引言

2022年11月30日,OpenAI公布了他们的新产品:ChatGPT。随后ChatGPT火得一塌糊涂。通过b站搜索“ChatGPT”的结果:

搞学术的想着从它身上找点创新,吃瓜群众吃着这锅热瓜,想赚钱的眼睛贼亮🌟🌟🌟
由于OpenAI不支持对中国服务,就有人通过淘宝卖ChatGPT注册账号赚了不少钱(月销达到了3万)
我也好奇看看这个新玩意,于是我试着注册账号。。。
却发现:
不过最后呢,我还是成功了。
这篇博客聊一下我使用的情况、ChatGPT的原理以及存在的问题。
ChatGPT的使用
说实话,我用得有点晚了,之前一直忙七七八八的事,昨天才开始使用的,我登录进去之后出于礼貌,首先用英文发了句“hi”:
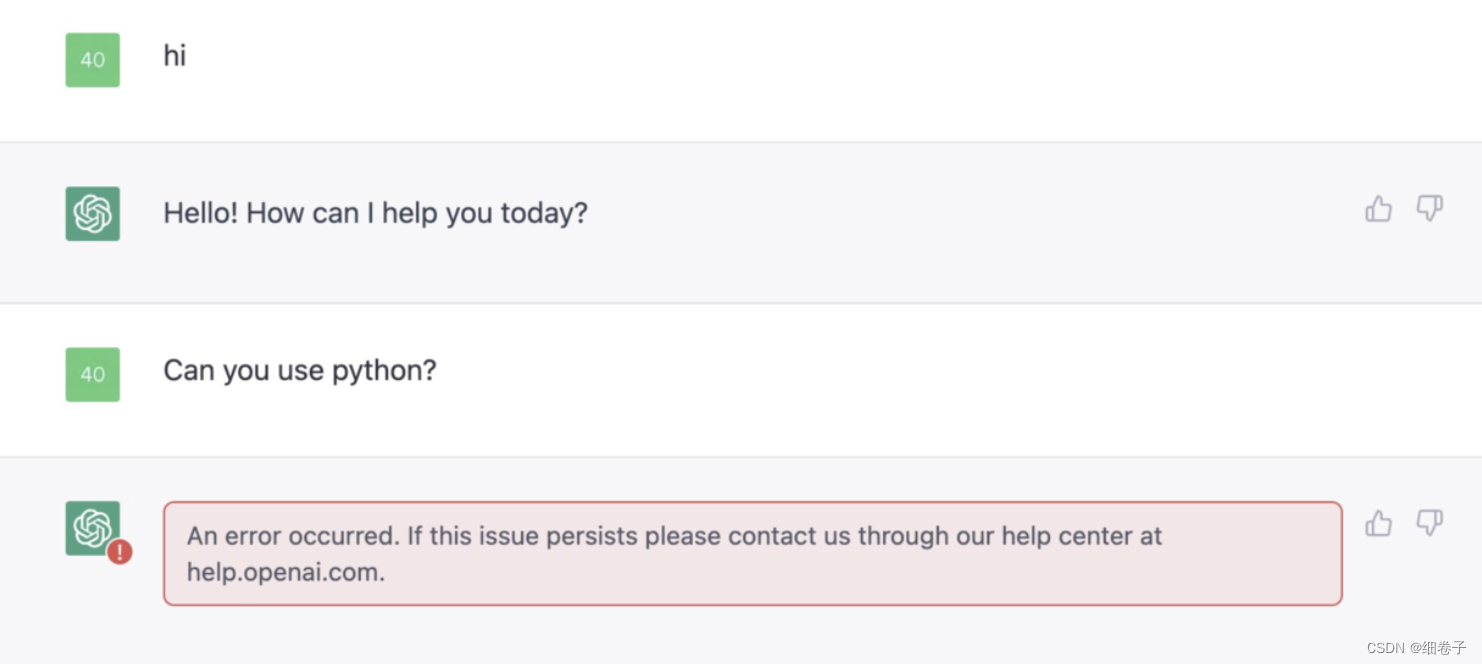
看它也挺有礼貌的回了我,但是,,发第二句就出错了。
可能是网络问题,也可能是它太火了,访问人数太多吧
我又试着用中文跟它聊天: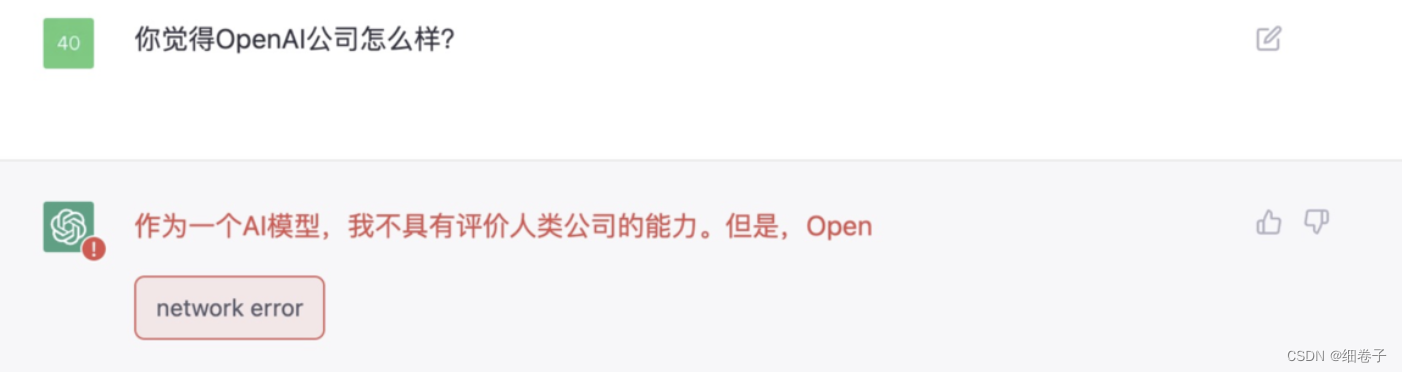
它回复中文了,我好开心,它是一个字一个字的回答的,因此我很期待的等啊等,,结果却报了个网络错误。(难过。。)
