今天,你内卷了吗?

文章目录
- 一、泛型编程
- 二、函数模板(显示实例化和隐式实例化)
- 1.函数模板格式
- 2.单参数模板
- 3.多参数模板
- 4.模板参数的匹配原则
- 三、类模板(没有推演的时机,统一显示实例化)
- 1.类模板的使用
- 2.类模板实现静态数组
- 3.类模板能否声明和定义分离?
- 四、STL简介
- 1.什么是STL
- 2.STL的版本
- 3.STL的六大组件
一、泛型编程
1.
假设要交换两个变量的值,如果只是用普通函数来做这个工作的话,那么只要变量的类型发生变化,我们就需要重新写一份普通函数,如果是C语言,函数名还不可以相同,但是这样很显然非常的麻烦,代码复用率非常的低。
那么能否告诉编译器一个模板,让编译器通过模板来根据不同的类型产生对应的代码呢?答案是可以的。
2.
而上面这样利用模板来生成类型所对应的代码,这样的思想实际上就是泛型编程。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。
模板正是泛型编程的基础,模板又可以分为类模板和函数模板。
void Swap(int& left, int& right)
{
int tmp = left;
left = right;
right = tmp;
}
void Swap(double& left, double& right)
{
double tmp = left;
left = right;
right = tmp;
}
二、函数模板(显示实例化和隐式实例化)
1.函数模板格式
1.
函数模板格式:
template<typename T1, typename T2,…,typename Tn>
返回值类型 函数名(参数列表){ }
2.
typename和class是用来定义模板参数的关键字。
template<typename T>//typename和class这里都可以
void Swap(T& left, T& right)
{
T tmp = left;
left = right;
right = tmp;
}
int main()
{
int a = 1, b = 2;
Swap(a, b);
double c = 1.1, d = 2.2;
Swap(c, d);
return 0;
}
2.单参数模板
1.
模板的实例化有两种方式,一种是显示实例化,一种是隐式实例化,隐式实例化就是让编译器根据实参所传类型确定模板参数,然后推导出来函数,显式实例化是告诉编译器指定模板参数的类型。
2.
如果显示实例化后,实参与指定模板参数类型不同,则编译器会自动发生隐式类型转换。
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.1, d2 = 20.2;
//自动推演实例化,让编译器推导T的类型
cout << Add(a1, a2) << endl;
cout << Add(d1, d2) << endl;
cout << Add((double)a1, d2) << endl;//强制类型转换,产生临时变量,临时变量具有常性
cout << Add(a1, (int)d2) << endl;
//显示实例化,直接告诉编译器T的类型
cout << Add<double>(a1, d2) << endl;//隐式类型转换,产生临时变量,临时变量具有常性
cout << Add<int>(a1, d2) << endl;
return 0;
}
3.多参数模板
模板参数除单个外,也可以是多个,在使用上和单参数模板没什么区别,同样实例化的方式也可分为两种,一种是隐式实例化,一种是显示实例化。
template<class T1,class T2>
T1 Add(const T1& left, const T2& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.1, d2 = 20.2;
//自动推演实例化,让编译器推导T的类型
cout << Add(a1, a2) << endl;//T1和T2都推成int
cout << Add(d1, d2) << endl;//都推成double
cout << Add(a1, d2) << endl;//推成一个是int,一个是double
cout << Add(d1, a2) << endl;
return 0;
}
4.模板参数的匹配原则
1.
普通函数和模板函数若同名,是可以同时存在的,相当于两个函数构成重载,在调用上,一般会优先调用普通函数,因为编译器虽然勤快,但是它不傻,他知道调用模板函数需要进行推演实例化,如果有现成的普通函数,他肯定不会去推导模板实例化的。但是如果强行显式实例化模板参数,那编译器也没辙,就会显示调用模板推导出来的函数。
// 专门处理int的加法函数
int Add(int left, int right)// _Z3Addii
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)// _Z3TAddii(修饰规则不一定这样,只是假设而已)
{
return left + right;
}
//一个具体的函数和模板函数能不能同时存在呢?答案是可以的,他们是可以同时存在的
int main()
{
int a = 1, b = 2;
Add(a, b);//会优先调用具体的函数,而不是调用模板进行推导。编译器很勤快,但它不傻。
Add<int>(a, b);//显示调用模板推导出来的函数。
//上面两行代码可以说明模板推导的int函数和具体的int函数可以同时存在,那么就可以证明这两个函数的函数名修饰规则是不一样的
return 0;
}
三、类模板(没有推演的时机,统一显示实例化)
1.类模板的使用
1.
