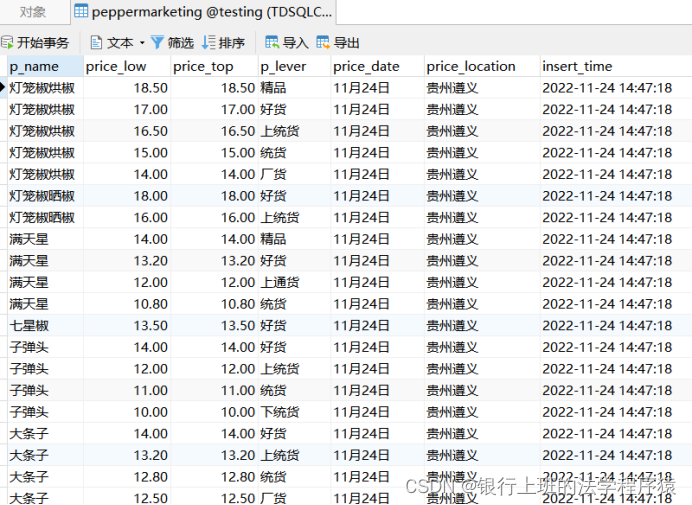
腾讯云轻量应用服务器+TDSQL-MYSQL数据库+PYTHON做爬虫
实现目标:轻量应用服务器上运行Python爬虫,把数据写到TDSQL-MYSQL数据库中。
最近双十一,趁着这一波福利,在腾讯云购买了一个轻量应用服务器和TDSQL-MYSQL版的数据库。买来之后,想做点什么,在网上找了很多主题,最后还是决定做个爬虫练练手。
后面按照这个顺序介绍
1.腾讯云轻量应用服务器的连接
2.TDSQL-MYSQL数据库连接
3.轻量应用服务器与数据库之间的连接
4.编写爬虫
5.虚拟环境配置
一、腾讯云轻量应用服务器
(一)确认服务器系统版本
点开服务器实例的管理,我的环境用了宝塔linux面板,如果要更换系统,在实例“概要”页面中部有“镜像”,点击重装系统,可以更换系统,非常快。
(二)确认防火墙打开
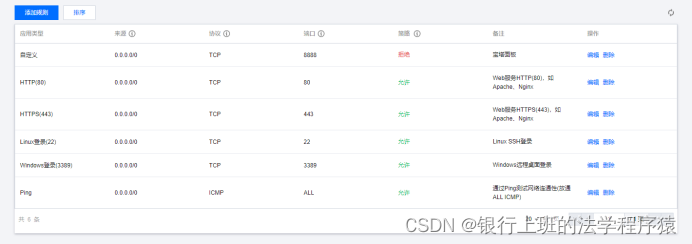
在服务器实例概要界面,点击顶部菜单防火墙,查看Llinux登陆22号端口是否是打开的状态。
(三)创建服务器登录的密钥
点击左侧轻量应用服务器左边栏“密钥”,新建一个密钥,创建密钥时,选择服务器所在的地域,名个英文名,下载到本地电脑妥善保存。然后绑定实例(绑定轻量云应用服务器那个实例)
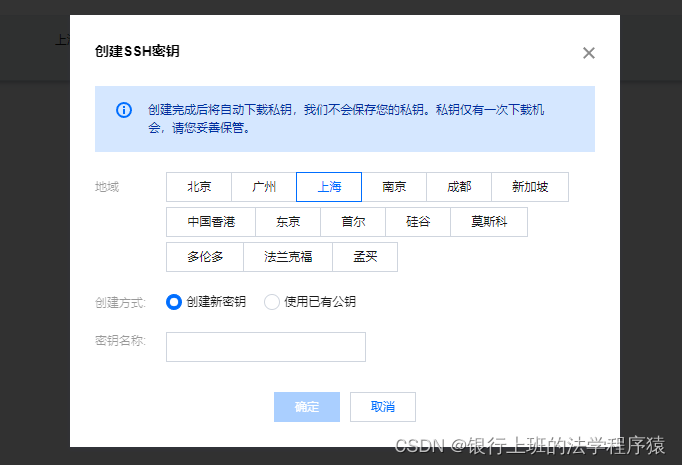
下载的密钥后缀名为*.pem。
(四)使用xshell连接服务器
在XSHELL中新建会话,就填写一个主机(服务器的外网IP),然后切换“用户身份验证”页面,方法选择PublicKey,用户密钥点击浏览,将刚才下载的pem文件倒入进来,以后连接时直接选择这个密钥即可登陆。
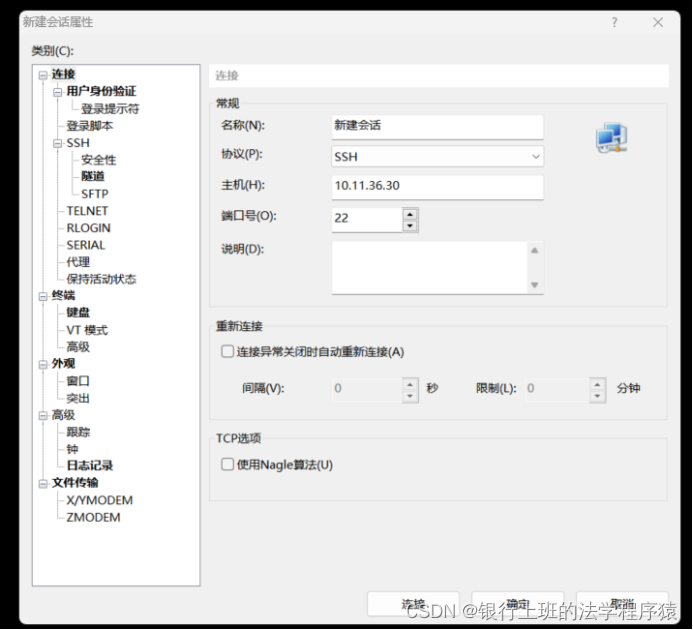
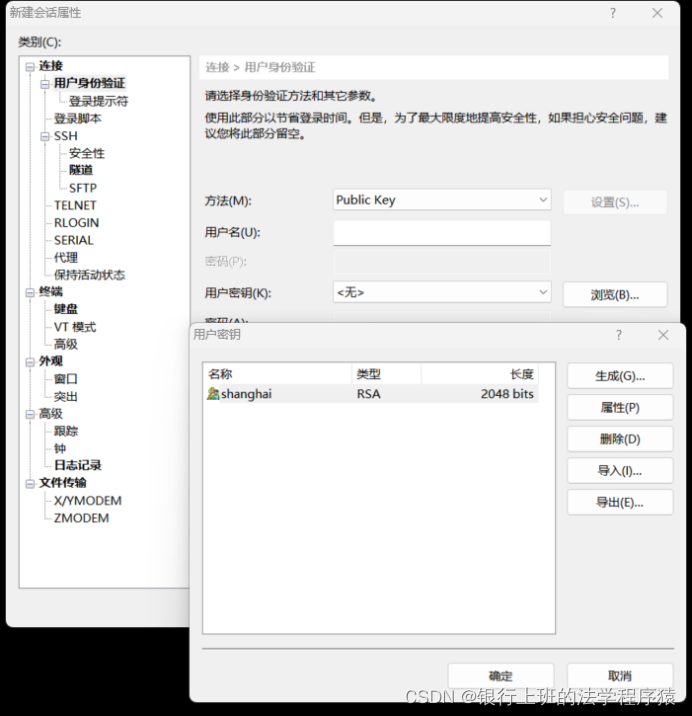
会话创建完毕后,连接该项服务器。
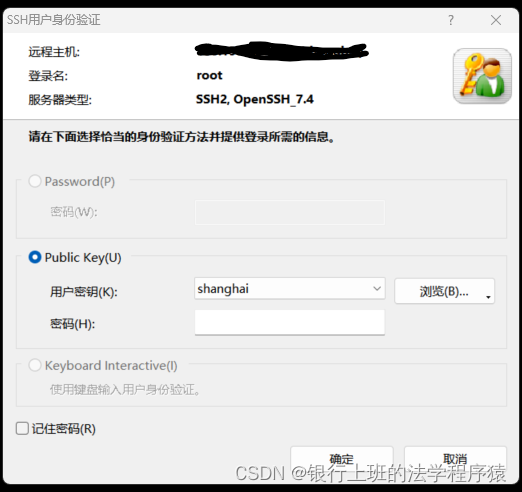
直接点击确定,没有密码。出现下图的样式,就是连接完成了。

二、TDSQLC-MYSQL数据库
(一)使用Navicat连接数据库
购买该项数据库后,系统自动会产生一个实例。
