浅谈Hadoop工作原理
文章目录
- 浅谈Hadoop工作原理
- Hadoop核心组件
- HDFS读写原理
- HDFS读文件
- HDFS写文件
- MapReduce原理
- Map流程
- Reduce流程
- Shuffle机制(无序--->有序)
Hadoop核心组件
Hadoop HDFS(分布式存储系统):解决海量数据存储
Hadoop YARN(集群资源管理和任务调度框架):解决资源任务调度
Hadoop MapReduce(分布式计算):解决海量数据计算
HDFS读写原理
HDFS读文件
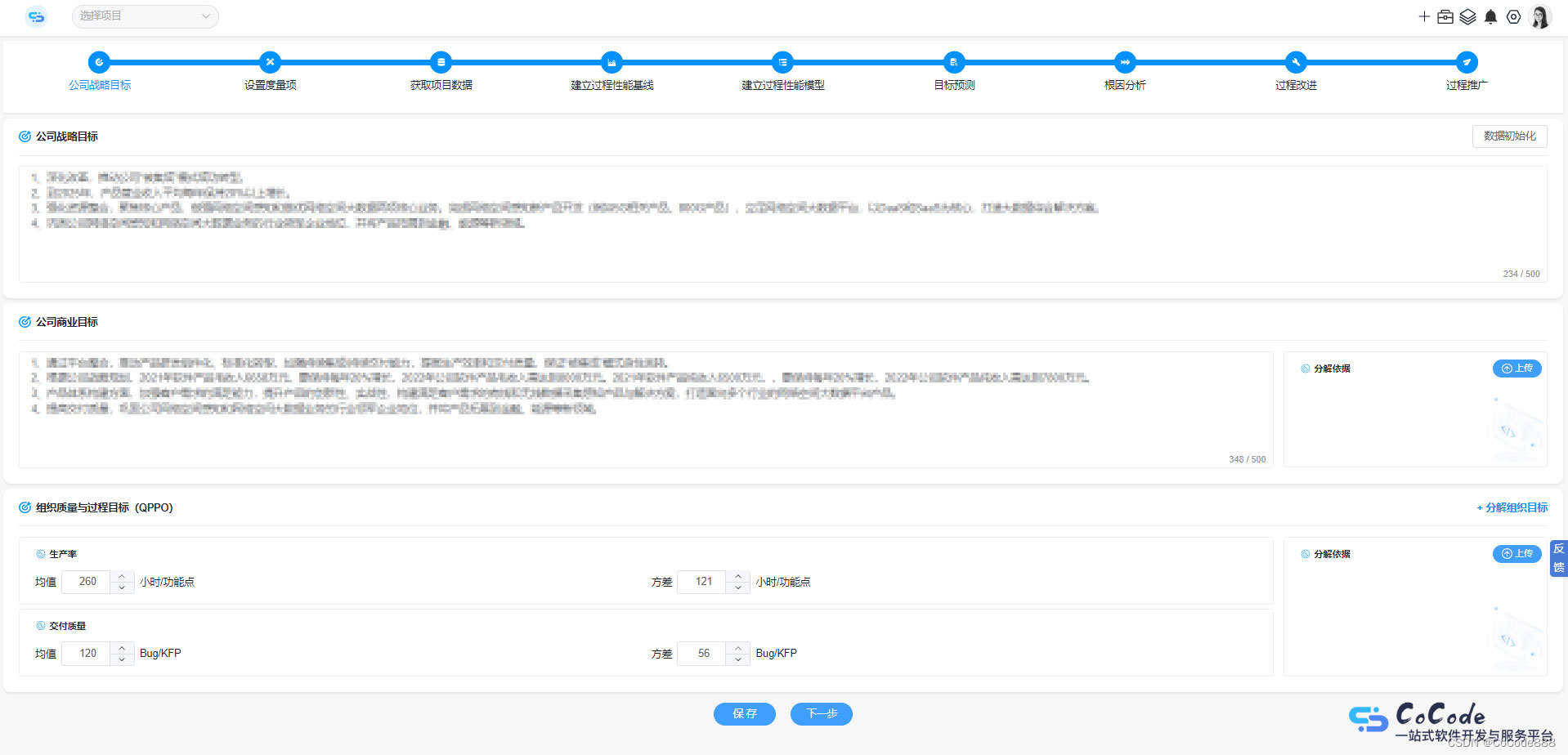
1.首先调用FileSystem.open()方法,获取到DistributedFileSystem实例
2.DistributedFileSystem向NameNode发起RPC(远程过程调用)请求获得文件的开始部分或全部block列表,对于每个返回的块,都包含块所在的DateNode地址,这些DataNode会按照Hadoop定义的集群拓扑结构得出客户端的距离,然后再进行排序。如果客户端本身就是一个DataNode,那么他将从本地读取文件
3.DistributedFileSystem会向客户端client返回一个支持文件定位的输入流对象FSDateInputStream,用于客户端读取数据。FSDateInputStream包含一个DFSInputStream对象,这个对象用来管理DataNode和NameNode之间的I/O
4.客户端调用read()方法,DFSInputStream就会找出离客户端最近的datanode并连接datanode
5.DFSInputStream对象中包含文件开始部分的数据块所在的DateNode地址,首先它会连接包含文件第一个块最近的DataNode。随后,在数据流中重复调用read()函数,直到这个块全部读完为止。如果第一个block块的数据读完,就会关闭指向第一个block块的datanode连接,接着读取下一个block块
6.如果第一批block都读完了,DFSInputStream就会去NameNode拿下一批blocks的location,然后继续读,如果所有的block块都读完,这时就会关闭所有流
HDFS写文件
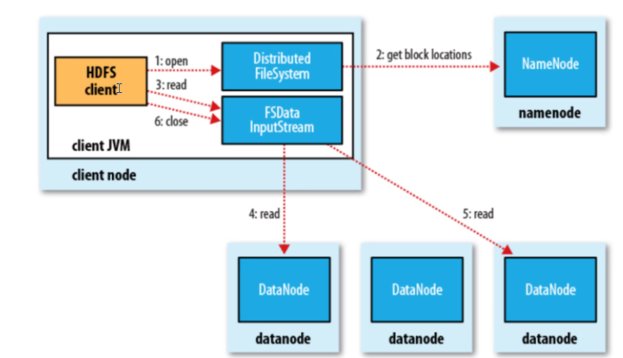
1 .客户端client 通过Distributed FileSystem向NameNode发起文件上传请求,NameNode检查目标文件是否已存在,父目录是否存在
2.NameNode校验完成后返回客户端首地址的位置
3.确定可以上传,客户端请求第一个block上传到哪几个datanode服务器上
4.NameNode返回3个datanode节点,假定分别为dn1,dn2,dn3
5.客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个管道pipeline建立完成
