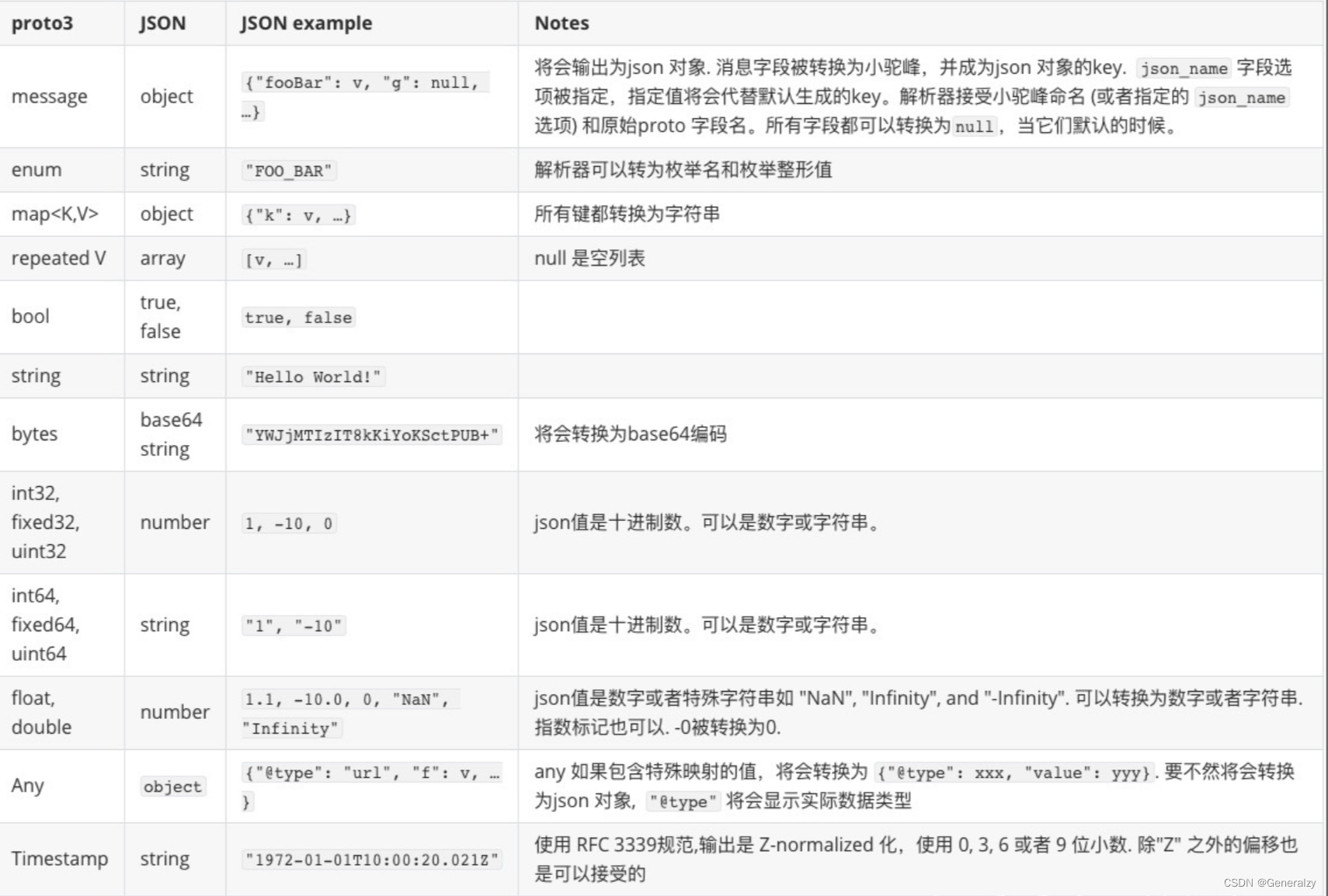
ES为用户提供了丰富的搜索功能:既有基本的搜索功能,又有搜索建议功能;既有常用的普通类型的匹配功能,又有基于地理位置的搜索功能;既提供了分页搜索功能,又提供了搜索的调试分析功能。
1 搜索辅助功能
俗话说“工欲善其事,必先利其器”。在介绍ES提供的各种搜索匹配功能之前,我们先介绍ES提供的各种搜索辅助功能。例如,为优化搜索性能,需要指定搜索结果返回一部分字段内容。为了更好地呈现结果,需要用到结果计数和分页功能;当遇到性能瓶颈时,需要剖析搜索各个环节的耗时;面对不符合预期的搜索结果时,需要分析各个文档的评分细节。
1 指定返回的字段
考虑到性能问题,需要对搜索结果进行“瘦身”——指定返回的字段。在ES中,通过_source子句可以设定返回结果的字段。_source指向一个JSON数组,数组中的元素是希望返回的字段名称。
定义酒店索引的结构如下:
PUT /hotel
{
"mappings": {
"properties": {
"title": { //定义title字段,指定类型为text
"type": "text"
},
"city": { //定义city字段,指定类型为keyword
"type": "keyword"
},
"price": { //定义price字段,指定类型为double
"type": "double"
},
"create_time": { //定义create_time字段,指定类型为date并设定其格式
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"amenities": { //定义amenities字段,指定类型为text
"type": "text"
},
"full_room": { //定义full_room字段,指定类型为boolean
"type": "boolean"
},
"location": { //定义location字段,指定类型为geo_point
"type": "geo_point"
},
"praise": { //定义praise字段,指定类型为integer
"type": "integer"
}
}
}
}
为方便演示,向酒店索引中新增如下数据:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title":"文雅酒店","city":"青岛","price":556,"create_time":"2020-04-18 12:00:00","amenities":"浴池,普通停车场/充电停车场","full_room":false,"location":{"lat":36.083078,"lon":120.37566},"praise":10}
{"index":{"_index":"hotel","_id":"002"}}
{"title":"金都嘉怡假日酒店","city":"北京","price":337,"create_time":"2021-03-15 20:00:00","amenities":"wifi,充电停车场/可升降停车场","full_room":false,"location":{"lat":39.915153,"lon":116.403},"praise":60}
{"index":{"_index":"hotel","_id":"003"}}
{"title":"金都欣欣酒店","city":"天津","price":200,"create_time":"2021-05-09 16:00:00","amenities":"提供假日party,免费早餐,可充电停车场","full_room":true,"location":{"lat":39.186555,"lon":117.162007},"praise":30}
{"index":{"_index":"hotel","_id":"004"}}
{"title":"金都酒店","city":"北京","price":500,"create_time":"2021-02-18 08:00:00","amenities":"浴池(假日需预定),室内游泳池,普通停车场","full_room":true,"location":{"lat":39.915343,"lon":116.4239},"praise":20}
{"index":{"_index":"hotel","_id":"005"}}
{"title":"文雅精选酒店","city":"北京","price":800,"create_time":"2021-01-01 08:00:00","amenities":"浴池(假日需预定),wifi,室内游泳池,普通停车场","full_room":true,"location":{"lat":39.918229,"lon":116.422011},"praise":20}
下面的DSL指定搜索结果只返回title和city字段:
GET /hotel/_search
{
"_source": ["title","city"], //设定只返回title和city字段
"query": { //查询条件
"term": {
"city": {
"value": "北京"
}
}
}
}
执行上述DSL后,搜索结果如下:
{
…
"hits" : {
…
"max_score" : 0.53899646,
"hits" : [ //命中的结果文档集合
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "002",
"_score" : 0.53899646,
"_source" : { //只返回酒店名称和城市
"city" : "北京",
"title" : "金都嘉怡假日酒店"
}
},
…
]
}
}
在上述搜索结果中,每个命中文档的_source结构体中只包含指定的city和title两个字段的数据。
在Java客户端中,通过调用searchSourceBuilder.fetchSource()方法可以设定搜索返回的字段,该方法接收两个参数,即需要的字段数组和不需要的字段数组。以下代码片段将和上面的DSL呈现相同的效果:
SearchRequest searchRequest = new SearchRequest("hotel"); //客户端请求
//创建搜索builder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建query
searchSourceBuilder.query(new TermQueryBuilder("city","北京"));
//设定希望返回的字段数组
searchSourceBuilder.fetchSource(new String[]{"title","city"} , null);
searchRequest.source(searchSourceBuilder);
public void searchDefineFiled() {
val request = new SearchRequest("hotel");
val builder = new SearchSourceBuilder();
builder.query(new TermQueryBuilder("city", "北京"));
builder.fetchSource(new String[]{"title", "city"}, null);
request.source(builder);
try {
val response = client.search(request, RequestOptions.DEFAULT);
System.out.println(response);
} catch (IOException e) {
e.printStackTrace();
}
}
2 结果计数
为提升搜索体验,需要给前端传递搜索匹配结果的文档条数,即需要对搜索结果进行计数。针对这个要求,ES提供了_count API功能,在该API中,用户提供query子句用于结果匹配,ES会返回匹配的文档条数。下面的DSL将返回城市为“北京”的酒店个数:
GET /hotel/_count
{
"query": { //计数的查询条件
"term": {
"city": {
"value": "北京"
}
}
}
}
执行上述DSL后,返回信息如下:
{
"count" : 3, //结果计数值
"_shards" : { //搜索命中的分片信息
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
由结果可知,ES不仅返回了匹配的文档数量(值为3),并且还返回了和分片相关的元数据,如总共扫描的分片个数,以及成功、失败、跳过的分片个数等。
在Java客户端中,通过CountRequest执行_count API,然后调用CountRequest对象的source()方法设置查询逻辑。countRequest.source()方法返回CountResponse对象,通过countResponse.getCount()方法可以得到匹配的文档条数。以下代码将和上面的DSL呈现相同的效果:
public long getCityCount() {
//客户端的count请求
CountRequest countRequest=new CountRequest("hotel");
//创建搜索builder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建query
searchSourceBuilder.query(new TermQueryBuilder("city","北京"));
countRequest.source(searchSourceBuilder); //设置查询
try {
CountResponse countResponse=client.count(countRequest,Request
Options.DEFAULT); //执行count
return countResponse.getCount(); //返回count结果
} catch (Exception e) {
e.printStackTrace();
}
return 0;
}
3 结果分页
在实际的搜索应用中,分页是必不可少的功能。在默认情况下,ES返回前10个搜索匹配的文档。用户可以通过设置from和size来定义搜索位置和每页显示的文档数量,from表示查询结果的起始下标,默认值为0,size表示从起始下标开始返回的文档个数,默认值为10。下面的DSL将返回下标从0开始的20个结果。
GET /hotel/_search
{
"from": 0, //设置搜索的起始位置
"size": 20, //设置搜索返回的文档个数
"query": { //搜索条件
"term": {
"city": {
"value": "北京"
}
}
}
}
在默认情况下,用户最多可以取得10 000个文档,即from为0时,size参数最大为10 000,如果请求超过该值,ES返回如下报错信息:
{
"error" : {
"root_cause" : [
{ //请求数量过多的报错信息
"type" : "illegal_argument_exception",
"reason" : "Result window is too large, from + size must be less than
or equal to: [10000] but was [10001]. See the scroll api for a more efficient
way to request large data sets. This limit can be set by changing the
[index.max_result_window] index level setting."
