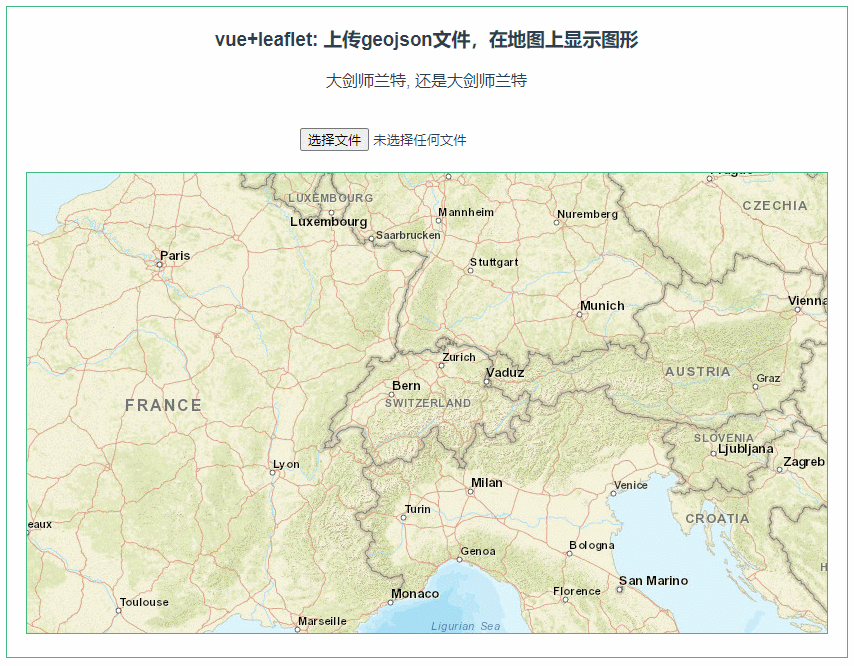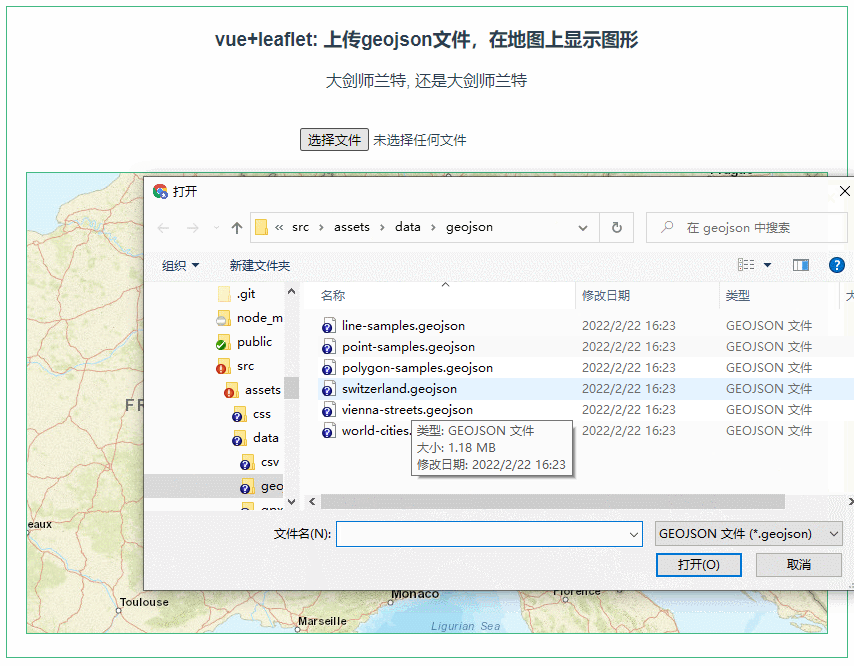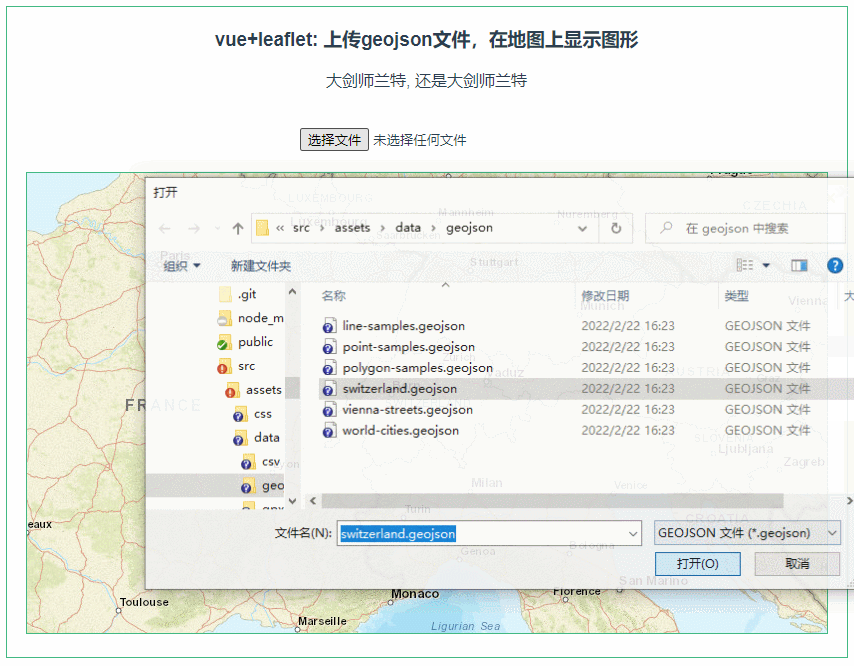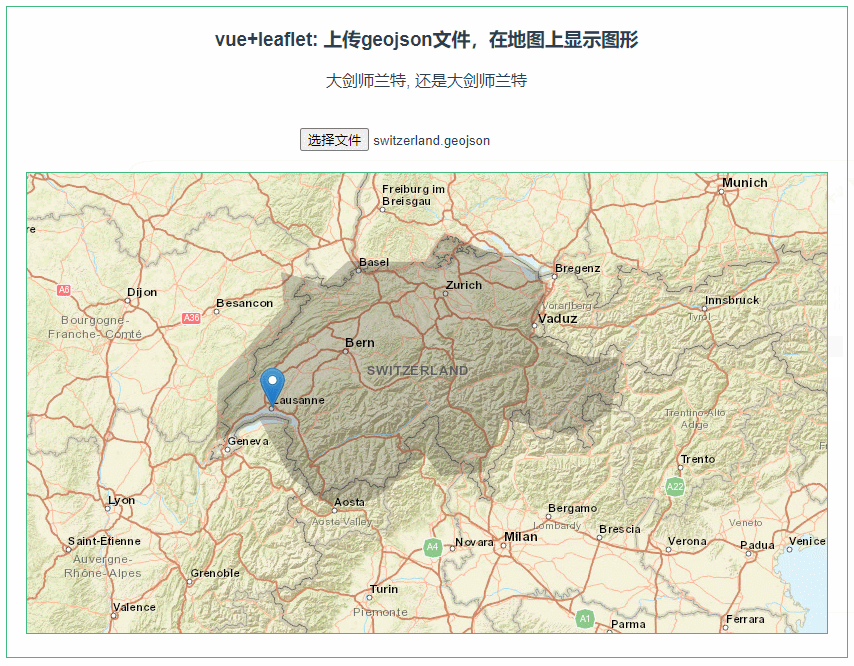
以下内容基于极客 蔡元楠老师的《大规模数据处理实战》做的笔记哈。感兴趣的去极客看蔡老师的课程即可。
MapReduce 缺点
高昂的维护成本
因为mapreduce模型只有map和reduce两个步骤。所以在处理复杂的架构的时候,需要协调多个map任务和多个reduce任务。
例如计算活跃在街头的美团外卖电动车数量,其中一个工作是处理所有美团外卖电动车。
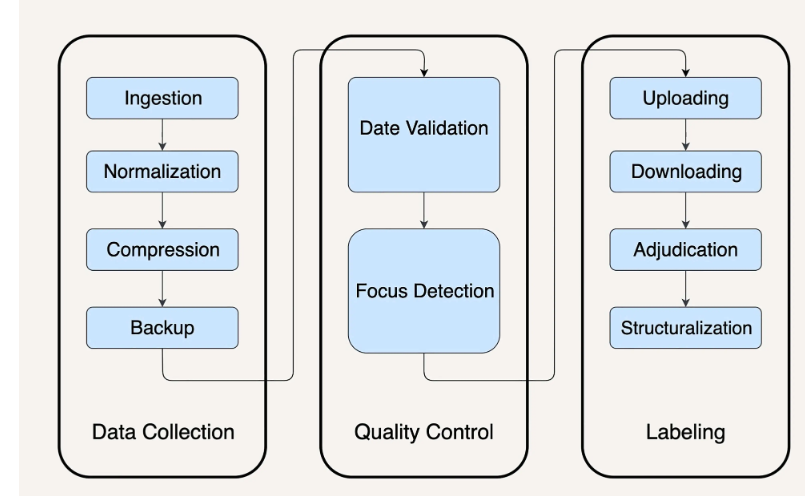
这个工作可以划分三部分:数据采集、数据质量控制、数据处理。
而其中的
数据采集又可以划分:1、数据导入:众包公司把拍的照片上传服务器或网盘,然后下载到你的存储系统 。2、数据统一化:不同外包公司的照片格式可能不一样 3、数据压缩:减少数据存储成本 4、数据备份:冗余降低风险。
