文章目录
- 前言
- 一、熵是什么?
- 1.信息量如何计算?
- 2.熵如何计算?
- 二、最大熵方法
- 1.设计思想
- 2.算法步骤
- 3.C++代码
- 4.实验结果
- 参考资料
前言
在图像分析中,通常需要将所关心的目标从图像中提取出来,这种从图像中某个特定区域与其他部分进行分离并提取出来的处理,就是图像分割。所以图像分割处理实际上就是区分图像中的“前景目标”和“背景”,所以通常又称之为图像的二值处理。之前我们已经介绍过基于图像灰度分布的阈值方法和大津二值化算法。今天我们再介绍一种二值化算法:最大熵方法。
一、熵是什么?
熵是信息论中对不确定性的度量,是对数据中所包含信息量大小的度量。熵取最大值时,就表明获得的信息量最大。
信息量:信息量有大有小。比如太阳从东边升起,这是一个确定的事件,没有一点信息量;比如说某人买了一张彩票,有99%的概率会中奖,那这个事情信息量就很大,因为本来概率很小很小的事情变得很确定了。
1.信息量如何计算?
一个事件的信息量就是这个事件发生的概率的负对数。
例如,符号
x
x
x出现的概率为
p
(
x
)
p(x)
p(x),则符号
x
x
x的自信息量
I
I
I为
I
=
−
l
o
g
p
(
x
)
I=-logp(x)
I=−logp(x)
2.熵如何计算?
假设符号集有
n
n
n个符号,每个符号出现的概率为
p
(
x
i
)
p(x_i)
p(xi),则符号集的信息熵为
H
=
−
∑
i
=
1
n
p
(
x
i
)
l
o
g
p
(
x
i
)
H=-\sum_{i=1}^np(x_i)logp(x_i)
H=−i=1∑np(xi)logp(xi)
可以得到一个结论:当
p
(
x
1
)
=
p
(
x
2
)
=
⋯
=
p
(
x
n
)
p(x_1)=p(x_2)=\cdots=p(x_n)
p(x1)=p(x2)=⋯=p(xn)时熵取最大值。
二、最大熵方法
1.设计思想
最大熵方法的设计思想是:选择适当的阈值将图像分为两类,两类的平均熵之和最大时,可以从图像中获得最大信息量,以此来确定最佳阈值。
2.算法步骤
- 求出图像中的所有像素的分布概率 p 0 , p 1 , ⋯ , p 255 p_0,p_1,\cdots,p_{255} p0,p1,⋯,p255(图像的灰度分布范围为[0,255]) p i = N i N i m a g e p_i=\frac{N_i}{N_{image}} pi=NimageNi其中, N i N_i Ni为灰度值为 i i i的像素个数; N i m a g e N_{image} Nimage为图像的总像素数;
- 给定一个初始阈值 T h = T h 0 Th=Th_0 Th=Th0, T h ∈ [ 0 , 255 ] Th\in[0,255] Th∈[0,255];将图像分为 C 1 C_1 C1和 C 2 C_2 C2两类;
- 分别计算两个类的平均相对熵 E 1 = − ∑ i = 0 T h ( p i / p T h ) ⋅ l n ( p i / p T h ) E_1=-\sum_{i=0}^{Th}(p_i/p_{Th})\cdot ln(p_i/p_{Th}) E1=−i=0∑Th(pi/pTh)⋅ln(pi/pTh) E 2 = − ∑ i = T h + 1 255 ( p i / ( 1 − p T h ) ) ⋅ l n ( p i / ( 1 − p T h ) ) E_2=-\sum_{i=Th+1}^{255}(pi/(1-p_{Th}))\cdot ln(p_i/(1-p_{Th})) E2=−i=Th+1∑255(pi/(1−pTh))⋅ln(pi/(1−pTh))其中 p T h = ∑ i = 0 T h p i p_{Th}=\sum_{i=0}^{Th}p_i pTh=∑i=0Thpi;
- 当 E 1 + E 2 E_1+E_2 E1+E2之和为最大值时,此时的 T h Th Th为最佳阈值 T h ∗ Th^* Th∗,此时满足图像中的信息量最大。
