libxlsxwriter库在windows系统下VS中存在中文输入报错问题。这在小白关于libxlsxwriter的第一篇博客libxlsxwriter初体验里有所阐述。当时小白给出的解决方案是将文件编码修改成不带签名的utf-8。后来在使用中,小白发现这样并没有完全解决问题。有的中文可以正常写入excel表中,有的中文却不能正常写入。这让人感到困惑和挫败。
1 问题原因
在libxlsxwriter初体验中,小白已经分析了,为什么libxlsxwriter库需要使用不带签名的utf-8编码。即由于excel文件中,用于中间解码的xml文件必须使用不带bom的utf-8编码才能正确解析。然而众所周知,windows系统的编码却是需要带bom的utf-8编码。
问题的原因正是由于这两种编码方式的矛盾。经过小白的检索,博客文章cocos2d-x中文显示问题中提到了:
有个叫wva的人遇到过类似问题,他向微软提交了此bug
http://connect.microsoft.com/VisualStudio/feedback/details/341454/compile-error-with-source-file-containing-utf8-strings-in-cjk-system-locale
根据Visual C++ Compiler Team员工的解释:
The compiler when faced with a source file that does not have a BOM the compiler reads ahead a certain distance into the file to see if it can detect any Unicode characters - it specifically looks for UTF-16 and UTF-16BE - if it doesn’t find either then it assumes that it has MBCS. I suspect that in this case that in this case it falls back to MBCS and this is what is causing the problem.
看见了吧,对于那些没有BOM的文件设计就是这样的。从语气上看,他们编译器小组也不打算修改设计。所以呢,在VC上使用“无签名的UTF-8”编码的文件,你就是在抱着一颗不定时炸弹玩耍。因为你永远都不敢确定哪些词能通过编译,哪些不能!
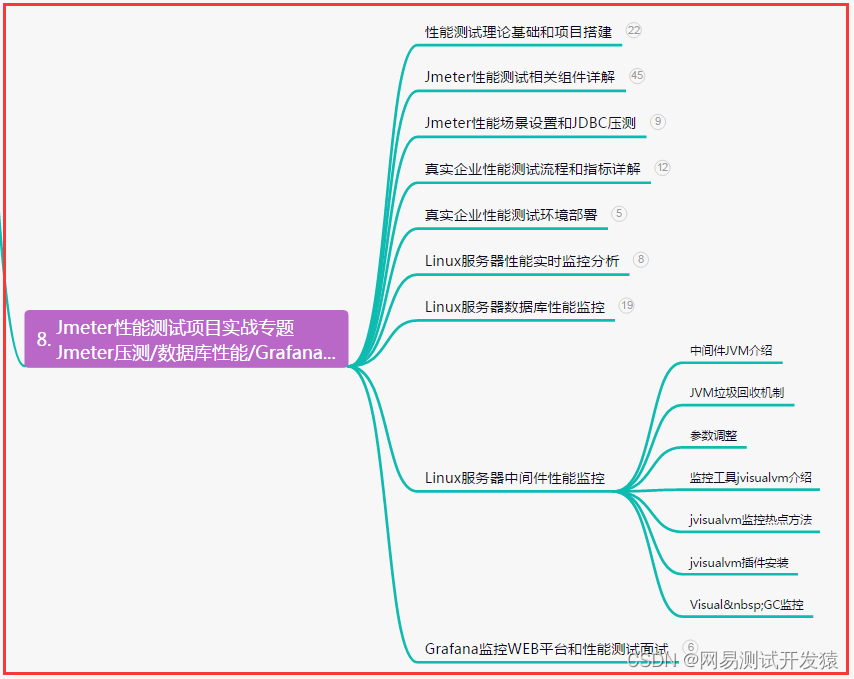
从这段描述中我们可以得知,在visual studio的C++编译器中,对于“无签名的UTF-8”编码的文件,无法确定哪些词能通过编译,而哪些词不能——事实上在小白的实际使用中,三个字的词(大量的中文人名)通常都不能通过编译。
这就给我们使用libxlsxwriter库造成了很大的阴影:不采用“无签名的utf-8”编码的话,在生成excel的过程中无法正确解码,若采用“无签名的utf-8”编码的话,在visual studio中编译时就要面临大量的中文组合可能无法通过编译的困境。
2 解决方案
没法子,此路不通,换一条路走。还是在cocos2d-x中文显示问题一文中,作者提到了“硬编码字符串”。这种方案对“跨平台代码”可能会产生一定的问题,因为硬编码可能就是与平台或编译器深度绑定的。但这对我们解决问题并无影响:我们就是要解决在windows平台上使用libxlsxwriter库自由写入中文的问题。
于是,找一下转码的文章,这里有一篇,也推荐给大家:
C/C++,字符串的UTF-8与GBK(或GB2312)编码转换
利用这里面的转码函数,我们给出以下方案:源文件编码仍然保持默认的GB2312。
/*
* Example of writing some data to a simple Excel file using libxlsxwriter.
*
* Copyright 2014-2021, John McNamara, jmcnamara@cpan.org
*
*/
#include "xlsxwriter.h"
#include <iostream>
#include <wchar.h>
#include <windows.h>
using std::string;
// 注意这个转换函数对头文件有所要求
string GBKToUTF8(const char* strGBK)
{
int len = MultiByteToWideChar(CP_ACP, 0, strGBK, -1, NULL, 0);
wchar_t* wstr = new wchar_t[len + 1];
memset(wstr, 0, len + 1);
MultiByteToWideChar(CP_ACP, 0, strGBK, -1, wstr, len);
len = WideCharToMultiByte(CP_UTF8, 0, wstr, -1, NULL, 0, NULL, NULL);
char* str = new char[len + 1];
memset(str, 0, len + 1);
WideCharToMultiByte(CP_UTF8, 0, wstr, -1, str, len, NULL, NULL);
string strTemp = str;
if (wstr) delete[] wstr;
if (str) delete[] str;
return strTemp;
}
int main() {
lxw_workbook* workbook = workbook_new("hello_world.xlsx");
lxw_worksheet* worksheet = workbook_add_worksheet(workbook, NULL);
worksheet_write_string(worksheet, 0, 0, "Hello", NULL);
worksheet_write_string(worksheet, 0, 2, GBKToUTF8("不出错").data(), NULL);
worksheet_write_number(worksheet, 1, 0, 123, NULL);
workbook_close(workbook);
return 0;
}
生成的结果如下所示:

虽然说这个解决方案总感觉有点让人觉得不舒服,但是出于实用主义,既然编译器的开发团队不想解决这个问题,那只能靠我们自己去绕路了。
小白还是觉得很好的,总算是找到了一种能自由使用中文的途径。