}
],
…
},
"status" : 400
}
对于普通的搜索应用来说,size设为10 000已经足够用了。如果确实需要返回多于10 000条的数据,可以适当修改max_result_window的值。以下示例将hotel索引的最大窗口值修改为了20 000。
PUT /hotel/_settings
{ //设定搜索返回的文档个数
"index": {
"max_result_window": 20000
}
}
注意,如果将配置修改得很大,一定要有足够强大的硬件作为支撑。
作为一个分布式搜索引擎,一个ES索引的数据分布在多个分片中,而这些分片又分配在不同的节点上。一个带有分页的搜索请求往往会跨越多个分片,每个分片必须在内存中构建一个长度为from+size的、按照得分排序的有序队列,用以存储命中的文档。然后这些分片对应的队列数据都会传递给协调节点,协调节点将各个队列的数据进行汇总,需要提供一个长度为number_of_shards*(from+size)的队列用以进行全局排序,然后再按照用户的请求从from位置开始查找,找到size个文档后进行返回。
基于上述原理,ES不适合深翻页。什么是深翻页呢?简而言之就是请求的from值很大。假设在一个3个分片的索引中进行搜索请求,参数from和size的值分别为1000和10,其响应过程如图4.1所示。
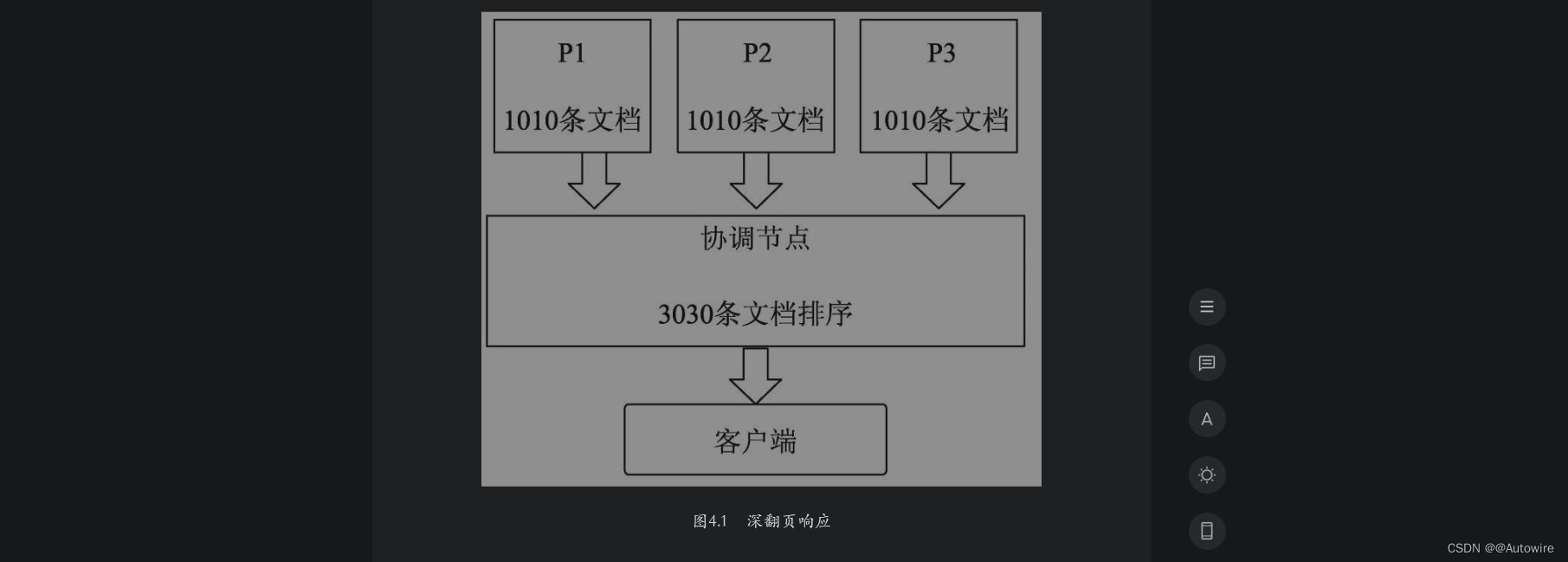
当深翻页的请求过多时会增加各个分片所在节点的内存和CPU消耗。尤其是协调节点,随着页码的增加和并发请求的增多,该节点需要对这些请求涉及的分片数据进行汇总和排序,过多的数据会导致协调节点资源耗尽而停止服务。
作为搜索引擎,ES更适合的场景是对数据进行搜索,而不是进行大规模的数据遍历。一般情况下,只需要返回前1000条数据即可,没有必要取到10 000条数据。如果确实有大规模数据遍历的需求,可以参考使用scroll模式或者考虑使用其他的存储引擎。限于篇幅,此处不再展开讲解。
在Java客户端中,可以调用SearchSourceBuilder的from()和size()方法来设定from和size参数。以下代码片段将from和size的值分别设置为20和10。
SearchRequest searchRequest = new SearchRequest("hotel"); //客户端请求
//创建搜索的builder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建query
searchSourceBuilder.query(new TermQueryBuilder("city","北京"));
searchSourceBuilder.from(20); //设置from参数
searchSourceBuilder.size(10); //设置size参数
searchRequest.source(searchSourceBuilder);
4 性能分析
在使用ES的过程中,有的搜索请求的响应可能比较慢,其中大部分的原因是DSL的执行逻辑有问题。ES提供了profile功能,该功能详细地列出了搜索时每一个步骤的耗时,可以帮助用户对DSL的性能进行剖析。开启profile功能只需要在一个正常的搜索请求的DSL中添加"profile":"true"即可。以下查询将开启profile功能:
GET /hotel/_search
{
"profile": "true", //打开性能剖析开关
"query": { //查询条件
"match": {
"title": "金都"
}
}
}
执行以上DSL后ES返回了一段比较冗长的信息,下面是省略一些信息的返回数据。
{
"took":2,
"timed_out":false,
"_shards":…,
"hits":…,
"profile":{ //命中的分片信息
"shards":[
{
"id":"[N533dYYvQWeYoRSPjpo8EA][hotel][0]",
"searches":[
{
"query":[
{ //在title中搜索“金都”,被ES拆分成两个子查询
"type":"BooleanQuery",
"description":"title:金 title:都",
"time_in_nanos":311540, //match搜索的总耗时
"breakdown":{
"set_min_competitive_score_count":0,
"match_count":3, //命中的文档个数
"shallow_advance_count":0,
"set_min_competitive_score":0,
"next_doc":11689,
"match":1833,
"next_doc_count":3,
"score_count":3, //打分的文档个数
"compute_max_score_count":0,
"compute_max_score":0,
"advance":46290,
"advance_count":1,
"score":9070,
"build_scorer_count":2,
"create_weight":137353,
"shallow_advance":0,
"create_weight_count":1,
"build_scorer":105305
},
"children":[ //子查询
{ //子查询"title:金"
"type":"TermQuery",
"description":"title:金",
"time_in_nanos":123649, //耗时
"breakdown":Object{…}
},
{ //子查询"title:都"
"type":"TermQuery",
"description":"title:都",
"time_in_nanos":29648,
"breakdown":Object{…}
}
]
}
],
"rewrite_time":12001,
"collector":[ //ES 收集数据性能剖析
{
"name":"SimpleTopScoreDocCollector",
"reason":"search_top_hits",
"time_in_nanos":18004 //ES收集数据的耗时
}
]
}
],
"aggregations":… //聚合性能剖析,本次搜索无聚合,因此数据为空
}
]
}
}
如上所示,在带有profile的返回信息中,除了包含搜索结果外,还包含profile子句,在该子句中展示了搜索过程中各个环节的名称及耗时情况。需要注意的是,使用profile功能是有资源损耗的,建议用户只在前期调试的时候使用该功能,在生产中不要开启profile功能。
因为一个搜索可能会跨越多个分片,所以使用shards数组放在profile子句中。每个shard子句中包含3个元素,分别是id、searches和aggregations。

id表示分片的唯一标识,它的组成形式为[nodeID][indexName][shardID]。
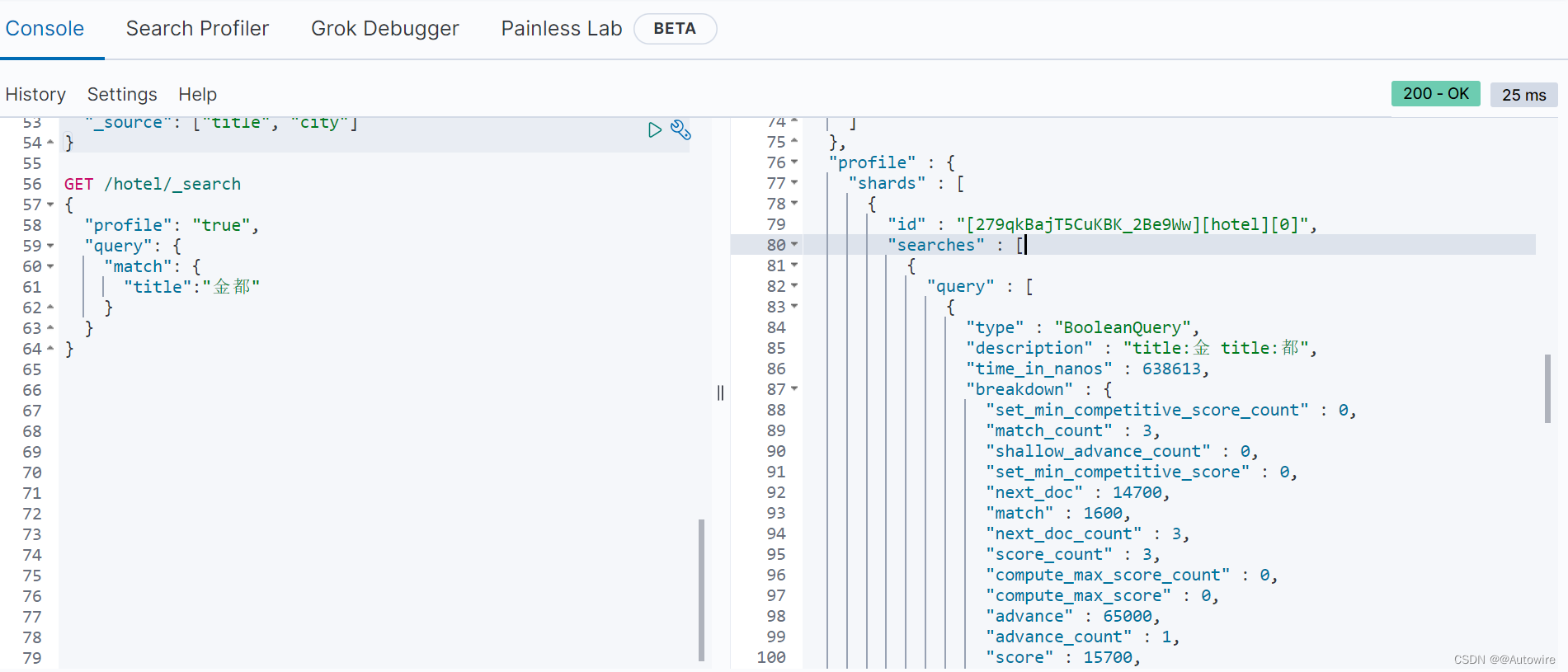
searches以数组的形式存在,因为有的搜索请求会跨多个索引进行搜索。每一个search子元素即为在同一个索引中的子查询,此处不仅返回了该search子元素耗时为322 496ns的信息,而且还返回了搜索“金都”的详细策略,即被拆分成“title:金”和“title:都”两个子查询。同理,children子元素给出了“title:金”“title:都”的耗时和详细搜索步骤的耗时,此处不再赘述。
aggregations只有在进行聚合运算时才有内容,限于篇幅,本节不展开介绍。
上面只是一个很简单的例子,如果查询比较复杂或者命中的分片比较多,profile返回的信息将特别冗长。在这种情况下,用户进行性能剖析的效率将非常低。为此,Kibana提供了可视化的profile功能,该功能建立在ES的profile功能基础上。在Kibana的Dev Tools界面中单击Search Profiler链接,就可以使用可视化的profile了,其区域布局如图4.2所示。
