量子神经网络是基于量子力学原理的计算神经网络模型。1995年,Subhash Kak 和 Ron Chrisley 独立发表了关于量子神经计算的第一个想法,他们致力于量子思维理论,认为量子效应在认知功能中起作用。然而,量子神经网络的典型研究涉及将经典的人工神经网络模型(在机器学习中广泛用于模式识别的重要任务)与量子信息的优势相结合,以发展更高效的算法。这些研究的一个重要动机是经典神经网络难以训练,特别是在大数据应用中更是如此。希望可以利用量子计算的特性,如量子并行性或干涉和纠缠效应作为资源。
基于QuTrunk+AI框架构建量子神经网络的解决方案,与 Mindspore 及 paddle 结合实践已经发布过相关实战的文章。而 TensorFlow 作为一个非常流行和重要的 AI 深度学习框架,QuTrunk 也同样支持与之结合一起使用。本文主要介绍在亚马逊云科技实验环境中使用 QuTrunk 结合 TensorFlow 来完成量子神经网络构建的实验。实验之前,我们首先介绍下本示例中使用到的两个技术资源:Amazon DLAMI 和 TensorFlow。
1、Amazon DLAMI 及 TensorFlow 简介
1.1 Amazon DLAMI
亚马逊云科技提供的 Amazon Deep Learning AMI(缩写为 DLAMI)可以帮助用户快速的部署部署好深度学习实验环境和快速上手实验。它具有如下特点:
预装框架:DLAMI 目前主要有2个主要的规格:DL Base AMI 和 DLAMI with conda和。DL Base AMI 未安装框架,仅安装了 NVIDIA CUDA 和其他依赖项。DLAMI with conda 则全部都包含,不仅完全配备了 TensorFlow、PyTorch、Apache MXNet 机器学习框架,也预先配置了 NVIDIA CUDA 和 NVIDIA cuDNN。它使用 Conda 环境来隔离每个框架,用户可以在它们之间随意切换,而不用担心它们的依赖关系冲突;预装 GPU 软件:即使使用仅 CPU 的实例,DLAMI 也将具有 NVIDIA CUDA 和 NVIDIA cuDNN。无论实例类型如何,安装的软件都相同。
模型服务和可视化:使用 Conda 的深度学习 AMI 预装了两种模型服务器,一种用于 MXNet,另一种用于 TensorFlow,以及 TensorBoard,用于模型可视化。
1.2 TensorFlow2