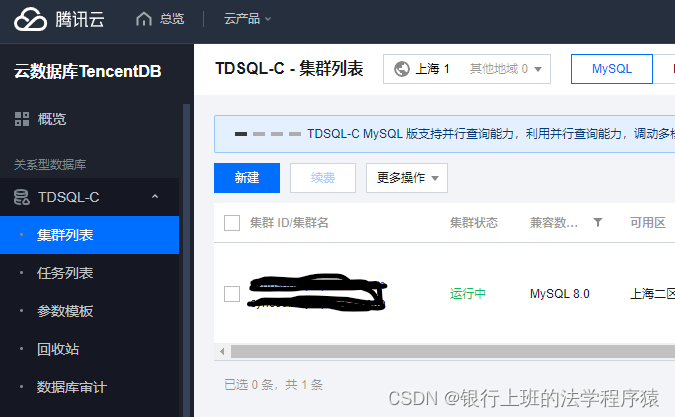
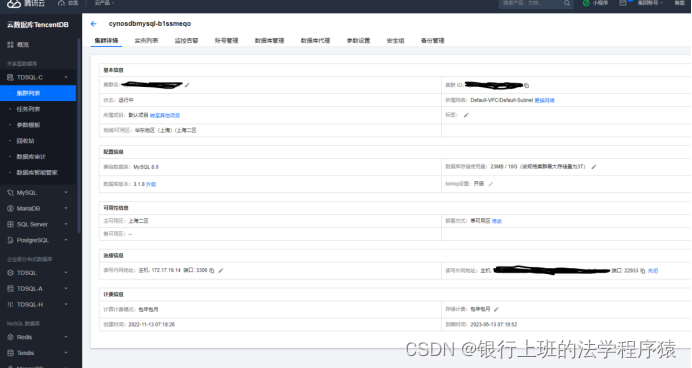
选择你购买的实例进去,在集群详情页面底部,需要打开外网读写地址,不然navicat没有地方连接。
在Navicat上新建一个连接,选择“腾讯云-腾讯云数据库mysql版。
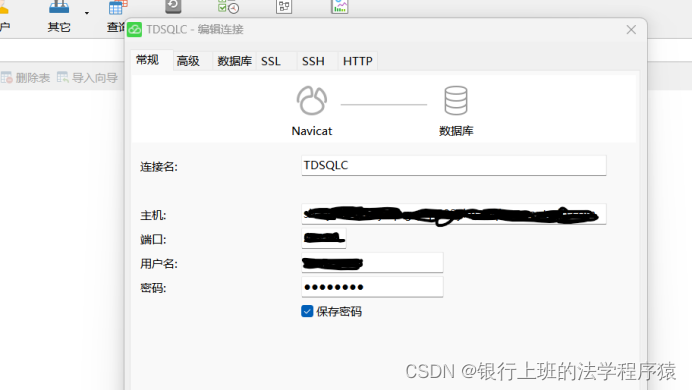
主机就是在刚才打开的数据库外网访问地址。
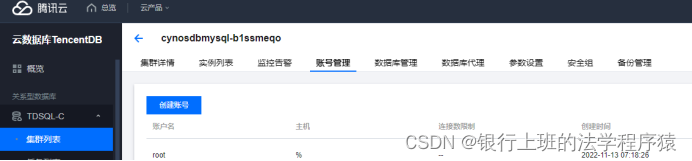
账号密码可以在下面图片的位置创建或者重置root用户密码
三、轻量应用服务器与数据库之间的连接
轻量应用服务器与云数据库天生无法互联互通,需要在轻量应用服务器一端建立“内网互联”的功能。在这里建立申请一个。
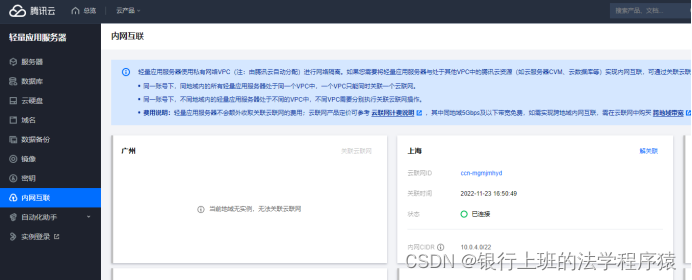
在这个位置,关联实例。
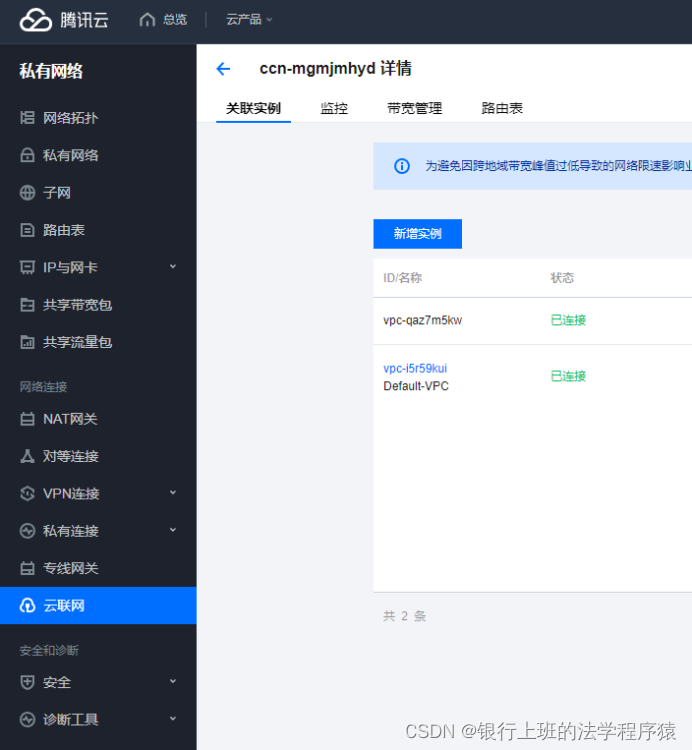
申请可能需要十几分钟,当状态为已连接,说明服务器和数据库在同一网络里面了。
四、写个爬虫
用python3+requests+beautifulsoup4+pymsql来做个爬虫。
直接上代码。并把代码上传到代码仓库当中。
(一)爬虫主体
import random
import requests
from bs4 import BeautifulSoup
import re
from tdmysql import mysqlconn
from datetime import datetime
import time
# 初始网页
url = "http://www.xxxx.cn/xxxx/xxxx.html"
# 获取网页
def getit(urls):
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36"
}
response = requests.request(url=urls, method="get", headers=header)
html_doc = response.text
soup = BeautifulSoup(html_doc, 'html.parser')