在索引编辑区中输入hotel,在DSL编辑区中输入如下内容:
{
"query":{ //搜索请求
"match":{ //match搜索
"title":"金都"
}
}
}
单击Profile按钮,Kibana会在结果反馈区将性能剖析的结果进行可视化展示,该结果对搜索的时间损耗进行了概要展示,如图4.3所示。用户还可以单击页面中的View details链接继续查看搜索过程中各个子步骤的耗时信息。
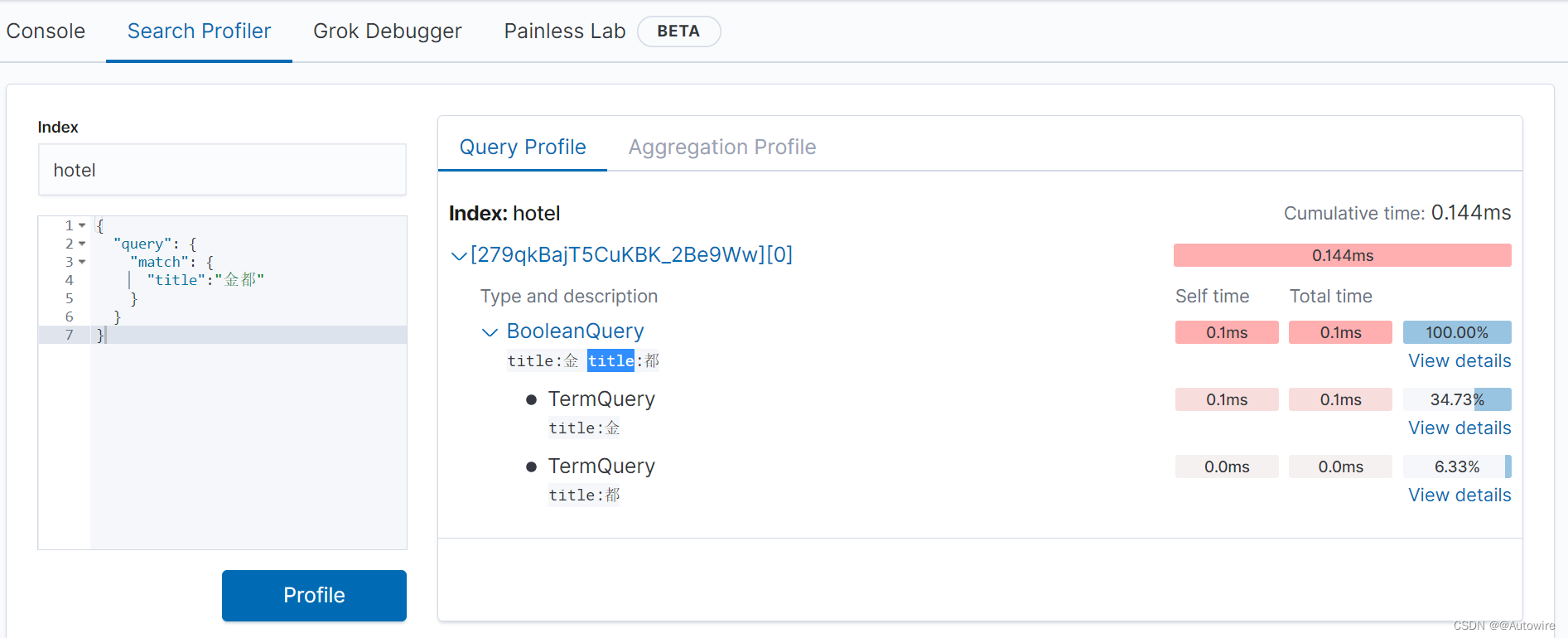
5 评分分析
在使用搜索引擎时,一般都会涉及排序功能。如果用户不指定按照某个字段进行升序或者降序排列,那么ES会使用自己的打分算法对文档进行排序。有时我们需要知道某个文档具体的打分详情,以便于对搜索DSL问题展开排查。ES提供了explain功能来帮助使用者查看搜索时的匹配详情。explain的使用形式如下:
GET /${index_name}/_explain/${doc_id}
{
"query": { //搜索的具体逻辑
…
}
}
以下示例为按照标题进行搜索的explain查询请求:
GET /hotel/_explain/002
{
"query": {
"match": { //搜索酒店名称匹配“金都”的文档
"title": "金都"
}
}
}
执行上述explain查询请求后,ES返回的信息如下:
{
"_index":"hotel",
"_type":"_doc",
"_id":"002",
"matched":true,
"explanation":{ //"title:金都"被拆分成两个子查询
"value":0.91718745,
"description":"sum of:",
"details":[
{ //子查询"title:金"的具体匹配过程
"value":0.45859373,
"description":"weight(title:金 in 1) [PerFieldSimilarity],
result of:",
"details":[
{
"value":0.45859373, //子查询"title:金"的匹配得分
"description":"score(freq=1.0), computed as boost *
idf * tf from:",
"details":[
…,
…,
…
]
}
]
},
{ //子查询"title:都"的具体匹配过程
"value":0.45859373,
"description":"weight(title:都 in 1) [PerFieldSimilarity],
result of:",
"details":[
{
"value":0.45859373, //子查询"title:都"的匹配得分
"description":"score(freq=1.0), computed as boost *
idf * tf from:",
"details":[
…,
…,
…
]
}
]
}
]
}
}
上面的内容将返回结果省略了,可以看到,explain返回的信息比较全面。此处不必关注具体的返回信息,在以后的全文搜索章节中将详细对每项输出进行讲解。
另外,如果一个文档和查询不匹配,explain也会直接返回信息告知用户,具体如下:
{
"_index" : "hotel", //搜索的索引
"_type" : "_doc",
"_id" : "001",
"matched" : false, //没有命中的文档
"explanation" : {
"value" : 0.0,
"description" : "no matching term",
"details" : [ ] //命中的文档集合为空
}
}
2 丰富的搜索匹配功能
针对不同的数据类型,ES提供了很多搜索匹配功能:既有进行完全匹配的term搜索,也有按照范围匹配的range搜索;既有进行分词匹配的match搜索,也有按照前缀匹配的suggest搜索。本节将介绍这些功能的使用场景,并以两个方面给出使用示例:一方面介绍各种搜索匹配功能的DSL使用示例,另一方面介绍各功能在Java客户端中的使用示例。
1 查询所有文档
在关系型数据库中,当需要查询所有文档的数据时,对应的SQL语句为select*form table_name。在ES中是否有类似的功能呢?答案是“有”,使用ES的match_all查询可以完成类似的功能。使用match_all查询文档时,ES不对文档进行打分计算,默认情况下给每个文档赋予1.0的得分。用户可以通过boost参数设定该分值。以下示例使用match_all查询所有文档,并设定所有文档的分值为2.0:
GET /hotel/_search
{
"_source": [ //只返回title和city字段
"title",
"city"
],
"query": {
"match_all": { //查询所有文档
"boost": 2 //设定所有文档的分值为2.0
}
}
}
ES返回的数据如下:
{
…
"hits" : {
"total" : { //命中5个文档
"value" : 5,
"relation" : "eq"
},
"max_score" : 2.0, //最高分为2.0
"hits" : [ //命中的文档集合
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_score" : 2.0,
"_source" : {
"city" : "青岛",
"title" : "文雅酒店"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "002",
"_score" : 2.0,
"_source" : {
"city" : "北京",
"title" : "金都嘉怡假日酒店"
}
}
…
]
}
}
通过返回数据集可以看到,ES返回了所有的文档,并且所有文档的得分都为2.0。
在Java客户端中进行查询时,可以调用QueryBuilders.matchAllQuery()方法新建一个match_all查询,并且通过boost()方法设置boost值。构建完term查询后,调用searchSource Builder.query()方法设置查询条件。
为方便演示,下面定义一个打印搜索结果的方法,该方法接收一个SearchRequest实例并将搜索结果进行逐条打印:
public void printResult(SearchRequest searchRequest) {
try {
SearchResponse searchResponse = client.search(searchRequest,
RequestOptions.DEFAULT); //执行搜索
SearchHits searchHits = searchResponse.getHits(); //获取搜索结果集
for (SearchHit searchHit : searchHits) { //遍历搜索结果集
String index = searchHit.getIndex(); //获取索引名称
String id = searchHit.getId(); //获取文档_id
Float score = searchHit.getScore(); //获取得分
String source = searchHit.getSourceAsString(); //获取文档内容
System.out.println("index=" + index + ",id=" + id + ",score=
" + score + ",source=" + source); //打印数据
}
} catch (Exception e) {
e.printStackTrace();
}
}
以下为在Java客户端中使用match_all查询的示例:
public void matchAllSearch() {
//新建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery().
