2.1.9.4、Optimize--->JVM On Compute
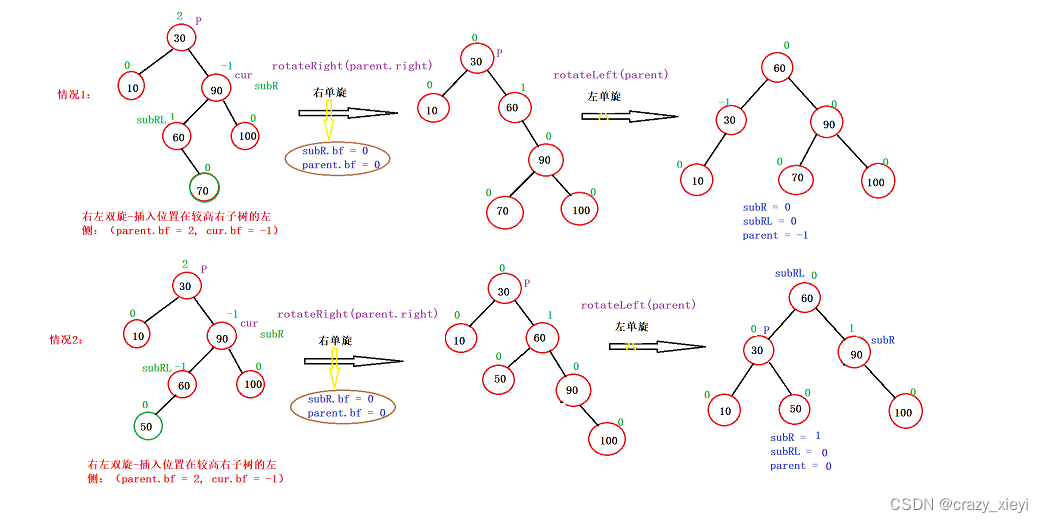
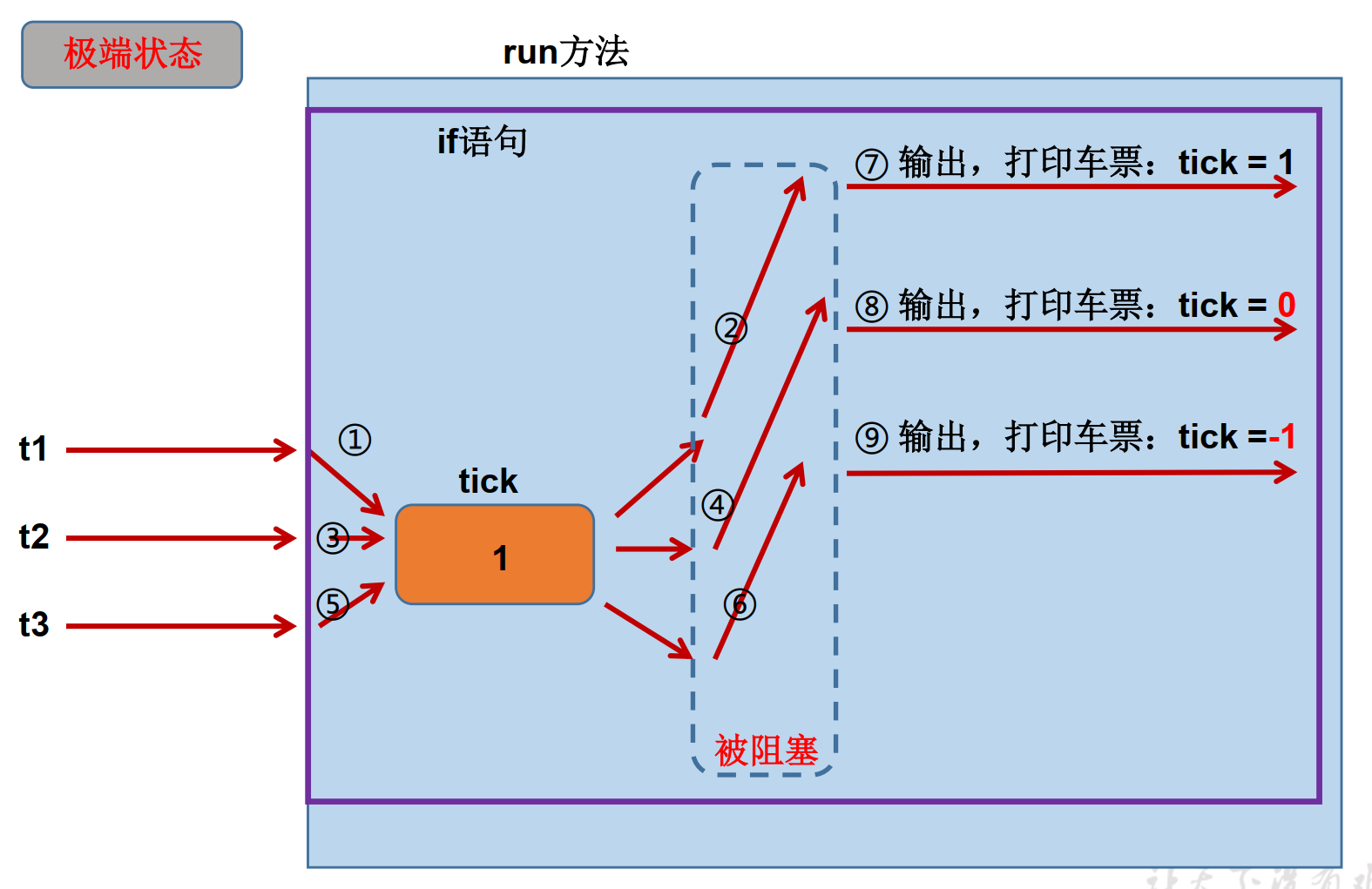
首要的一个问题就是GC,那么先来了解下其原理:
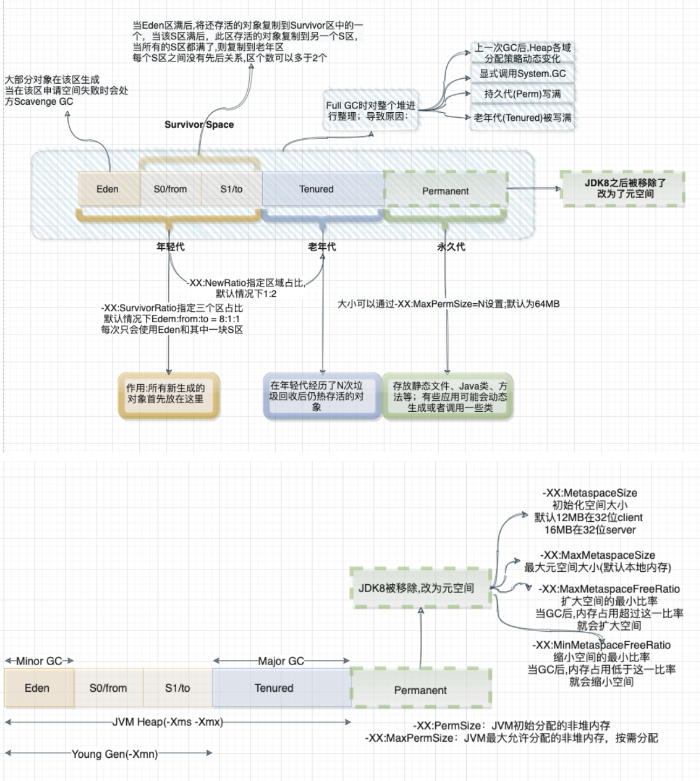
1、内存管理其实就是对象的管理,包括对象的分配和释放,如果显式的释放对象,只要把该对象赋值为null,即该对象变为不可达.GC将负责回收这些不可达对象的内存空间。
2、GC采用有向图的方式记录并管理堆中的所有对象,通过这些方式来确定哪些对象是可达的,哪些对象是不可达的。根据上图的JVM内存分配来看,当Eden满了之后,一个小型的GC将会被触发,Eden和Survivor1中幸存的仍被使用的对象被复制到Survivor2中。同时Survivor1和Survivor2区域进行交换,当一个对象生存的时间足够长,或者Survivor2满了,那么就会把存活的对象移到Old代,当Old空间快满的时候,这个时候会触发一个Full GC.
根据以上简单对GC的回顾,Spark GC调优的目的是确保Old代只存生命周期长的RDD,Young 代只保存短生命周期的对象,尽量避免发生Full GC。
那么这里梳理一下spark中关于Jvm的一些参数调优以及一些调优步骤:
1、针对MetaSpace:
-XX:MetaspaceSize:初始化元空间的大小
-XX:MaxMetaspaceSize:最大元空间大小
-XX:MinMetaspaceFreeRatio:扩大空间的最小比率,当GC后,内存占用超过这一比率后,就会扩大空间
-XX:MaxMetaspaceFreeRatio:缩小空间的最小比率,当GC后,内存占用低于这一比率,就会缩小空间。
默认的Metaspace只会受限于本地内存大小,当Metaspace达到MetaSpaceSize的当前大小时,就会触发GC.
