一、MySQL 排它锁和共享锁
在进行实验前,先来了解下MySQL 的排它锁和共享锁,在 MySQL 中的锁分为表锁和行锁,在行锁中锁又分成了排它锁和共享锁两种类型。
1. 排它锁
排他锁又称为写锁,简称X锁,是一种悲观锁,具有悲观锁的特征,如一个事务获取了一个数据行的X锁,其他事务尝试获取锁时就会等待另一个事务的释放。其中在 InnoDB 引擎下做写操作时 (UPDATE、DELETE、INSERT)都会自动给涉及到的数据加上 X 锁,因此当多线程情况下对同一条数据进行更新,在MySQL中不会出现线程安全问题。
其中 SELECT 语句默认不会加锁,如果查询的数据已经存在 X 锁,则会返回其最近提交的数据,如果希望每次获取的数据都是更新后最新的数据,当存在有更新时,则等待更新完成后获取新的值,这种情况下就需要对 SELECT 语句也要存在 X 锁,其中 SELECT 语句加 X 锁的话需要使用 FOR UPDATE 语句。
比如:当前有一张表结构如下:
CREATE TABLE `lock` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
写入一条测试数据:
INSERT INTO `testdb`.`lock`(`id`, `name`) VALUES (1, 'lock1');
下面,我使用 Navicat 开启了两个对话框,我在第一个对话框中,使用手动提交事务的方式执行更新语句,并且既不提交也不回滚事务:
BEGIN;
UPDATE `lock` SET `name` = 'lock2' WHERE id = 1;
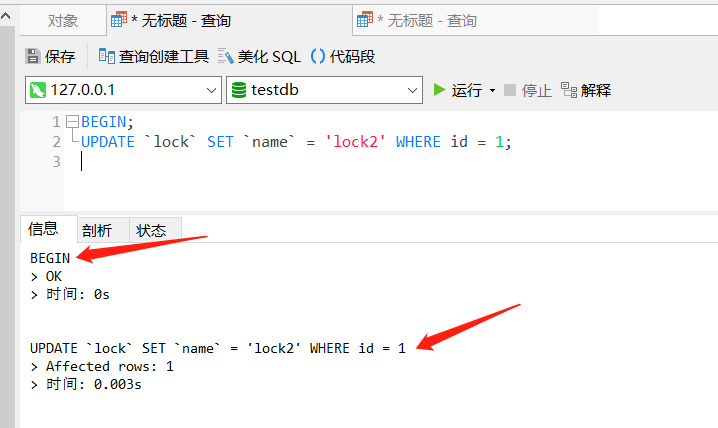
下面在另一个对话框中,查询 id = 1 的数据:
SELECT * FROM `lock` where id = 1
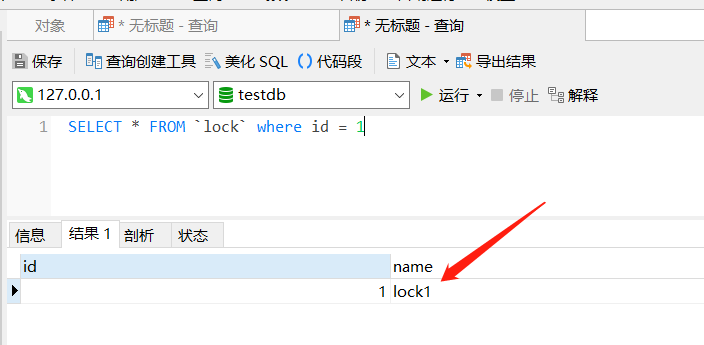
可以看到,并没有拿到最新的内容,因为此时 X 锁还没有释放,那此时对查询语句进行调整下,加上 FOR UPDATE 语句:
SELECT * FROM `lock` where id = 1 FOR UPDATE
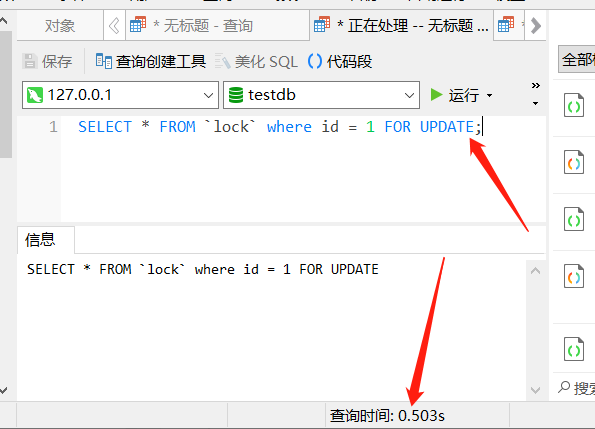
此时会发现,查询语句一直在等待,因为这个查询语句在等待 X 锁的释放,下面对第一个对话框中,执行提交事务:
COMMIT;
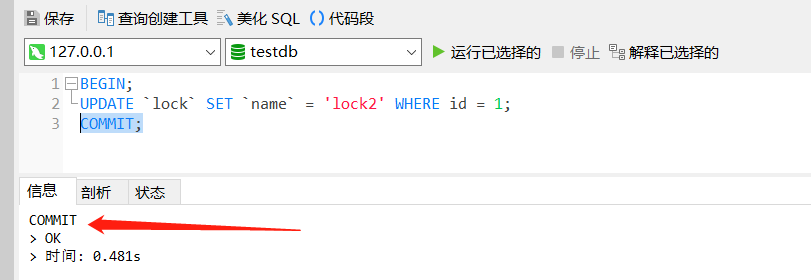
在回到第二个对话框中查看:
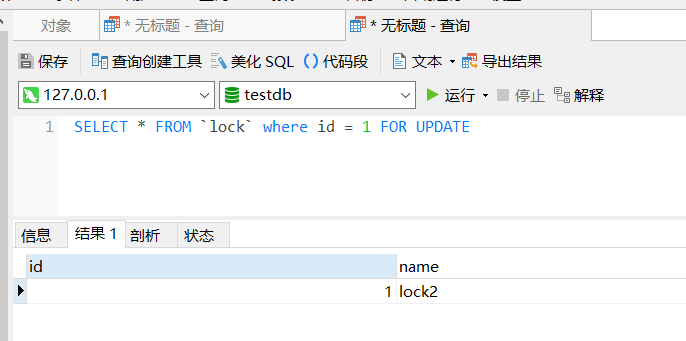