TensorFlow 是一个用于机器学习和人工智能的免费开源软件库。它可以用于一系列任务,但特别关注深度神经网络的训练和推理。 TensorFlow 由谷歌大脑团队开发,用于谷歌内部研究和生产。初始版本于2015年根据 Apache License 2.0 发布。Google 于2019年9月发布了 TensorFlow 的更新版本,名为 TensorFlow 2.0。TensorFlow 可用于多种编程语言,包括 Python、JavaScript、C++ 和 Java。 这种灵活性适用于许多不同行业的一系列应用。
TensorFlow 2.0 引入了许多变化,最重要的是 TensorFlow eager,它将自动微分方案从静态计算图改变为最初由 Chainer 和后来的 PyTorch 流行的“按运行定义”方案。其他主要变化包括删除旧库、不同版本 TensorFlow 上的训练模型之间的交叉兼容性以及 GPU 性能的显著改进。
2、实验环境搭建
2.1 启动 Amazon Deep Learning EC2 实例
2.1.1、打开 EC2 Dashborad
登录亚马逊云科技的管理控制台,点击右上角 Region 下拉菜单切换到需要创建的资源的 Region,本示例使用亚太新加坡站点的资源。然后从 Services 选择 EC2,打开 EC2 Dashboard。

2.1.2、创建 EC2 访问密钥对
依次点击服务->计算->EC2 打开 EC2 的主页面。首先创建好秘钥对便于后面登录到 EC2,依次点击左侧导航栏的网络与安全->密钥对->创建密钥对。
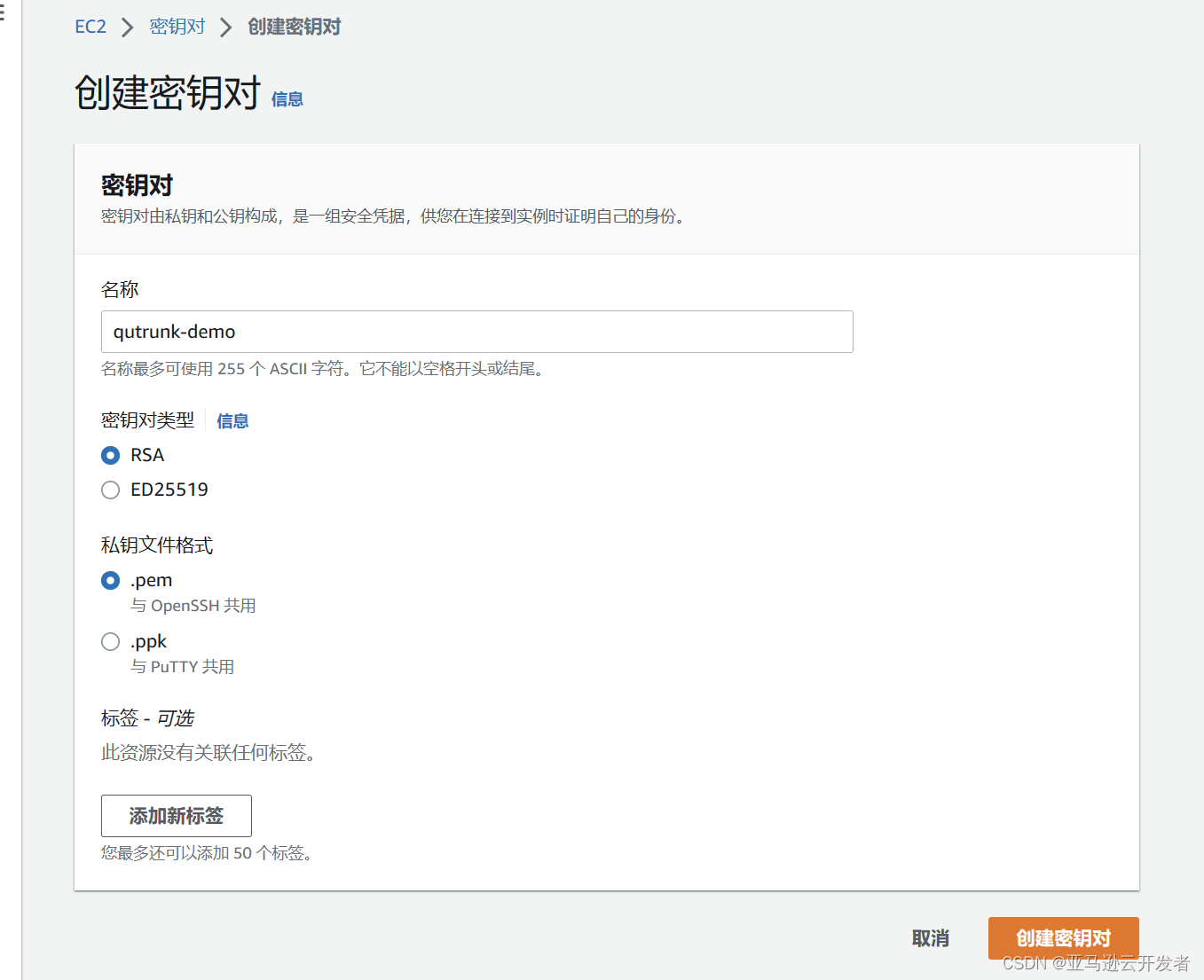
完成创建后自动下载秘钥,保存好秘钥文件备用。
2.1.3、AMI 选择
返回到 EC2 主页,选择启动实例,打开实例配置页面,先设置实例名称设置为 QNNDemo_Tensor,然后选择镜像版本,搜索框输入 Deep Learning 进行搜索,打开镜像搜索结果页面,显示如下:
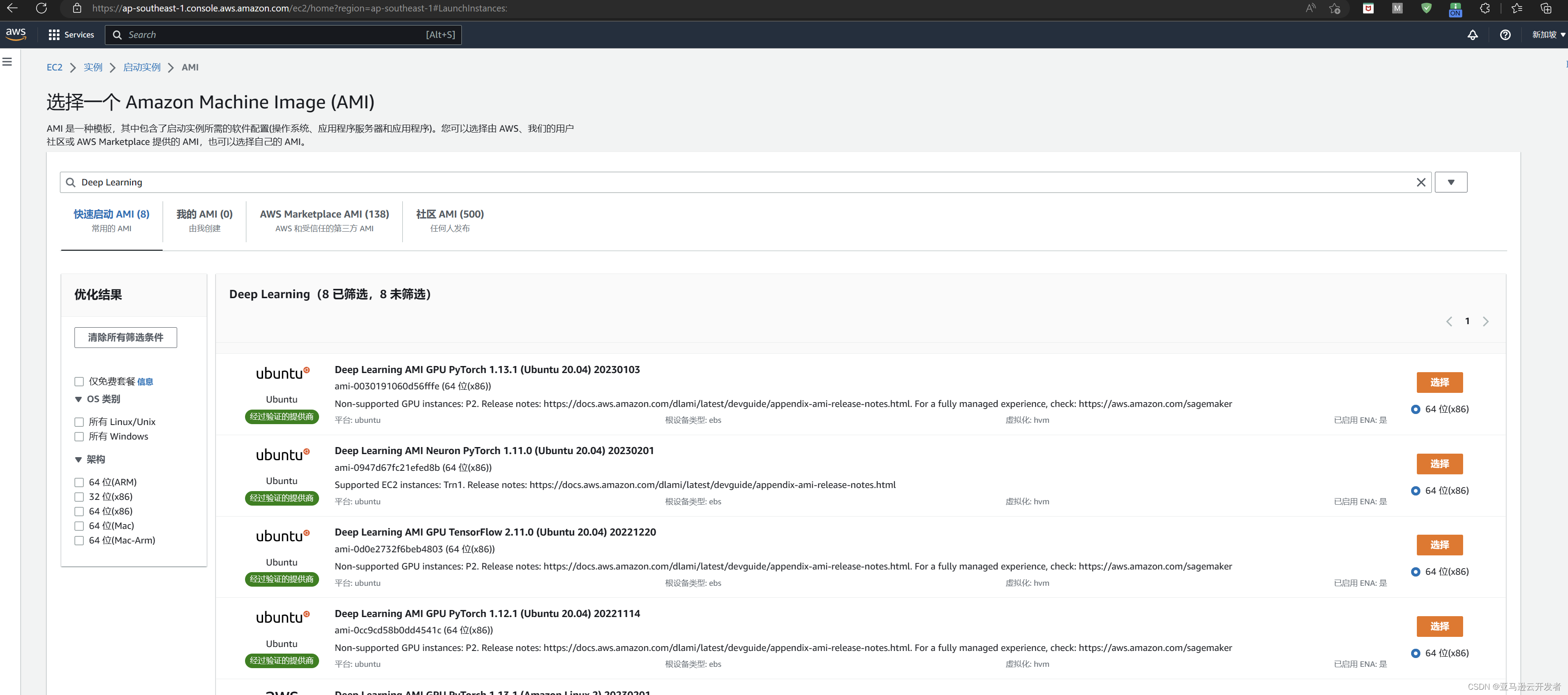
快速启动 AMI 中有8个搜索结果,本示例使用的是 TensorFlow2,选择搜索结果中:Deep Learning AMI GPU TensorFlow 2.11.0 (Ubuntu 20.04) 20221220 这个镜像。
2.1.4、实例类型确定
选定镜像后再确定需要创建的实例类型。镜像的实例类型可以在实例下面的实例类型中查询,例如查询 GPU 是实例类型,根据条件过滤,可以看到有如下 gpu 实例类型:
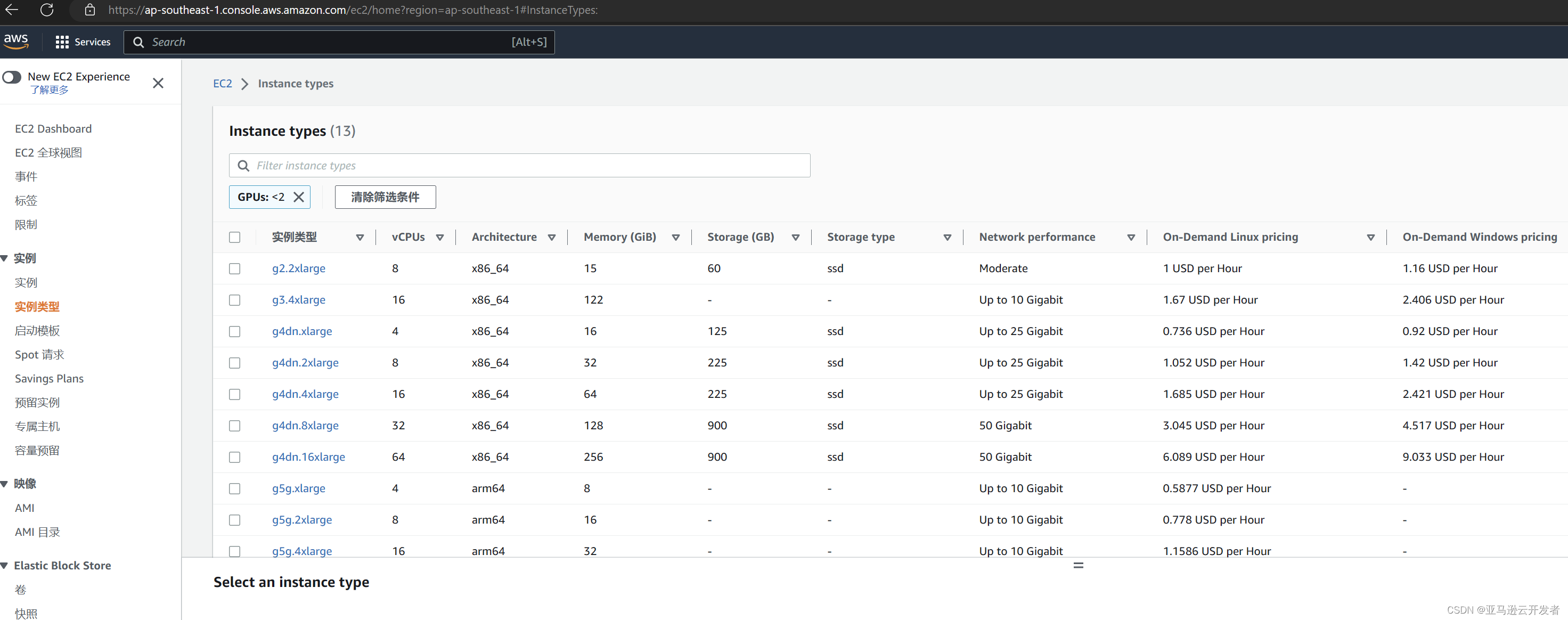
亚马逊云科技提供了大量的实例类型可供用户选择,用户可以从经济和需求角度出发,选择合适的镜像来创建实例。对于深度学习,亚马逊云科技推荐是使用 GPU 实例 P3,P4,G3,G4,G5和G5g。各 GPU 实例类型的配置如下:
