lamada表达式格式
格式:( parameter-list ) -> { expression-or-statements }
实例:简化匿名内部类的写法
原本写法:
public class LamadaTest {
public static void main(String[] args) {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println("沉默王二");
}
}).start();
}
}
直接通过lamada表达式可以改写成:
public class LamadaTest {
public static void main(String[] args) {
new Thread(() -> {System.out.println("沉默王二")}.start();
}
}
2 结合foreach替代for循环
List<Student> stus = Lists.newArrayList();//假设stus里面有数据,这里就不添加了
stus.foreach(stu->system.out.println(stu.getName()));
或者采用如下遍历方式:
for(Student stu : stus){
system.out.println(stu.getName());
}
lamada实现排序
Collections.sort(list,(Integer o1,Integer o2) ->{
return o2-o1;
}) //降序
stream流相关
https://blog.csdn.net/anyi2351033836/article/details/125027710
filter操作
方法的定义,源码如下Stream filter(Predicate< super T> predicate);一个单纯的过滤操作直接返回传入类型
String[] dd = { “a”, “b”, “c” };
Stream stream = Arrays.stream(dd);
stream.filter(str -> str.equals(“a”)).forEach(System.out::println);//返回字符串为a的值
stream项目实例:
CppBankExercise cppBankExercise = exerciseList.stream().filter(exercise -> Objects.equals(projectId, exercise.getProjectId())).findFirst().orElse(null);
map操作
先看方法定义,源码如下** Stream map(Function< super T, extends R> mapper);**
这个方法传入一个Function的函数式接口,这个接口,接收一个泛型T,返回泛型R,map函数的定义,返回的流,表示的泛型是R对象,这个表示,调用这个函数后,可以改变返回的类型
Integer[] dd = { 1, 2, 3 };
Stream<Integer> stream = Arrays.stream(dd);
stream.map(str -> Integer.toString(str)).forEach(str -> {
System.out.println(str);// 1 ,2 ,3
System.out.println(str.getClass());// class java.lang.String
});
List<String> list = Arrays.asList(bankProjectQueryDto.getArithmeticLabel().split(",")).stream().map(label -> labelBiz.getArithmeticLabelById(label)).collect(Collectors.toList());
总结:无论是经过filte\map都是返回的stream
stream转化成clollector的方法
1️ collect是Stream流的一个终止方法,会使用传入的收集器(入参)对结果执行相关的操作,这个收集器必须是Collector接口的某个具体实现类
2️ Collector是一个接口,collect方法的收集器是Collector接口的具体实现类
3️ Collectors是一个工具类,提供了很多的静态工厂方法, 提供了很多Collector接口的具体实现类,是为了方便程序员使用而预置的一些较为通用的收集器(如果不使用Collectors类,而是自己去实现Collector接口,也可以)
又可将收集器分为几种不同的大类:恒等 归约 分组,如下图
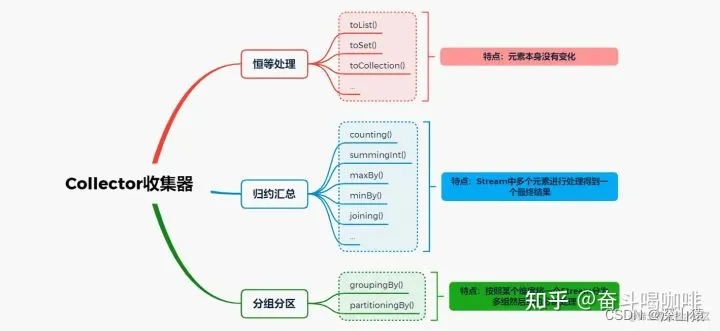
恒等,例如toList()操作,只是最终将结果从Stream中取出放入到List对象中,并没有对元素本身做任何的更改处理,如:
list.stream().collect(Collectors.toList());
list.stream().collect(Collectors.toSet());
list.stream().collect(Collectors.toCollection());
归约,如Collectors.summingInt(),Stream流中的元素逐个遍历,进入到Collector处理函数中,然后会与上一个元素的处理结果进行合并处理,并得到一个新的结果
例1:计算总薪资
public void calculateSum() {
Integer salarySum = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(Collectors.summingInt(Employee::getSalary));
System.out.println(salarySum);
}
例2:找薪资最高的员工
