文本相似度插件开发,本文基于Elasticsearch5.5.1,Kibana5.5.1
下载地址为:
Past Releases of Elastic Stack Software | Elastic
本地启动两个服务后,localhost:5601打开Kibana界面,点击devTools,效果图
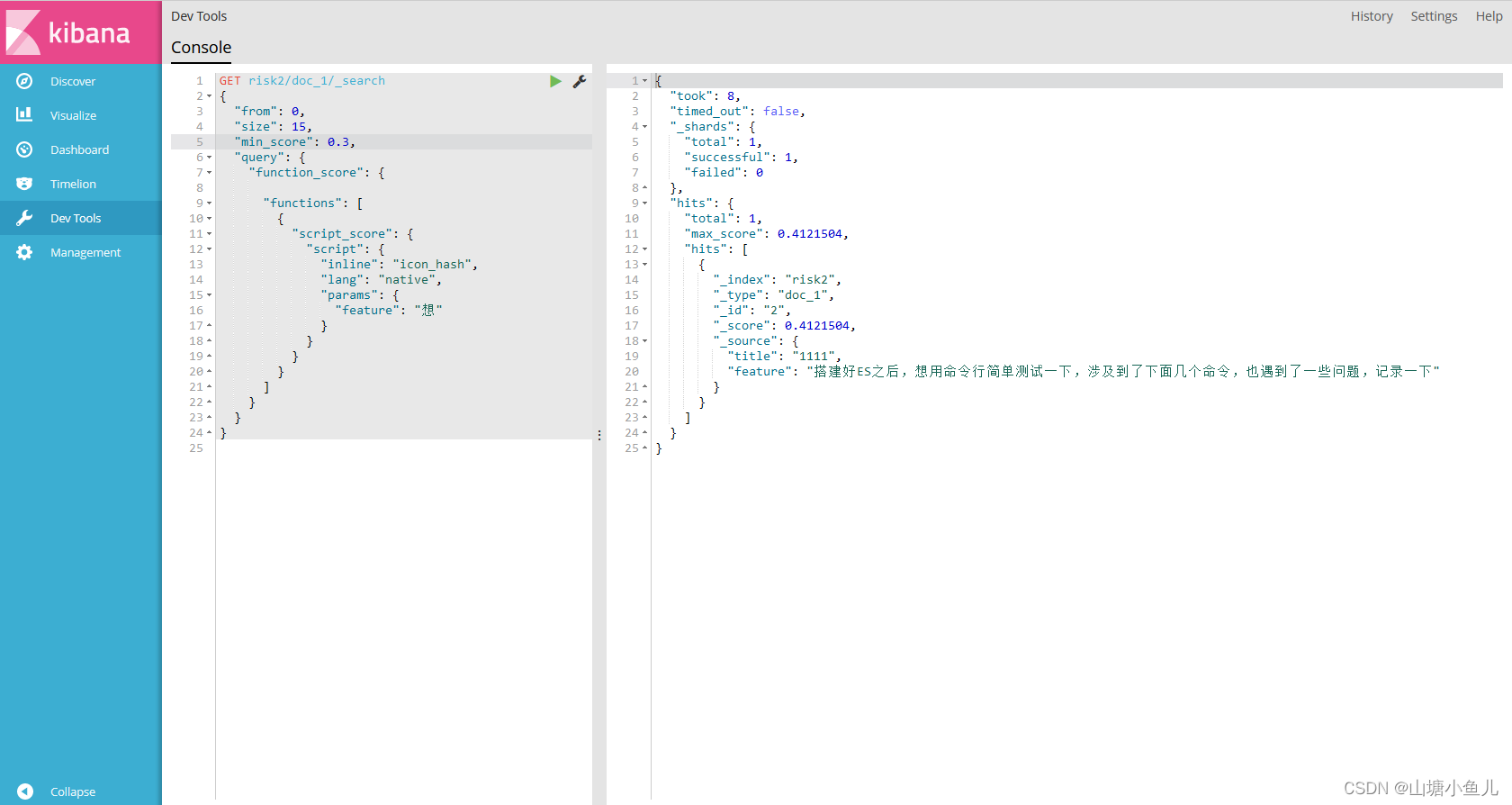
创建索引 PUT index
添加数据 GET index/doc_1,json
{
"title":"11111",
"feature":"搭建好ES之后,想用命令行简单测试一下,涉及到了下面几个命令,也遇到了一些问题,记录一下"
}
查询语句 GET index/doc_1/_search 必须有_search,不然就变插入或更新了
{
"from": 0,
"size": 15,
"min_score": 0.3,
"query": {
"function_score": {
"functions": [
{
"script_score": {
"script": {
"inline": "icon_hash",
"lang": "native",
"params": {
"feature": "想"
}
}
}
}
]
}
}
}记录一下插件的写法:
1.相似度比较算法,pom
<dependency>
<groupId>com.janeluo</groupId>
<artifactId>ikanalyzer</artifactId>
<version>2012_u6</version>
</dependency>算法代码:
import org.wltea.analyzer.core.IKSegmenter;
import org.wltea.analyzer.core.Lexeme;
import java.io.IOException;
import java.io.StringReader;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Vector;
public class TextComparator {
public static double YUZHI = 0.1;
public TextComparator() {
}
public static double getSimilarity(Vector<String> T1, Vector<String> T2) throws Exception {
if (T1 != null &&T1.size() > 0 && T2 != null && T2.size() > 0) {
Map<String, double[]> T = new HashMap();
String index = null;
int i;
double[] c;
for(i = 0; i < T1.size(); ++i) {
index = (String)T1.get(i);
if (index != null) {
c = (double[])T.get(index);
c = new double[]{1.0, YUZHI};
T.put(index, c);
}
}
for(i = 0; i < T2.size(); ++i) {
index = (String)T2.get(i);
if (index != null) {
c = (double[])T.get(index);
if (c != null && c.length == 2) {
c[1] = 1.0;
} else {
c = new double[]{YUZHI, 1.0};
T.put(index, c);
}
}
}
Iterator<String> it = T.keySet().iterator();
double s1 = 0.0;
double s2 = 0.0;
double Ssum;
for(Ssum = 0.0; it.hasNext(); s2 += c[1] * c[1]) {
c = (double[])T.get(it.next());
Ssum += c[0] * c[1];
s1 += c[0] * c[0];
}
return Ssum / Math.sqrt(s1 * s2);
} else {
throw new Exception("传入参数有问题!");
}
}
public static Vector<String> participle(String str) {
Vector<String> str1 = new Vector();
try {
StringReader reader = new StringReader(str);
IKSegmenter ik = new IKSegmenter(reader, true);
Lexeme lexeme = null;
while((lexeme = ik.next()) != null) {
str1.add(lexeme.getLexemeText());
}
if (str1.size() == 0) {
return null;
}
System.out.println("str分词后:" + str1);
} catch (IOException var5) {
System.out.println();
}
return str1;
}
public static void main(String[] args) {
String s1 = "想";
String s2 = "搭建好ES之后,想用命令行简单测试一下,涉及到了下面几个命令,也遇到了一些问题,记录一下";
Double score;
try {
score = getSimilarity(participle(s1), participle(s2));
} catch (Exception var5) {
throw new RuntimeException(var5);
}
System.out.println(score);
}
