设计问题也是一种很重要的考察类型,特征是整体难度不大,但是要求结构合理、复用性好、考虑周全,代码规范等等。有些面试官不喜欢烧脑的动态规划等问题,就喜欢设计题,笔者曾经在面试微博和猿辅导都遇到过类似的问题。这些题目中最重要的是LRU设计,我们前面应重点讲解。LeetCode里还有大量的设计类型的问题,这些题目整体来说难度都不大,但是要完整写完要花费很多篇幅,感兴趣的同学可以看这里力扣 加强练习。本文我们盘点几道典型的设计问题。
1 设计推特
LeetCode355.设计一个简化版的推特(Twitter),可以让用户实现发送推文,关注/取消关注其他用户,能够看见关注人(包括自己)的最近 10 条推文。
实现 Twitter 类:
Twitter() 初始化简易版推特对象 void postTweet(int userId, int tweetId) 根据给定的 tweetId 和 userId 创建一条新推文。每次调用此函数都会使用一个不同的 tweetId 。 List<Integer> getNewsFeed(int userId) 检索当前用户新闻推送中最近 10 条推文的 ID 。新闻推送中的每一项都必须是由用户关注的人或者是用户自己发布的推文。推文必须 按照时间顺序由最近到最远排序 。 void follow(int followerId, int followeeId) ID 为 followerId 的用户开始关注 ID 为 followeeId 的用户。 void unfollow(int followerId, int followeeId) ID 为 followerId 的用户不再关注 ID 为 followeeId 的用户。
这种题目是很多面试官特别喜欢出的问题,因此务必认真分析,代码尽量写得规范一些。本题的一种方式是采用哈希表+链表的方式来实现。
根据题意我们知道,对于每个推特用户,我们需要存储他关注的用户 Id,以及自己发的推文 Id 的集合,为了使每个操作的复杂度尽可能的低,我们需要根据操作来决定存储这些信息的数据结构。注意,由于题目中没有说明用户的 Id 是否连续,所以我们需要用一个以用户 Id 为索引的哈希表来存储用户的信息。
对于操作 3 和操作 4,我们只需要用一个哈希表存储,即可实现插入和删除的时间复杂度都为 O(1)O(1)。
对于操作 1 和操作 2,由于操作 2 要知道此用户关注的人和用户自己发出的最近十条推文,因此我们可以考虑对每个用户用链表存储发送的推文。每次创建推文的时候我们在链表头插入,这样能保证链表里存储的推文的时间是从最近到最久的。那么对于操作 2,问题其实就等价于有若干个有序的链表,我们需要找到它们合起来最近的十条推文。由于链表里存储的数据都是有序的,所以我们将这些链表进行线性归并即可得到最近的十条推文。这个操作与 23. 合并K个排序链表 基本等同。
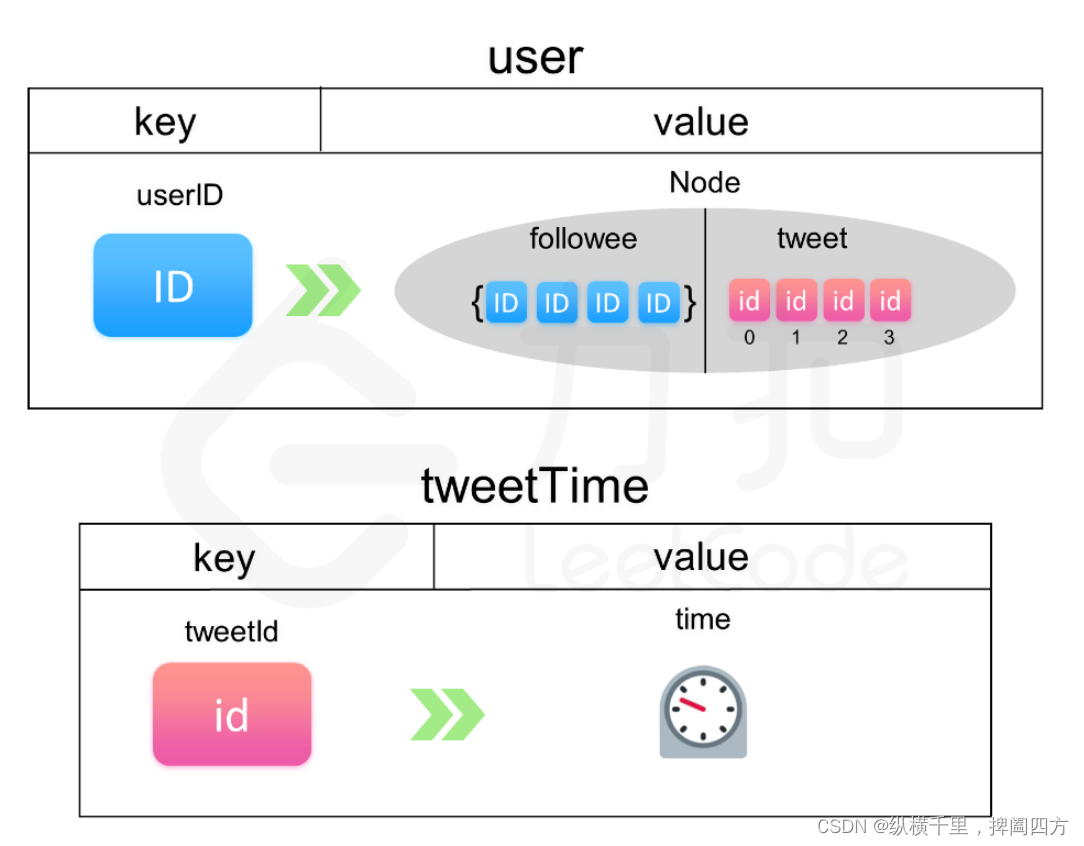
如果我们直接照搬「合并K个排序链表」的解法来进行合并,那么无疑会造成空间的部分浪费,因为这个题目不要求你展示用户的所有推文,所以我们只要动态维护用户的链表,存储最近的 recentMax 个推文 Id 即可(题目中的 recentMax 为 10)。那么对于操作 1,当发现链表的节点数等于 recentMax 时,我们按题意删除链表末尾的元素,再插入最新的推文 Id。对于操作 2,在两个链表进行线性归并的时候,只要已合并的数量等于 recentMax,代表已经找到这两个链表合起来后最近的 recentMax 条推文,直接结束合并即可。
class Twitter {
private class Node {
// 哈希表存储关注人的 Id
Set<Integer> followee;
// 用链表存储 tweetId
LinkedList<Integer> tweet;
Node() {
followee = new HashSet<Integer>();
tweet = new LinkedList<Integer>();
}
}
// getNewsFeed 检索的推文的上限以及 tweetId 的时间戳
private int recentMax, time;
// tweetId 对应发送的时间
private Map<Integer, Integer> tweetTime;
// 每个用户存储的信息
private Map<Integer, Node> user;
public Twitter() {
time = 0;
recentMax = 10;
tweetTime = new HashMap<Integer, Integer>();
user = new HashMap<Integer, Node>();