P3具有 8 NVIDIA Tesla V100 GPUs
P4具有8 NVIDIA Tesla A100 GPUs
G3具有4 NVIDIA Tesla M60 GPUs
G4具有4 NVIDIA T4 GPUs
G5具有o 8 NVIDIA A10G GPU
G5g则有基于Arm的 Amazon Graviton2 processors。
如果经济上受限或者对于性能要求不是非常高,亚马逊云科技也提供了相对经济的深度学习 CPU 实例和推理实例。深度学习推荐的 CPU 实例有三种:C5(不是所以的region都提供)、C4、C3等实例类型。
C5 实例最多有72个 Intel vCPU。C5 实例擅长科学建模、批处理、分布式分析、高性能计算(HPC)以及机器和深度学习推理。
C4 实例最多有36个 Intel vCPU。
亚马逊云科技推理实例旨在为深度学习模型推理工作负载提供高性能和高成本效率。具体来说,Inf1实例类型使用 Amazon Infentia 芯片和 Amazon Neuron SDK,后者与 TensorFlow、PyTorch 和 MXNet 等流行的机器学习框架集成。客户可以使用 Inf1 实例以最低的云成本运行大规模机器学习推理应用程序,如搜索、推荐引擎、计算机视觉、语音识别、自然语言处理、个性化和欺诈检测。Amazon EC2 Inf1 实例具有多达16个 Amazon Infentia 芯片和 100 Gbps 的网络吞吐量。
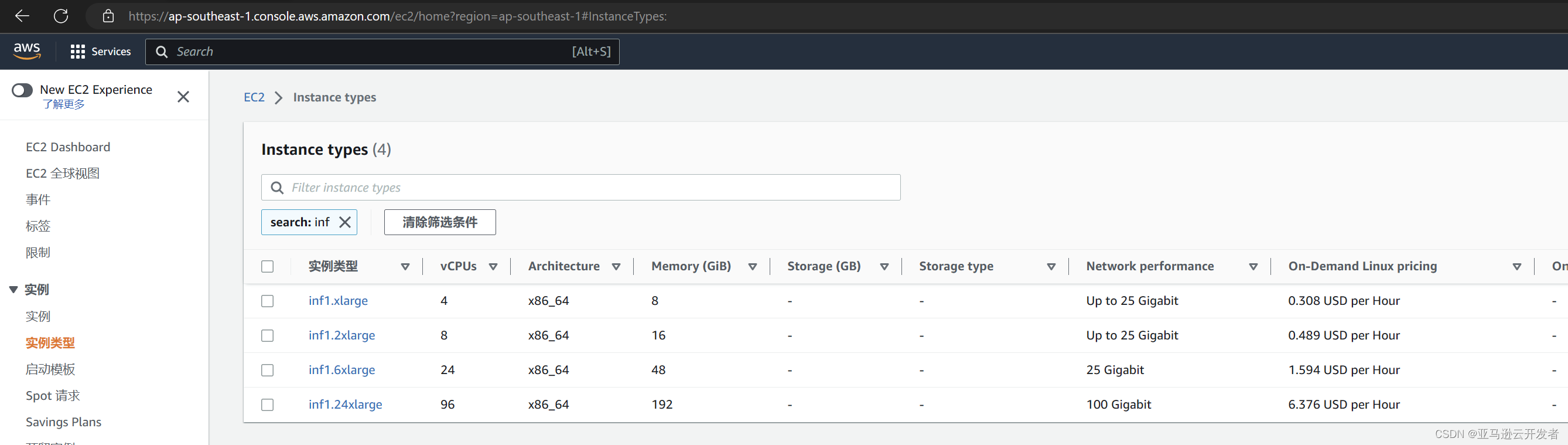
本示例只是用于简单深度学习实验,从节省成本考虑,选用的实例类型是 CPU 类型,选择的是普通是 t2.medium。用户也可以根据需要选择其他带 GPU 的实例。
2.1.5、创建和启动实例
实例类型确定后然后选择密钥对、网络设置及存储。最后点击启动示例提交创建。其他配置如下:
提交后示例创建中,待状态转变为正在运行即可开始使用。

3、量子神经网络构建
使用量子+深度学习构建量子神经网络基本流程差不多一一致,主要流程如下:

为了便于学习和理解,我们本示例程序同样采用单量子比特来构建一个简单的神经网络,构建的神经模型架构如下:
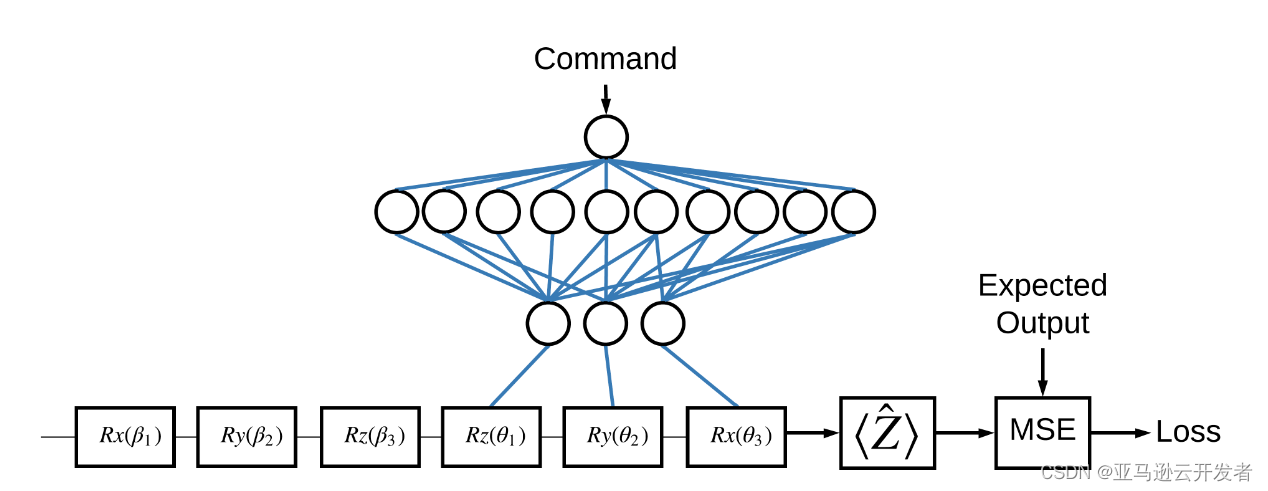
本示例模型主要由3个部分组成:
输入电路/数据点电路:前面3个门,分别为:
模型电路:后面3个门,对应分别为:
期望值电路:对线路执行 PauliZ 算符
3.1、环境准备
3.1.1、登录 EC2 实例
