前言
🚀 作者 :“程序员梨子”
🚀 **文章简介 **:本篇文章主要是写了opencv的人脸检测、猫脸检测小程序。
🚀 **文章源码免费获取 : 为了感谢每一个关注我的小可爱💓每篇文章的项目源码都是无
偿分享滴💓👇
点这里蓝色这行字体自取,需要什么源码记得说标题名字哈!私信我也可!
🚀 欢迎小伙伴们 点赞👍、收藏⭐、留言💬

正文
今天的案例分享会挑选几个咯!之后大家还喜欢爬虫的内容的话我就继续分享,不喜欢的话我
只能给大家分享其他的内容了🤡🤡
运行环境:
小编使用的环境:Python3、Pycharm社区版,第三方库下面有安装教程↓ 自带的不用安装。
模块安装:pip install -i https://pypi.douban.com/simple/+模块名 1)🎊疫情最新消息!爬取疫情最新数据并且保存在excel中并数据可视化,实战分享!
爬虫代码:
"""
import requests # 发送请求 第三方模块(安装)
import csv
# 表格的表头
with open('疫情数据.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(['name', 'confirmAdd', 'confirm', 'dead', 'heal', 'nowConfirm', 'nowConfirmCompare'])
# 赋值操作 x = 1, y = 2
url = 'https://api.inews.qq.com/newsqa/v1/automation/modules/list?modules=FAutoCountryConfirmAdd,WomWorld,WomAboard'
# 1. 发送请求
response = requests.post(url)
# <Response [200]>: 请求成功
# json是一种前后端数据交互的格式
# json_data: Python里面字典类型数据
# 2. 获取数据
json_data = response.json()
# json 结构化数据
# 非结构化数据 网页源代码 没有任何规律数据
# 定位网页源代码
# 3. 解析数据
womAboard = json_data['data']['WomAboard']
# 循环 执行重复代码
for wom in womAboard:
name = wom['name']
confirmAdd = wom['confirmAdd']
confirm = wom['confirm']
dead = wom['dead']
heal = wom['heal']
nowConfirm = wom['nowConfirm']
nowConfirmCompare = wom['nowConfirmCompare']
print(name, confirmAdd, confirm, dead, heal, nowConfirm, nowConfirmCompare)
# 4. 保存数据
# mode='a': 追加写入
with open('疫情数据.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow([name, confirmAdd, confirm, dead, heal, nowConfirm, nowConfirmCompare])![]() 数据分析代码:
数据分析代码:
"""
import requests # 发送请求 第三方模块(安装)
import csv
# 表格的表头
with open('疫情数据.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.writer(f)
csv_writer.writerow(['name', 'confirmAdd', 'confirm', 'dead', 'heal', 'nowConfirm', 'nowConfirmCompare'])
# 赋值操作 x = 1, y = 2
url = 'https://api.inews.qq.com/newsqa/v1/automation/modules/list?modules=FAutoCountryConfirmAdd,WomWorld,WomAboard'
# 1. 发送请求
response = requests.post(url)
# <Response [200]>: 请求成功
# json是一种前后端数据交互的格式
# json_data: Python里面字典类型数据
# 2. 获取数据
json_data = response.json()
# json 结构化数据
# 非结构化数据 网页源代码 没有任何规律数据
# 定位网页源代码
# 3. 解析数据
womAboard = json_data['data']['WomAboard']
# 循环 执行重复代码
for wom in womAboard:
name = wom['name']
confirmAdd = wom['confirmAdd']
confirm = wom['confirm']
dead = wom['dead']
heal = wom['heal']
nowConfirm = wom['nowConfirm']
nowConfirmCompare = wom['nowConfirmCompare']
print(name, confirmAdd, confirm, dead, heal, nowConfirm, nowConfirmCompare)