3.C++代码
/* 最大熵算法 */
int main()
{
cv::Mat image = cv::imread("Lena.bmp");
cv::Mat gray_image = cv::Mat::zeros(image.size(), CV_8UC1);
cv::cvtColor(image, gray_image, cv::COLOR_BGR2GRAY);
int height = gray_image.rows;
int width = gray_image.cols;
// 计算像素分布概率
float p[256] = { 0 };
for (int row = 0; row < height; row++)
{
for (int col = 0; col < width; col++)
{
p[gray_image.at<uchar>(row, col)] = p[gray_image.at<uchar>(row, col)] + 1;
}
}
for (int i = 0; i < 256; i++)
{
p[i] = p[i] / (height*width);
}
//保存E_1+E_2
float E[256] = { 0.0 };
//遍历所有的像素值
int index = 0; //最大值的索引
for (int th = 0; th < 256; th++)
{
// 计算p_Th
float p_Th = 0.0;
for (int i = 0; i < th+1; i++)
{
p_Th += p[i];
}
// 计算E_1
float E_1 = 0.0, E_2 = 0.0;
for (int i = 0; i < th + 1; i++)
{
if (fabs(p_Th) < 1e-6)
{
E_1 = 0;
}
else
{
E_1 += -(p[i] / p_Th) * log(p[i] / p_Th + 1e-6);
}
}
for (int j = th + 1; j < 256; j++)
{
if (fabs(1 - p_Th) < 1e-6)
{
E_2 = 0;
}
else
{
E_2 += -(p[j] / (1 - p_Th))*log(p[j] / (1 - p_Th)+1e-6);
}
}
if ((E_1 + E_2) > E[index])
{
index = th;
}
E[th] = E_1+E_2;
}
// 进行二值化
cv::Mat output_image = cv::Mat::zeros(height, width, CV_8UC1);
for (int row = 0; row < height; row++)
{
for (int col = 0; col < width; col++)
{
if (gray_image.at<uchar>(row, col) > index)
{
output_image.at<uchar>(row, col) = 255;
}
else
{
output_image.at<uchar>(row, col) = 0;
}
}
}
cv::imshow("input-image", gray_image);
cv::imshow("output-image", output_image);
cv::waitKey(0);
return 0;
}
关于代码的几点说明:
- 因为除数可能是0,所以要对p_Th进行为0判断。可以参考C++ float、double判断是否等于0,1-p_Th同理。
- 因为log()函数括号内可能取到0,从而出现负无穷的情况,所以加上一个很小的整数1e-6,避免出现负无穷的情况。
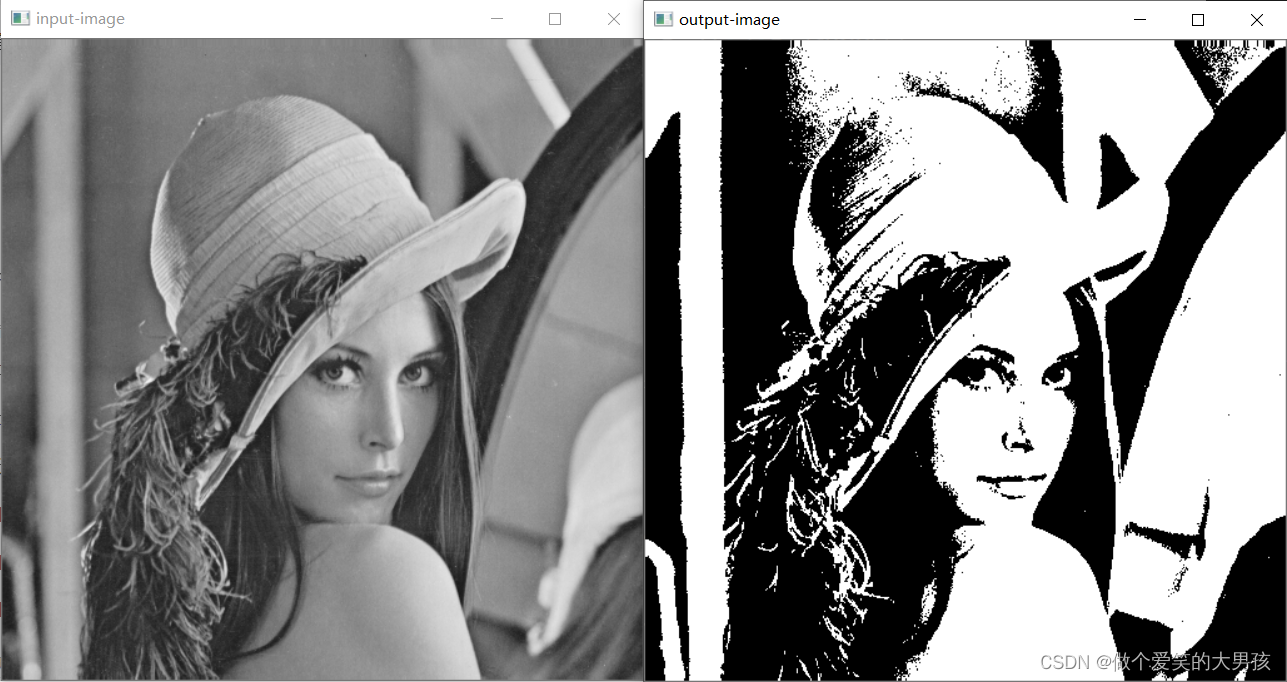
4.实验结果
参考资料
1.数字图像处理基础.朱虹.