}
// 初始化
public void init(int userId) {
user.put(userId, new Node());
}
public void postTweet(int userId, int tweetId) {
if (!user.containsKey(userId)) {
init(userId);
}
// 达到限制,剔除链表末尾元素
if (user.get(userId).tweet.size() == recentMax) {
user.get(userId).tweet.remove(recentMax - 1);
}
user.get(userId).tweet.addFirst(tweetId);
tweetTime.put(tweetId, ++time);
}
public List<Integer> getNewsFeed(int userId) {
LinkedList<Integer> ans = new LinkedList<Integer>();
for (int it : user.getOrDefault(userId, new Node()).tweet) {
ans.addLast(it);
}
for (int followeeId : user.getOrDefault(userId, new Node()).followee) {
if (followeeId == userId) { // 可能出现自己关注自己的情况
continue;
}
LinkedList<Integer> res = new LinkedList<Integer>();
int tweetSize = user.get(followeeId).tweet.size();
Iterator<Integer> it = user.get(followeeId).tweet.iterator();
int i = 0;
int j = 0;
int curr = -1;
// 线性归并
if (j < tweetSize) {
curr = it.next();
while (i < ans.size() && j < tweetSize) {
if (tweetTime.get(curr) > tweetTime.get(ans.get(i))) {
res.addLast(curr);
++j;
if (it.hasNext()) {
curr = it.next();
}
} else {
res.addLast(ans.get(i));
++i;
}
// 已经找到这两个链表合起来后最近的 recentMax 条推文
if (res.size() == recentMax) {
break;
}
}
}
for (; i < ans.size() && res.size() < recentMax; ++i) {
res.addLast(ans.get(i));
}
if (j < tweetSize && res.size() < recentMax) {
res.addLast(curr);
for (; it.hasNext() && res.size() < recentMax;) {
res.addLast(it.next());
}
}
ans = new LinkedList<Integer>(res);
}
return ans;
}
public void follow(int followerId, int followeeId) {
if (!user.containsKey(followerId)) {
init(followerId);
}
if (!user.containsKey(followeeId)) {
init(followeeId);
}
user.get(followerId).followee.add(followeeId);
}
public void unfollow(int followerId, int followeeId) {
user.getOrDefault(followerId, new Node()).followee.remove(followeeId);
}
}2 设计循环双端队列
LeetCode641.设计实现双端队列。
实现 MyCircularDeque 类:
MyCircularDeque(int k) :构造函数,双端队列最大为 k 。
boolean insertFront():将一个元素添加到双端队列头部。 如果操作成功返回 true ,否则返回 false 。
boolean insertLast() :将一个元素添加到双端队列尾部。如果操作成功返回 true ,否则返回 false 。