# 4. 保存数据
# mode='a': 追加写入
with open('疫情数据.csv', mode='a', encoding='utf-8', newline='') as f:
csv_writer = csv.wrier(f)
csv_writer.writerow([name, confirmAdd, confirm, dead, heal, nowConfirm, nowConfirmCompare])
 效果展示——
效果展示——
1)爬虫数据

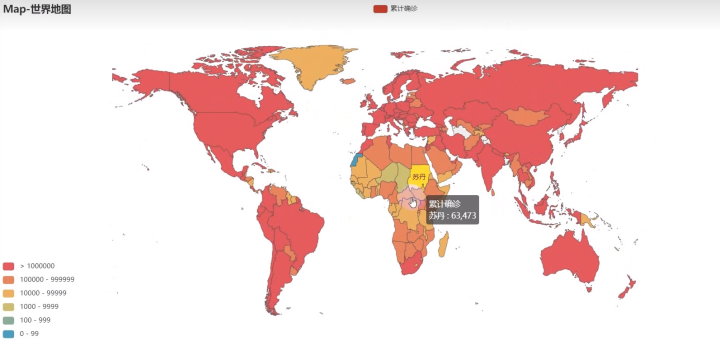
2)可视化图
初级图
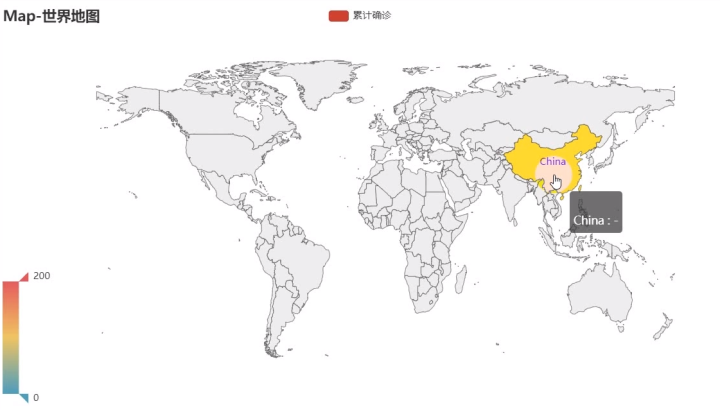
优化图
2)🎉Python爬取某宝商品数据,零基础也能学习的案例哦!
爬虫代码:
"""
import requests # 第三方模块
import re
import json
import csv
f = open('taobao.csv', mode='a', newline='', encoding='utf-8')
csv_writer = csv.writer(f)
csv_writer.writerow(['raw_title', 'view_price', 'item_loc', 'view_sales', 'comment_count', 'nick', 'detail_url'])
# 为什么要做伪装?
# 服务器肯定是不想给你数据的
# headers 构建成字典的
# 什么是字典呢? 字典是Python里面的一个数据容器{}, 列表[], 元组()
# {"":"", "":"", "":"", "":"", "":""}
headers = {
'cookie': 'cna=s/5FG78j/FUCAa8APiecOvNg; tracknick=tb668512329; thw=cn; enc=5QzxAFeTLCIaj4DdlClUUmCfmppq0mVmYnRM4MnjLLB4RjqMpvuUixwqmjkBvCn0Jgo9mK5a7GX5bTUVvYOjcKlG6Dcyihb49SfHSHh4p5w%3D; t=213a75d5f9b973a401f09b4b2ec812d7; _cc_=URm48syIZQ%3D%3D; sgcookie=E100uQe2yhvlDzLeFPm4%2BfB6tf%2BFsK%2FMda5f7206IxmCCrAvLuVZh8UBxD%2FJNv7XB8FEpm04JpToQ7vBpAnzq53Nd%2Be35XveHYnbr7vbksiQXTo%3D; uc3=nk2=F5RDKmf768KMcHQ%3D&vt3=F8dCv4of0HO1FFYJIBE%3D&lg2=U%2BGCWk%2F75gdr5Q%3D%3D&id2=UUpgRsItw%2BrsB7dvyw%3D%3D; lgc=tb668512329; uc4=id4=0%40U2gqyZJ81Yv14cp6ZGKPzfQ18kyJG1rt&nk4=0%40FY4I6earzOZXUhcMjuCe8tiaY1Stpw%3D%3D; mt=ci=-1_0; _tb_token_=43f7e76e367f; _m_h5_tk=d9ed16b25f4b5df7ba6b499f4a885508_1667573369978; _m_h5_tk_enc=2b5734c43a982a947a8c43805ca6f756; cookie2=119afda486ca9dece1dd8cddb6af1ebd; xlly_s=1; uc1=cookie14=UoeyCURCeMBd0w%3D%3D; JSESSIONID=80D01100395EA2871F8B9EA1E137609F; l=eBrY7YtILf1CV5oyBO5ahurza77O2QOb8sPzaNbMiInca6BRtKdgnNCUVupDSdtjgtCXWetzmSrNYdEvJp4daxDDBexrCyCoExvO.; tfstk=cz9NBFt5MAHZ8nKxy9X2UmYzO95OagKMmJS5sqjsuG5gAlCGzsqgkMb1XMSbYrfG.; isg=BN7eZuVIMWxljWQk6kJ9bdpuL3Qgn6IZKkIfcIhkCyGEq3-F8C9tKT0Jo7enk5ox',
'referer': 'https://s.taobao.com/search?q=iPhone14&imgfile=&js=1&style=grid&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20221104&ie=utf8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