数据质量控制可划分:1、数据时间有效性2、照片对焦检测
数据处理可以划分:1、数据标注问题上传:让你的标注者开始工作 。2、标注结果下载 3、标注异议处理 4、标注结果结构化。
这里不谈技术处理,观点意在阐述:真正的mapreduce场景都是复杂的,很多场景都是拥有多个子任务的,在应用场景中,每个任务都有可能出错,需要重试和异常处理的机制。所以维护起来成本很高。
配置复杂,时间性能低
谷歌些年做了一个测试,处理1pb数据,他们用了五年时间将一开始的处理时间12小时优化成了0.5小时,而大部分时间主要是优化mapreduce配置上。就算如此,mapreduce处理的结果也低于用户所期待。
设计思想:通用技术抽象模型让多步骤处理易于维护
举个例子,例如炒鸡蛋,用有向无环图表示这个问题的话,可以表示为如下:
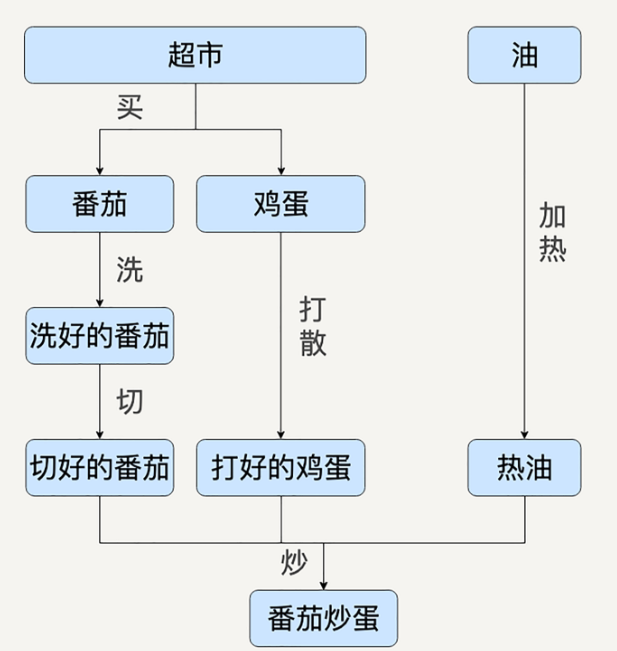
这里如果用mapreduce来实现的话,这个图中的每一个箭头都是一个独立的mapper和ruducer。同时为了协调这么多的mapper和reducer,又得做很多次的检查,检查上一个mr是否有错误,复杂的依赖关系会导致整个系统非常复杂。
