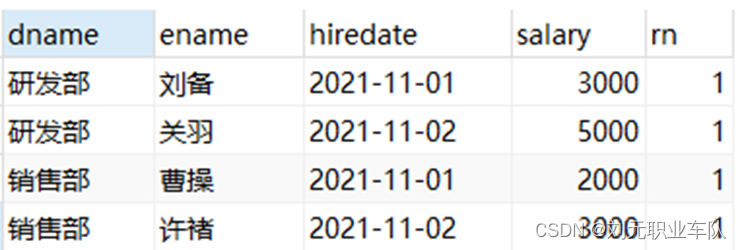
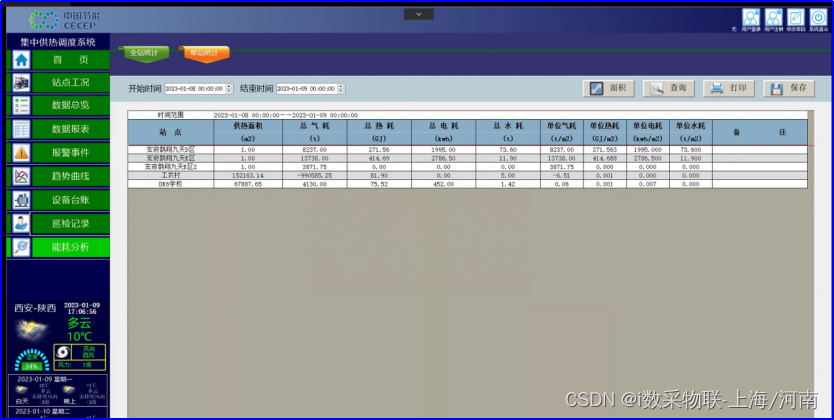
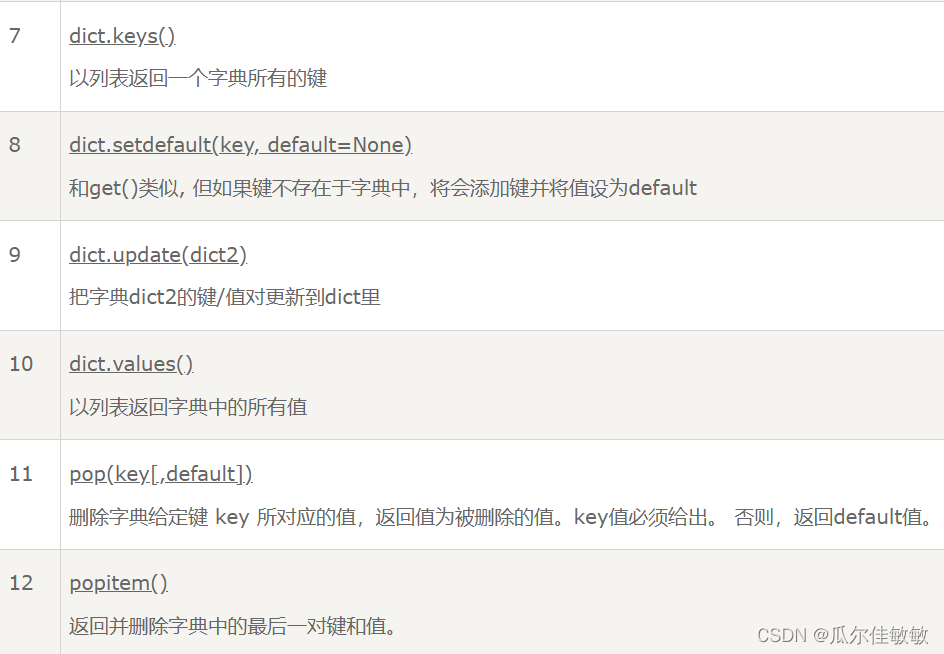
诸如词-词共现计数的全局语料库统计可以来解释跳元模型。
交叉熵损失可能不是衡量两种概率分布差异的好选择,特别是对于大型语料库。GloVe使用平方损失来拟合预先计算的全局语料库统计数据。
对于GloVe中的任意词,中心词向量和上下文词向量在数学上是等价的。
GloVe可以从词-词共现概率的比率来解释。
上下文窗口内的词共现可以携带丰富的语义信息。例如,在一个大型语料库中,“固体”比“气体”更有可能与“冰”共现,但“气体”一词与“蒸汽”的共现频率可能比与“冰”的共现频率更高。此外,可以预先计算此类共现的全局语料库统计数据:这可以提高训练效率。为了利用整个语料库中的统计信息进行词嵌入,让我们首先回顾 预训练——词嵌入(word2vec)、 近似训练_流萤数点的博客-CSDN博客中的跳元模型,但是使用全局语料库统计(如共现计数)来解释它。
1.带全局语料统计的跳元模型

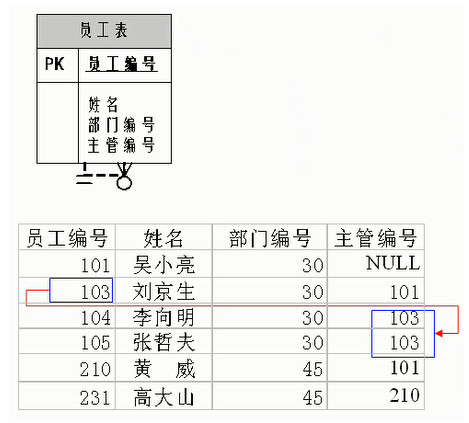
考虑词可能在语料库中出现多次。在整个语料库中,所有以
为中心词的上下文词形成一个词索引的多重集Ci,该索引允许同一元素的多个实例。对于任何元素,其实例数称为其重数。举例说明,假设词wi在语料库中出现两次,并且在两个上下文窗口中以
为其中心词的上下文词索引是k,j,m,k和k,l,k,j。因此,多重集Ci={j,j,k,k,k,k,l,m},其中元素j,k,l,m的重数分别为2、4、1、1。
 虽然交叉熵损失函数通常用于测量概率分布之间的距离,但在这里可能不是一个好的选择。一方面,规范化
虽然交叉熵损失函数通常用于测量概率分布之间的距离,但在这里可能不是一个好的选择。一方面,规范化的代价在于整个词表的求和,这在计算上可能非常昂贵。另一方面,来自大型语料库的大量罕见事件往往被交叉熵损失建模,从而赋予过多的权重。
2.GloVe模型
有鉴于此,GloVe模型基于平方损失 (Pennington et al., 2014)对跳元模型做了三个修改:

应该强调的是,当词出现在词
的上下文窗口时,词wj也出现在词
的上下文窗口。因此,
。与拟合非对称条件概率
的word2vec不同,GloVe拟合对称概率
。因此,在GloVe模型中,任意词的中心词向量和上下文词向量在数学上是等价的。但在实际应用中,由于初始值不同,同一个词经过训练后,在这两个向量中可能得到不同的值:GloVe将它们相加作为输出向量。
3.从条件概率比值理解GloVe模型

我们可以观察到以下几点:
-
对于与“ice”相关但与“steam”无关的单词
,例如
-
对于与“steam”相关但与“ice”无关的单词
-
对于同时与“ice”和“steam”相关的单词
-
对于与“ice”和“steam”都不相关的单词
由此可见,共现概率的比值能够直观地表达词与词之间的关系。因此,我们可以设计三个词向量的函数来拟合这个比值。对于共现概率的比值,其中
是中心词,
和
是上下文词,我们希望使用某个函数f来拟合该比值:

通过对 (14.5.7)的加权平方误差的度量,得到了 (14.5.4)的GloVe损失函数。