# https://s.taobao.com/search?q=%E7%A1%AC%E7%9B%98&imgfile=&js=1&style=grid&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20221104&ie=utf8&bcoffset=1&ntoffset=1&p4ppushleft=2%2C48&s=44
# https://s.taobao.com/search?q=%E7%A1%AC%E7%9B%98&imgfile=&js=1&style=grid&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20221104&ie=utf8&bcoffset=-2&ntoffset=-2&p4ppushleft=2%2C48&s=88
# https://s.taobao.com/search?q=%E7%A1%AC%E7%9B%98&imgfile=&js=1&style=grid&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20221104&ie=utf8&bcoffset=-5&ntoffset=-5&p4ppushleft=2%2C48&s=132
# https://s.taobao.com/search?q=%E7%A1%AC%E7%9B%98&imgfile=&js=1&style=grid&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20221104&ie=utf8&bcoffset=-8&ntoffset=-8&p4ppushleft=2%2C48&s=176
for page in range(1, 100):
print(f"----正在爬取第{page}页----")
s = page*44
coffset = 1-3*(page-1)
url = f'https://s.taobao.com/search?q=%E7%A1%AC%E7%9B%98&imgfile=&js=1&style=grid&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20221104&ie=utf8&bcoffset={coffset}&ntoffset={coffset}&p4ppushleft=2%2C48&s={s}'
# 1. 发送请求
response = requests.get(url=url, headers=headers)
# 2. 获取数据
html_data = response.text
# 3. 解析数据
# 结构化数据: json数据 字典取值
# 非结构化数据: 网页源代码 xpath/css/re
# g_page_config = (.*);
# (.*): 匹配任意内容 直到最后一个;结束
# 搜索功能高级用法
# 从html_data里面匹配出 符合 g_page_config = (.*); 规则的数据
# 以列表的形式返回给你 re.S 如果要匹配换行
g_page_config = re.findall('g_page_config = (.*);', html_data)[0]
# 从g_page_config里面取出所有的商品信息
json_dict = json.loads(g_page_config) # 字典格式数据了
# 字典的好处 好取值 方便取值
# xpath 提取标签属性或者文本内容
# xpath 不能提取字典
# {"键(拼音)":"值(字)", "A":"啊", "B":"不", "":"", "":""}['A']
auctions = json_dict["mods"]['itemlist']['data']['auctions'] # 列表
for auction in auctions:
raw_title = auction['raw_title']
view_price = auction['view_price']
item_loc = auction['item_loc']
view_sales = auction['view_sales']
comment_count = auction['comment_count']
nick = auction['nick']
detail_url = auction['detail_url']
print(raw_title, view_price, item_loc, view_sales, comment_count, nick, detail_url)
# 4. 保存数据
csv_writer.writerow([raw_title, view_price, item_loc, view_sales, comment_count, nick, detail_url])附带:某宝秒杀脚本案例
import datetime
import time
from selenium import webdriver
now = datetime.datetime.now().strftme('%Y-%m-%d %H:%M:%S.%f')
times = "2022-03-03 21:07:00.00000000"
driver = webdriver.Chrome(r'C:\Users\Tony\PycharmProjects\Module_Tony_Demo\Moudle_游戏源码锦集\chromedriver.exe')
driver.get("https://www.taobao.com")
time.sleep(3)
driver.find_element_by_link_text("亲,请登录").click()
print(f"请尽快扫码登录")
time.sleep(20)
driver.get("https://cart.taobao.com/cart.htm")
time.sleep(3)
# 是否全选购物车
while True:
try:
if driver.find_element_by_id("J_SelectAll1"):