boost(2.0f); //新建match_all查询,并设置boost值为2.0
searchSourceBuilder.query(matchAllQueryBuilder);
searchRequest.source(searchSourceBuilder); //设置查询
printResult(searchRequest); //打印结果
}
2 term级别查询
term查询是结构化精准查询的主要查询方式,用于查询待查字段和查询值是否完全匹配,其请求形式如下:
GET /${index_name}/_search
{
"query": {
"term": {
"${FIELD}": { //搜索字段名称
"value": "${ VALUE }" //搜索值
}
}
}
}
其中,FIELD和VALUE分别代表字段名称和查询值,FIELD的数据类型可以是数值型、布尔型、日期型、数组型及关键字等。
以下示例是搜索住宿价格为500元的酒店,price字段为数值型数据:
GET /hotel/_search
{
"query": {
"term": {
"price": { //搜索字段为price,字段类型为double
"value": "500" //搜索值为500
}
}
}
}
以下示例是搜索城市为北京的酒店,city字段为关键字类型数据:
GET /hotel/_search
{
"query": {
"term": {
"city": { //搜索字段为city,字段类型为keyword
"value": "北京" //搜索值为北京
}
}
}
}
以下示例是搜索没有满房的酒店,full_room(满房状态)字段为布尔型数据:
GET /hotel/_explain/001
{
"query": {
"term": {
"full_room": { //搜索字段为full_room,字段类型为boolean
"value": "false" //搜索值为false
}
}
}
}
对于日期型的字段查询,需要按照该字段在mappings中定义的格式进行查询。如果create_time字段使用默认的格式,那么下面的请求是错误的:
GET /hotel/_search
{
"query": {
"term": {
"create_time": { //使用与默认格式不符的日期格式查询
"value": "2021-01-15 12:00:00"
}
}
}
}
S将返回错误,具体信息如下:
{
"error":{
"root_cause":[
{ //日期格式解析出错信息
"type":"parse_exception",
"reason":"failed to parse date field [2021-01-15 12:00:00]
with format [strict_date_optional_time||epoch_millis]: [failed to parse
date field [2021-01-15 12:00:00] with format [strict_date_optional_time||
epoch_millis]]"
}
],
"type":"search_phase_execution_exception",
"reason":"all shards failed",
"phase":"query",
"grouped":true,
"failed_shards":Array[1],
"caused_by":Object{…}
},
"status":400
}
之所以返回错误信息,是因为ES的默认格式中不包含yyyy-MM-dd HH:mm:ss格式。
在Java客户端中进行查询时,可以调用QueryBuilders.termQuery()方法新建一个term查询。termQuery()方法传入不同的参数即可生成不同数据类型的term查询,可以传入boolean、double、float、int、long和String等类型的参数,但是没有日期类型的参数,如图4.4所示。

那么如何构建日期类型的term查询呢?可以使用日期形式字符串类型的term查询来解决。以下为使用日期类型的字符串参数构建的term查询:
public void termDateSearch() {
//创建搜索请求
val searchRequest = new SearchRequest("hotel");
val searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.termQuery("create_time", "2021-05-09 16:00:00")); //构建term查询
searchRequest.source(searchSourceBuilder); //设置查询请求
printResult(searchRequest); //打印搜索结果
}
其他类型的term查询,如boolean、double、float、int和long等比较简单,读者可以查询API进行学习,此处不再赘述。
terms查询是term查询的扩展形式,用于查询一个或多个值与待查字段是否完全匹配,其请求形式如下:
GET /${index_name}/_search
{
"query": {
"terms": {
"FIELD": [ //指定查询字段
"VALUE1", //指定查询值,多个值之间用逗号分隔
"VALUE2",
…
]
}
}
}
其中,FIELD代表待查字段名,VALUE1和VALUE2代表多个查询值,FIELD的数据类型可以是数值型、布尔型、日期型、数组型及关键字等。以下是搜索城市为“北京”或者“天津”的酒店示例:
GET /hotel/_search
{
"query": {
"terms": {
"city": [ //指定查询字段为city
"北京",
"天津"
]
}
}
}
在Java客户端中对应terms查询的类为TermsQuery,该类的实例通过QueryBuilders.termsQuery()生成。在QueryBuilders.termsQuery()方法中,第一个参数为字段名称,第二个参数可以是一个集合类型,也可以是一个单独类型,当为单独类型时,该参数为可变长度参数。QueryBuilders.termsQuery()方法列表如图4.5所示。

以下是使用terms查询城市为“北京”或“天津”的文档:
public void termsSearch() {
//创建搜索请求
val searchRequest = new SearchRequest("hotel");
val searchSourceBuilder = new SearchSourceBuilder();
//构建terms查询
searchSourceBuilder.query(QueryBuilders.termsQuery("city", "北京", "天津"));
searchRequest.source(searchSourceBuilder); //设置查询请求
printResult(searchRequest); //打印搜索结果
}
3 range查询
range查询用于范围查询,一般是对数值型和日期型数据的查询。使用range进行范围查询时,用户可以按照需求中是否包含边界数值进行选项设置,可供组合的选项如下:
gt:大于;lt:小于;gte:大于或等于;lte:小于或等于。
以下是数值类型的查询示例,查询住宿价格在300~500(包含边界值)元的酒店:
GET /hotel/_search
{
"query": {
"range": { //range查询
"price": { //指定字段为price,此处包含边界值
"gte": 300,
"lte": 500
}
}
}
}
以下为数值类型的查询示例,查询住宿价格大于300(不包含边界值)元的酒店:
GET /hotel/_search
{
"query": {
"range": { //range查询
"price": { //指定字段为price,此处不包含边界值
"gt": 300
}
}
}
}
注意,使用range查询时,查询值必须符合该字段在mappings中设置的规范。例如,在酒店索引中,price字段是double类型,则range应该使用数值型或者数值类型的字符串形式,不能使用其他形式。以下示例将导致ES返回错误:
GET /hotel/_search
{
"query": {
"range": { //range查询
"price": { //指定字段为price,但是查询值和字段类型不符
"gte": "abc"
}
}
}
}
执行上述DSL后,ES返回的信息如下:
{
"error":{
…
"type":"search_phase_execution_exception", //range查询解析异常
…
"failed_shards":[
{
"shard":0,
"index":"hotel",
"node":"N533dYYvQWeYoRSPjpo8EA",
"reason":{
"type":"query_shard_exception",
//构建range查询时出现异常
"reason":"failed to create query: For input string: "abc"",
"index_uuid":"7Hvzlr3xRW25Q9_O1Z4jOA",
"index":"hotel",
"caused_by":{
//字符串类型不能转换为range查询对应的数值型数据
"type":"number_format_exception",
"reason":"For input string: "abc""
}
}
}
]
},
"status":400
}
和term查询类似,查询日期型的字段时,需要遵循该字段在mappings中定义的格式进行查询。例如,create_time使用的是默认格式,并且统一采用的是“yyyyMMddHHmmss”格式,则range查询应该使用如下方式:
GET /hotel/_search
{
"query": {
"range": {
"create_time": { //range查询的日期格式符合日期字段的格式
"gte": "20210115120000",
"lte": "20210116120000"
}
}
}
}
在Java客户端上构建range请求是使用QueryBuilders.rangeQuery()方法实现的,该方法的参数为字段名称,然后再调用相应的方法即可构建相应的查询范围。可以调用gt()、lt()、gte()和lte()等方法分别实现大于、小于、大于等于、小于等于等查询范围。在使用时,可以直接连着使用“.”操作符,这样不用拆分语句,也比较容易理解。以下为在Java中使用range查询的示例程序:
public void rangeSearch() {
//创建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建range查询
QueryBuilder queryBuilder = QueryBuilders.rangeQuery("create_time").gte("20210115120000").lte("20210116120000");
searchSourceBuilder.query(queryBuilder);
searchRequest.source(searchSourceBuilder); //设置查询请求
printResult(searchRequest); //打印搜索结果
}
4 exists查询
在某些场景下,我们希望找到某个字段不为空的文档,则可以用exists搜索。字段不为空的条件有:
值存在且不是null;·值不是空数组;·值是数组,但不是[null]。
为方便测试,创建索引hotel_1,DSL如下:
PUT /hotel_1
{
"mappings": {
"properties": {
"title": { //定义字段title,类型为text
"type": "text"
},
"tag": { //定义字段tag,类型为keyword
"type": "keyword"
}
}
}
}
添加tag字段值为null的文档,DSL如下:
POST /hotel_1/_doc/006
{ //写入tag为null的文档
"title": "环球酒店",
"tag": null
}
添加tag字段是空数组的文档,DSL如下:
POST /hotel_1/_doc/007
{ //写入tag为空数组的文档
"title": "环球酒店",
"tag": []
}
添加tag为数组,其中只有一个元素且该元素为null的文档,DSL如下:
POST /hotel_1/_doc/008
{ //写入tag为数组,其中只有一个元素且该元素为null的文档
"title": "环球酒店",
"tag": [null]
}
上面3种情况的数据使用exists查询都不命中,查询的DSL如下:
GET /hotel_1/_search
{
"query": {
"exists": { //查询tag字段不为空的文档
"field": "tag"
}
}
}
查询结果如下:
{
…
"hits" : {
"total" : {
"value" : 0, //命中的文档个数为0
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ] //命中的文档集合为空
}
}
在Java客户端上构建exists查询时,使用SearchSourceBuilder.existsQuery(String name)来构建,传递的name参数是目标字段名称。以下是使用Java客户端构建exists查询的示例:
public void existsSearch(){
SearchRequest searchRequest=new SearchRequest("hotel_1");
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.existsQuery("tag"));
searchRequest.source(searchSourceBuilder);
printResult(searchRequest);
}
5 布尔查询
复合搜索,顾名思义是一种在一个搜索语句中包含一种或多种搜索子句的搜索。
布尔查询是常用的复合查询,它把多个子查询组合成一个布尔表达式,这些子查询之间的逻辑关系是“与”,即所有子查询的结果都为true时布尔查询的结果才为真。布尔查询还可以按照各个子查询的具体匹配程度对文档进行打分计算。布尔查询支持的子查询有四种,各子查询的名称和功能如表4.1所示。

1 must查询
当查询中包含must查询时,相当于逻辑查询中的“与”查询。命中的文档必须匹配该子查询的结果,并且ES会将该子查询与文档的匹配程度值加入总得分里。must搜索包含一个数组,可以把其他的term级别的查询及布尔查询放入其中。
以下示例使用must查询城市为北京并且价格在350~400元的酒店:
GET /hotel/_search
{
"query": {
"bool": {
"must": [ //must查询,数组内可封装各类子查询
{ //第一个子查询:城市为北京
"term": {
"city": {
"value": "北京"
}
}
},
{ //第二个子查询:价格>=350且价格<=400