今天,我帮我老师也注册了个账号,她问了下ChatGPT关于糖尿病的问题,ChatGPT还是给出了挺好的回答:

我老师让它写段条件随机场的代码:
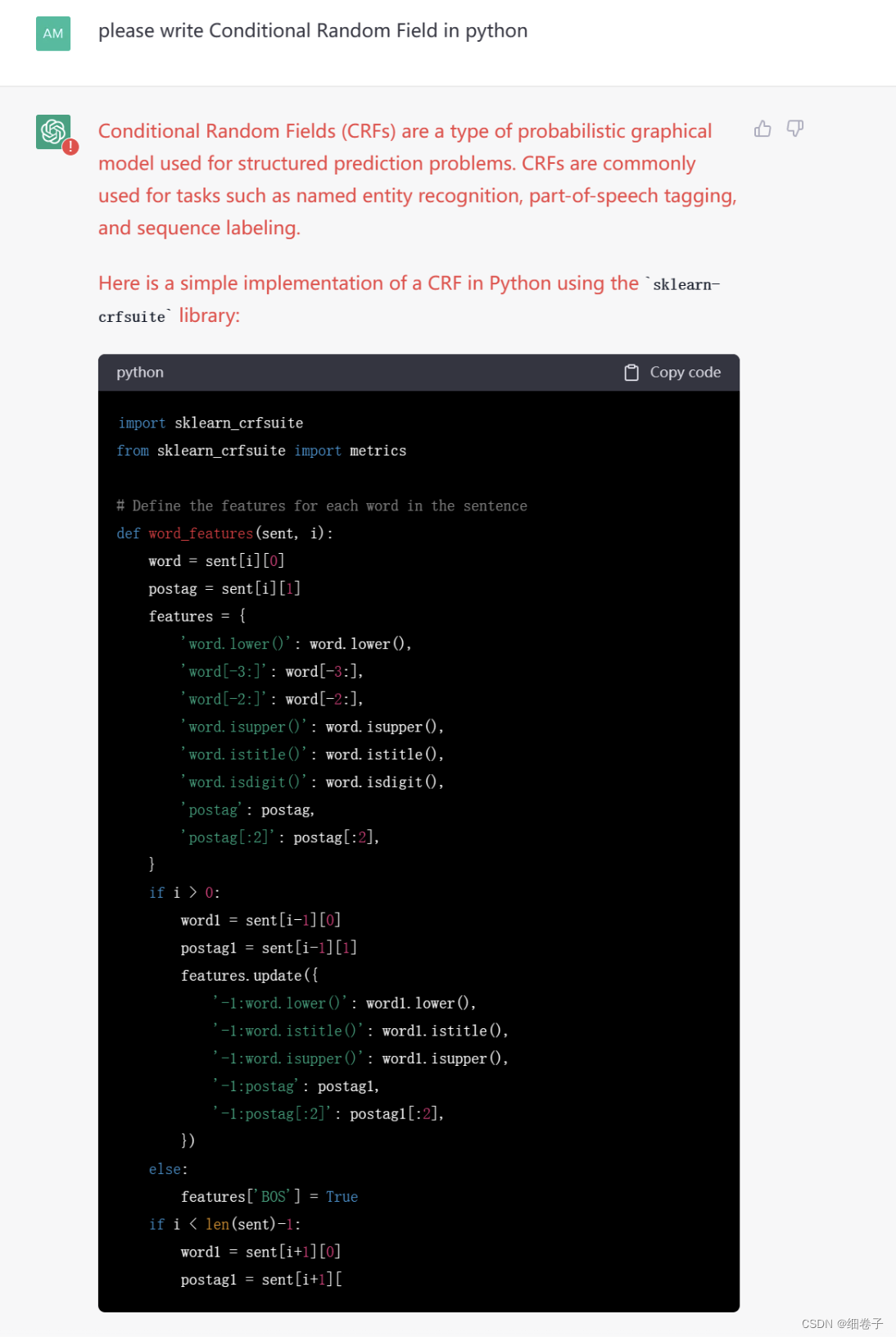
可惜写着写着掉线了
这里用的是英文,不过我在网上也看了很多中文的问题,也回答得挺好。
以上就是我的使用情况,总体来说还行,就是网络不太好总掉线
下面我讲一下它的一个简单原理吧~
由于ChatGPT的论文还没出来,也没有提供开源代码,我只能通过OpenAI的博客和相关研究等来了解ChatGPT了。
首先了解一下OpenAI公司
OpenAI

OpenAI是一个人工智能研究实验室,由营利组织 OpenAI LP 与母公司非营利组织 OpenAI Inc 组成,目的是促进和发展友好的人工智能,让更多人受益。
OpenAI 有两位创始人其中一位是埃隆·马斯克,这个大家应该都认识,就是特斯拉的CEO,提出造火箭带人类星际旅行的人,《硅谷钢铁侠》里说的就是他:

OpenAI 另一个创始人是原Y Combinator(美国著名创业孵化器)总裁山姆·阿尔特曼,美国斯坦福大学计算机系辍学生。