EC2 页面选中刚才创建的这个示例,点击右键选择连接,选择 ssh 客户端,显示如下:
根据秘钥文件保存的目录,使用如下命令即可访问
ssh -i "qutrunk-asia.pem" ubuntu@18.141.145.323.1.2、QuTrunk 安装
执行如下命令安装 QuTrunk 最新版本到 EC2 环境上:
ubuntu@ip-192-168-150-172:~$ pip3 install --upgrade pip -i https://pypi.tuna.tsinghua.edu.cn/simple
ubuntu@ip-192-168-150-172:~$ pip3 install qutrunk -i https://pypi.tuna.tsinghua.edu.cn/simpleQuTrunk 安装完成后,在 python3 命令行交互模式下,测试是否安装成功:
ubuntu@ip-192-168-150-172:~$ python3
Python 3.10.7 (main, Dec 20 2022, 07:32:05) [GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import qutrunk
>>> qutrunk.run_check()
============QuSL instruction:===========
qreg q[2]
creg c[2]
H * q[0]
MCX(1) * (q[0], q[1])
Measure * q[0]
Measure * q[1]
===============Draw circuit=============
┌───┐ ┌─┐
q[0]: ┤ H ├──■───┤M├───
└───┘┌─┴──┐└╥┘┌─┐
q[1]: ─────┤ CX ├─╫─┤M├
└────┘ ║ └╥┘
c: 2/════════════╩══╩═
0 1
==========circuit running result=========
[{"0b00": 57}, {"0b11": 43}]
===========circuit running info==========
{"backend": "BackendLocal", "task_id": "7478c36b8ec941dbaed9b14f64a854a3", "status": "success", "arguments": {"shots": 100}}
qutrunk v0.2.0 is installed successfully! You can use QuTrunk now.3.1.3、Jupyter Notebook Server 设置