"range": {
"price": {
"gte": 350,
"lte": 400
}
}
}
]
}
}
}
在Java客户端上构建must搜索时,可以使用QueryBuilders.boolQuery().must()进行构建,上面的range查询例子改写成Java客户端请求的形式为:
public void mustSearch() {
val searchRequest = new SearchRequest("hotel"); //新建请求
val searchSourceBuilder = new SearchSourceBuilder();
val boolQueryBuilder = QueryBuilders.boolQuery();
//构建城市term查询
val termQueryIsReady = QueryBuilders.termQuery("city", "北京");
val rangeQueryBuilder = QueryBuilders.rangeQuery("price").gte(350).lte(400); //构建价格range查询
//进行关系“与”查询
boolQueryBuilder.must(termQueryIsReady).must(rangeQueryBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder); //设置查询
printResult(searchRequest); //打印结果
}
2 should查询
当查询中包含should查询时,表示当前查询为“或”查询。命中的文档可以匹配该查询中的一个或多个子查询的结果,并且ES会将该查询与文档的匹配程度加入总得分里。should查询包含一个数组,可以把其他的term级别的查询及布尔查询放入其中。
以下示例使用should查询城市为北京或者天津的酒店。
GET /hotel/_search
{
"query": {
"bool": {
"should": [ //shoud查询,数组内可封装各类子查询
{ //第一个子查询:城市为北京
"term": {
"city": {
"value": "北京"
}
}
},
{ //第二个子查询:城市为天津
"term": {
"city": {
"value": "天津"
}
}
}
]
}
}
}
在Java客户端上构建should搜索时,可以使用QueryBuilders.boolQuery().should()进行构建,上面的例子改写成Java客户端请求的形式为:
public void shouldSearch() {
//新建搜索请求
val searchRequest = new SearchRequest("hotel");
val searchSourceBuilder = new SearchSourceBuilder();
val boolQueryBuilder = QueryBuilders.boolQuery();
//构建城市为“北京”的term查询
val termQueryIsReady = QueryBuilders.termQuery("city", "北京");
//构建城市为“天津”的term查询
val termQueryWritter = QueryBuilders.termQuery("city", "天津");
//进行关系“或”查询
boolQueryBuilder.should(termQueryIsReady).should(termQueryWritter);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder); //设置查询
printResult(searchRequest); //打印结果
}
3 must not查询
当查询中包含must not查询时,表示当前查询为“非”查询。命中的文档不能匹配该查询中的一个或多个子查询的结果,ES会将该查询与文档的匹配程度加入总得分里。must not查询包含一个数组,可以把其他term级别的查询及布尔查询放入其中。以下示例中使用must not查询城市不是北京也不是天津的酒店:
GET /hotel/_search
{
"query": {
"bool": {
"must_not": [ // must_not查询,数组内可封装各类子查询
{ //第一个子查询:城市为北京
"term": {
"city": {
"value": "北京"
}
}
},
{ //第二个子查询:城市为天津
"term": {
"city": {
"value": "天津"
}
}
}
]
}
}
}
在Java客户端上构建must_not搜索时,可以使用QueryBuilders.boolQuery().mustNot()方法进行构建,上面的例子改写成Java客户端请求的形式为:
public void mustNotSearch() {
//新建搜索请求
val searchRequest = new SearchRequest("hotel");
val searchSourceBuilder = new SearchSourceBuilder();
val boolQueryBuilder = QueryBuilders.boolQuery();
//构建城市为“北京”的term查询
val termQueryIsReady = QueryBuilders.termQuery("city", "北京");
//构建城市为“天津”的term查询
val termQueryWritter = QueryBuilders.termQuery("city", "天津");
//进行关系“必须不”查询
boolQueryBuilder.mustNot(termQueryIsReady).mustNot(termQueryWritter);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder); //设置查询
printResult(searchRequest); //打印结果
}
4 filter查询
filter查询即过滤查询,该查询是布尔查询里非常独特的一种查询。其他布尔查询关注的是查询条件和文档的匹配程度,并按照匹配程度进行打分;而filter查询关注的是查询条件和文档是否匹配,不进行相关的打分计算,但是会对部分匹配结果进行缓存。
GET /hotel/_search
{
"query": {
"bool": {
"filter": [ // filter查询,数组内可封装各类子查询
{ //第一个子查询:城市为北京
"term": {
"city": "北京"
}
},
{ //第一个子查询:满房状态为否
"term": {
"full_room": false
}
}
]
}
}
}
以上是请求城市为北京并且未满房的酒店的查询结果。
在Java客户端上构建filter搜索时,可以使用QueryBuilders.boolQuery().filter()进行构建,上面的例子改写成Java客户端请求的形式为:
public void filterSearch() {
SearchRequest searchRequest = new SearchRequest("hotel");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
boolQueryBuilder.filter( QueryBuilders.termQuery("city", "北京"));
boolQueryBuilder.filter(QueryBuilders.termQuery("full_room", false));
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
printResult(searchRequest);
}
6 filter查询原理
假设当前有5个文档,ES对于city字段的倒排索引结构如图4.6所示。

ES对于满房字段倒排的索引结构如图4.7所示。

下面以上一节的请求为例,讲解在ES内部执行filter查询的工作步骤。
当ES执行过滤条件时,会查询缓存中是否有city字段值为“北京”对应的bitset数据。bitset,中文为位图,它可以用非常紧凑的格式来表示给定范围内的连续数据。如果查询缓存中有对应的bitset数据,则取出备用;如果缓存中没有bitset数据,则ES在查询数据后会对查询条件进行bitset的构建并将其放入缓存中。同时,ES也会考察满房字段为false是否有对应的bitset数据。如果有,则取出备用;如果缓存中没有,ES也会进行bitset的构建。
假设city字段值为“北京”,缓存中没有对应的bitset数据,则bitset构建的过程如下:
首先,ES在倒排索引中查找字段city值为“北京”字符串的文档,这里为doc1和doc5。然后为所有文档构建bitset数组,数组中每个元素的值用来表示对应位置的文档是否和查询条件匹配,0表示未匹配,1表示匹配。在本例中,doc1和doc5匹配“北京”,对应位置的值为1;doc2、doc3、doc4不匹配,对应位置的值为0。最终,本例的bitset数组为[1,0,0,0,1]。之所以用bitset表示文档和query的匹配结果,是因为该结构不仅节省空间而且后续进行操作时也能节省时间。
如果满房字段缓存中没有对应的bitset数据,ES构建满房字段为false对应bitset的过程也是类似的。如图4.8所示为ES构建的字段city值为“北京”和满房字段值为false时对应的bitset结构。
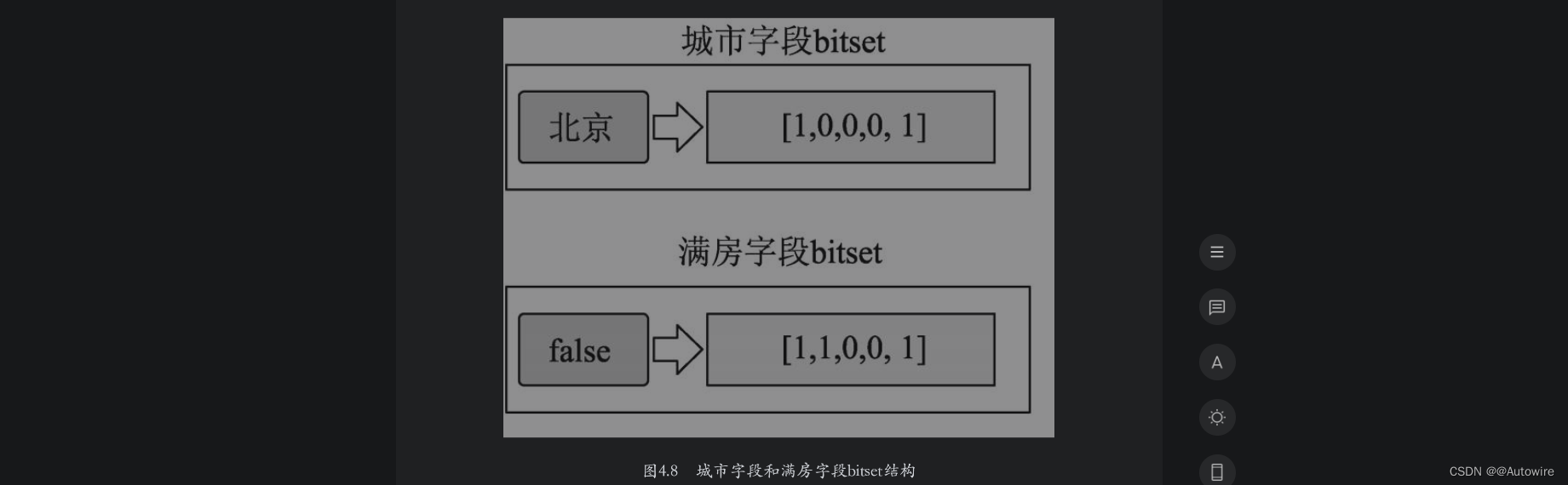
接下来ES会遍历查询条件的bitset数组,按照文档命中与否进行文档过滤。当一个请求中有多个filter查询条件时,ES会构建多个bitset数组。为提升效率,ES会从最稀疏的数组开始遍历,因为遍历稀疏的数组可以过滤掉更多的文档。此时,城市为“北京”对应的bitset比满房为false的bitset更加稀疏,因此先遍历城市为“北京”的bitset,再遍历满房为false的bitset。遍历的过程中也进行了位运算,每次运算的结果都逐渐接近符合条件的结果。遍历计算完这两个bitset后,得到匹配所有过滤条件的文档,即doc1和doc5。
正如上面的介绍,如果查询内包含filter,那么ES首先就从缓存中搜索这个filter条件是否有执行记录,是否有对应的bitset缓存可查询。如果有,则从缓存中查询;如果没有,则为filter中的每个查询项新建bitset,并且缓存该bitset,以供后续其他带有filter的查询可以先在缓存中查询。也就是说,ES对于bitset是可重用的,这种重用的机制叫作filter cache(过滤器缓存)。
filter cache会跟踪每一个filter查询,ES筛选一部分filter查询的bitset进行缓存。首先,这些过滤条件要在最近256个查询中出现过;其次,这些过滤条件的次数必须超过某个阈值。
另外,filter cache是有自动更新机制的,即如果有新增文档或者文档被修改过,那么filter cache对应的过滤条件中的bitset将被更新。例如城市为“北京”过滤条件对应的bitset为[1,0,0,0,1],如果文档4的城市被修改为“北京”,则“北京”过滤条件对应的bitset会被自动更新为[1,0,0,1,1]。
filter查询带来的效益远不止这些,使用filter查询的子句是不计算分数的,这可以减少不小的时间开销。
为提升查询效率,对于简单的term级别匹配查询,应该根据自己的实际业务场景选择合适的查询语句,需要确定这些查询项是否都需要进行打分操作,如果某些匹配条件不需要打分操作的话,那么应该把这些查询全部改成filter形式,让查询更高效。
7 Constant Score查询
如果不想让检索词频率TF(Term Frequency)对搜索结果排序有影响,只想过滤某个文本字段是否包含某个词,可以使用Constant Score将查询语句包装起来。
假设需要查询amenities字段包含关键词“停车场”的酒店,则请求的DSL如下:
GET /hotel/_search
{
"_source": ["amenities"],
"query": {
"constant_score": { //满足条件即打分为1
"filter": {
"match": { //查询设施中包含“停车场”的文档
"amenities": "停车场"
}
}
}
}
}
查询结果如下:
{
…
"hits" : {
"total" : {
"value" : 5, //命中的文档的个数
"relation" : "eq"
},
"max_score" : 1.0, //命中文档的最高分值为1.0
"hits" : [ //命中的文档集合
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_score" : 1.0, //每个命中的文档的得分都为1.0
"_source" : {
"amenities" : "浴池,普通停车场/充电停车场"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "002",
"_score" : 1.0, //每个命中的文档的得分都为1.0
"_source" : {
"amenities" : "wifi,充电停车场/可升降停车场"
}
},
…
]
}
}
通过结果可以看到,使用Constant Score搜索时,命中的酒店文档对应的amenities字段都包含有“停车场”一词。但是不论该词在文档中出现多少次,这些文档的得分都是一样的,值为1.0。在Constant Score搜索中,参数boost可以控制命中文档的得分,默认值为1.0。以下为更改boost参数为2.0的例子:
GET /hotel/_search
{
"_source": ["amenities"],
"query": {
"constant_score": {
"boost": 2.0, //设置Constant Score查询命中文档的得分为2.0
"filter": {
"match": {
"amenities": "停车场"
}
}
}
}
}
查询结果如下:
{
…
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 2.0, //命中文档的最高得分为2.0
"hits" : [
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_score" : 2.0, //每个命中文档的得分都为1.0
"_source" : {
"amenities" : "浴池,普通停车场/充电停车场"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "002",
"_score" : 2.0, //每个命中文档的得分都为1.0
"_source" : {
"amenities" : "wifi,充电停车场/可升降停车场"
}
},
…
}
]
}
}
根据搜索结果可以看到,设定boost值为2.0后,所有命中的文档得分都为2.0。
在Java客户端上构建Constant Score搜索时,可以使用ConstantScoreQueryBuilder类的实例进行构建,上面的Constant Score查询例子改写成Java客户端请求的形式为:
public void constantScoreSearch() {
//新建搜索请求
val searchRequest = new SearchRequest("hotel");
val searchSourceBuilder = new SearchSourceBuilder();
//构建设施包含“停车场”的constant score查询
val constantScoreQueryBuilder = new ConstantScoreQueryBuilder(QueryBuilders.termQuery("amenities", "停车场"));
searchSourceBuilder.query(constantScoreQueryBuilder);
constantScoreQueryBuilder.boost(2.0f);
searchRequest.source(searchSourceBuilder); //设置查询
printResult(searchRequest); //打印结果
}
8 Function Score查询
当使用ES进行搜索时,命中的文档默认按照相关度进行排序。有些场景下用户需要干预该“相关度”,此时就可以使用Function Score查询。使用时,用户必须定义一个查询以及一个或多个函数,这些函数为每个文档计算一个新分数。
下面使用一个随机函数对查询结果进行排序:
GET /hotel/_search
{
"_source": ["title","city"],
"query": {
"function_score": {
"query": { //查询符合条件的文档
"term": {
"city": {
"value": "北京"
}
}
},
"functions": [ //定义函数
{ //此处只定义了一个函数:随机数函数
"random_score": {}
}
],
"score_mode": "sum" //最终分数是各个函数的加和值
}
}
}
上述请求使用了Function Score查询,其中,query子句负责对文档进行匹配,本例使用了简单的term查询,functions子句负责输出对文档的排序分值,此处使用了random_score随机函数,使得每个文档的分数都是随机生成的。每次执行上述查询时生成的文档分数都不同。以下为某次搜索的结果:
{
…
"hits" : {
…
"hits" : [
{
…
"_id" : "004",
"_score" : 0.4921564, //分数为随机值
"_source" : {
…
}
},
{
…
"_id" : "002",
"_score" : 0.36784336, //分数为随机值
"_source" : {
…
}
},
{
…
"_id" : "005",
"_score" : 0.05952649, //分数为随机值
"_source" : {
…
}
}
]
}
}
在Java客户端中使用Function Score进行查询时,可以调用ScoreFunctionBuilders.randomFunction()方法新建一个随机函数,然后将该随机函数的实例传给QueryBuilders.functionScoreQuery()方法生成FunctionScoreQueryBuilder的实例,最终由该实例完成搜索。以下是使用Java客户端的Function Score进行查询的例子,其排序结果和上述使用Function Score进行查询的示例相似,即文档的得分是通过随机函数生成的。
public void functionScoreSearch() {
//创建搜索请求
val searchRequest = new SearchRequest("hotel");
val searchSourceBuilder = new SearchSourceBuilder();
//构建term查询
val termQuery = QueryBuilders.termQuery("city", "北京");
ScoreFunctionBuilder<?> scoreFunction = ScoreFunctionBuilders.randomFunction(); //构建随机函数
//构建Function Score查询
val funcQuery = QueryBuilders.functionScoreQuery(termQuery, scoreFunction)
.boostMode(CombineFunction.SUM);
searchSourceBuilder.query(funcQuery);
searchRequest.source(searchSourceBuilder); //设置查询请求
printResult(searchRequest); //打印搜索结果
}
Function Score查询提供了很多实用函数,能满足绝大多数的用户自定义打分需求。在后面的排序相关章节中将会对Function Score查询展开介绍。
9 全文搜索
不同于结构化查询,全文搜索首先对查询词进行分析,然后根据查询词的分词结果构建查询。这里所说的全文指的是文本类型数据(text类型),默认的数据形式是人类的自然语言,如对话内容、图书名称、商品介绍和酒店名称等。结构化搜索关注的是数据是否匹配,全文搜索关注的是匹配的程度;结构化搜索一般用于精确匹配,而全文搜索用于部分匹配。本节将详细介绍使用最多的全文搜索。
1 match查询
match查询是全文搜索的主要代表。对于最基本的math搜索来说,只要分词中的一个或者多个在文档中存在即可。例如搜索“金都酒店”,查询词先被分词器切分为“金”“都”“酒”“店”,因此,只要文档中包含这4个字中的任何一个字,都会被搜索到。
读者可能会有疑问,为什么“金都酒店”被切分成4个字而不是“金都”“酒店”两个词呢?这是因为在默认情况下,match查询使用的是标准分词器。该分词器比较适用于英文,如果是中文则按照字进行切分,因此默认的分词器不适合做中文搜索,在后面的章节中将介绍如何安装和使用中文分词器。
以下示例为按照标题搜索“金都酒店”:
GET /hotel/_search
{
"_source": ["title"], //只返回title字段
"query": {
"match": { //匹配title字段为“金都酒店”的文档
"title": "金都酒店"
}
}
}
或者按照如下方式搜索:
GET /hotel/_search
{
"_source": ["title"], //只返回title字段
"query": {
"match": { //匹配title字段为“金都酒店”的文档
"title": {
"query": "金都酒店"
}
}
}
}
搜索结果如下:
{
…
"hits" : {
…
"max_score" : 1.4177237,
"hits" : [
{
…
"_id" : "004",
"_score" : 1.4177237,
"_source" : {
"title" : "金都酒店"
}
},
{
…
"_id" : "003",
"_score" : 1.2164695,
"_source" : {
"title" : "金都欣欣酒店"
}
},
{
…
"_id" : "002",
"_score" : 1.065251,
"_source" : {
"title" : "金都嘉怡假日酒店"
}
},
{
…
"_id" : "001",
"_score" : 0.19705516,
"_source" : {
"title" : "文雅酒店"
}
},
{
…
"_id" : "005",
"_score" : 0.16908203,
"_source" : {
"title" : "文雅精选酒店"
}
}
]
}
}
从结果中可以看到,匹配度最高的文档是004,该酒店的名称和查询词相同,得分为1.4177237;次之的文档是003,因为该酒店名称中包含“金”“都”“酒”“店”,并且标题相对较短,所以部分匹配,得分为1.2164695;再次之的文档是002,虽然该酒店名称中包含“金”“都”“酒”“店”,但是相对于文档003其标题相对较长,因此位居其后。文档001和文档005只有“酒”“店”两个字和查询词部分匹配,因此排在后面,又因为文档005比文档001较长,所以位居最后。
假设用户搜索“金都”是想搜索名称中同时包含“金”和“都”的酒店,而不需要命中名称中包含“酒”或“店”的酒店。显然,文档001和文档005不是用户想命中的文档。match搜索可以设置operator参数,该参数决定文档按照分词后的词集合进行“与”还是“或”匹配。在默认情况下,该参数的值为“与”关系,即operator的值为and,这也解释了搜索结果中包含部分匹配的文档。如果希望各个词之间的匹配结果是“与”关系,则可以设置operator参数的值为and。
下面的请求示例设置查询词之间的匹配结果为“与”关系:
GET /hotel/_search
{
"_source": ["title"],
"query": {
"match": {
"title":{
"query": "金都",
"operator":"and" //查询词之间的匹配结果为“与”关系
}
}
}
}
此时,搜索结果中只有同时包含“金”和“都”的文档,返回结果如下:
{
…
"hits" : {
…
"max_score" : 1.2206686,
"hits" : [ //命中的文档标题同时包含“金”和“都”
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "004",
"_score" : 1.2206686,
"_source" : {
"title" : "金都酒店"
}
},
…
]
}
}
有时搜索多个关键字,关键词和文档在某一个比例上匹配即可,如果使用“与”操作过于严苛,如果使用“或”操作又过于宽松。这时可以采用minimum_should_match参数,该参数叫作最小匹配参数,其值为一个数值,意义为可以匹配上的词的个数。在一般情况下将其设置为一个百分数,因为在真实场景中并不能精确控制具体的匹配数量。以下示例设置最小匹配为80%的文档:
GET /hotel/_search
{
"_source": ["title"],
"query": {
"match": {
"title": { //match搜索条件
"query": "金都",
"operator": "or",
"minimum_should_match": "80%" //设置最小匹配度为80%
}
}
}
}
在Java客户端上可以使用QueryBuilders.matchQuery()方法构建match请求,分别给该方法传入字段名称和查询值即可进行match查询。以下代码展示了match请求的使用逻辑:
public void matchSearch() {
val searchRequest = new SearchRequest(); //新建搜索请求
val searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.matchQuery("title", "金都")
.operator(Operator.AND)); //新建match查询,并设置operator值为and
searchRequest.source(searchSourceBuilder); //设置查询
printResult(searchRequest); //打印结果
}
2 multi_match查询
有时用户需要在多个字段中查询关键词,除了使用布尔查询封装多个match查询之外,可替代的方案是使用multi_match。可以在multi_match的query子句中组织数据匹配规则,并在fields子句中指定需要搜索的字段列表。
下面的示例在title和amenities两个字段中同时搜索“假日”关键词:
GET /hotel/_search
{
"_source": ["title","amenities"],
"query": {
"multi_match": {
"query": "假日", //匹配关键字为“假日”
"fields": [ //设置匹配的字段为title和amenities
"title",
"amenities"
]
}
}
}
搜索结果如下:
{
…
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 2.358998,
"hits" : [
{ //title字段匹配“假日”
…
"_id" : "002",
"_score" : 2.358998,
"_source" : {
"amenities" : "wifi,充电停车场/可升降停车场",
"title" : "金都嘉怡假日酒店"
}
},
{ // amenities字段匹配“假日”
…
"_id" : "003",
"_score" : 1.0720664,
"_source" : {
"amenities" : "提供假日party,免费早餐,可充电停车场",
"title" : "金都欣欣酒店"
}
},
…
]
}
}
根据结果可以看到,命中的文档要么在title中包含“假日”关键词,要么在amenities字段中包含“假日”关键词。
在Java客户端上可以使用QueryBuilders.multiMatchQuery()方法构建multi_match请求,分别给该方法传入查询值和多个字段名称即可进行multi_match查询。以下代码展示了multi_match请求的使用逻辑:
public void multiMatchSearch() {
SearchRequest searchRequest = new SearchRequest(); //新建搜索请求
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(QueryBuilders.multiMatchQuery("假日", "title",
"amenities")); //新建multi_match查询,从"title"和"amenities"字段查询"假日"
searchRequest.source(searchSourceBuilder); //设置查询
printResult(searchRequest); //打印结果
}
3 match_phrase查询
match_phrase用于匹配短语,与match查询不同的是,match_phrase用于搜索确切的短语或邻近的词语。假设在酒店标题中搜索“文雅酒店”,希望酒店标题中的“文雅”与“酒店”紧邻并且“文雅”在“酒店”前面,则使用match_phrase查询的DSL如下:
GET /hotel/_search
{
"query": {
"match_phrase": {
"title": "文雅酒店"
}
}
}
结果如下:
{
…
"hits" : {
…
"max_score" : 2.1797345,
"hits" : [
{
…
"_id" : "001",
"_score" : 2.1797345,
"_source" : {
"title" : "文雅酒店",
…
}
}
]
}
}
根据上述结果可知,使用match_phrase查询后,只有文档001命中,而文档005(酒店标题为“文雅精选酒店”)没有命中,这是为什么呢?