已经拿到最新的值。这里需要注意下,你的是不是出现了超时报错,这是因为 Innodb 引擎对等待锁有个等待超时时间,默认情况下是 50s ,可以通过下面指令查看:
SHOW VARIABLES LIKE "Innodb_lock_wait_timeout"
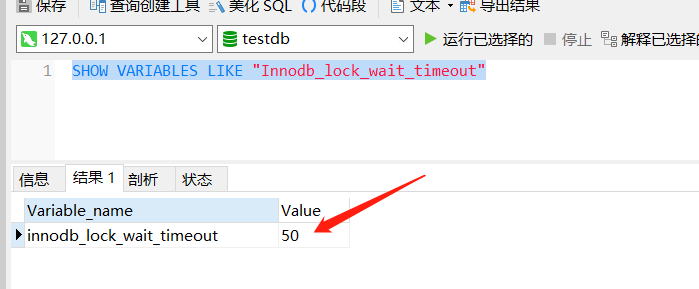
如果感觉太小,可以通过下面指令调整:
SET innodb_lock_wait_timeout = 100
上面的操作已经感觉出来 X 锁的效果,那当两个 SELECT 语句都加上 FOR UPDATE 呢,比如在第一个回话框中,使用手动事务执行 SELECT 语句,同样不提交事务:
BEGIN;
SELECT * FROM `lock` where id = 1 FOR UPDATE;
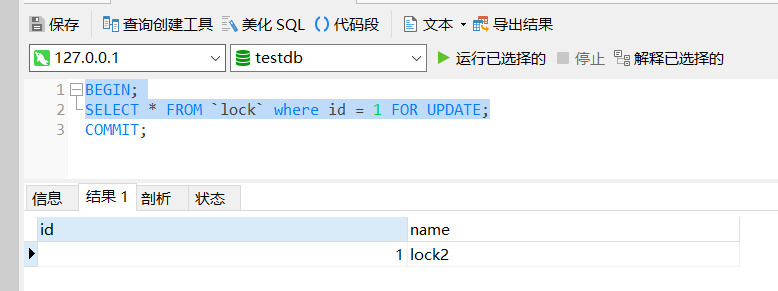
在第二个对话框同样执行相同的代码,可以发现被阻塞掉了。
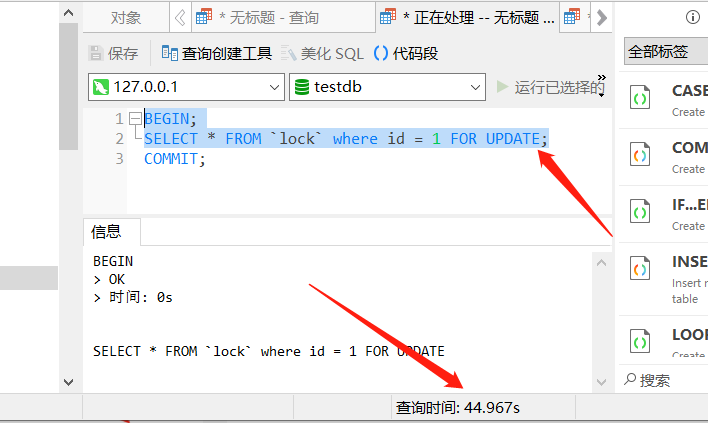
当第一个提交事务后,第二个紧接着也查出了信息,这也正符合排他锁的特征。
2. 共享锁
共享锁可以理解为读锁,简称S锁,可以对多个事务SELECT情况下读取同一数据时不会阻塞,但是如果存在写操作时 (UPDATE、DELETE、INSERT),SELECT语句也会被阻塞,在MySQL中使用 S 锁需要使用 LOCK IN SHARE MODE。
例如还是开启两个对话框,在第两个对话框中,都查询 id = 1 的数据,并加上 S 锁,最后同样不提交事务:
BEGIN;
SELECT * FROM `lock` where id = 1 LOCK IN SHARE MODE;
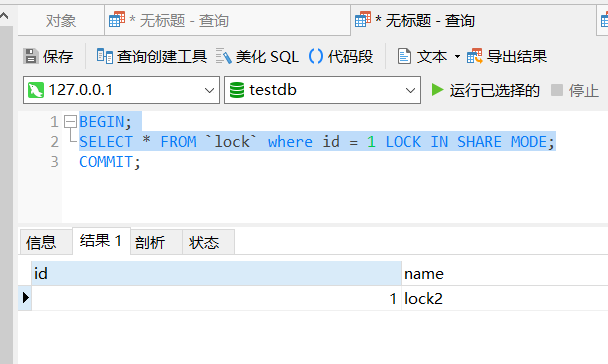
可以发现两个都拿到了数据,对两个都提交事务后,假如第一个对话框中是更新操作,最后同样不提交事务:
BEGIN;
UPDATE `lock` SET `name` = 'lock3' WHERE id = 1 ;
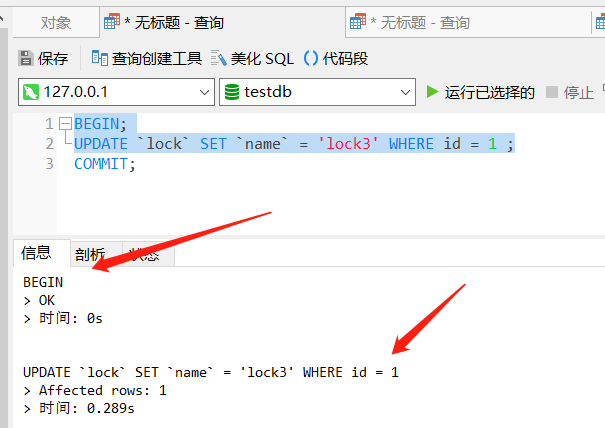
在第二个对话框中还是加上 S 锁的查询操作:
BEGIN;
SELECT * FROM `lock` where id = 1 LOCK IN SHARE MODE;
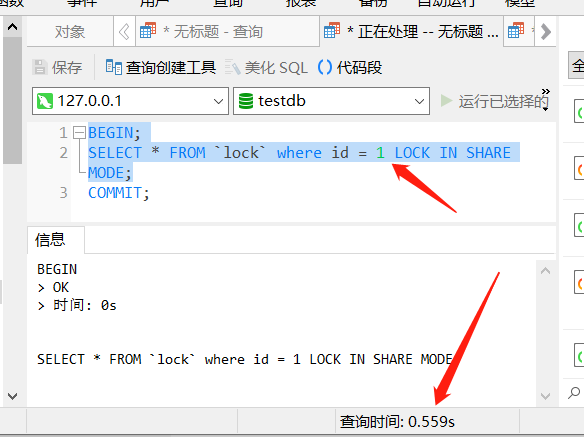
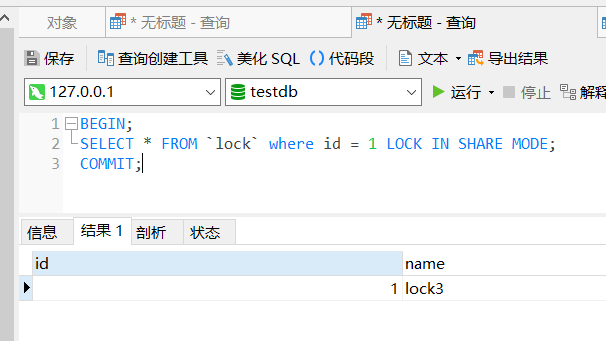
可以看到查询被阻塞了,当第一个对话框中提交了事务,这里才会返回结果:
读到这里相信大家已经对 MySQL 的排它锁和共享锁有了一定的了解,下面我们基于 排它锁 实现分布式锁的场景。