这时候如果用有向图建模,那么图中的每一个节点都可以被抽象的表达成一种通用的数据集,每一条边都被表达通用的一个数据变换操作。如此用数据集和数据变换来描述复杂的数据处理流程,其依赖关系就不会那么复杂了。
设计思想:系统最好可以自动进行性能优化
mapreduce其中一个缺点就是配置太复杂。那么如果优化呢?那就尽量让人少做一点,机器多做一点(机器不容易犯错)。
例如上面的例子,在番茄炒蛋需求上多加了番茄炒牛肉。
那么有向无环图表示为:
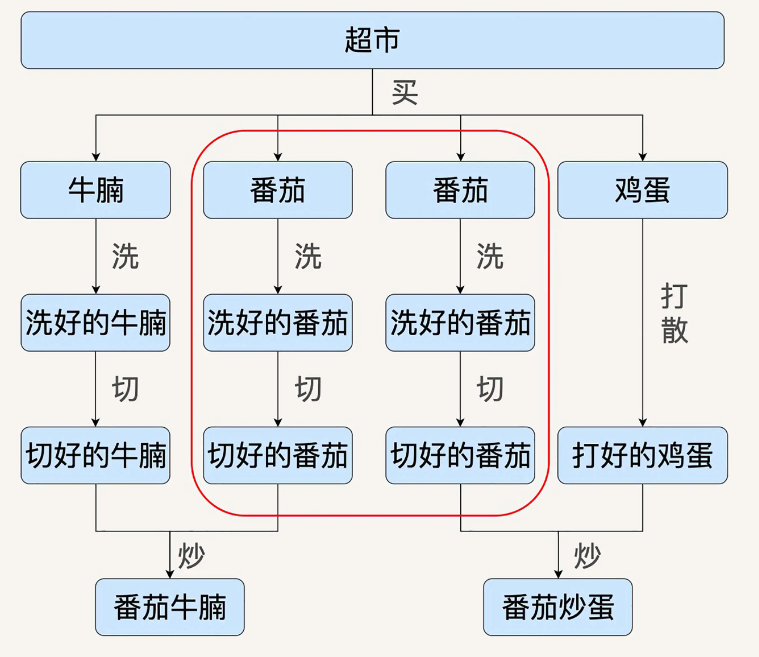
有图可见,两个需求中有一个通用的步骤,就算洗、切番茄。在理想的情况下,我们希望计算引擎可以自动发现两个需求中重复的数据处理流程,希望可以将其合并。
同样的,如果需求减少,不需要番茄炒蛋了,那么我们也希望计算引擎可以把鸡蛋处理流程等无关的数据操作优化去除。
另外一种自动的优化是计算资源的自动弹性分配。
例如洗番茄,今天需求洗100个番茄,明天需求洗1000个番茄,如果是手动配置资源,是很慢的。我们理想的系统是希望其能自动分配资源。
以上两个粗糙的例子是想阐述:我们希望数据处理系统能拥有自动优化步骤和分配资源的能力。