driver.find_element_by_id("J_SelectAll1").click()
break
except:
print(f"找不到购买按钮")
while True:
# 获取时间
now = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S.%f')
print(now)
# 判断 -
if now > times:
# 结算
while True:
try:
if driver.find_element_by_link_text("结 算"):
print("here")
driver.find_element_by_link_text("结 算").click()
print(f"程序已将商品锁定,结算成功")
break
except :
pass
# 提交订单
while True:
try:
if driver.find_element_by_link_text('提交订单'):
driver.find_element_by_link_text('提交订单').click()
print(f"抢购成功,请尽快付款")
except:
print(f"恭喜,本程序已帮你抢到商品啦,您来支付吧")
break
time.sleep(0.01)
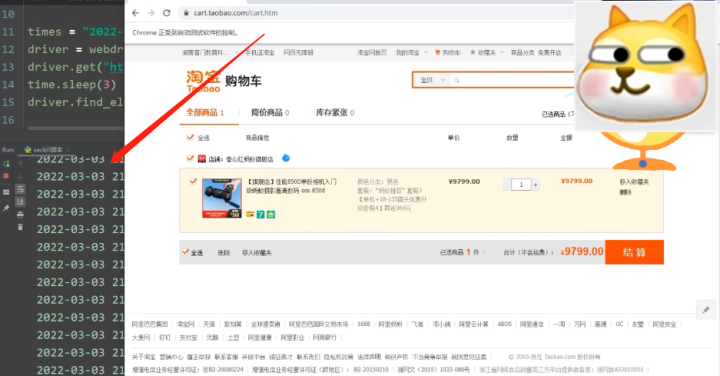
 效果展示——
效果展示——
1)抢购中
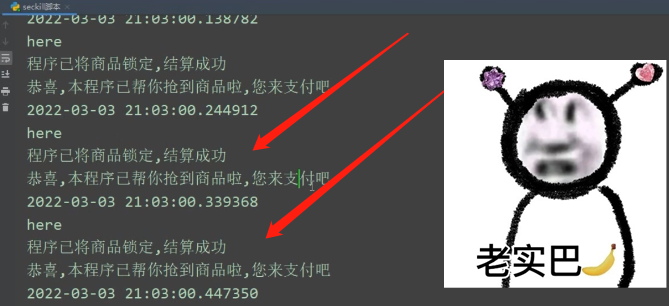
![]() 2)枪成功
2)枪成功
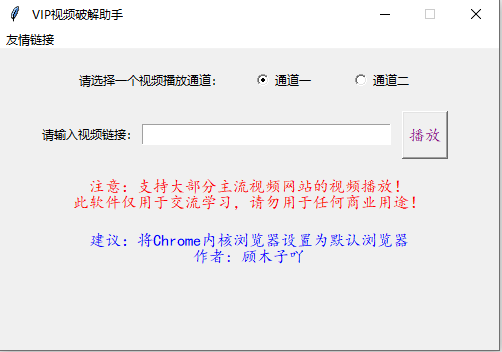
3)VIP视频解析小程序
# -*- coding:utf-8 -*-
# url解析
from urllib import parse
import tkinter.messagebox as msgbox
import tkinter as tk
import webbrowser
import re
class APP:
def __init__(self, width=500, height=300):
self.w = width
self.h = height
self.title = ' VIP视频破解助手'
self.root = tk.Tk(className=self.title)
# 定义button控件上的文字
self.url = tk.StringVar()
# 定义选择哪个播放源
self.v = tk.IntVar()
# 默认为1
self.v.set(1)
# Frame空间
frame_1 = tk.Frame(self.root)
frame_2 = tk.Frame(self.root)
frame_3 = tk.Frame(self.root)
# Menu菜单
menu = tk.Menu(self.root)
self.root.config(menu=menu)
moviemenu = tk.Menu(menu, tearoff=0)
menu.add_cascade(label='友情链接', menu=moviemenu)
# 各个网站链接
moviemenu.add_command(label= '腾讯视频', command = lambda: webbrowser.open('http://v.qq.com/'))
moviemenu.add_command(label='搜狐视频', command=lambda: webbrowser.open('http://tv.sohu.com/'))
moviemenu.add_command(label='芒果TV', command=lambda: webbrowser.open('http://www.mgtv.com/'))
moviemenu.add_command(label='爱奇艺', command=lambda: webbrowser.open('http://www.iqiyi.com/'))
moviemenu.add_command(label='PPTV', command=lambda: webbrowser.open('http://www.bilibili.com/'))
moviemenu.add_command(label='优酷', command=lambda: webbrowser.open('http://www.youku.com/'))
moviemenu.add_command(label='乐视', command=lambda: webbrowser.open('http://www.le.com/'))
moviemenu.add_command(label='土豆', command=lambda: webbrowser.open('http://www.tudou.com/'))
moviemenu.add_command(label='A站', command=lambda: webbrowser.open('http://www.acfun.tv/'))
moviemenu.add_command(label='B站', command=lambda: webbrowser.open('http://www.bilibili.com/'))
# 控件内容设置
group = tk.Label(frame_1, text='请选择一个视频播放通道:', padx=10, pady=10)