二、基于 MySQL 排它锁实现分布式可重入锁
根据上面的实例可以看到排它锁具有阻塞等待的效果,和我们 JVM 中普通的锁的效果是一致的,但普通的锁通常只能在单个 JVM 中,但现在的服务,动则都要多台集群部署,对于不同的 JVM 普通的锁实在心有余而力不足,此时就要考虑使用分布式锁,目前分布式锁的解决方案也比较多,例如基于 Redis 的 setNx 实现的分布式锁,相关框架有 Redissson ,还有基于 Zookeeper 的临时节点实现的分布式锁,相关框架有 Curator 等等,而且这些都有方案实现锁的可重入性。
本文我们再介绍一种基于 MySQL 的方案,毕竟现在再小的项目基本都会引入数据库,我们在此基础上延伸也少了其他框架的学习。
实现的思路:
- 数据库中创建一个
lock表 ,里面根据场景添加数据,一行就代表一个分布式锁的句柄。 - 在项目中在需要锁的方法中首先开启事务,保证下面的操作在事务中,事务可借助
Spring的@Transactional注解。 - 在获取锁时,使用
SELECT * FROM lock WHERE id = #{id} FOR UPDATE排它锁语句执行。 - 如果正常查询到则获取锁成功,此时如果其他事务也在获取锁,则因为排他锁的原因会阻塞等待。
- 此时如果还要获取锁,也就是对于锁的可重入性设计,可以利用同一个事务中对于同一条数据
FOR UPDATE不会阻塞的特征,只需在同一个事务中再次获取锁的操作即可实现 。 - 方法执行完,如果是手动事务一定要提交或回滚事务,即表示释放锁,如果是
Spring的@Transactional注解,则会自动提交或回滚。
开始实施:
首先新建一个 SpringBoot 项目,在 pom 中引入 mybatis-plus 依赖:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.6</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
下面在配置文件中增加 MySQL 的配置:
server:
port: 8081
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/testdb?useUnicode=true&characterEncoding=utf8&serverTimezone=UTC
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
下面获取锁的逻辑其实就是一个 Mapper 中的 Select 操作:
@Mapper
public interface LockMapper {
/**
* 尝试获取锁
*/