为方便测试,本实验在 JupyterNotebook 环境下进行验证,DLAMI 环境上已经安装 Jupyter Notebook,只需进行简单的配置和启动即可。
1、设置 Jupyter server
首先设置首选密码:
ubuntu@ip-192-168-150-172:~$ jupyter notebook password
Enter password:
Verify password:
[NotebookPasswordApp] Wrote hashed password to /home/ubuntu/.jupyter/jupyter_notebook_config.json2、启动 upyter notebook server
我们可以通过如下命令开启一个支持远程访问的 jupyter notebook:
$ jupyter notebook --ip=0.0.0.0
然后我们就可以在本地 PC 上访问了,打开浏览器,输入 EC2 的公网 IP:8888 即可访问,打开登录界面:
输入刚设置的密码登录到环境,点击新建按钮,然后选择 Python3
打开实验页面就可以开始基于 QuTrunk 的量子计算与深度学习框架结合的程序的开发了

3.2、程序实现
3.2.1 环境设置
安装完成后,设置程序使用的环境:
import random
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt
from qutrunk.circuit import QCircuit
from qutrunk.circuit.gates import Rx, Ry, Rz, PauliZ3.2.2、定义量子线路相关函数
根据前面模型设计,主要包含3个神经网络组成部分的量子线路函数,还有一个量子线路合并函数
数据点电路函数如下:
def datapoint_circuit(rotations):
beta0, beta1, beta2 = [float(f) for f in rotations]
circuit = QCircuit()
qreg = circuit.allocate(1)
Rx(beta0) * qreg[0]
Ry(beta1) * qreg[0]
Rz(beta2) * qreg[0]
return circuit模型电路函数定义:
def model_circuit():
circuit = QCircuit()
q = circuit.allocate(1)
angles = ["theta-1", "theta-2", "theta-3"]