ES在构建索引时,文档001的title字段被切分为“文雅”“酒店”,文档005的title字段被切分为“文雅”“精选”“酒店”。
使用match_phrase进行查询时,ES将查询文本“精选酒店”切分为“文雅”“酒店”,“文雅”匹配时命中了文档001和文档005,但是“酒店”匹配时要求“酒店”必须在“文雅”之后并且索引位置和“文雅”之差为1,而文档001符合匹配要求但是文档005不符合要求。
如果需要文档005也命中上述查询,则可以设置match_phrase查询的slop参数,它用来调节匹配词之间的距离阈值。下面的DSL将slop设置为2:
GET /hotel/_search
{
"query": {
"match_phrase": {
"title": {
"query": "文雅酒店",
"slop": 2 //将“文雅”和“酒店”之间的最大匹配距离设置为2
}
}
}
}
在Java客户端上可以使用QueryBuilders.matchPhraseQuery()方法构建match_phrase请求,分别给该方法传入查询字段和值即可进行multi_match查询。以下代码展示了match_phrase请求的使用逻辑:
public void matchPhraseSearch() {
SearchRequest searchRequest = new SearchRequest(); //新建搜索请求
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//新建match_phrase查询,并设置slop值为2
QueryBuilder matchPhraseQueryBuilder = QueryBuilders.matchPhraseQuery
("title", "文雅酒店").slop(2);
searchSourceBuilder.query(matchPhraseQueryBuilder);
searchRequest.source(searchSourceBuilder); //设置查询
printResult(searchRequest); //打印结果
}
4 基于地理位置查询
随着互联网+的热门,越来越多的传统行业将全部或者部分业务转移到互联网上,其中不乏一些和地理位置强相关的行业。基于地理位置的搜索功能,大大提升了人们的生活和工作效率。例如,外出旅行时,只需要用手机打开订酒店的应用软件,查找附近心仪的酒店下单即可;又或者打车行业,人们不用在寒冷的户外去拦截出租车,只需要在室内打开手机里的打车App定位到当前位置,然后确定目的地,系统就可以为附近的车辆派发订单。
幸运的是,ES为用户提供了基于地理位置的搜索功能。它主要支持两种类型的地理查询:一种是地理点(geo_point),即经纬度查询,另一种是地理形状查询(geo_shape),即支持点、线、圆形和多边形查询等。
从实用性上来说,地理点(即geo_point)数据类型的使用更多一些,因为篇幅所限,本节只对地理点类型进行详细介绍。
对应于geo_point字段类型的查询方式有3种,分别为geo_distance查询、geo_bounding_box查询和geo_polygon。
geo_distance查询方式需要用户指定一个坐标点,在指定距离该点的范围后,ES即可查询到相应的文档。假设北京天安门的经纬度为[116.4039,39.915143],以下为使用geo_distance查询所找到的天安门5km范围内的酒店:
GET /hotel/_search
{
"_source": [ //只返回部分字段
"title",
"city",
"location"
],
"query": {
"geo_distance": {
"distance": "5km", //设置距离范围为5km
"location": { //设置中心点经纬度
"lat": "39.915143", //设置纬度
"lon": "116.4039" //设置经度
}
}
}
}
Java客户端使用QueryBuilders.geoDistanceQuery()方法构建geo_distance请求,同时可以设置基准点坐标和周边距离。以下代码展示了geo_distance请求的使用逻辑:
public void geoDistanceSearch() {
//新建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//新建geo_distance查询,设置基准点坐标和周边距离
searchSourceBuilder.query(QueryBuilders.geoDistanceQuery("location").
distance(5, DistanceUnit.KILOMETERS).point(40.026919, 116.47473));
searchRequest.source(searchSourceBuilder); //设置查询
printResult(searchRequest); //打印结果
}
geo_shape查询提供的是矩形内的搜索,需要用户给出左上角的顶点地理坐标和右下角的顶点地理坐标。假设定义国贸商圈为一个矩形,其左上角顶点的经纬度为[116.457044,39.922821],右下角顶点的经纬度为[116.479466,39.907104],则在国贸商圈内搜索酒店的DSL如下:
GET /hotel/_search
{
"query": {
"geo_bounding_box": {
"location": {
"top_left": { //设置左上角的顶点坐标
"lat": "39.922821",
"lon": "116.457044"
},
"bottom_right": { //设置右下角的顶点坐标
"lat": "39.907104",
"lon": "116.479466"
}
}
}
}
}
geo_polygon比geo_shape提供的地理范围功能更加灵活,它支持多边形内的文档搜索,使用该查询需要提供多边形所有顶点的地理坐标。假设北京地坛公园商圈的地形为三角形,该三角形的三个顶点的经纬度分别为[116.417088,39.959829]、[116.432035,39.960272]和[116.421399,39.965802],则在地坛公园商圈内搜索酒店的DSL语句如下:
GET /hotel/_search
{
"query": {
"geo_polygon": {
"location": {
"points": [
{ //设置三角形的第1个顶点坐标
"lat": "39.959829",
"lon": "116.417088"
},
{ //设置三角形的第2个顶点坐标
"lat": "39.960272",
"lon": "116.432035"
},
{ //设置三角形的第3个顶点坐标
"lat": "39.965802",
"lon": "116.421399"
}
]
}
}
}
}
Java客户端使用QueryBuilders.geoPolygonQuery()方法构建geo_polygon请求,在构建请求之前,需要将多边形的顶点事先准备好。以下代码展示了geo_polygon请求的使用逻辑:
public void geoPolygonSearch() {
//新建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel");
//新建geo_distance查询,设置基准点坐标和周边距离
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//新建多边形顶点列表
List<GeoPoint> geoPointList = new ArrayList<GeoPoint>();
//添加多边形顶点
geoPointList.add(new GeoPoint(39.959829, 116.417088));
geoPointList.add(new GeoPoint(39.960272, 116.432035));
geoPointList.add(new GeoPoint(39.965802, 116.421399));
searchSourceBuilder.query(QueryBuilders.geoPolygonQuery("location",
geoPointList)); //新建geo_polygon查询
searchRequest.source(searchSourceBuilder); //设置查询
printResult(searchRequest); //打印结果
}
5 搜索建议
搜索建议,顾名思义,即在用户输入搜索关键词的过程中系统进行自动补全,用户可以根据自己的需求单击搜索建议的内容直接进行搜索。在搜索时,用户每输入一个字符,前端就需要向后端发送一次查询请求对匹配项进行查询,因此这种场景对后端响应速度的要求比较高。通过协助用户进行搜索,可以避免用户输入错误的关键词,引导用户使用更合适的关键词,提升用户的搜索体验和搜索效率。
搜索建议目前是各大搜索引擎和电商的标配服务,如图4.9所示为在京东商城中输入elastic时的搜索建议示例。
那么类似的功能在ES中是如何实现呢?答案就是ES的搜索建议查询。对于以上应用来说,ES中的Completion Suggester是比较合适的。为了使用Completion Suggester,其对应的字段类型需要定义为completion类型。在以下示例中定义了一个酒店搜索建议的索引:
PUT /hotel_sug
{
"mappings": {
"properties": {
"query_word": { //定义query_word字段,类型为completion
"type": "completion"
}
}
}
}
为方便演示,现在向索引中写入一些候选数据:
POST /_bulk
{"index":{"_index":"hotel_sug","_id":"001"}}
{"query_word":"如家酒店"}
{"index":{"_index":"hotel_sug","_id":"002"}}
{"query_word":"如家快捷酒店"}
{"index":{"_index":"hotel_sug","_id":"003"}}
{"query_word":"如家精选酒店"}
{"index":{"_index":"hotel_sug","_id":"004"}}
{"query_word":"汉庭假日酒店"}
假设用户输入“如家”关键词,需要ES给出前缀为该词的酒店查询词,DSL如下:
GET /hotel_sug/_search
{
"suggest": {
"hotel_zh_sug": { //定义搜索建议名称
"prefix": "如家", //设置搜索建议的前缀
"completion": { //设置搜索建议对应的字段名称
"field": "query_word"
}
}
}
}
在上述查询中,hotel_zh_sug定义的是搜索建议的名称,prefix定义的是用户输入的关键词,completion.field定义的是搜索建议的候选集对应的字段名称。
{
…
"hits" : {
…
"hits" : [ ]
},
"suggest" : {
"hotel_zh_sug" : [ //搜索建议的名称
{
"text" : "如家", //搜索建议的前缀
"offset" : 0,
"length" : 2,
"options" : [ //匹配的文档集合
{
"text" : "如家快捷酒店", //匹配的文档字段内容
…
"_score" : 1.0,
"_source" : {
"query_word" : "如家快捷酒店"
}
},
{
"text" : "如家精选酒店", //匹配的文档字段内容
…
"_score" : 1.0,
"_source" : {
"query_word" : "如家精选酒店"
}
},
{
"text" : "如家酒店", //匹配的文档字段内容
…
"_score" : 1.0,
"_source" : {
"query_word" : "如家酒店"
}
}
]
}
]
}
}
和普通搜索不同的是,搜索建议的结果不是封装在hits中,而是单独封装在suggest中。在suggest.hotel_zh_sug.options中可以看到每一个候选集的文档信息。
在Java客户端上可以使用SuggestBuilder方法构建搜索建议请求。使用suggestBuilder.addSuggestion()方法添加具体的搜索建议,第1个参数为自定义名称,对于第2个参数可以新建一个CompletionSuggestionBuilder实例对该方法进行传参。获取搜索建议结果时,可以通过SearchResponse.getSuggest().getSuggestion()方法获取completion类型的搜索建议结果,然后进行遍历即可。以下为Java查询搜索建议结果的使用示例:
public void suggestSearch() throws IOException {
//创建搜索请求,指定索引名称为hotel_sug
SearchRequest searchRequest = new SearchRequest("hotel_sug");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//创建completion类型的搜索建议
CompletionSuggestionBuilder comSuggest = SuggestBuilders.
