文章目录
- 前言
- 一、基础知识
- 1.异构图(Heterogeneous Graph)
- 2.元路径
- 3.异构图注意力网络
- 二、异构图注意力网络
- 1.结点级别注意力(Node-level Attention)
- 2.语义级别注意力(Semantic-level Attention)
- 总结
前言
异构图注意力网络Heterogeneous Graph Attention Network ( HAN )学习笔记。
一、基础知识
1.异构图(Heterogeneous Graph)
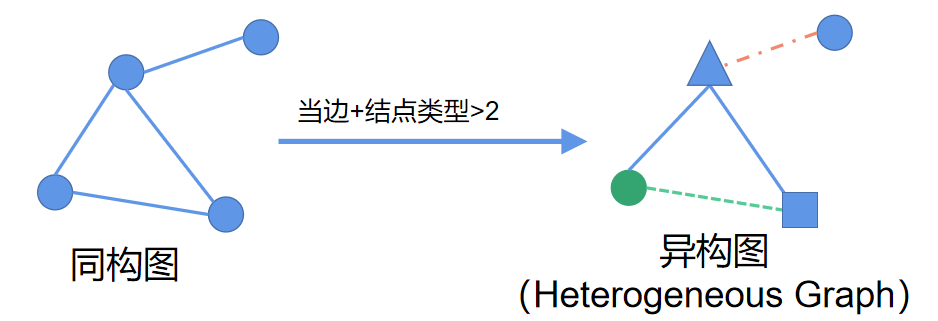
同构图是指结点类型相同、边类型也相同的图。异构图则是边和结点类型总和大于2的图,如下所示。
2.元路径

3.异构图注意力网络
中心思想:通过元路径生成不同元路径下的同构子图,在不同子图中进行消息传递聚合信息( Node-Level Attention ),最后将各元路径下子图聚合出的向量注意力加权聚合后进行后道传播( Sematic-Level Attention )。
为更清晰的解释原理,以下将逐步拆解。
(1)第一步

异构图如图片左边所示。根据M-A-M和M-D-M两种元路径,将有“介质”A或D连接的M之间视为通路(一阶邻居),可以拆解异构图为图片右边所示的子图。
二、异构图注意力网络
1.结点级别注意力(Node-level Attention)
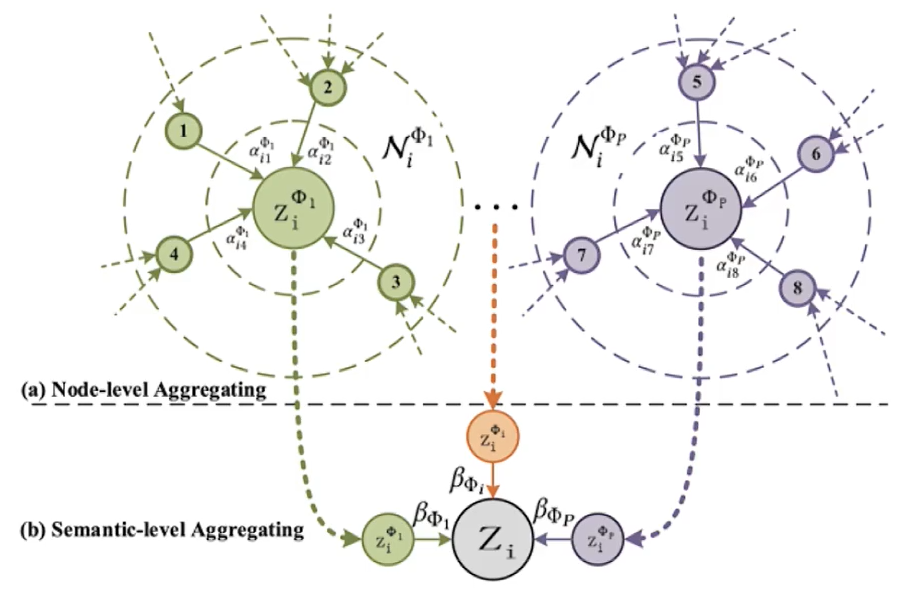
图取自论文原文
- 节点注意力的计算。
h i ′ = M ϕ i ⋅ h i \mathbf{h}_i^{\prime}=\mathbf{M}_{\phi_i} \cdot \mathbf{h}_i hi′=Mϕi⋅hi
- i i i为第i个主结点。
- j j j为第j个邻居结点。
- M Φ i M_{\Phi_i} MΦi 是模型需要训练的线性变化矩阵。 M Φ i M_{\Phi_i} MΦi 主要作用是提高拟合能力。
-
h
i
\mathbf{h}_i
hi为结点的特征向量。
α i j Φ = softmax j ( e i j Φ ) = exp ( σ ( a Φ T ⋅ [ h i ′ ∥ h j ′ ] ) ) ∑ k ∈ N i Φ exp ( σ ( a Φ T ⋅ [ h i ′ ∥ h k ′ ] ) ) \alpha_{i j}^{\Phi}=\operatorname{softmax}_j\left(e_{i j}^{\Phi}\right)=\frac{\exp \left(\sigma\left(\mathbf{a}_{\Phi}^{\mathrm{T}} \cdot\left[\mathbf{h}_i^{\prime} \| \mathbf{h}_j^{\prime}\right]\right)\right)}{\sum_{k \in \mathcal{N}_i^\Phi} \exp \left(\sigma\left(\mathbf{a}_{\Phi}^{\mathrm{T}} \cdot\left[\mathbf{h}_i^{\prime} \| \mathbf{h}_k^{\prime}\right]\right)\right)} αijΦ=softmaxj(eijΦ)=∑k∈NiΦexp(σ(aΦT⋅[hi′∥hk′]))exp(σ(aΦT⋅[hi′∥hj′])) - N i Φ N_i^{\Phi} NiΦ 代表在元路径 Φ \Phi Φ 下节点 i i i 的邻居集。如图中左右两个 z i Φ z_i^\Phi ziΦ周围的结点1、2、3…8
- a i j Φ a_{i j}^{\Phi} aijΦ 代表在元路径 Φ \Phi Φ 下邻居节点 j j j 传递消息至主节点 i i i 的注意力。
- α Φ T \alpha_{\Phi}^T αΦT 是模型需要训练的线性变化矩阵, 更多的作用是调整形状。
