文章目录
- Classification 概念
- Example Application
- How to do Classification
- Why not Regesssion
- Probability from Class - Feature
- Probability from Class
- How’s the results?
- Modifying Model
- Three Steps
- Probability Distribution
Classification 概念
本质是找一个函数,输入对象X后输出其所属类别Class,实际应用如下:

Example Application
以神奇宝贝属性分类(Water/79 和 Normal/61)进行推进,function中input数据来源如下:

How to do Classification
数据通过函数中计算后返回判断类别结果,loss函数返回训练集汇总出现的错误,然后选择最优模型
idea图如下(二分类):

Why not Regesssion
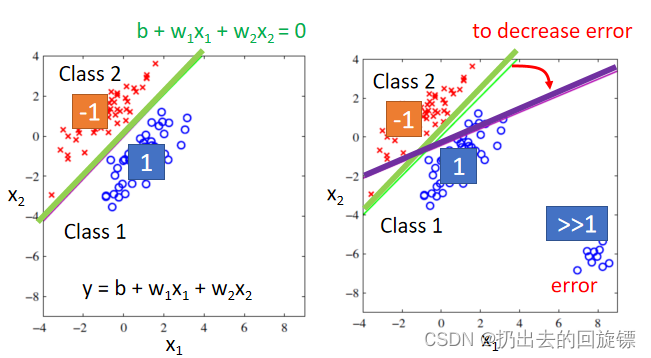
存在的问题:
- 回归用一条线,但问题是非常正确的样本将分界线过度纠正导致效果不好
- Regression返回的是连续值,classification返回离散的点,性质不同
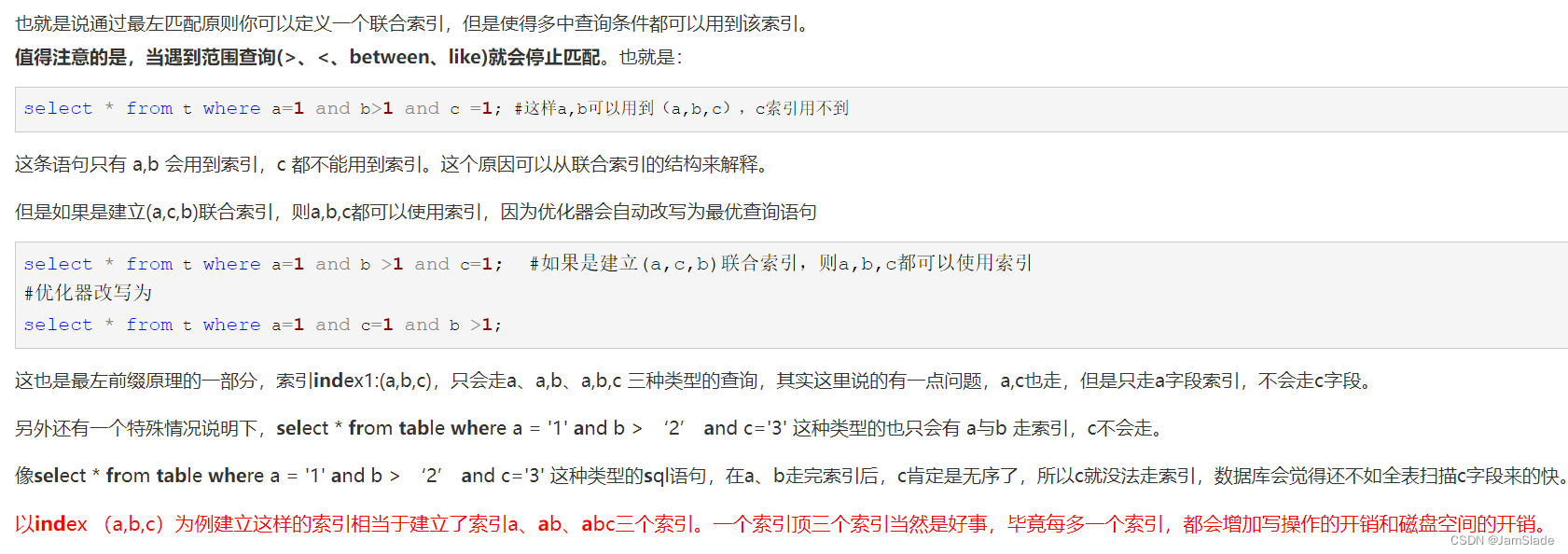
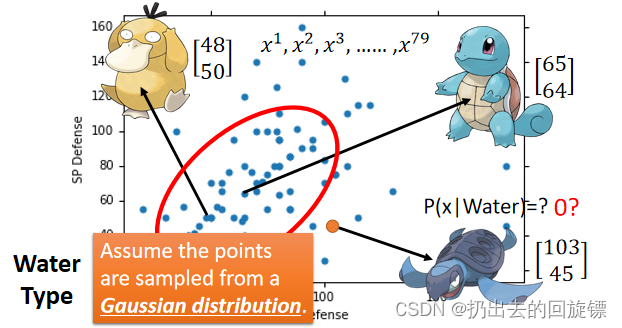
Probability from Class - Feature
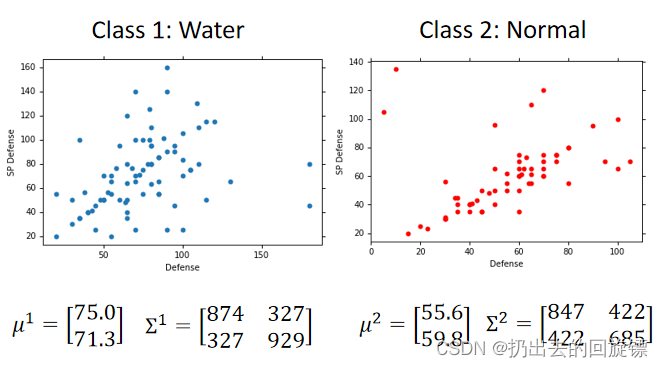
只考虑Defense和SP Defence这两种feature,并认为样本点符合高斯分布(正态分布)注意海龟不在训练集中
高斯分布的简单介绍
公式如下:
f
μ
,
Σ
(
x
)
=
1
(
2
π
)
D
/
2
1
∣
Σ
∣
1
/
2
e
x
p
{
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
}
f_{\mu,\Sigma}(x)=\frac{1}{(2\pi)^{D/2}}\frac{1}{|\Sigma|^{1/2}}exp\{-\frac{1}{2}(x-\mu)^T\Sigma^{-1}(x-\mu)\}
fμ,Σ(x)=(2π)D/21∣Σ∣1/21exp{−21(x−μ)TΣ−1(x−μ)}
其中,
μ
\mu
μ表示均值,
Σ
\Sigma
Σ表示协方差(covariance),它们对于分布的影响如下:
- 不同的 μ \mu μ相同的 Σ \Sigma Σ概率分布最高点不同
- 相同
μ
\mu
μ不同的
Σ
\Sigma
Σ,概率最高点相同,分散程度不同
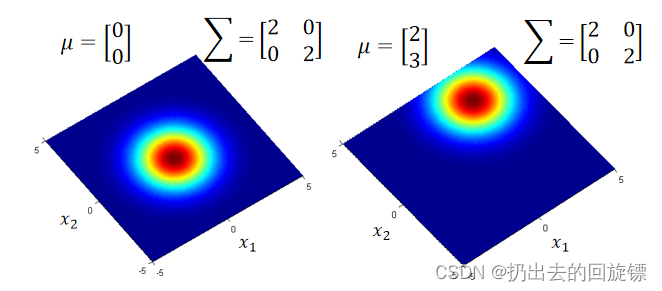
Probability from Class
将海龟的数据代入由之前的79个资料形成的高斯分布中就可以估测它所属类别的概率。通过极大似然函数寻找这个高斯分布:
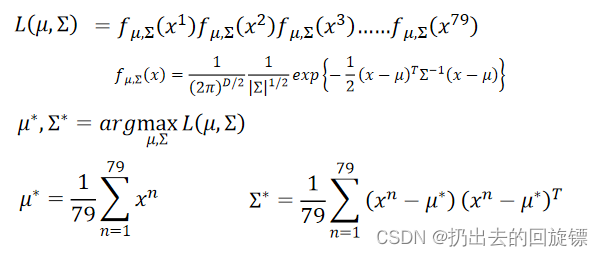
分别计算两种类别最佳高斯分布参数:
将这些得到的数据进行代入分类公式(设定阈值0.5):

