |
|---|---|
| 普通索引 INDEX | 值可空,没有唯一性限制 |
| 唯一值索引 UNIQUE | 值可空,但唯一 |
| 主键索引 PRIMARY KEY | 一个表只能由一个PK, 系统自动创建 |
| 全文索引 FULLTEXT | 在 varchar、char、text 类型的列上创建,便于查询字符串类型 |
物理存储区分:
- 聚集索引
- 非聚集索引
创建 修改 删除 显示
CREATE INDEX
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX 索引名[索引类型]
on 表名(索引列名)
[索引选项]
索引列名 =:
列名[(长度)][ASC|DESC]
- SPATIAL表示为空间索引
- 索引类型:BTREE或HASH
- 列名
- CHAR,VARCHAR, length可以小于字段实际长度 —— 减少索引文件
- BLOB和TEXT类型,必须指定 length
- 可包含属于同一个表的多个列,用逗号分开 —— 复合索引
- 没有PK索引

ALTER TABLE语句可以修改表定义,包括向表中添加索引
ALTER TABLE tbl_name ADD PRIMARY KEY | UNIQUE | INDEX | FULLTEXT (column_list)
删除
DROP INDEX 索引名 ON 表名
Alter TABLE 表名 ...
DROP PRIMARYKEY
| DROP {INDEX | KEY} 索引名
| DROP FOREIGN KEY 外键名
显示
SHOW INDEXES FROM tbl_name;
SHOW INDEXES FROM tbl_name IN db_name;
# *INDEX和KEY是INDEXES同义词
返回
| name | use |
|---|---|
| table | 表的名称 |
| NON_UNIQUE | 如果索引可以包含重复项,则为1;如果可以,则为0。 |
| KEY_NAME | 索引的名称。主键索引始终具有PRIMARY名称。 |
| seq_in_index | 索引中的列序列号。第一列序列号从1开始。 |
| column_name | 列名称。 |
| collation | 排序规则表示列在索引中的排序方式。A表示升序;B表示降序;NULL表示未分类。 |
| cardinality | 基数返回索引中估计的唯一值数。请注意,基数越高 —— 查询优化器使用索引进行查找的可能性就越大。 |
| sub_part | 索引前缀。如果对整个列编制索引,则为null。否则,它会显示部分索引列的索引字符数。 |
| packed | 表示密钥是如何打包的。 |
| null | YES——如果列可能包含NULL值,如果不包含空值则为空。 |
| INDEX_TYPE | 表示使用诸如索引方法BTREE,HASH,RTREE,或FULLTEXT。 |
| comment | 有关索引的信息未在其自己的列中描述 |
| index_comment | 显示使用COMMENT属性创建索引时指定的索引的注释。 |
| ¤visible | 索引是否对查询优化器可见或不可见; YES 是,NO 不是。 |
| expression | 如果索引使用表达式而不是列或列前缀值,则表达式指示键部分的表达式,并且column_name列也为NULL。 |
索引的使用情况
建议使用
- 唯一性的限制,比如用户名
- 频繁用WHERE查询字段
- GROUP BY和ORDER BY的列
- UPDATE、DELETE的WHERE条件列(类似2)
- DISTINCT字段需要创建索引
不建议使用
- WHERE GROUPBY ORDERBY 未出现的字段
- 记录较少的表 < 1000个
- 大量重复数据(比重偏差小
- 频繁更新的字段 (字段频繁更新导致索引更新效率慢)
失效
- 对索引进行 表达式计算
- 使用函数
- 使用LIKE且前缀为%
注意
- 多表JOIN连接操作时
- 连接表尽量不超3张
- 对WHERE条件创造index
- 于连接的字段创建索引,并且该字段在多张表中的类型必须一致
- 索引列尽量设置为 NOT NULL 约束
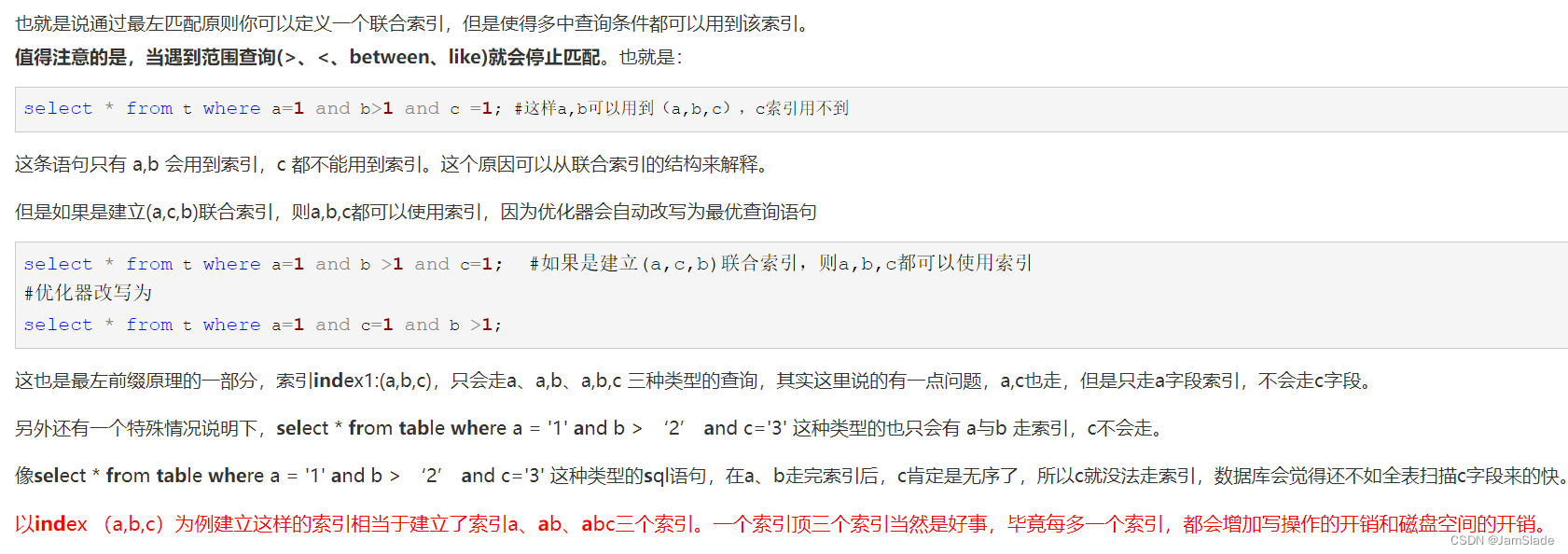
- 使用联合索引的时候要注意最左原则
- 从左到右的使用索引中的字段
- 一条 SQL 语句可以只使用联合索引的一部分,但要从最左侧开始,否则失效
- 当遇到范围查询(>、<、between、like)就会停止匹配
最左匹配原则
EXPAIN
| name | use |
|---|---|
| ¤ id | 选择标识符 |