public static Double getScore(String s1, String s2) {
try {
return getSimilarity(participle(s1), participle(s2));
} catch (Exception var3) {
throw new RuntimeException(var3);
}
}
}Elasticsearch插件代码
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.elasticsearch.common.Nullable;
import org.elasticsearch.common.xcontent.support.XContentMapValues;
import org.elasticsearch.plugins.ActionPlugin;
import org.elasticsearch.plugins.Plugin;
import org.elasticsearch.plugins.ScriptPlugin;
import org.elasticsearch.script.AbstractDoubleSearchScript;
import org.elasticsearch.script.ExecutableScript;
import org.elasticsearch.script.NativeScriptFactory;
import java.util.Collections;
import java.util.List;
import java.util.Map;
public class IconHashPlugin extends Plugin implements ActionPlugin, ScriptPlugin {
private final static Logger LOGGER = LogManager.getLogger(IconHashPlugin.class);
public IconHashPlugin() {
super();
LOGGER.warn("Create the Basic Plugin and installed it into elasticsearch");
}
@Override
public List<NativeScriptFactory> getNativeScripts() {
return Collections.singletonList(new MyNativeScriptFactory());
}
public static class MyNativeScriptFactory implements NativeScriptFactory {
private final static Logger LOGGER = LogManager.getLogger(MyNativeScriptFactory.class);
@Override
public ExecutableScript newScript(@Nullable Map<String, Object> params) {
LOGGER.info("MyNativeScriptFactory run new Script ");
String featureStr = params == null ? null : XContentMapValues.nodeStringValue(params.get("feature"), null);
if (featureStr == null) {
LOGGER.error("Missing the field parameter ");
}
return new MyScript(featureStr);
}
@Override
public boolean needsScores() {
return false;
}
@Override
public String getName() {
return "icon_hash";
}
}
public static class MyScript extends AbstractDoubleSearchScript {
private final static Logger LOGGER = LogManager.getLogger(MyScript.class);
private final String featureStr;
public MyScript(String featureStr) {
this.featureStr = featureStr;
}
@Override
public double runAsDouble() {
LOGGER.info("my run As begining ");
String strSrcFeature = (String) source().get("feature");
String f1 = featureStr;
String f2 = strSrcFeature;
LOGGER.info("featureStr------> "+featureStr);
LOGGER.info("strSrcFeature------> "+strSrcFeature);
Double score = MyTextComparator.getScore(featureStr,strSrcFeature);
LOGGER.info("score------> "+score);
return score;
}
}
}
2.部署插件
打包啥的见我的另一个代码源码:
https://download.csdn.net/download/airyearth/87435594
本次主要就是替换了算法
3.部署插件,非常重要的一点就是把一些冲突的jar包删掉,copy进Elasticsearch的\elasticsearch-5.5.1\plugins后,手动删掉lucene所有的包,不然会和es冲突
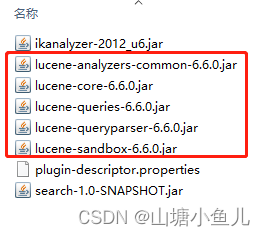
重启es就可以了