类模板和函数模板在使用上有些区别,函数模板可以隐式实例化,通过实参类型进行函数推演,而类模板是无法隐式实例化的,因为没有推演的时机,所以对于类模板,统一使用显示实例化,即在类后面加尖括号,尖括号中存放类型名,进行类模板的实例化。
2.
值得注意的是类模板不是具体的类,具体的类是需要进行实例化的,只有类名后面的尖括号跟上类型才算实例化出真正的类。
例如下面的栈,如果想让栈存储不同类型的数据,就需要显示实例化类模板。
template<typename T>
class Stack
{
public:
Stack(int capacity = 4)
{
cout << "Stack(int capacity = )" <<capacity<<endl;
_a = (T*)malloc(sizeof(T)*capacity);
if (_a == nullptr)
{
perror("malloc fail");
exit(-1);
}
_top = 0;
_capacity = capacity;
}
~Stack()
{
cout << "~Stack()" << endl;
free(_a);
_a = nullptr;
_top = _capacity = 0;
}
void Push(const T& x)//用引用效率高一点,因为类对象可能所占字节很大,如果不改变最好加const
{
// ....
// 扩容
_a[_top++] = x;
}
private:
T* _a;
int _top;
int _capacity;
};
int main()
{
//Stack st1;
st1.push(1);
//st1.Push(1.1);
//Stack st2;
//st2.Push(1);
//一个栈存int,一个栈存double这样的场景,用typedef无法解决,必须使用类模板来解决。
//函数模板可以通过实参传递形参,推演模板参数。但是类模板一般没有推演的时机,统一使用显示实例化。
Stack<int> st1;
st1.Push(1);
Stack<double>st2;
st2.Push(1.1);
//180和182行是两个不同的类类型,因为类的大小有可能不同,所以类模板相同,但模板参数不同,则类模板实例化出来的类是不同的。
//st1 = st2;//这样的操作是不允许的,因为如果类不同,则实例化对象肯定也不相同,所以不可以赋值。
return 0;
}
2.类模板实现静态数组
1.
std命名空间中的array可能和我们的array产生冲突,所以我们可以利用自己的命名空间将自己的类封装起来,以免产生冲突。
2.
利用运算符重载可以实现对静态数组中每一个元素进行操控。
与C语言不同的是,这种运算符重载可以不依赖于抽查行为,而是进行严格的越界访问检查,通过assert函数来进行严格检查。
#define N 10
namespace wyn
{
template<class T>
class array
{
public:
inline T& operator[](size_t i)//内联,不会建立栈帧,提高效率,减少性能损耗。
{
assert(i < N);//不依赖于抽查行为
return _a[i];
}
private:
T _a[N];
};
}
int main()
{
int a2[10];
//C语言对于越界访问是抽查的方式,访问近一点的位置,会查到报错,但访问远一点的位置,就有可能不会报错。
//a2[10] = 10;
//a2[20] = 20;//对于越界访问写,勉强会检查到。
a2[10];
a2[20] ;//但对于越界访问读,基本不会检查出来。
wyn::array<int> a1;//array有可能和std命名空间里面的array冲突,所以我们自己定义一个命名空间
for (size_t i = 0; i < N; i++)
{
a1[i] = i;
//等价于 a1.operator[](i)=i;
}
for (size_t i = 0; i < N; i++)
{
a1[i]++;
}
for (size_t i = 0; i < N; i++)
{
cout << a1[i] << " ";
}
cout << endl;
return 0;
}
3.类模板能否声明和定义分离?
1.
首先明确一点,类模板是不允许声明和定义分离的,因为这会发生链接错误。
2.
其实原因很简单,因为在用的地方类模板的确进行了实例化,可是用的地方只有声明没有定义,而定义的地方又没有进行实例化,所以就会发生链接错误。
3.
说白了就是Stack.cpp里面的类模板由于没有实例化,那就是没有真正的类,所以类中成员函数的地址无法进入符号表,那么在链接阶段,Test.cpp就无法链接到类成员函数的有效地址。
4.
解决方式有两种:
a.既然在Stack.cpp里面类模板没有实例化么,那我们就手动在Stack.cpp里面进行实例化就好了,但是这样也有一个弊端,只要类模板参数类型改变,我们手动实例化时就需要多加一行,这未免有些太繁琐了吧!