# 这个也是为了不得罪人
delay_seconds = random.randint(1, 10)
print("延迟%s秒后继续……"%(delay_seconds))
time.sleep(delay_seconds)
return soup
# 先拆分结果[结果为: 品种、价格、类别备注]
def split_text(txt):
split_s = re.compile('[r"\r\n\u3000",:,元/斤,左右,(,)]')
return split_s.split(txt)
# 在标题里面提取日期
def get_date(txt):
pattern = r"(\d{1,2}月\d{1,2}日)"
result = re.search(pattern, txt)
return result.groups()[0]
# 在标题里面提取地区
def get_address(txt):
txt = txt.replace("月", "").replace("日", "").replace("/", "").replace("辣椒价格", "").strip()
pattern = r"([\u4e00-\u9fa5]{2,6})"
result = re.search(pattern, txt)
return result.groups()[0]
# 将拆分的结果进行列表化处理 把日期也传入进去
def split_list(ls, data_date, d_address, in_time):
def pr(price):
# 如果价格长度超过六个字符,肯定是xx-xx价格区间,所以还要拆一次
if len(price) > 6:
split_s = re.compile('-')
result = split_s.split(price)
else:
# 如果价格没有超过六个字符,说明是一口价,不是价格区间。
result = [price, price]
return result
name = ls[4]
comment = ls[len(ls) - 2] # 倒数第二个是备注
a_price = pr(ls[5])
if comment == "":
comment = "空"