总的来说OpenAI是不差钱了,在ChatGPT之前研发的GPT3的训练就花了1200万美元。
OpenAI除了今天的主角之外,还有很多产品,
如:OpenAI曾跟Github合作,开发了智能编程助手 Copilot :

这里说的是“产品”,虽然OpenAI曾说自己是非营利机构,但从出产品的情况来看,有趋向营利的目的,例如:ChatGPT,很多人都关心它会不会开源,而目前它的论文还没出来,它的前一代InstructGPT没有开源,就连前前代GPT3都没开源,从趋势上判断,ChatGPT开源的可能性有点小了。
ChatGPT原理
要讲ChatGPT的原理,不得不向上追溯这样的一个链:
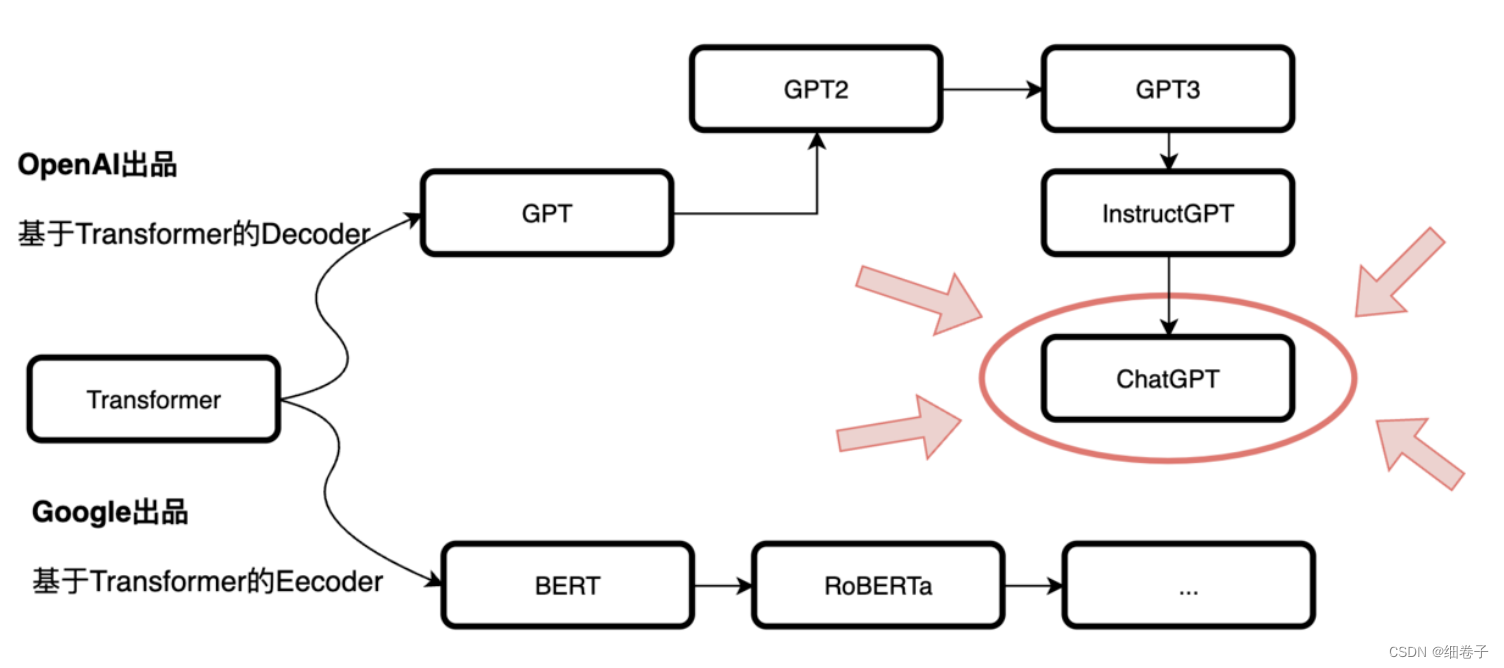
从上图来看,有两条链,上面那条是OpenAI,下面是Google,其根源还在于2017年Google技术提出的 Transformer[1]
而Transformer由Encoder和Decoder组成:
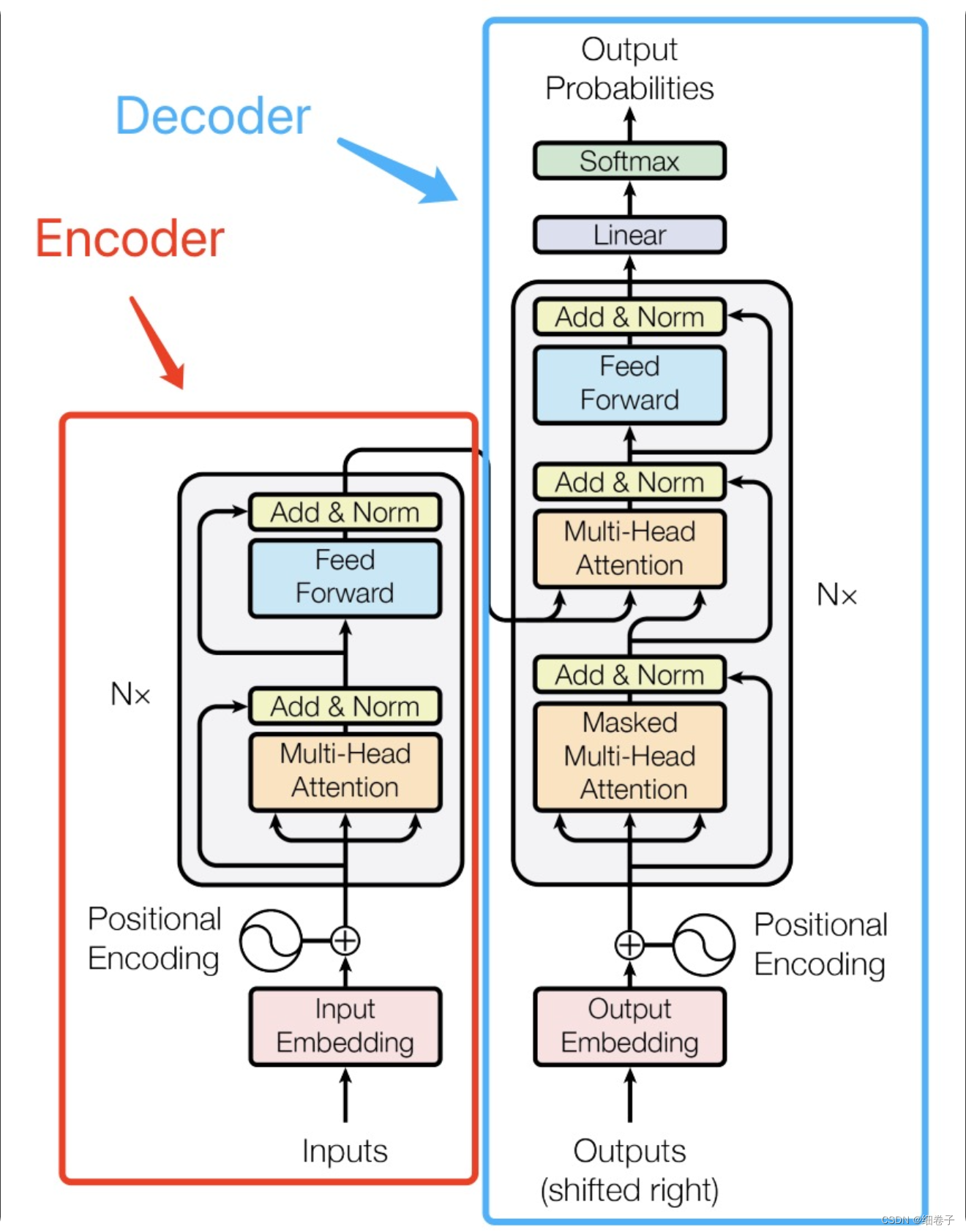
如果看起来复杂,请看下面这张图:
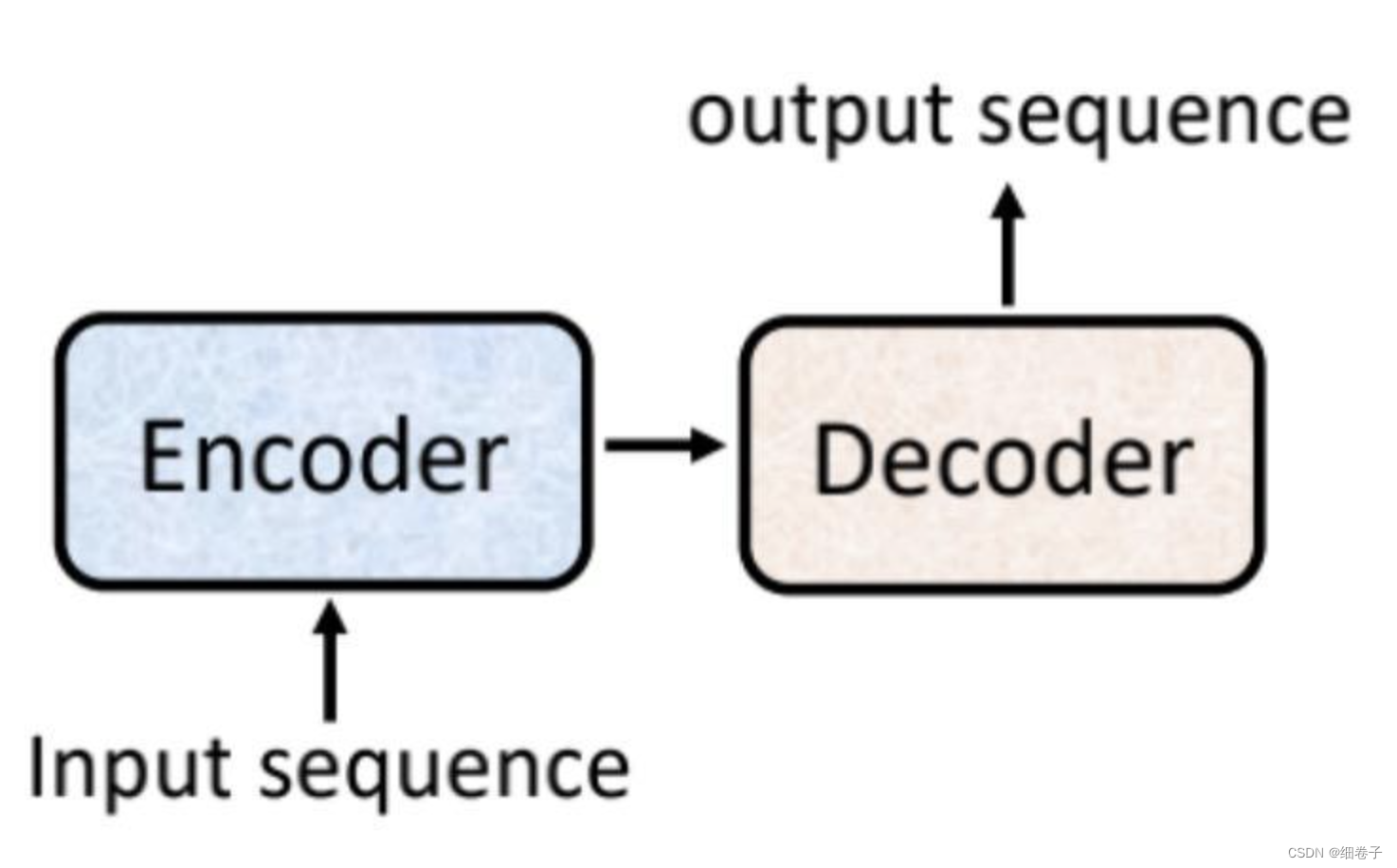