@Select("SELECT id FROM `lock` where id = #{id} FOR UPDATE;")
Long tryLock(@Param("id") Long id);
}
下面编写一个线程安全的例子,使用 10 个线程,去对一个全局 int 变量做 +1 操作,这里为了方便测试,直接声明成 Controller
@RestController
public class LockService {
private volatile int count = 0;
@GetMapping("/test")
public void test() {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
testLock();
}).start();
}
}
public void testLock() {
count++;
System.out.print(count+" , ");
}
}
运行后,访问测试接口,查看控制台打印的效果:
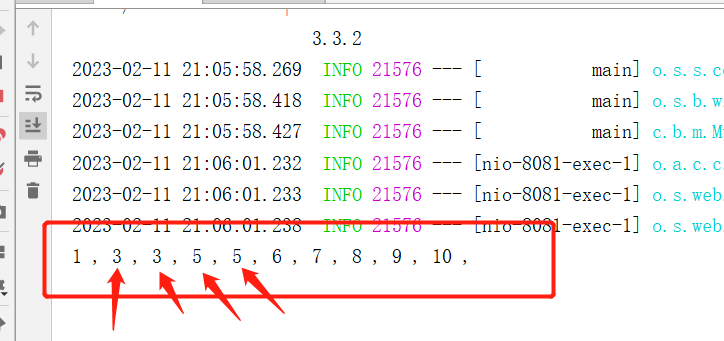
可以看到已经出现线程安全问题了,下面我们改造成使用 MySQL 的排他锁进行协调,这里需要注意下,这里事务使用的是 Spring 的 @Transactional 注解,是基于 AOP 实现的,因此 LockService 需要从 Spring 容器中获取 ,另外对于锁的超时可以捕获 CannotAcquireLockException 异常。
@RestController
public class LockService {
@Resource
LockService lockService;
@Resource
LockMapper lockMapper;
private final Long LOCK_ID = 1L;
private volatile int count = 0;
@GetMapping("/test")
public void test() {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
lockService.testLock();
}).start();
}
}
@Transactional(rollbackFor = Exception.class)
public void testLock() {
try {
//获取锁,如果获取不到则阻塞
if (Objects.nonNull(lockMapper.tryLock(LOCK_ID))){
count++;
System.out.print(count + " , ");
}