return [name, a_price[0], a_price[1], comment, data_date, d_address, in_time]
# 找XX日贵州遵义辣椒价格的标题A标签
url_list = getit(url).find_all('a', {"title": re.compile("日贵州遵义辣椒价格")})
times = 0
TDSQL = mysqlconn()
for i in url_list:
times += 1
url2 = i.attrs['href']
title = i.attrs['title']
d_date = get_date(title)
d_address = get_address(title)
insert_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
response = getit(url2).find_all(text=re.compile("元/斤"))
empty_list = []
for j in response:
x = split_text(j)
rrr = split_list(x, d_date, d_address, insert_time)
# 先转为元组,后用列表包裹。
r_tuple = tuple(rrr)
empty_list.append(r_tuple)
TDSQL.ldb(empty_list)
# 这个是为了不得罪人写的
if times == 5:
break
(二)数据库连接
import pymysql
class mysqlconn:
def __init__(self):
self.dbuser = 'root'
self.dbpwd = '密码'
self.conn = pymysql.connect(host='数据库内网访问地址',
user=self.dbuser,
password=self.dbpwd,
port=3306,
charset='utf8mb4')
# 检查数据库与表是否完整
def check(self):
conn = self.conn
cursor = conn.cursor()
try:
cursor.execute("use testing;")
