2.1.9、Optimize--->Submit
调优工作主要从CPU、内存、网络开销和IO四方面入手
2.1.9.0、Spark On Yarn
2.1.9.0.1、Jar包管理及本地性调优
spark.yarn.jars :将jar包放到hdfs上,避免每次driver启动的时候都要进行jar包的分发。
yarn.nodemanager.localizer.cache.cleanip.interval-ms:配置缓存清理间隔,spark程序启动时,其他节点会根据上面的参数配置下载jar包并缓存在本地,如果下次启动的时候包没有变化,则直接使用。
2.1.9.0.2、调度模型调优
调优方面从以下几个层面考虑:
1、Yarn层面的队列资源分配
主要是在提交阶段,如果需要申请的资源大于当前yarn可用资源,那么应用程序就会一直处于等待状态,因此可以根据应用程序类型进行分类,提交到不同的队列上,或者调整队列的资源,或者调整分配策略(Fair/Capcaity/FIFO)
2、Executor端的资源分配
"常见的一个错误如:Container Killed By Yarn for exceeding memory limits. 42GB of 40GB physical memory used.Consider boosting spark.yarn.executor.memoryOverhead。"
从错误提示可以看出Executor端内存被用完了,可以按照提示的参数进行调整内存。
通常出现这种问题可以考虑以下几个方案(总体还是围绕着统一动态内存模型):
1、减少RDD缓存的操作(主要是减少存储内存占用)
2、增加Job的spark.storage.memroyFraction值(增大计算内存)
3、增加spark.yarn.executor.memoryOverhead (增大堆外内存)
3、Driver端的资源分配
1、当需要把结果返回到Driver端时,可以调大内存。
2、当使用yarn-cluster模式时,Driver运行在某个节点上,那么对应的JVM PermGen一般是默认值(82MB),很容易会出现栈溢出的问题,即出现PermGen Out Of Memory error Log信息。这个时候可以在spark-submit脚本中配置PermGen。
-conf spark.driver.extraJavaOptions="-XX:PermSize=128MB -XX:MaxPermSize=256MB"
2.1.9.1、Optimize--->Operator&RDD
2.1.9.1.1、使用mapPartitions或者mapPartitionWithIndex代替map操作。
2.1.9.1.2、使用foreachPartition代替foreach
2.1.9.1.3、使用coalesce代替repartition,避免不必要的shuffle
2.1.9.1.4、使用repartitionAndSortWithinPartitions取代repartition和sort联合操作
2.1.9.1.5、使用treeAggregate代替Aggregate
2.1.9.1.6、使用treeReduce代替reduce
treeReduce类似于treeAggregate,在Executor端进行多次Aggregate来减少Driver的计算开销
2.1.9.1.7、使用AggregateByKey代替groupByKey(减少不必要的数据传输,可提前进行combine)
2.1.9.1.8、RDD复用
原则:
1、避免创建重复的RDD
2、尽可能复用同一个RDD
3、对多次使用的RDD进行持久化(无需每次从源头开始计算)
2.1.9.1.9、广播变量使用