} catch (CannotAcquireLockException e) {
System.out.println("获取锁超时!");
}
}
}
执行后,查看日志:
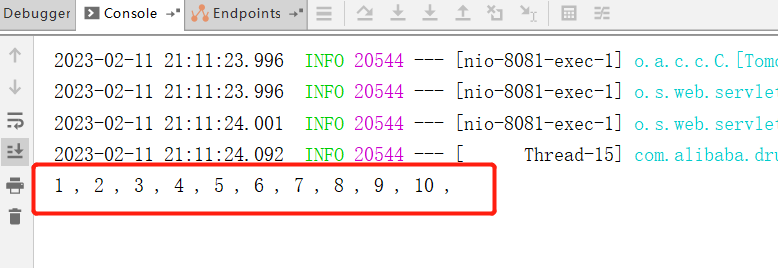
细心地话可以明显感觉执行速度比之前慢了,因为出现了阻塞情况,通过数据可以看到已经解决了线程安全问题,但是锁的可重入性呢,我们在获取到锁后,再次获取锁看看是否正常,注意可重入锁表示锁中锁,锁的对象一定要是一致的,也就是这里的锁的 ID 要是一致的:
@RestController
public class LockService {
@Resource
LockService lockService;
@Resource
LockMapper lockMapper;
private final Long LOCK_ID = 1L;
private volatile int count = 0;
@GetMapping("/test")
public void test() {
for (int i = 0; i < 10; i++) {
new Thread(() -> {
lockService.testLock();
}).start();
}
}
@Transactional(rollbackFor = Exception.class)
public void testLock() {
try {
//获取锁,如果获取不到则阻塞
if (Objects.nonNull(lockMapper.tryLock(LOCK_ID))){
// 重入锁
if (Objects.nonNull(lockMapper.tryLock(LOCK_ID))){
count++;
System.out.print(count + " , ");
}
}
} catch (CannotAcquireLockException e) {
System.out.println("获取锁超时!");
}
}
}
运行后,查看日志:
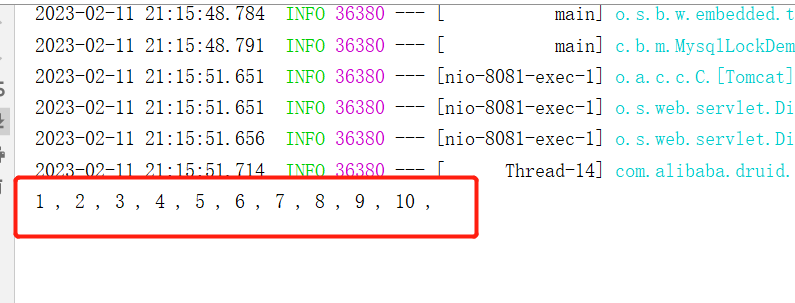
可以看到可重入锁场景下也是可以正常获取到锁。
三、总结
本文基于 MySQL 实现的一种分布式可重入锁的效果,由于锁是使用的 MySQL 的排他锁,因此在多个 JVM 中也是可以实现锁的效果。这里主要讲解了实现思路,对于模块的封装没有做过多的设计,如果有想法的小伙伴也可以发动想法封装一下。另外由于是使用了 MySQL 如果是大量并发的情况下,可能会对 MySQL 造成一些压力。另外可能由于某些原因造成一端持有锁的时间过长,其余等待锁发生超时现象,超时情况这里未做处理,后续可以根据实际情况进行重试或错误处理。