params = circuit.create_parameters(angles)
Rz(params[0]) * q[0]
Ry(params[1]) * q[0]
Rx(params[2]) * q[0]
return circuit期望值函数定义:
def expectation():
circuit = QCircuit()
qreg = circuit.allocate(1)
return PauliZ(qreg[0])最后是电路组合函数定义:
def join_circuit(datapoint_cir, model_cir, inputs):
params = {"theta-" + str(i): inputs[i] for i in range(len(inputs))}
model_cir = model_cir.bind_parameters(params)
datapoint_cir.append_circuit(model_cir)
return datapoint_cir3.2.3、定义梯度计算类
采用梯度下降的算法训练量子神经网络,为了方便调用,本示例将梯度计算定义为一个类
class CustomGradientTape:
def __init__(self, inputs, exp_op, shift=np.pi / 2):
self.inputs = inputs
self.exp_op = exp_op
self.shift = shift
def gradient(self, loss, var_list):
params = [var.numpy() for var in var_list]
gradients = []
for i in range(len(params)):
shift_right = np.copy(params)
shift_right[i] += self.shift
shift_left = np.copy(params)
shift_left[i] -= self.shift
circuit = join_circuit(datapoint_circuit(self.inputs), model_circuit(), shift_right)
expectation_right = -1 * circuit.expval_pauli(self.exp_op)
circuit = join_circuit(datapoint_circuit(self.inputs), model_circuit(), shift_left)