| ¤ select_type | 表示查询的类型 |
| ¤ table | 输出结果集的表 |
| ¤ partitions | 匹配的分区 |
| ¤ type | 访问类型,常用的有: ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好) |
| ¤ possible_keys | 表示查询时,可能使用的索引,为NULL表示没有相关索引 |
| ¤ key | 表示实际使用的索引,如果为NULL表示没有选择索引 |
| ¤ key_len | 索引字段的长度,不损失精确性的情况下,长度越短越好 |
| ¤ ref | 列与索引的比较 |
| ¤ rows | 扫描出的行数(估算的行数) |
| ¤ filtered | 按表条件过滤的行百分比 |
| ¤ Extra | 执行情况的描述和说明 |
事务管理
MySQL 4.1开始支持事务,事务由作为一个单独单元的一个或多个SQL语句组成。
- 这个单元中的每个SQL语句是互相依赖的,而且单元作为一个整体是不可分割的
- 不能完成,整个单元就会回滚
- 事务中的所有语句都成功的执行这个事务才被成功地执行
提交
当一个会话开始时,系统变量AUTOCOMMIT值为1,即自动提交功能是打开的
任意一条SQL语句发送到服务器时,MySQL服务器会立即解析、执行并将更新结果提交到数据库文件中
在执行事务时要首先关闭MySQL的自动提交,使用命令“set autocommit=0;”可以关闭MySQL的自动提交
- 当MySQL关闭自动提交后,可以使用COMMIT命令来完成事务的提交,也标志transaction的结束
- 使用命令“start transaction;”可以开启一个事务 —— 隐式关闭MySQL的提交
注意
- transaction不能嵌套 —— 开始第二个事务会自动提交第一个事务
- 下面语句会隐式执行commit
- set autocommit=1、rename table、truncate table;
- create、alter、drop;
- grant、revoke、set password、create user、drop user、rename user
- lock tables、unlock tables
example
set autocommit=0;
insert into account values(111,500);
commit;
insert into account values(222,500);
create table student(
studentid char(6) primary key,
name varchar(10),
sex char(2)
)engine=innodb;
insert into account values(333,500);
select * from account;
在上面SQL语句执行过程中
- 首先使用命令“set autocommit=0;”关闭
MySQL的自动提交。 - 插入第一条记录后,使用commit命令完成事务的提交。
- 当插入第二条记录后,使用create命令创建数据表,由于create命令在执行时会隐式地执行commit命令,所以插入的第二条记录也会被提交。
- 当插入完第三条记录时,使用select语句查询到的是内存中的记录,所以查询结果可以看到新添加的三条记录。
- 由于最后一条语句并没有提交,所以该值并没有写到数据库文件中。另一客户机执行查询时,看到的是外存数据库文件在服务器内存中的一个副本,所以只查询到两条添加记录
- 当前客户机使用commit命令提交事务后,两个客户机看到的查询结果是相同的
回滚
销未提交的事务所做的各种修改操作,并结束当前这个事务
若只撤销一部分,可以用“部分回滚”
savepoint保存点名;”可以在事务中设置一个保存点,使用“rollback to savepoint 保存点名;”可以将事务回滚到保存点状态
四大特性和隔离级别
四大特性
- 事务是一个单独的逻辑工作单元,事务中的所有更新操作要么都执行,要么都不执行。
- 事务保证了一系列更新操作的原子性。如果事务与事务之间存在并发操作,则可以通过事务之间的隔离级别来实现事务的隔离,从而保证事务间数据的并发访问。
ACID
ATOMICITY CONSISTENCY ISOLATION DURABILITY
- 原子性意味着每个事务都必须被认为是一个不可分割的单元,事务中的操作必须同时成功事务才是成功的。如果事务中的任何一个操作失败,则前面执行的操作都将回滚,以保证数据的整体性没有受到影响
- 事务的一致性保证了事务完成后,数据库能够处于一致性状态。如果事务执行过程中出现错误,那么数据库中的所有变化将自动地回滚,回滚到另一种一致性状态