boolean deleteFront() :从双端队列头部删除一个元素。 如果操作成功返回 true ,否则返回 false 。
boolean deleteLast() :从双端队列尾部删除一个元素。如果操作成功返回 true ,否则返回 false 。
int getFront() ):从双端队列头部获得一个元素。如果双端队列为空,返回 -1 。
int getRear() :获得双端队列的最后一个元素。 如果双端队列为空,返回 -1 。
boolean isEmpty() :若双端队列为空,则返回 true ,否则返回 false 。
boolean isFull() :若双端队列满了,则返回 true ,否则返回 false 。题目要求简洁明了,也不算很难。不过在实现的时候,我们要注意代码的规范和是否严谨。基于数组和链表都可以实现双端队列,但是数组实现的话,处理起来要麻烦很多,还要解决内存泄露的问题,具体我们在《队栈Hash》一章介绍过。我们同样可以使用双向链表来模拟双端队列,实现双端队列队首与队尾元素的添加、删除。双向链表实现比较简单,双向链表支持 O(1)O(1) 时间复杂度内在指定节点的前后插入新的节点或者删除新的节点。
循环双端队列的属性如下:
head:队列的头节点;
tail:队列的尾节点
capacity:队列的容量大小。
size:队列当前的元素数量。实现循环双端队列的接口方法,要点如下:
-
MyCircularDeque(int k):初始化队列,同时初始化队列元素数量size 为 0。head,tail 初始化为空。
-
insertFront(int value):队列未满时,在队首头结点head 之前插入一个新的节点,并更新head,并更新 size。
-
insertLast(int value):队列未满时,在队w尾节点tail 之后插入一个新的节点,并更新tail,并更新size。
-
deleteFront():队列不为空时,删除头结点head,并更新head 为head 的后一个节点,并更新size。
-
deleteLast():队列不为空时,删除尾结点tail,并更新tail 为tail 的前一个节点,并更新size。
-
getFront():返回队首节点指向的值,需要检测队列是否为空。
-
getRear():返回队尾节点指向的值,需要检测队列是否为空。
-
isEmpty():检测当前 size 是否为 0。
-
isFull():检测当前size 是否为capacity。
代码实现如下:
class MyCircularDeque {
private class DLinkListNode {
int val;
DLinkListNode prev, next;
DLinkListNode(int val) {
this.val = val;
}
}
private DLinkListNode head, tail;
private int capacity;
private int size;
public MyCircularDeque(int k) {
capacity = k;
size = 0;
}
public boolean insertFront(int value) {
if (size == capacity) {
return false;
}
DLinkListNode node = new DLinkListNode(value);
if (size == 0) {
head = tail = node;
} else {
node.next = head;
head.prev = node;
head = node;
}
size++;
return true;
}
public boolean insertLast(int value) {
if (size == capacity) {
return false;
}
DLinkListNode node = new DLinkListNode(value);
if (size == 0) {
head = tail = node;
} else {
tail.next = node;
node.prev = tail;
tail = node;
}
size++;
return true;
}
public boolean deleteFront() {
if (size == 0) {
return false;
}
head = head.next;
if (head != null) {
head.prev = null;
}
size--;
return true;
}
public boolean deleteLast() {