2.1.9.1.10、使用kryo代替默认的序列化器
spark提供了两个序列化类库
Java序列化:默认序列化,适用于所有实现了java.io.Serializable的类。可以通过继承java.io.Externalizable,能进一步控制序列化的性能。Java序列化比较灵活,但是速度较慢。
Kryo序列化:速度高且结果更加紧凑,但是不支持所有的类型,也就是说支持org.apache.spark.serializer的子类,但不支持java.io.serializable接口的类型,所以需要提前注册程序中所使用的类。对于网络密集型的应用,可以采用该种方式。
如通过System.setProperty("spark.serializer","spark.kryo.serializer")
当然如果不使用kryo序列化器的话,也是可以的,但是每个对象实例的序列化结果都会包含一份完整的类名,有点浪费空间。
2.1.9.1.11、使用FastUtil优化JVM数据格式解析(性能上提升不会很大)
FastUtil扩展了Java标准集合框架(Map,List,Set...)的类库,提供了特殊类型的map,set,list和queue。
FastUtil提供了更小的内存占用,更快的存取速度。可以使用FastUtil提供的集合类代替JDK原生的集合。除了对象和原始类型为元素的集合外,FastUtil还提供了引用类型的支持,但是对引用类型是使用=来进行比较的,而不是equals方法。
使用场景:
1、如果算子函数使用了外部变量,
一:可以使用广播变量进行优化;
二:可以使用kryo序列化器,提升序列化性能和效率
三:如果外部变量是某种比较大的集合,那么可以使用FastUtil改写外部变量,即从源头上减少内存占用,然后再结合第一、二两个手段进行优化;
2、如果在算子函数内的计算逻辑里面,要创建比较大的Map,List等集合,那么会占用比较大的内存空间,也可能会涉及到遍历、存取等操作;这个时候可以考虑使用FastUtil类库进行重写,在一定程度上减少Task创建出来的集合类型的内存占用,避免Executor内存爆满,频繁GC
2.1.9.1.12、Persist和Checkpoint
Persist操作根据缓存数据量情况以及内存大小来选择存储策略。
在执行checkpoint之前先对RDD进行persist操作,主要是因为checkpoint会触发一个job,如果执行checkpoint的rdd是由其他rdd经过计算转换过来的,而如果没有persist这个rdd的话,那么就又要从头开始计算这个rdd,也就是做了很多重复性的计算工作。
因此建议先perist RDD,在执行checkpoint的时候会丢弃该RDD之前的依赖关系,使得该rdd作为顶层父RDD。
2.1.9.1.13、序列化问题
在spark应用程序中如果引用了无法序列化的变量或者类的话,会遇到"org.apache.spark.SparkException:Task not serializable"问题,对于变量只需要标注@transient注解即可,即表示不需要进行序列化;对于类的话需要进行序列化(extends Serializable)
2.1.9.2、Optimize--->Parallelity&Resouce allocate
2.1.9.2.1、内存示意图
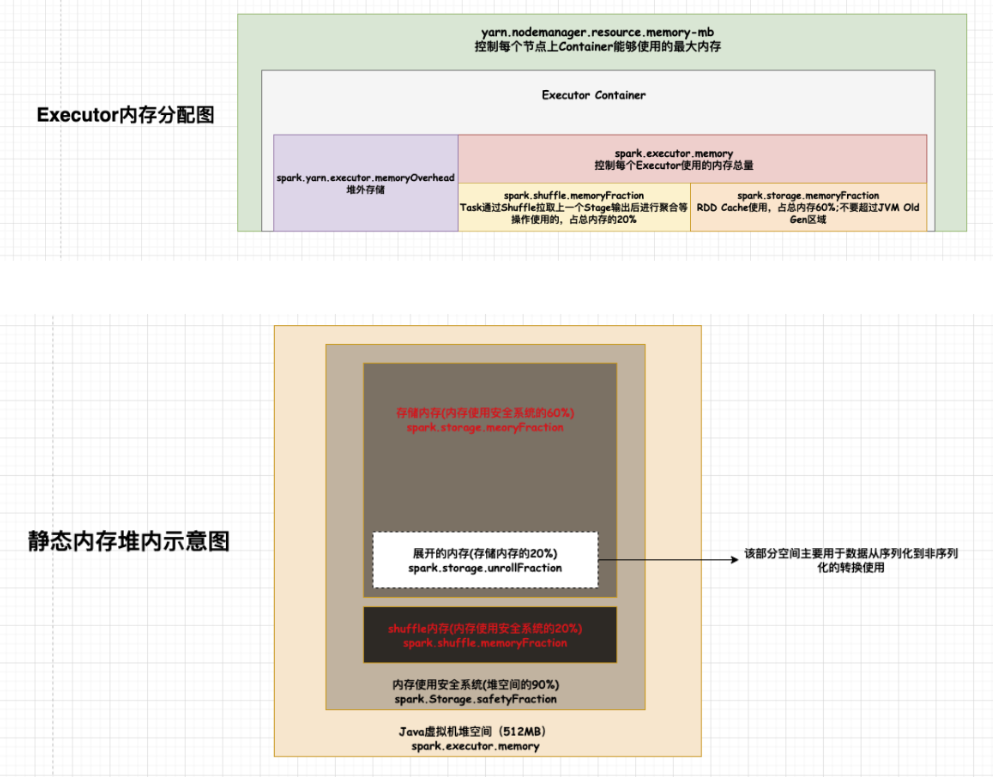
每个Executor支持的Task的并行处理数量取决于其Cpu Core的数量。
例如通过spark-submit或者spark-shell启动提交spark的时候,指定以下参数:--num-executors 10 --executor-cores 2