- 由MySQL的日志机制处理,它记录了数据库的所有变化,为事务恢复提供了跟踪记录
- 如果系统在事务处理中发生错误,MySQL恢复过程将使用这些日志来发现事务是否已经完全成功地执行,是否需要返回
- 事务的隔离性确保多个事务并发访问数据时,各个事务不能相互干扰; 的每个事务在自己的空间执行,并且事务的执行结果只有在事务执行完才能看到 —— 其他事务暂时看不到结果 (可以使用页级锁定或行级锁定来隔离)
- 事务的持久性意味着事务一旦提交,其改变会永久生效,不能再被撤销。 —— 即使系统崩溃,一个提交的事务仍然存在
隔离级别
从低到高分别是
read uncommitted(读取未提交的数据)
read committed(读取提交的数据)
repeatable read(可重复读)
serializable(串行化)。
- read uncommitted(读取未提交的数据)提供了事务之间的最小隔离程度,处于这个隔离级别的事务可以读到其他事务还没有提交的数据
- read committed(读取提交的数据)处于这一级别的事务可以看见已经提交事务所做的改变
- repeatable read(可重复读)这是MySQL默认的事务隔离级别,它确保在同一事务内相同的查询语句其执行结果总是相同的(即使某个事务突然改了某个数据而且事务还没结束,前后查询的内容还是一样的)
- serializable(串行化) 最高级别的隔离,它强制事务排序,使事务一个接一个地顺序执行
解决多用户问题
用户对数据库并发访问时,为了确保事务完整性和数据库一致性,需要使用锁定 —— 防止用户读取正在由其他用户更改的数据,并可以防止多个用户同时更改相同数据
-
高级别的事务隔离 —— 有效地实现并发,但会降低事务并发访问的性能
-
低级别的事务隔离可以提高事务的并发访问性能,但可能导致并发事务中的脏读、不可重复读和幻读等问题
三个问题:
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| read uncommitted | ✔ | ✔ | ✔ |
| read committed | × | ✔ | ✔ |
| repeatable read | × | × | ✔ |
| serializable | × | × | × |
脏读
一个事务可以读到另一个事务未提交的数据
- 打开MySQL客户机A,将当前MySQL会话的事务隔离级别设置为read uncommitted。
set session transaction isolation level read uncommitted - 开启事务,查询账号为“111”账户的余额。
- 打开MySQL客户机B,将当前MySQL会话的事务隔离级别设置为read uncommitted。
- 开启事务,将账号为“111”账户余额增加800。
- 在MySQL客户机A中查看账号为“111”账户的余额。
- 关闭MySQL客户机A和客户机B后,再查看账号为“111”账户的余额。
这个时候 A 读到了B未结束事务但已更新的结果(也就是加了 800)
不可重复读
同一个事务中,两条相同的查询语句其查询结果不一致
- 一个事务访问数据时,另一个事务对该数据进行修改并提交,导致第一个事务两次读到的数据不一样
- 将MySQL客户机A与客户机B使用语句“set session transaction isolation level read committed;”,将他们的隔离级别都设置为read committed。
- 与例6-5相同,首先在MySQL客户机A中查询账号为“111”账户的余额。
- 在MySQL客户机B中将账号为“111”账户余额增加800,未提交事务时在MySQL客户机A中查询账号为“111”账户的余额,对比是否出现脏读。
- MySQL客户机B中提交事务后,在MySQL客户机A中查询账号为“111”账户的余额,对比是否出现不可重复读。
A读到的数据是B事务提交后的数据
幻读
当前事务读不到其他事务已经提交的修改(别人已经改了而且提交事务了,而你的读的内容还是修改之前的)
- 将MySQL客户机A与客户机B使用语句“set session transaction isolation level repeatable read;”,将他们的隔离级别都设置为repeatable read。
- 在MySQL客户机A中开启事务并查询账号为“999”的账户信息。
- 在MySQL客户机B中开启事务,插入一条账户信息(999,700),然后提交事务。
- 在MySQL客户机A中再次查账号为“999”的账户信息,判断是否可以避免不可重复读。
- 在MySQL客户机A中插入账户信息(999,700),并判断是否可以插入