tb1 = tk.Radiobutton(frame_1, text='通道一', variable=self.v, value=1, width=10, height=3)
tb2 = tk.Radiobutton(frame_1, text='通道二', variable=self.v, value=2, width=10, height=3)
label1 = tk.Label(frame_2, text="请输入视频链接:")
entry = tk.Entry(frame_2, textvariable=self.url, highlightcolor='Fuchsia', highlightthickness=1, width=35)
label2 = tk.Label(frame_2, text=" ")
play = tk.Button(frame_2, text="播放", font=('楷体', 12), fg='Purple', width=2, height=1, command=self.video_play)
label3 = tk.Label(frame_2, text=" ")
label_explain = tk.Label(frame_3, fg='red', font=('楷体', 12),
text='\n注意:支持大部分主流视频网站的视频播放!\n此软件仅用于交流学习,请勿用于任何商业用途!')
label_warning = tk.Label(frame_3, fg='blue', font=('楷体', 12), text='\n建议:将Chrome内核浏览器设置为默认浏览器\n作者: 顾木子吖')
# 控件布局
frame_1.pack()
frame_2.pack()
frame_3.pack()
group.grid(row=0, column=0)
tb1.grid(row=0, column=1)
tb2.grid(row=0, column=2)
label1.grid(row=0, column=0)
entry.grid(row=0, column=1)
label2.grid(row=0, column=2)
play.grid(row=0, column=3, ipadx=10, ipady=10)
label3.grid(row=0, column=4)
label_explain.grid(row=1, column=0)
label_warning.grid(row=2, column=0)
"""
函数说明:视频播放
"""
def video_play(self):
# 视频解析网站地址
port_1 = 'http://www.wmxz.wang/video.php?url='
port_2 = 'http://www.vipjiexi.com/tong.php?url='
# 正则表达是判定是否为合法链接
if re.match(r'^https?:/{2}\w.+$', self.url.get()):
if self.v.get() == 1:
# 视频链接获取
ip = self.url.get()
# 视频链接加密
ip = parse.quote_plus(ip)
# 浏览器打开
webbrowser.open(port_1 + self.url.get())
elif self.v.get() == 2:
# 链接获取
ip = self.url.get()
# 链接加密
ip = parse.quote_plus(ip)
# 获取time、key、url
get_url = 'http://www.vipjiexi.com/x2/tong.php?url=%s' % ip
# 请求之后立刻打开
webbrowser.open(get_url)
else:
msgbox.showerror(title='错误', message='视频链接地址无效,请重新输入!')
"""
函数说明:tkinter窗口居中
"""
def center(self):
ws = self.root.winfo_screenwidth()
hs = self.root.winfo_screenheight()
x = int((ws / 2) - (self.w / 2))
y = int((hs / 2) - (self.h / 2))
self.root.geometry('{}x{}+{}+{}'.format(self.w, self.h, x, y))
"""
函数说明:loop等待用户事件
"""
def loop(self):
# 禁止修改窗口大小
self.root.reizable(False, False)
# 窗口居中
self.center()
self.root.mainloop()
if __name__ == '__main__':
app = APP() # 实例化APP对象
app.loop() # loop等待用户事件效果展示——

总结
案例的话都没有特别详细的,文章太长,大家需要的话有详细的视频跟代码的,需要的话可以
找我来拿哈!保证可以白嫖,只要是有视频代码的(部分没得)
要啥给啥哦~这里没有的案例实战大家也可以说说名字吼 比如 :12306抢票、火车票购票、链
家房源等等。之前写过超多的案例来着。大家需要的话自己来哈!
安啦!文章就写到这里,你们的支持是我最大的动力,记得三连哦!
关注小编获取更多精彩内容!记得点击传送门哈👇👇👇👇👇👇
记得三连哦! 如需打包好的完整源码+素材免费分享滴!!!传送门