b.
所以最好的方式就是不要将类成员函数定义和声明分文件存放,而是将类模板中的成员函数直接放在.h文件里面。这样就不会出现找不到有效地址的问题了,因为一旦Test.cpp中进行了模板实例化,则.h文件中的那些方法也就会实例化,此时他们的地址就会进入符号表。也有人会将.h文件重命名为.hpp文件,这就是典型的模板类的声明和定义方式。
template<class T>
Stack<T>::Stack(int capacity)//声明处写了缺省值,定义处就不用写了。
{
cout << "Stack(int capacity = )" << capacity << endl;
_a = (T*)malloc(sizeof(T) * capacity);
if (_a == nullptr)
{
perror("malloc fail");
exit(-1);
}
_top = 0;
_capacity = capacity;
}
template<class T>
Stack<T>::~Stack()
{
cout << "~Stack()" << endl;
free(_a);
_a = nullptr;
_top = _capacity = 0;
}
template<class T>
void Stack<T>::Push(const T& x)
{
// ....
//
_a[_top++] = x;
}

四、STL简介
1.什么是STL
STL(standard template libaray-标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包罗数据结构与算法的软件框架。
2.STL的版本
原始版本:
Alexander Stepanov、Meng Lee 在惠普实验室完成的原始版本,本着开源精神,他们声明允许任何人任意运用、拷贝、修改、传播、商业使用这些代码,无需付费。唯一的条件就是也需要向原始版本一样做开源使用。 HP 版本–所有STL实现版本的始祖。
P. J. 版本:
由P. J. Plauger开发,继承自HP版本,被Windows Visual C++采用,不能公开或修改,缺陷:可读性比较低,符号命名比较怪异。
RW版本:
由Rouge Wage公司开发,继承自HP版本,被C+ + Builder 采用,不能公开或修改,可读性一般。
SGI版本:
由Silicon Graphics Computer Systems,Inc公司开发,继承自HP版本。被GCC(Linux)采用,可移植性好,可公开、修改甚至贩卖,从命名风格和编程 风格上看,阅读性非常高。我们后面学习STL要阅读部分源代码,主要参考的就是这个版本。
3.STL的六大组件
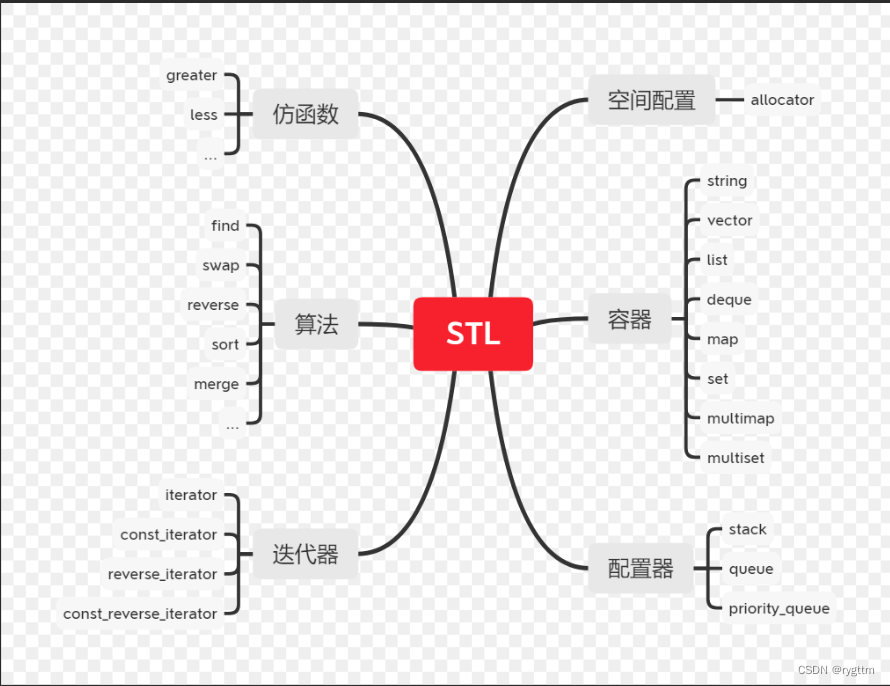
STL的六大组件(转载自博客园博主WELEN的文章)