前言
这里容我罗嗦几句 😗
这个时间,我想大学生应该都回学校了吧,嘿嘿
现在应该蛮忙的,有些的还要准备开学考,临近毕业的朋友,也快要因为工作而烦恼了,但是!!
咱也是要有点娱乐时间的,俗话说劳逸结合嘛
正好周末我还要和朋友出去玩,这下雨天的,也不好在室外逛,索性就准备看看剧本杀或者其他桌游
咱就是干啥都是要有所准备的,这不得用python来采集采集这些桌游店的数据信息,比较比较哪家更好吗
再顺便做个 可视化数据展示
那咱就直接开始吧

环境使用:
- Python 3.8
- Pycharm
模块使用:
- requests >>> pip install requests
- re
- csv
如何安装python第三方模块:
- win + R 输入 cmd 点击确定, 输入安装命令 pip install 模块名 (pip install requests)回车
- 在pycharm中点击Terminal(终端) 输入安装命令
基本流程思路
一. 数据来源分析
- 找url, 找我们想要数据从哪里来的
采集美 —> 武汉 桌游 上商品数据 - 通过开发者工具进行抓包分析
F12 或者鼠标右键点击检查, 选择 network
二. 代码实现步骤过程: 固定四大步骤
-
发送请求, 对于刚刚分析得到url地址发送请求
-
获取数据, 获取服务器返回响应数据 —> 开发者工具里面response
-
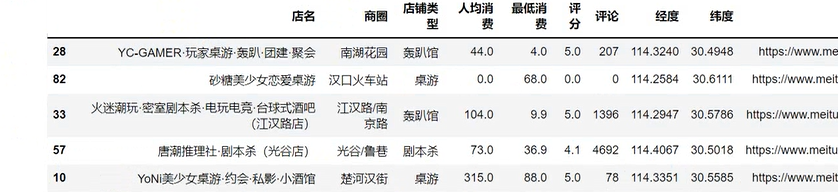
解析数据, 提取我们想要数据内容 —> 店铺基本信息
-
保存数据, 保存数据, 保存表格里面
-
多页数据采集
多页数据采集 —> 循环 for <目的>
分析请求url地址参数变化

实现代码
导入模块
# 导入数据请求模块 ---> 第三方模块 需要在cmd里面进行 pip install requests
import requests
# 导入格式化输出模块 ---> 内置模块 不需要安装
from pprint import pprint
# 导入csv模块 ---> 内置模块 不需要安装
import csv
创建文件
f = open('武汉桌游多页.csv', mode='a', newline='', encoding='utf-8')
# f 创建文件对象 fieldnames 字段名, 对应表头数据
csv_writer = csv.DictWriter(f, fieldnames=[
'店名',
'商圈',
'店铺类型',
'人均消费',
'最低消费',
'评分',
'评论',
'经度',
'纬度',
'详情页',
])
# 写入表头
csv_writer.writeheader()
1.发送请求
模拟浏览器对于url地址发送请求
- 相对于长链接, 可以分段写入
链接问号后面内容 属于请求参数 可以分开写 - 批量替换
1. 选中替换内容 ctrl + r
2. 选中正则 .* 勾选上
3. 使用正则命令替换
(.?): (.)
‘$1’: ‘$2’, - headers请求头使用:
确定url请求地址