if (size == 0) {
return false;
}
tail = tail.prev;
if (tail != null) {
tail.next = null;
}
size--;
return true;
}
public int getFront() {
if (size == 0) {
return -1;
}
return head.val;
}
public int getRear() {
if (size == 0) {
return -1;
}
return tail.val;
}
public boolean isEmpty() {
return size == 0;
}
public boolean isFull() {
return size == capacity;
}
}同样的题目可以参考LeetCode707题。
3 设计浏览器记录
LeetCode1472.你有一个只支持单个标签页的 浏览器 ,最开始你浏览的网页是 homepage ,你可以访问其他的网站 url ,也可以在浏览历史中后退 steps 步或前进 steps 步。
请你实现 BrowserHistory 类:
-
BrowserHistory(string homepage) ,用 homepage 初始化浏览器类。
-
void visit(string url) 从当前页跳转访问 url 对应的页面 。执行此操作会把浏览历史前进的记录全部删除。
-
string back(int steps) 在浏览历史中后退 steps 步。如果你只能在浏览历史中后退至多 x 步且 steps > x ,那么你只后退 x 步。请返回后退 至多 steps 步以后的 url 。
-
string forward(int steps) 在浏览历史中前进 steps 步。如果你只能在浏览历史中前进至多 x 步且 steps > x ,那么你只前进 x 步。请返回前进至多steps步以后的url 。
class BrowserHistory
{
List<String> a = new ArrayList<>();
int i;
public BrowserHistory(String homepage)
{
a.add(homepage);
i = 0;
}
public void visit(String url)
{
a.subList(i + 1, a.size()).clear();
a.add(url);
i ++;
}
public String back(int steps)
{
i = Math.max(0, i - steps);
return a.get(i);
}
public String forward(int steps)
{
i = Math.min(i + steps, a.size() - 1);
return a.get(i);
}
}4 表达式求值
表达式计算是编译原理、自然语言处理、文本分析等领域非常重要的问题,我们这里看一个相对中等的问题,逆波兰表达式。LeetCode150.根据 逆波兰表示法,求表达式的值。说明:
-
有效的算符包括 +、-、*、/ 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
-
注意 两个整数之间的除法只保留整数部分。
-
可以保证给定的逆波兰表达式总是有效的。也即表达式总会得出有效数值且不存在除数为 0 的情况。
示例1:
输入:tokens = ["2","1","+","3","*"]
输出:9
解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
输入:tokens = ["4","13","5","/","+"]
输出:6
解释:该算式转化为常见的中缀算术表达式为:(4 + (13 / 5)) = 6本题看起来很复杂,但其实很简单,我们先理解一下什么是表达式,表达式就是小学里学的类似((2 + 1) * 3)这样的式子,根据不同的记法,有前缀、中缀和后缀三种方式,其区别在于运算符相对于操作数的位置,前缀表达式的运算符位于操作数之前,中缀和后缀同理,如下图,其实这就对应了树的前中后三种遍历方式。
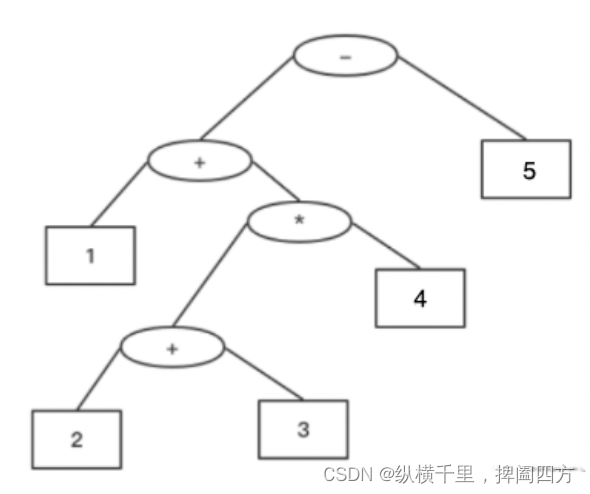
对应的三种表达式就是:
中缀表达式:1 + (2 + 3) × 4 - 5
前缀表达式:- + 1 × + 2 3 4 5