print("数据库连接成功")
except Exception as e:
print(e)
finally:
cursor.close()
conn.close()
def ldb(self, content):
conn = self.conn
cursor = conn.cursor()
tablename = 'peppermarketing'
s_content = content
# 构造sql语句
insert_sql = "REPLACE INTO peppermarketing VALUES(%s,%s,%s,%s,%s,%s,%s)"
print(insert_sql)
try:
cursor.execute('use testing;')
cursor.executemany(insert_sql, s_content)
conn.commit()
print('%s入库成功' % tablename)
except Exception as e:
# 万一失败了,要进行回滚操作
print('入库失败,因为%s' % e)
conn.rollback()
五、配置虚拟环境。
1.Xshell中输入命令 “pip3 install pipenv” 安装pipenv
2.“mkdir test3” 建立文件夹
3.进入test3 文件夹,初始化特定版本的环境输入“pipenv --python 3.6” (可选,如果不初始,则跟随系统)
4.输入命令 pipenv install 开始安装虚拟环境
5.安装完毕后输入命令 pipenv shell 进入虚拟环境,前面有”(xxx)”即代表进入了虚拟环境。
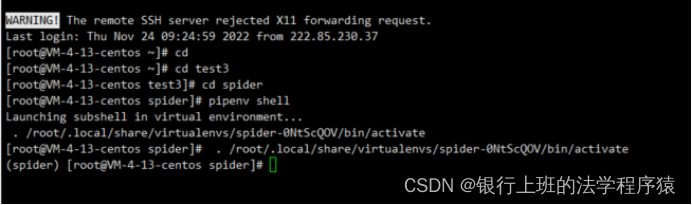
6.用了“pipenv install + 包名” 这种命令安装了所需要的包。
7.包安装完毕,拉取代码。拉取代码的方法和部署公钥查看gitee即可。
8.在xshell中运行程序,python3 hohoho.py
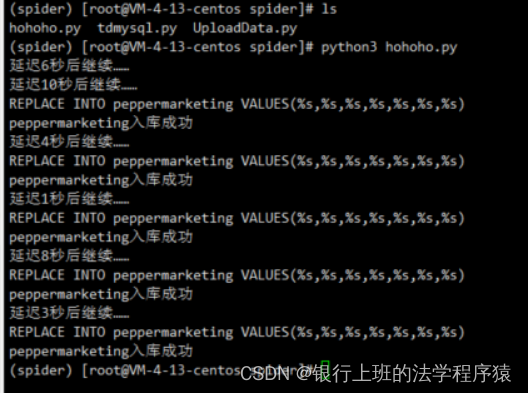
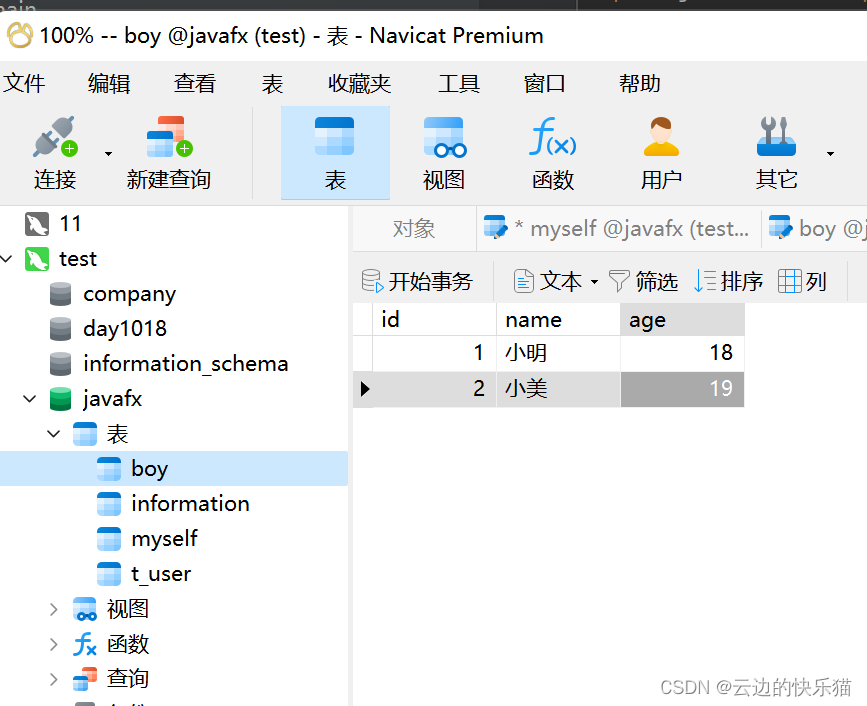
使用Navicat查看爬取的数据