6.dn1,dn2,dn3逐级应答客户端
7.客户端开始往dn1都上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet(64KB)为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个parket会放入一个应答队列等待应答
8.当一个block传输完成之后,客户端再次请求NameNode上传第二个block的服务器。
MapReduce原理
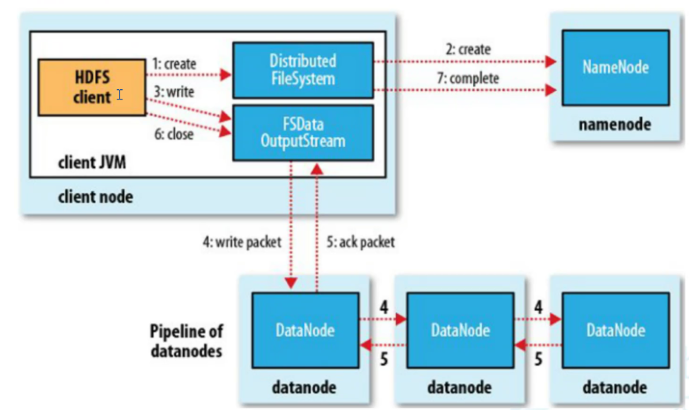
Map流程
第一阶段:把输入目录下文件按照一定的标准逐个进行辑切片形成切片规划。默认Splitsize=Blocksize(128M)每一个切片由一一个MapTask处理(getSpIits)
第二阶段:对切片中的数据按照一定的规则读取解析返回〈key,value>对。默认是按行读取数据。key是每一行的起始位置偏移量,value是本行的文本内容。(TextInputFormart)
第三阶段:调用Mapper类中的map方法处理数据。每读取解析出来的一个<key,value>,调用一次map方法。
第四阶段:按照一定的规则对Map输出的值对进行分区partition。默认不分区,因为只有一个reducetask。分区的数量就是reducetask运行的数量
第五阶段:Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出spill的时候根据key进行排序sort。默认根据key字典序排序。
第六阶段:对所有溢出文件进行最终的merge合并,成为一个文件。
Reduce流程
第一阶段:ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据。
第二阶段:把拉取来数据,全部进行合井merge,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段:是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法。最后把这些输出的键值对写入到HDFS文件中。
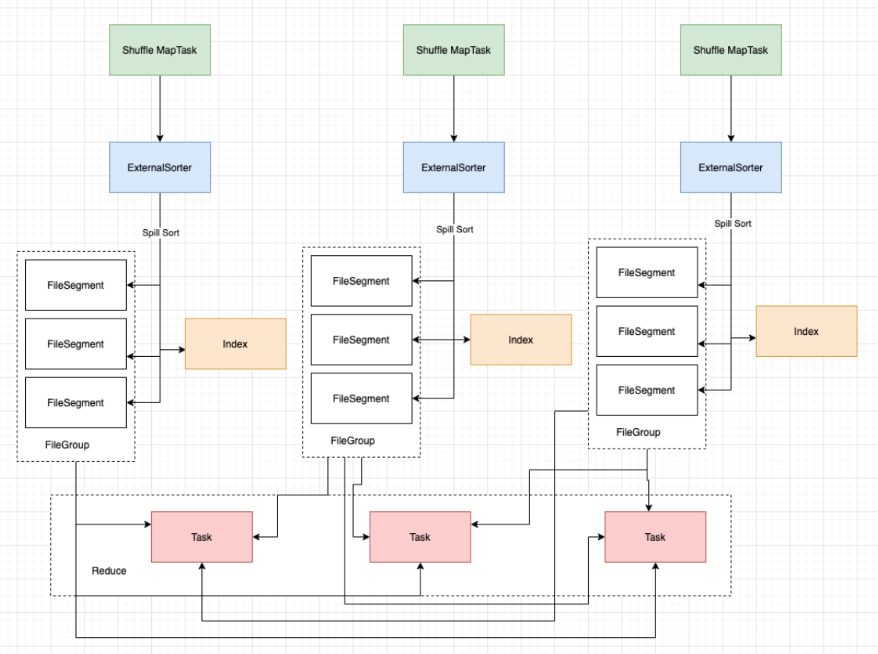
Shuffle机制(无序—>有序)
Shuffe的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据。而在MapReduce中,Shuffe更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱“成具有一定规则的数据,以便reduce端接收处理。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。