请求参数
data = {
'uuid': '760326fa1f194488b4b2.1659677166.1.0.0',
'userid': '266252179',
'limit': '32',
'offset': page,
'cateId': '-1',
'q': '桌游',
}
# 伪装浏览器 headers请求头
headers = {
# Referer 防盗链 告诉服务器我们请求的网址从哪里跳转过来的 <行程码>
'Referer': 'https://wh.meituan.com/',
# User-Agent 用户代理 表示浏览器基本身份信息 <健康码>
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求 <Response [403]> 没有访问权限...请求失败了
response = requests.get(url=url, params=data, headers=headers)
# 得到响应对象
print(response)
2. 获取数据
获取服务器返回响应数据 print(response.json())
3. 解析数据,
提取我们想要数据内容
- response.json() —> 字典数据类型
- 字典数据取值, 根据冒号左边的内容[键], 提取冒号右边的内容[值] 键值对取值
格式化输出 可以更加方便提取数据 pprint(response.json())
for index in response.json()['data']['searchResult']:
href = f'https://www.meituan.com/xiuxianyule/{index["id"]}/'
# 创建一个字典接收数据 百度滑轮设置pycharm字体大小
# python基础语法知识 for循环遍历 字典创建与取值 字符串格式化方法
dit = {
'店名': index['title'],
'商圈': index['areaname'],
'店铺类型': index['backCateName'],
'人均消费': index['avgprice'],
'最低消费': index['lowestprice'],
'评分': index['avgscore'],
'评论': index['comments'],
'经度': index['longitude'],
'纬度': index['latitude'],
'详情页': href
}
4.写入数据
csv_writer.writerow(dit)
print(dit)
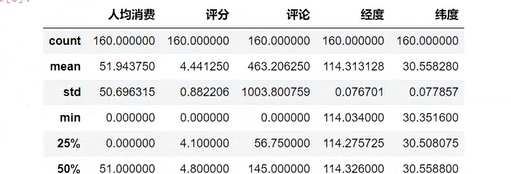
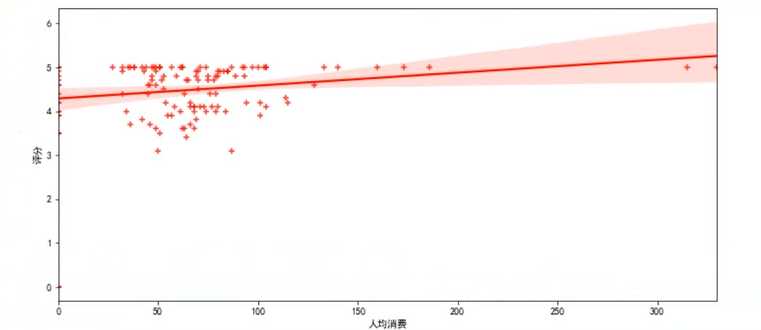
可视化代码
全部源码 点击文末名片领取~
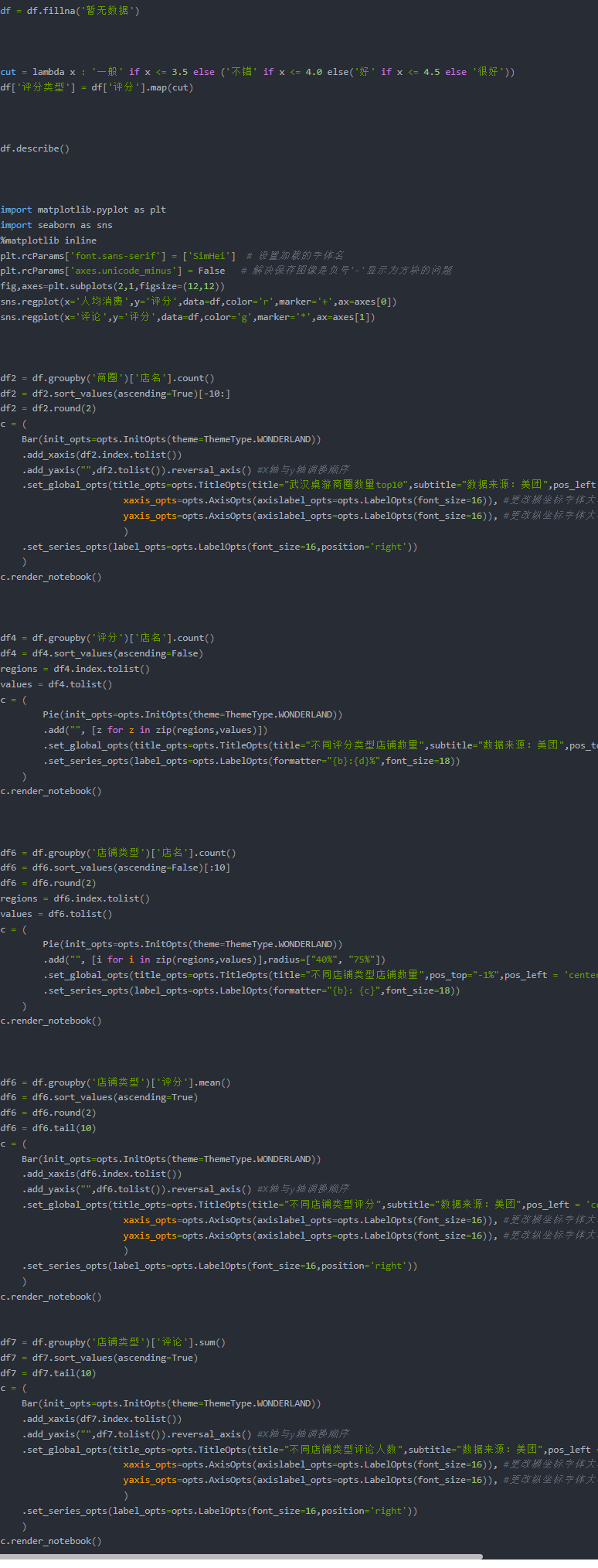
效果展示