expectation_left = -1 * circuit.expval_pauli(self.exp_op)
gradient = expectation_right - expectation_left
gradients.append(tf.convert_to_tensor(gradient, dtype=tf.float32))
return gradients3.2.4、自定义层类
自定义层类包含了损失函数的定义,返回为迭代训练后的损失值
class ControlledPQC(tf.keras.layers.Layer):
def __init__(self, optimizer, exp_op, var_list, grad):
super(ControlledPQC, self).__init__()
self.optimizer = optimizer
self.exp_op = exp_op
self.var_list = var_list
self.grad = grad
def call(self, inputs):
params_list = [var.numpy() for var in self.var_list]
circuit = join_circuit(datapoint_circuit(inputs), model_circuit(), params_list)
loss = -1 * circuit.expval_pauli(self.exp_op)
self.optimizer.minimize(loss, self.var_list, self.grad)
return loss3.2.5、模型设置及训练
首先根设置预先定义的参数,然后通过 TensorFlow 的 Adam 优化器优化上面的量子神经网络,,通过调整迭代次数 ITR 和学习率 LR 重新计算以使得这两个值达到非常接近。初始化设置如下:
ITR = 200
LR = 0.02
rand = random.Random()
random_rotations = tf.convert_to_tensor(np.random.uniform(0, 2 * np.pi, 3))
op = expectation()
opt = tf.keras.optimizers.Adam(learning_rate=LR)迭代循环计算和打印损失值。
control_params = [tf.Variable(rand.uniform(0, 2 * np.pi)) for _ in range(3)]
model = ControlledPQC(opt, op, control_params, CustomGradientTape(random_rotations, op))