设计思想:把数据处理的描述语言和背后的计算引擎解耦分离
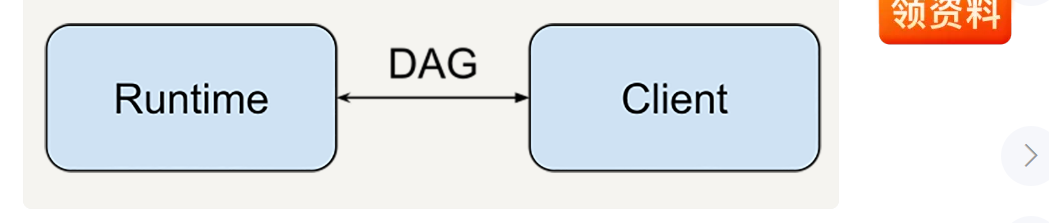
前两个设计思想中有一个很重要的设计,就是有向图。
在以上两个数据处理设计中,数据处理描述语言部分是可以和计算引擎分离的,而有向图则作为数据处理描述语言和计算引擎的中间连接协议。
例如tensorFlow,客户端可以用任何语言(例如c,python)描述,运行的时候,引擎runtime可以在任何地方运行,例如本地、cpu、tpu。
设计思想:需要统一处理批数据和流数据的编程模型
真正的业务系统通常的是流数据与批数据混合共生的。所以不管是流处理还是批处理,最好都要用统一的数据结构表示。编程api也要统一。
设计思想:需要在架构层面提供异常处理和数据监控能力
系统中最难处理的不是开发系统,而且异常处理。所以我们希望能设计出:一套拥有基本的数据监控能力的系统,能对数据处理的每一步提供自动的监控平台,比如ui网站。
小结
综上所述,我们需求的一个大数据处理框架基本模型图如下:
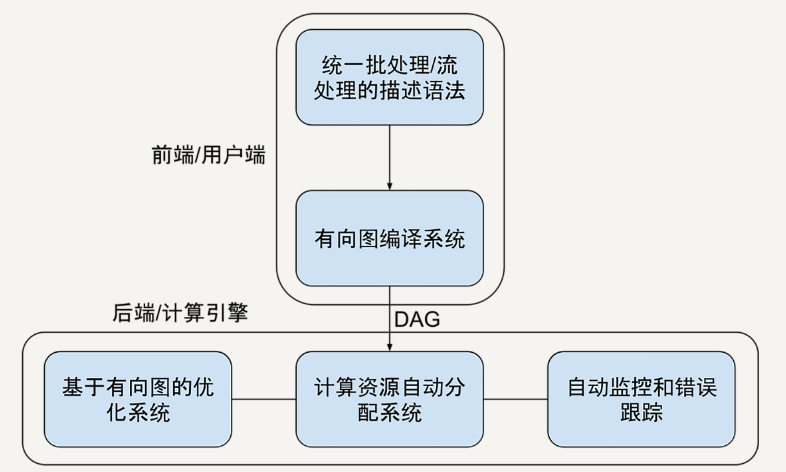
目前最接近这个思想的大数据处理框架应该是Spark和Flink。