Optional<Employee> highestSalaryEmployee = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.max(Comparator.comparingInt(Employee::getSalary));
分组
常规的数据分组操作时,可以仅传入一个分组函数,这样collect返回的结果,就是一个HashMap,其每一个HashValue的值为一个List类型。
// 按照子公司维度将员工分组
Map<String, List<Employee>> resultMap = getAllEmployees()
.stream().collect(Collectors.groupingBy(Employee::getSubCompany));
collect返回的结果,就是一个HashMap,其每一个HashValue的值为一个List类型。
如果不仅需要分组,还需要对分组后的数据进行处理的时候,则需要同时给定分组函数以及值收集器:
public void groupAndCaculate() {
// 按照子公司分组,并统计每个子公司的员工数
Map<String, Long> resultMap = getAllEmployees().stream()
.collect(Collectors.groupingBy(Employee::getSubCompany,
Collectors.counting()));
System.out.println(resultMap);
}
public void filterEmployeesThenGroupByStream() {
Map<String, List<Employee>> resultMap = getAllEmployees().stream()
.filter(employee -> "上海公司".equals(employee.getSubCompany()))
.collect(Collectors.groupingBy(Employee::getDepartment));
System.out.println(resultMap);
}
public void streamFilterAndMap(){
List<String> addressList = data.toJavaList(DecrepitHouseInfo.class).stream().filter(item -> {
//filter 过滤目标,返回值true:保留 返回值false:不保留
return "C".equals(item.getType()) && "泥木结构".equals(item.getType2());
}).map(item ->{
//map 映射 可改变数据结构,添加、删除、组合数据均可
return item.getCity()+item.getStreet();
}).collect(Collectors.toList());
System.out.println(JSON.toJSON(addressList));
}
for循环、foreache、stream性能对比
普通for循环、foreache、stream三种方式性能差别不大,甚至在少量数据的时候stream效率低于for循环,但是stream写法更简洁、提供了并发处理的方式、且丰富的功能可以简化代码。
stream的parallelStream
如果要操作的集合很大,如针对答题结果的数据统计,则可以使用并发流,充分利用机器多核的特性,实例如下:
List<CompStuInfoReq> registerReqs = notRegister.parallelStream().map(userEntry ->
CompStuInfoReq.builder()
.secretKey(Constants.UC_SECRET_KEY)
.userId(userEntry.getUserId())
.competitionId(userEntry.getCompetitionId())
.passwordSalt(userEntry.getPasswordSalt())
.passwordHash(userEntry.getPasswordHash())
.mobile(userInfoService.getDecryptMsg(userEntry.getMobile()))
.name(userEntry.getName())
.identity(userEntry.getIdentity())
.build())
.collect(Collectors.toList());
说明:
parallelStream默认使用了fork-join框架,其默认线程数是CPU核心数。也可以通过如下方式指定:
1.全局设置
在运行代码之前,加入如下代码:
System.setProperty("java.util.concurrent.ForkJoinPool.common.parallelism", "64");
一般不建议修改,因为修改虽然改进当前的业务逻辑,但对于整个项目中其它地方只是用来做非耗时的并行流运算,性能就不友好了,因为所有使用并行流parallerStream的地方都是使用同一个Fork-Join线程池,而Fork-Join线程数默认仅为cpu的核心数。最好是自己创建一个Fork-Join线程池来用,即下面的方法2。
2.默认优先用在CPU密集型计算中
这里有的人就说了,用在IO密集比如HTTP请求啊什么的这种耗时高的操作并行去请求不是效果显著吗
由于默认并行流使用的是全局的线程池,线程数量是根据cpu核数设置的,所以如果某个操作占用了线程,将影响全局其他使用并行流的操作
所以IO密集型场景的正确用法是自定义线程池来执行某个并行流操作
ForkJoinPool forkJoinPool = new ForkJoinPool(10);
forkJoinPool.execute(() -> {
listByPage.parallelStream().forEach(str -> {
});
});