那么10指的是启动executor的数量;而2指的是每个executor运行的核数,也就是Executor能最大运行的并行数,对应每个核共享Executor分配到的总内存。
2.1.9.2.2、并行度
并行度就是spark作业中,每个Stage的同时运行Task数量。
合理的设置并行度,能够有效利用集群资源,避免造成浪费或者计算不足。适当提高并行度,可以减少task处理的数据量,同时也可以减少轮询的次数。
Task数量至少设置成和spark应用程序申请的总cpu core数量相同,例如一共150个Cpu Core,那么分配150个Task一起运行,差不多同一时间运行完毕。
当然官方推荐的是把Task数量设置成spark程序总cpu core数量的2~3倍。也就是说150个cpu core,那么基本上要设置task数量为300~500
2.1.9.3、Optimize--->Mapper/Reducer
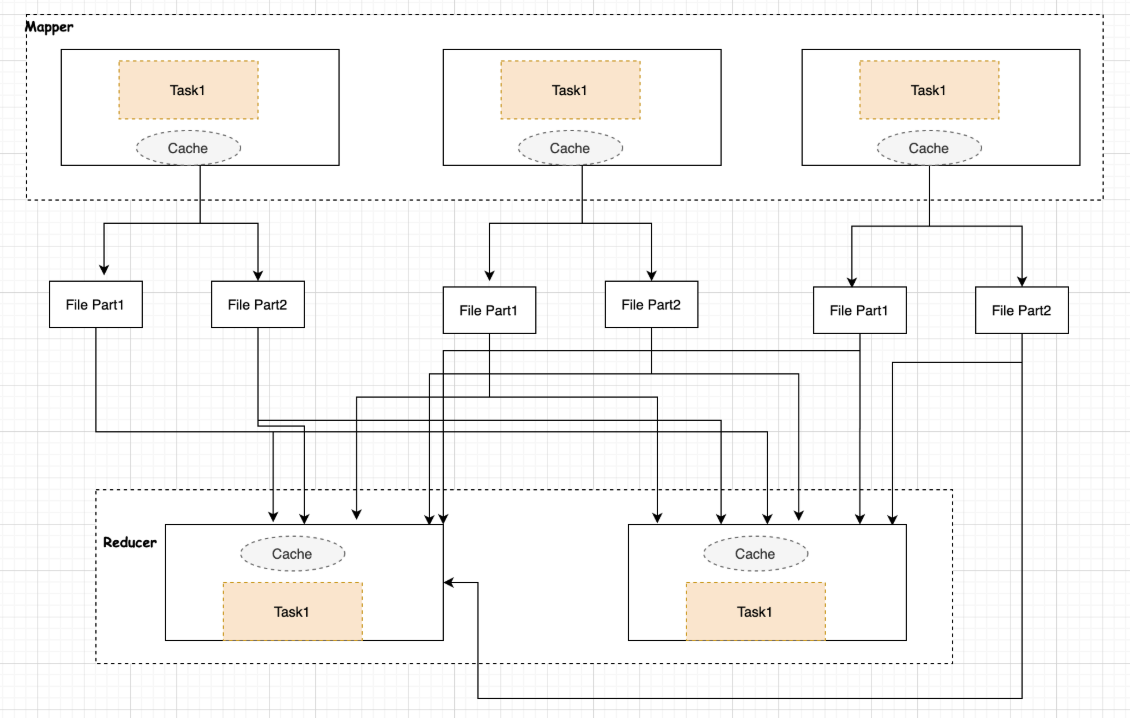
2.1.9.3.1、Mapper端调优
Spark Shuffle分为两部分:Mapper端和Reducer端。数据在传输到Reducer端的时候先进行Mapper端的处理,Mapper端会有一个缓存,数据会从缓存写入文件中,Mapper端的缓存根据Reducer的需求,将数据分成不同的部分,然后Reducer端抓取属于自己的数据进行reduce操作。那么在reducer端也有一个缓存,用来定义逻辑运行的地方。
由此可见对于Mapper端的内存性能调优主要在于缓存,通过log和web ui界面来观察不同的Stage分布在什么地方,读写的数据量等等来设置缓存大小,如果mapper端的缓存设置不合理的话,那么会频繁的往本地磁盘写数据,就会产生大量的磁盘IO操作。
Mapper端的缓存参数spark.shuffle.file.buffer的默认大小是32KB,用户根据数量和并发量来适当调整该参数,避免频繁发生磁盘IO。
2.1.9.3.2、Reducer端调优
spark shuffle中的reducer阶段获取数据,并不是等Mapper端全部结束之后才抓取数据,而是一边进行shuffle,一边抓取处理数据,Reducer在抓取的数据中间有一个缓存,类似于Java NIO方式,通过创建一个缓存区ByteBuffer,从通道把数据读入到缓冲区中,然后交由task进行处理。
在这里需要有三点可以作为性能调优的地方:
1、reducer端的代码基于缓存层处理数据,默认配置是为每个task配置48MB的缓存,设置参数为spark.reducer.maxSizeInFlight。也就是说可以调整缓存层的大小。当出现OOM的情况,那么就需要调小缓存层,因为占用的缓存越多,会产生大量的对象,从而出现OOM。同时如果调小缓存层,那么向Mapper端提取的次数就会变多,性能也就会降低,但相对而言首先思考的是应该先让程序跑起来,然后再考虑增加Executor内存,或者调大缓存来对性能层面进一步的改善。
2、在业务逻辑处理运行这一层,如果空间分配不够,那么数据会溢写到磁盘上,这个时候就会出现磁盘IO,也会导致不安全(读写故障),基于这种情况可以调节spark.shuffle.memoryFraction(reducer端默认的task堆大小是20%的空间),从20%调节到30%,40%等。调节越大,那么溢写的次数就会越少。
3、当Reducer端根据Driver提供的信息到Mapper端指定的位置获取数据的时候,会先定位所在的文件,但如果Mapper端出现GC那么就会无法响应数据的请求,那么就会出现shuffle file not found的问题。这个时候可以调节以下两个参数:
spark.shuffle.io.maxRetries=30;
spark.shuffle.io.retryWait=30s;