- ∣ ∣ || ∣∣为拼接符号。式子中是将两个节点的线性变换后的特征向量拼接起来。
- 进行将注意力作为权重的加权求和计算(左边的公式), 或者多头注意力计算(右边的公式)。
z i Φ = σ ( ∑ j ∈ N i Φ α i j Φ ⋅ h j ′ ) z i Φ = ∥ k = 1 K σ ( ∑ j ∈ N i Φ α i j Φ ⋅ h j ′ ) \mathrm{z}_i^{\Phi}=\sigma\left(\sum_{j \in \mathcal{N}_i^{\Phi}} \alpha_{i j}^{\Phi} \cdot \mathbf{h}_j^{\prime}\right) \quad \mathrm{z}_i^{\Phi}=\|_{k=1}^K \sigma\left(\sum_{j \in \mathcal{N}_i^{\Phi}} \alpha_{i j}^{\Phi} \cdot \mathbf{h}_j^{\prime}\right) ziΦ=σ⎝⎛j∈NiΦ∑αijΦ⋅hj′⎠⎞ziΦ=∥k=1Kσ⎝⎛j∈NiΦ∑αijΦ⋅hj′⎠⎞
- z i Φ z_i^{\Phi} ziΦ 代表在元路径 Φ \Phi Φ 下进行一轮消息传递后代表节点 i i i 的特征向量。
- σ \sigma σ为激活函数。
2.语义级别注意力(Semantic-level Attention)
- 语义级别注意力的计算。
w Φ p = 1 ∣ V ∣ ∑ i ∈ V q T ⋅ tanh ( W ⋅ z i Φ p + b ) w_{\Phi_p}=\frac{1}{|\mathcal{V}|} \sum_{i \in \mathcal{V}} \mathbf{q}^{\mathrm{T}} \cdot \tanh \left(\mathbf{W} \cdot \mathbf{z}_i^{\Phi_p}+\mathbf{b}\right) wΦp=∣V∣1i∈V∑qT⋅tanh(W⋅ziΦp+b)
- V V V 代表所有节点的数量。 q , W , b q, W, b q,W,b 是此处模型需要训练的参数。
- 公式的意义代表对元路径 Φ p \Phi^p Φp 下生成的子图中所有的节点都进行 过消息传递得到每个节点的向量表示 z i Φ p z_i^{\Phi_p} ziΦp 后。进行线性变化再将 形状调整至一维标量后取个平均值。
- 对上述的结果进行Sotfmax归一化作为语义级别的注意力。
β Φ p = exp ( w Φ p ) ∑ p = 1 P exp ( w Φ p ) \beta_{\Phi_p}=\frac{\exp \left(w_{\Phi_p}\right)}{\sum_{p=1}^P \exp \left(w_{\Phi_p}\right)} βΦp=∑p=1Pexp(wΦp)exp(wΦp)
- 最终注意力的加权求和。
Z = ∑ p = 1 P β Φ p ⋅ Z Φ p \mathbf{Z}=\sum_{p=1}^P \beta_{\Phi_p} \cdot \mathbf{Z}_{\Phi_p} Z=p=1∑PβΦp⋅ZΦp
- 公式中的 Z Φ P Z_{\Phi_P} ZΦP 代表在元路径 p p p 下生成的子图 Φ p \Phi_p Φp 的所有节点集合 Z Φ P = { z 1 Φ p , z 2 Φ p … z n Φ p } ∘ Z_{\Phi_P}=\left\{z_1^{\Phi_p}, z_2^{\Phi_p} \ldots z_n^{\Phi_p}\right\}_{\circ} ZΦP={z1Φp,z2Φp…znΦp}∘
- Z Z Z 即代表最终经过HAN网络层传递一轮后的节点特征向量集合 Z = { z 1 , z 2 … z n } Z=\left\{z_1, z_2 \ldots z_n\right\} Z={z1,z2…zn} 。