后缀表达式:1 2 3 + 4 × + 5 -从上面的例子我们也可以看到 中缀表达式是最像人话的,它是一种通用的算术或逻辑公式表示方法,操作符以中缀形式处于操作数的中间。 虽然人的大脑很容易理解与分析中缀表达式,但对计算机来说中缀表达式却是很复杂的,因此计算表达式的值时,通常需要先将中缀表达式转换为前缀或后缀表达式再进行求值。 前缀表达式的运算符位于两个相应操作数之前,前缀表达式又被称为前缀记法或波兰式。而后缀式就是逆波兰式,知道这些就行了。
观察后缀表达式可以发现,其特点就是数字先保存下来,然后遇到符号就计算,例如”1 2 3 +“,遇到 +号就将2+3加起来变成5再继续其他操作,直到最后完成。
如果用栈来解释就是遇见数字即进栈,遇见运算符,则取出栈中最上面的两个元素进行计算,最后将运算结果入栈。实现代码其实很容易:
public int evalRPN(String[] tokens) {
Stack<Integer> stack = new Stack<>();
for(String token : tokens){
if(!Character.isDigit(token.charAt(0)) && token.length() == 1){
/**
* 运算符,从栈中取出两个数进行运算!
*/
int b = stack.pop();
int a = stack.pop();
switch (token){
/**
* 根据运算符的种类进行计算
* 将结果直接入栈!
*/
case "+":stack.push(a + b);break;
case "-":stack.push(a - b);break;
case "*":stack.push(a * b);break;
case "/":stack.push(a / b);break;
}
}else {
/**
* 整数直接入栈!
*/
stack.push(Integer.parseInt(token));
}
}
return stack.pop();
}5 设计计算器
计算器也是非常常见的问题,我们看一个中等问题。LeetCode227.给你一个字符串表达式 s ,请你实现一个基本计算器来计算并返回它的值。整数除法仅保留整数部分。
你可以假设给定的表达式总是有效的。所有中间结果将在 [-231, 231 - 1] 的范围内。
注意:不允许使用任何将字符串作为数学表达式计算的内置函数,比如 eval() 。
示例:
输入:s = "3+2*2"
输出:7解决运算器问题,最好的工具就是栈。由于乘除优先于加减计算,因此不妨考虑先进行所有乘除运算,并将这些乘除运算后的整数值放回原表达式的相应位置,则随后整个表达式的值,就等于一系列整数加减后的值。
基于此,我们可以用一个栈,保存这些(进行乘除运算后的)整数的值。对于加减号后的数字,将其直接压入栈中;对于乘除号后的数字,可以直接与栈顶元素计算,并替换栈顶元素为计算后的结果。
具体来说,遍历字符串 ss,并用变量preSign 记录每个数字之前的运算符,对于第一个数字,其之前的运算符视为加号。每次遍历到数字末尾时,根据 preSign 来决定计算方式:
加号:将数字压入栈; 减号:将数字的相反数压入栈; 乘除号:计算数字与栈顶元素,并将栈顶元素替换为计算结果。 代码实现中,若读到一个运算符,或者遍历到字符串末尾,即认为是遍历到了数字末尾。处理完该数字后,更新 preSign 为当前遍历的字符。
遍历完字符串 s 后,将栈中元素累加,即为该字符串表达式的值。
class Solution {
public int calculate(String s) {
Deque<Integer> stack = new ArrayDeque<Integer>();
char preSign = '+';
int num = 0;
int n = s.length();
for (int i = 0; i < n; ++i) {
if (Character.isDigit(s.charAt(i))) {
num = num * 10 + s.charAt(i) - '0';
}
if (!Character.isDigit(s.charAt(i)) && s.charAt(i) != ' ' || i == n - 1) {
switch (preSign) {
case '+':
stack.push(num);
break;
case '-':
stack.push(-num);
break;
case '*':
stack.push(stack.pop() * num);
break;
default:
stack.push(stack.pop() / num);
}
preSign = s.charAt(i);
num = 0;
}
}
int ans = 0;
while (!stack.isEmpty()) {
ans += stack.pop();
}
return ans;
}
}