Google的BERT系列使用的是Transformer的Encoder部分,而OpenAI的GPT系列使用的是Decoder部分。
Google提出的Transformer一开始是用于机器翻译,Encoder用于输入,Decoder用于输出,如:英语翻德语,Encoder就主要是学习到英语句子中的词及其关系,然后丢给Decoder,Decoder得到后进行处理并输出德语出来。
其中,Encoder的输入是整个句子,比如一句话“I love China”,其中"love"的上文是"I",下文是“China”,而Decoder输出是一个词一个词的输出的如“我爱中国”的输出顺序是“我”、“爱”、“中国”,
从上可知Encoder的特点是:在结构上对上下文的理解更强,更适合嵌入式的表达,因此它比较适合做“完形填空”式的任务;而Decoder的特点是:基于上文而不知道下文,因此它比较适合做“根据上文推测下文”的任务。
由上可知,Decoder就适合ChatGPT这种聊天的场景了。
回到前面的图,在ChatGPT之前是由:GPT->GPT2->GPT3,再然后有一个叫:InstructGPT[2]的,我从ChatGPT官网上看到这样一句话:

请注意我用蓝色框 框起来的这里,他说 ChatGPT是InstructGPT的姊妹,她俩都是“基于人类反馈的强化学习”(后面这句是我从文献中获得的)
ChatGPT和InstructGPT与之前GPT系列模型的区别就在于“基于人类反馈的强化学习”。
通俗来讲,我们可以把之前的GPT模型想象成一大堆数据训练出来的模型,在应用时,这模型有个致命缺点就是它输出的内容对人类不太友好(比如输出有毒的内容或编造出来的内容,不符合人类逻辑等等)
“基于人类反馈的强化学习”,就是在训练GPT模型之前,先用一批专家的知识来训练一个反馈模型,然后再训练GPT3模型,如下图:
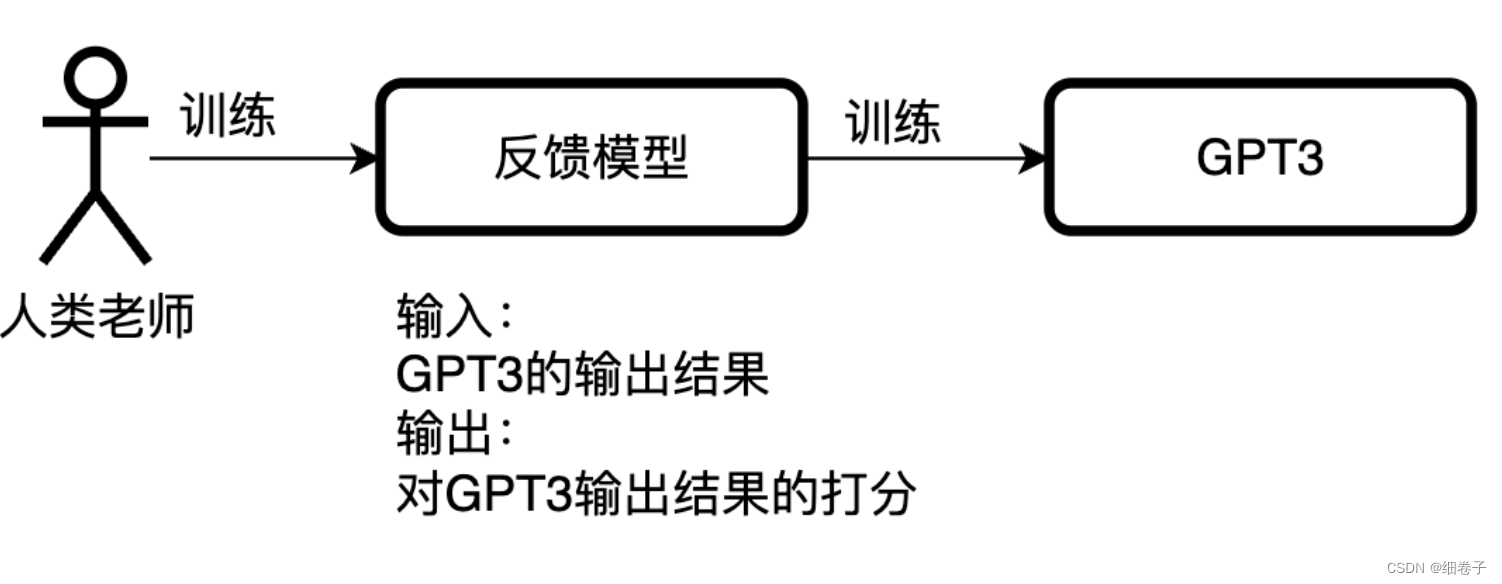
从图中可知,该模型与之前GPT模型区别就像是“注入了人类的意识”,基于人类反馈模型训练的模型就被叫做“基于人类反馈的强化学习”(Reinforcement Learning from Human Feedback)
原理就简单介绍到这里了,如果你有兴趣的话,给我留言,激励我出更多GPT相关内容。
ChatGPT的应用