completionSuggestion("query_word").prefix("如家");
SuggestBuilder suggestBuilder = new SuggestBuilder();
//添加搜索建议,"hotel_zh_sug"为自定义名称
suggestBuilder.addSuggestion("hotel_zh_sug", comSuggest);
searchSourceBuilder.suggest(suggestBuilder); //设置搜索建议请求
searchRequest.source(searchSourceBuilder); //设置查询请求
SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT); //进行搜索,获取搜索结果
CompletionSuggestion suggestion = response.getSuggest().getSuggestion
("hotel_zh_sug"); //获取搜索建议结果
System.out.println("sug result:");
//遍历搜索建议结果并进行打印
for (CompletionSuggestion.Entry.Option option : suggestion.
getOptions()) {
System.out.println("sug:" + option.getText().string());
}
}
需要注意的是,ES提供的Completion Suggester功能使用的索引结构不是倒排索引,而是在内存中构建FST(Finite StateTransducers)。构建该数据结构是有比较大的内存存储成本的,因此在生产环境中向索引中添加数据时一定要关注ES节点的内存消耗,避免数据量过大造成ES节点内存耗尽从而影响集群服务。
10 按字段值排序
在默认情况下,ES对搜索结果是按照相关性降序排序的。有时需要按照某些字段的值进行升序或者降序排序。例如在酒店搜索应用软件中,除了可以按照综合排序外,还可以按照价格、销量、评论数、距离进行升/降序排序。之所以提供这样的功能,是因为存在多种不同的心态促使用户并不只想按照关键词匹配对结果进行浏览。用户单击价格进行升序或降序排列,很可能说明该用户对酒店价格比较敏感;用户按照销量或评论数进行升序或降序排列,很可能说明用户有一些从众心理,希望通过销量或评论数来评估大众对该酒店是否看好,从而筛选心仪的酒店;用户按照距离进行排序,很可能是该用户需要找到距离匹配的酒店。
如图4.11所示为在“艺龙网”输入关键词“如家”后的搜索页面。
ES提供了sort子句可以对数据进行排序。使用sort子句一般是按照字段信息进行排序,不受相关性影响,而且打分步骤需要耗费一定的硬件资源和时间,因此默认情况下,不对文档进行打分。使用sort排序分为两种类别,一种是按照字段值的大小进行排序,另一种是按照给定地理坐标的距离远近进行排序。
1 按普通字段值排序
使用sort子句对字段值进行排序时需要指定排序的字段。ES默认是按照字段值进行升序排序,可以设置order参数为asc或desc,指定按照字段值进行升序或者降序排序。
以下示例为搜索名称包含“金都”的酒店,并对酒店按照价格进行降序排列。
GET /hotel/_search
{
"_source": [ //只返回部分字段
"title",
"price"
],
"query": { //搜索条件
"match": {
"title": "金都"
}
},
"sort": [
{ //按照价格降序排列
"price": {
"order": "desc"
}
}
]
}
执行上述DSL后,搜索结果如下:
{
…
"hits" : {
…
"max_score" : null, //按字段排序时,各文档不进行打分,得分都为null
"hits" : [
{
…
"_score" : null,
"_source" : {
"price" : 500.0,
"title" : "金都酒店"
},
"sort" : [ //显示排序字段的值
500.0
]
},
{
…
"_score" : null,
"_source" : {
"price" : 337.0,
"title" : "金都嘉怡假日酒店"
},
"sort" : [ //显示排序字段的值
337.0
]
},
{
…
"_score" : null,
"_source" : {
"price" : 200.0,
"title" : "金都欣欣酒店"
},
"sort" : [ //显示排序字段的值
200.0
]
}
]
}
}
从上面的结果中可以看到,使用sort对搜索结果排序后,在每个文档的_source信息下面多出了一个sort信息,该信息中显示了当前文档排序字段的值。另外,文档的_score值和max_score都为null,这说明在默认情况下ES查询时使用sort对结果排序是不计算分数的。也可以使用sort对搜索结果按照多个字段进行排序。
例如,用户可以按照价格进行降序排列,然后再按照口碑值进行降序排列,对应的DSL如下:
GET /hotel/_search
{
"_source": [ //返回部分字段
"title",
"price",
"praise"
],
"query": { //查询条件
"match": {
"title": "金都"
}
},
"sort": [
{
"price": { //按照价格进行降序排列
"order": "desc"
},
"praise": { //按照口碑进行降序排列
"order": "desc"
}
}
]
}
在Java客户端中对搜索结果进行排序时,可以一次或者多次调用searchSourceBuilder.sort()方法添加一个或多个排序条件。对应上面的排序DSL,Java代码如下:
public void commonSort(){
//创建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建match查询
searchSourceBuilder.query(QueryBuilders.matchQuery("title","金都"));
searchRequest.source(searchSourceBuilder); //设置查询请求
//设置按照价格进行降序排序
searchSourceBuilder.sort("price",SortOrder.DESC);
//设置按照口碑值进行降序排序
searchSourceBuilder.sort("praise",SortOrder.DESC);
printResult(searchRequest); //打印搜索结果
}
2 按地理距离排序
前面我们介绍了ES提供的基于地理位置的查询功能,使用geo_distance查询,配合sort可以指定另一种排序规则,即按照文档坐标与指定坐标的距离对结果进行排序。使用时,需要在sort内部指定排序名称为geo_distanc,并指定目的地坐标。除了可以指定升序或者降序排列外,还可以指定排序结果中sort子句中的距离的计量单位,默认值为km即千米。在进行距离计算时,系统默认使用的算法为arc,该算法的特点是计算精准但是耗费时间较长,用户可以使用distance_type参数选择另一种计算速度快但经度略差的算法,名称为plane。
如下示例使用geo_distance查询天安门5km范围内的酒店,并按照距离由近及远进行排序:
GET /hotel/_search
{
"_source": [ //返回部分字段
"title",
"city",
"location"
],
"query": {
"geo_distance": {
"distance": "5km", //设置地理范围为5km
"location": { //设置中心点坐标
"lat": "39.915143",
"lon": "116.4039"
}
}
},
"sort": [ //设置排序逻辑
{
"_geo_distance": {
"location": { //设置排序的中心点坐标
"lat": "39.915143",
"lon": "116.4039"
},
"order": "asc", //按距离由近到远进行排序
"unit": "km", //排序所使用的距离的计量单位
"distance_type": " plane " //排序所使用的距离计算算法
}
}
]
}
搜索结果如下:
{
…
"hits" : {
…
"max_score" : null, //按距离排序时,各文档不进行打分,得分都为null
"hits" : [
{
…
"_score" : null,
"_source" : {
"city" : "北京",
"location" : {
"lon" : 116.403,
"lat" : 39.915153
},
"title" : "金都嘉怡假日酒店"
},
"sort" : [
0.07677101525356582 //排序的距离值
]
},
…
]
}
}
在Java客户端中对geo_distance的搜索结果进行排序时,可以调用SortBuilders.geo DistanceSort()方法新建geo_distance查询对象的实例,然后将该实例传给searchSource Builder.sort()方法即可完成按照距离排序的要求。对应上面的排序DSL,Java代码如下:
public void geoDistanceSearchSort() throws IOException {
//创建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//创建geo_distance查询,搜索距离中心点5km范围内的酒店
searchSourceBuilder.query(QueryBuilders.geoDistanceQuery("location").
distance(5, DistanceUnit.KILOMETERS).point(39.915143, 116.4039));
//创建geo_distance_sort排序,设定按照与中心点的距离进行升序排序
GeoDistanceSortBuilder geoDistanceSortBuilder = SortBuilders.
geoDistanceSort("location", 39.915143, 116.4039)
.point(39.915143, 116.4039).unit(DistanceUnit.KILOMETERS).
order(SortOrder.ASC);
searchSourceBuilder.sort(geoDistanceSortBuilder); //设置排序规则
searchRequest.source(searchSourceBuilder); //设置查询
//开始搜索
SearchResponse searchResponse = client.search(searchRequest, Request
Options.DEFAULT);
SearchHits searchHits = searchResponse.getHits(); //获取搜索结果
System.out.println("search result distance sort:");
//开始遍历搜索结果
for (SearchHit searchHit : searchHits) {
//得到酒店距离中心点的距离
double geoDistance = (double) searchHit.getSortValues()[0];
//以Map形式获取文档_source内容
Map<String, Object> sourceMap = searchHit.getSourceAsMap();
Object title = sourceMap.get("title");
Object city = sourceMap.get("city");
//打印结果
System.out.println("title=" + title + ",city=" + city + ",geoDistance:"
+ geoDistance);
}
}
通过对比可以看到,使用Java和使用DSL获取的文档顺序和距离的计算值都是一致的,这也验证了编码的正确性。在实际开发过程中,往往需要先写出符合需求的查询的DSL,然后对照DSL进行Java编码,最后再通过对比两方的结果是否一致来判定程序正确与否。