2、GC查看步骤:
2.1、首先查看GC统计日志观察GC启动次数是否太多,可以给JVM设置参数-verbose:GC -XX:+PrintGCDetails,那么就可以在Worker日志中看到每次GC花费的时间;如果某个任务在结束之前,多次发生了Full GC,那么说明执行该任务的内存不够
spark-submit --name "app-name" \
--master local[4] \
--conf spark.shuffle.spill=false \
--conf "spark.executor.extraJavaOptions=-XX:+PrintGCDetails -XX:+PrintGCTimeStamps" \
jar_name.jar
2.2、如果GC信息显示,Old代空间快满了,那么可以降低spark.memory.storageFraction来减少RDD缓存占用的内存。先不要考虑执行性能问题,先让程序跑起来再说
2.3、如果Major GC比较少,但是Minor GC比较多,可以把Eden内存调大些。
3、计算内存和存储内存调整(钨丝计划就是专门来解决JVM性能问题的)
两者之间没有硬性界限,可以相互借用空间,通过参数spark.memory.fraction(默认0.75)来设置整个堆空间的比例。
spark.storage.memoryFraction:设置RDD持久化数据在Executor内存能占用的比例,默认是0.6;如果作业有较多的RDD持久化的话,那么该参数值可以调高些,避免内存不够缓存所有的数据,导致溢写磁盘;如果作业中shuffle类操作比较多,且频繁发生GC,那么可以适当调低该参数值。
spark.yarn.executor.memoryoverhead:如果数据量很大,导致Stage内存溢出,导致后面的Stage无法获取数据,如出现Shuffle file not found、Executor Task lost、Out Of Memory等问题时,可以调整该参数增大堆外内存。
spark.core.connection.ack.wait.timeout:当然对于not found ,file lost问题也可能是因为某些task去其他节点上拉取数据,而该节点正好正在进行GC,导致连接超时(默认60s),那么可以试着调大该参数值。
spark.shuffle.memoryFraction:设置shuffle过程一个task拉取上一个Stage的task输出后,进行聚合操作时能够使用Executor内存的比例,默认是0.2;如果shuffle使用的内存超过了这个限制,那么就会把多余的数据溢写到磁盘中,如果作业中RDD持久化的操作比较少的话,shuffle比较多的话,那么可以调大该值,降低缓存内存占用比例。
2.1.9.5、Optimize--->Shuffle On Compute
更详细的参数配置见2.1.8.6部分。
1、使用Broadcast实现Mapper端Shuffle。
也就是常说的MapJoin,即将较小的RDD进行广播到Executor上,让该Executor上的所有Task都共享该数据
2、Shuffle传输过程中的序列化和压缩。
序列化和压缩
spark.serializer=org.apache.spark.serializer.KryoSerializer
spark.shuffle.compress=true
spark.shuffle.spill.compress=true
spark.io.compression.codec=snappy
使用KryoSerializer的原因是因为其支持relocation,也就是说在把对象进行序列化之后进行排序,这种排序效果和先对数据排序再序列化是一样的。这个属性会在UnsafeShuffleWriter进行排序中用到。
3、为了避免Spark下的JVM GC可能会导致Shuffle拉取文件失败的问题,可以使用以下措施:
3.1、调整获取Shuffle数据的重试次数,默认是3次
3.2、调整获取Shuffle数据重试间隔,通过spark.shuffle.io.retryWait参数配置,默认为5s
3.3、适当增大reduce端的缓存空间,否则会spill到磁盘,同时也减少GC次数,可以通过spark.reducer.maxSizeInFlight参数配置
3.4、ShuffleMapTask端也可以增大Map任务写缓存,可以通过spark.shuffle.file.buffer,默认为32k
3.5、可以适当调大计算内存,减少溢写磁盘。
2.1.9.6、Optimize---->Data Skew
spark层面的数据倾斜定位可以通过以下几个方面:
1、通过spark web ui界面,查看每个Stage下的每个Task运行的数据量大小
2、通过Log日志分析定位是在哪个Stage中出现了倾斜,然后再定位到具体的Shuffle代码
3、代码走读,重点看Join,各种byKey的关键性代码
4、数据特征分布分析
针对数据倾斜有以下几种解决手段:
2.1.9.6.1、聚合过滤导致倾斜的Keys
可过滤针对业务逻辑中不需要的倾斜数据,例如无效数值
2.1.9.6.2、提高并行度
其主要思想在于把一个Task处理的数据量拆分为多份给不同的task进行处理,进而减轻Task的压力,其本质在于数据的分区策略。
例如
1、通过repartition或者coalesce进行重分区
2、对外部数据读取设置最小分区数
3、在使用涉及到shuffle类算子时,可以显示指定分区数(默认spark会推导分区数)
4、设置默认spark.default.parallelism并行度
2.1.9.6.3、随机Key二次聚合
使用场景:对于各种byKey操作,可以将每个key通过加上随机数前缀进行拆分,先做局部聚合,然后将随机数拆掉在做全局聚合。
2.1.9.6.4、MapJoin
使用场景:两个RDD的数据量,其中一个RDD的数据量特别小,可以放到内存中。
2.1.9.6.5、采样倾斜Key单独处理
使用场景:两个RDD进行join操作,如果一个RDD倾斜严重,那么可以通过采样方式进行拆分,然后再分别和另外一个RDD进行join,最后把结果进行union。
2.1.9.6.6、随机Join
使用场景:两个RDD中的某一个Key或者某几个Key对应的数量很大,那么在Join的时候会发生倾斜。可以将RDD1中的一个或者几个Key加上随机数前缀,然后RDD2在相同的Key上做同样的处理。
2.1.9.6.7、扩容Join
使用场景:如果两个RDD的倾斜Key特别多,则可以将其中一个RDD的数据进行扩容N倍,另一个RDD的每条数据都打上一个n以内的随机前缀,最后进行join


![[WUSTCTF2020]level1 题解](https://img-blog.csdnimg.cn/7ec47b8d0ced4bf6aa8918c4687e57fa.png)