How’s the results?
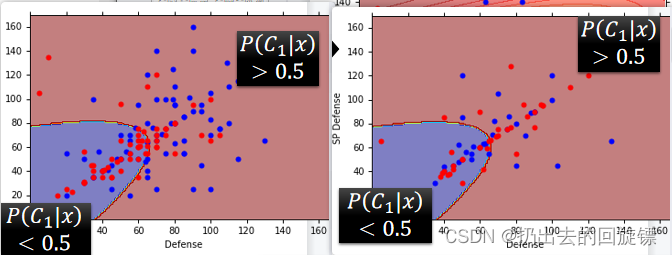
左图是训练集右图是测试集,结果47% accuracy,效果非常差。即使使用所有的6种数据集accuracy也仅仅54%。
Modifying Model
考虑可能是参数过多导致过拟合,比较好的解决方式是公用一个covariance matrix,因为它在样本数量较多时增长非常迅速(与feature size的平方成正比)然后造成过拟合,使用相同协方差过程如下:

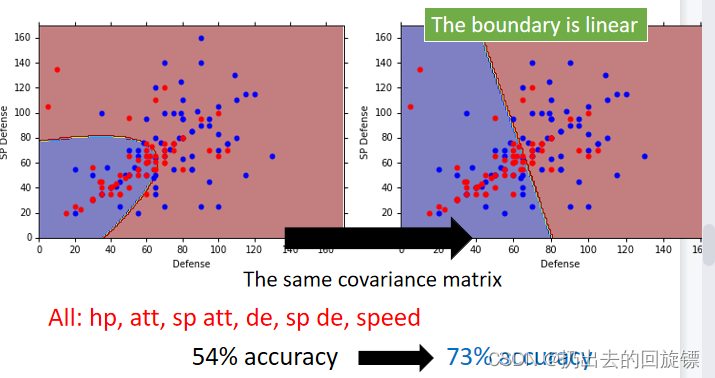
效果得到了显著提升,并且边界变成了线性的。为什么?鬼知道!
Three Steps

Probability Distribution

sigmoid function:
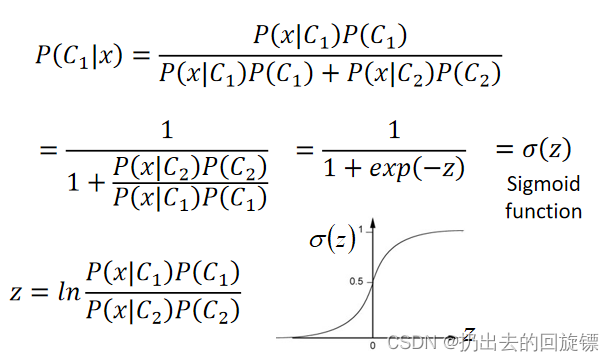




上面推导解释为何分类的边界线变成了线性的