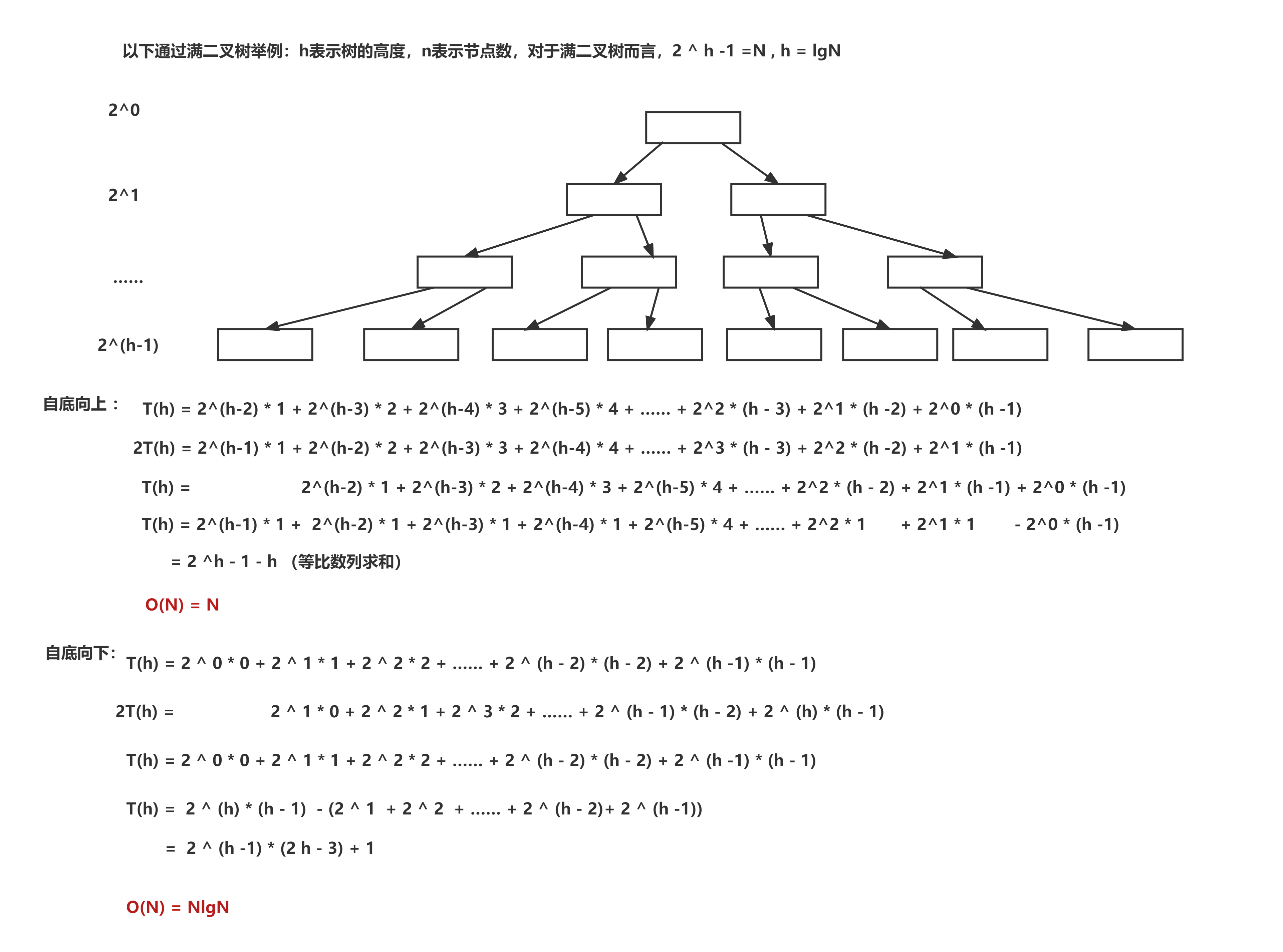
大家好,我们今天说一说正则表达式,在之前我们也介绍了关于正则表达式,今天,我们来深入的了解一下。我们知道正则表达式是处理字符串的强大工具,它有自己的语法结构,什么匹配啊,都不算什么。
正则表达式是什么?
正则表达式,又称规则表达式,(英语:Regular Expression,在代码中常简写为 regex、regexp 或 RE),它是计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式的文本。 许多程序设计语言都支持利用正则表达式进行字符串操作。例如在 Perl 中内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由 Unix 中的工具软件普及开的。正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为"元字符"))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,模式描述在搜索文本时要匹配的一个或多个字符串。
1.实例引入
说了一大堆废话,大家可能还是云里雾里的,我们通过实例来说明一下,我们可以用正则表达式测试工具,或者python都可以,首先,我们输入一段文本。
hello,my name is Tina,my phone number is 123456 and my web is http://tina.com.
我们接下来尝试用正则表达式提取出来;
[a-zA-z]+://[^\s]*我们就可以获取网页链接,也就是文本中的url,是不是很神奇?
这是因为它有自己的匹配规则,部分如下。
| 模式 | 描述 |
| . | 任意字符 |
| * | 0个或者多个表达式 |
| + | 一个或者多个表达式 |
关于更多的匹配规则可自行查阅。
?,*,+,\d,\w 都是等价字符
?等价于匹配长度{0,1}
*等价于匹配长度{0,}
+等价于匹配长度{1,}
\d 等价于[0-9]
\D 等价于[^0-9]
\w 等价于[A-Za-z_0-9]
\W 等价于[^A-Za-z_0-9]
2.match()
这里介绍一个常用的匹配方法——match(),向他传入要匹配的字符串以及正则表达式,就可以检测这个正则表达式是否匹配字符串。
匹配目标
res = re.match('hello\s(\d+)sword')贪婪匹配
res = re.match('hello.*(\d+)sword')3.findall()
我们最常用的就是这个,我们看看这个是如何使用的。
import re
useData = str(input('请输入字符串数据:'))
'''
匹配字符串中的数字,+是匹配前面的子表达式一次或多次
'''
digital = re.findall('\d+',useData)
print(digital)我们看看运行结果

findall()函数是返回所有匹配到的字符串,返回值的数据类型为列表。
我们今天就介绍到这里。