loss_list = []
for it in range(ITR):
ls = model(random_rotations)
loss_list.append(ls)
if it % 10 == 0:
print(f"{it}: {ls:.4f}")运行后输出的结果如下:
0: -0.2399
10: -0.6203
20: -0.8689
30: -0.9746
40: -0.9969
50: -0.9967
60: -0.9973
70: -0.9991
80: -0.9999
90: -1.0000
100: -1.0000
110: -1.0000
120: -1.0000
130: -1.0000
140: -1.0000
150: -1.0000
160: -1.0000
170: -1.0000
180: -1.0000
190: -1.0000从结果可以看到经过130次迭代之后损失值逐渐收敛到-1。
3.2.6、结果展示
为了更形象的展示训练结果,我们使用 plot 打印其曲线,实现方式如下:
plt.plot(loss_list)
plt.title("Learning to Control a Qubit")
plt.xlabel("Iterations")
plt.ylabel("loss")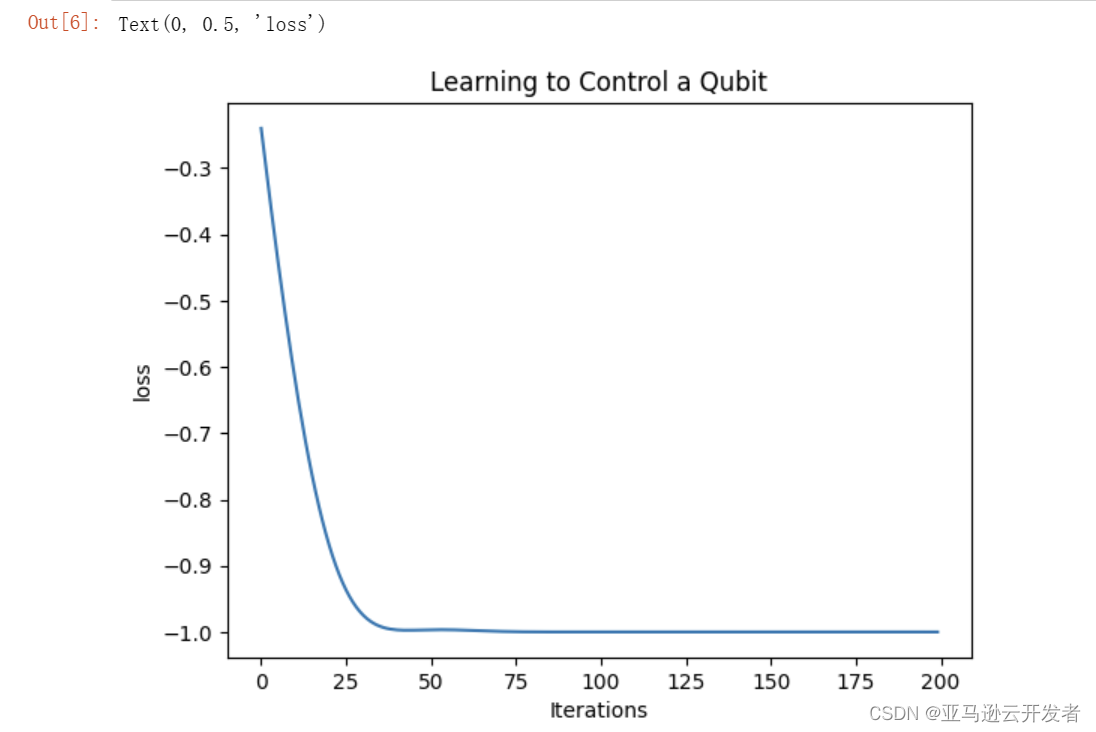
4、总结
本文章详细展示了使用亚马逊云科技的 DLAMI 快速部署出深度学习的实验环境,并使用 QuTrunk 与 AI 框架 TensorFlow 结合完成构建量子神经网络的实验和输出测试结果,为量子计算+深度学习的开发者用户提供了一个简单的入门学习示例。
QuTrunk 是启科量子发布的一个开源的、灵活方便使用的、可以与各种考虑开源AI框架结合使用的量子编程框架。通过本文的展示,读者对量子编程 +AI 框架结合使用的方法有了基本了解,读者也可以访问启科开发者社区,深入了解 QuTrunk 的特性以便使用QuTrunk+AI的解决方案解决实际应用的中问题。更多的信息请点击 QuSaaS:启科开发者平台
作者:

Keith Yan(丘秉宜)中国首位亚马逊云科技 Community Hero。

黄文,启科量子DEVOPS工程师

Marz Kuo(郭梦杰),启科量子资深研发工程师,量子计算开源框架维护人
阅读原文:https://dev.amazoncloud.cn/column/article/63e48790e5e05b6ff897ca1b?sc_channel=CSDN