ChatGPT的应用就很多了,这里简单提一下,如:写作、写代码、聊天、指导决策等等。。
我老师关注医疗方面的应用,于是我也搜了一下,
有人对ChatGPT医疗建议进行图灵测试[3],发现机器人对于不同的问题,回答的正确分类在49.0%到85.7%之间,平均而言,患者对聊天机器人功能的信任度反应较弱,并随着问题任务与健康相关的复杂性增加,信任度也会降低,但整体而言,ChatGPT对患者问题的回答与人类提供者对问题的回答难以区分,外行似乎相信使用聊天机器人来回答风险较低的健康问题。
看来未来应用于医疗也不是不可能。
到这里,就不得不担心ChatGPT可能带来的问题了。
ChatGPT可能存在的问题
什么某些人失业啊,这啥啥的,我就不说了。
我想提的是“道德问题”,这灵感也是来源于我老师。
我也搜了一下,确实有这方面的文献[4]。
这也可想而知的,该模型的训练注入了人类老师的标记嘛。
而该聊天模型功能强大,能作为工作、决策的好助手,那么它作为一个机器人,如何对自己说的话负责呢?
这就存在自动驾驶一样的问题了。
总结
本文主要讲了以下内容:
- 我对ChatGPT的使用过程;
- OpenAI的简单介绍;
- ChatGPT的简单原理:
Transformer的Encoder->GPT->GPT2->GPT3->InstructGPT->ChatGPT;
以及,“基于人类反馈的强化学习”是什么; - ChatGPT的应用;
- ChatGPT可能带来的道德问题。
参考文献
[1] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
[2] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. arXiv preprint arXiv:2203.02155, 2022.
[3] Nov O, Singh N, Mann D M. Putting ChatGPT’s Medical Advice to the (Turing) Test[J]. medRxiv, 2023: 2023.01. 23.23284735.
[4] Krügel S, Ostermaier A, Uhl M. The moral authority of ChatGPT[J]. arXiv preprint arXiv:2301.07098, 2023.